机器学习————逻辑回归
一、逻辑回归核心概念
1、实现任务:监督学习中的二分类任务,也可扩展为多分类,用于预测样本属于某一类别的概率,如垃圾邮件识别、疾病诊断、用户流失预测。
(注:虽然名字带 “回归”,但不是回归任务,而是分类任务。其核心是基于 “线性回归的输出” 做分类转换。)
2、核心步骤:先通过线性模型计算连续值输出,再通过Sigmoid 激活函数将该输出映射到[0, 1]区间,得到样本属于正类的概率值,最后通过阈值(阈值通常为0.5)判断样本类别。
两种核心公式:
- 线性部分(与线性回归一致):
- 分类部分(Sigmoid 映射):
3、分类逻辑:
- 若
≥0.5,判定样本为正类(通常标记为 1)。
- 若
4、损失函数:不使用均方误差(例:MSE,非凸函数,易陷入局部最优),采用对数损失函数,目标是最小化分类误差,求解最优权重w和偏置b。
二、 数学原理
1、Sigmoid 函数特性:
- 输出值域严格在
[0, 1]之间,符合概率的取值范围。 - 函数呈 S 型曲线,在z=0处对应概率 0.5斜率最大,两端斜率趋近于 0,能有效区分正负类。
- 当z→+∞时,
2、无法通过最小二乘法直接求解,通常采用梯度下降法(批量梯度下降、随机梯度下降等)迭代更新参数,最小化对数损失函数。
(注:逻辑回归的损失函数是对数损失函数,为非凸函数,它是通过最大似然估计推导出来的,最小二乘法适合连续值预测的凸损失场景。)
三、代码解释
模块一
# 1. 导入所需库
import numpy as np
from sklearn.linear_model import LogisticRegression#逻辑回归分类模型LogisticRegression
from sklearn.datasets import make_classification#导入人工生成二分类数据集的函数
from sklearn.model_selection import train_test_split#划分数据集
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report#分类任务专用评估指标
import matplotlib.pyplot as plt#导入绘图库matplotlib的绘图模块模块二
n_features=2:每个样本包含 2 个特征,对应二维平面(),方便后续绘制散点图和决策边界。
n_informative:设置 2 个有效特征,即这两个特征都对类别标签有区分作用,保证逻辑回归模型能有效学习规律。
n_redundant=0:无冗余特征,冗余特征是有效特征的线性组合,无额外信息,简化数据,提升模型拟合效果。
n_clusters_per_class=1:每个类别仅对应 1 个数据簇,数据分布更集中,逻辑回归更容易拟合。
# 2. 生成模拟二分类数据集
np.random.seed(42) # 设置随机种子,保证结果可复现
X, y = make_classification(
n_samples=200, # 样本数量
n_features=2, # 特征数量
n_informative=2,# 有效特征数量
n_redundant=0, # 冗余特征数量
n_clusters_per_class=1, # 每个类别对应的簇数量
random_state=42
)模块三
将完整数据集(x,y),按 7:3 比例拆分为训练集(x_train,y_train)和测试集(x_test,y_test)。
# 3. 划分训练集和测试集(7:3比例)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)模块四
实例化逻辑回归模型,创建模型对象lr_clf。
训练模型,让lr_clf从训练集(x_train,y_train)中学习最优的权重w和偏置b。
# 4. 构建并训练逻辑回归模型
lr_clf = LogisticRegression(random_state=42) # 实例化逻辑回归模型
lr_clf.fit(X_train, y_train) # 训练模型,学习最优参数w和b模块五
前者得到硬分类结果,后者得到软分类结果。
# 5. 模型预测(两种预测结果:类别标签 + 正类概率)
y_pred = lr_clf.predict(X_test) # 预测测试集样本的类别标签(0或1)
y_pred_proba = lr_clf.predict_proba(X_test) # 预测测试集样本的类别概率模块六
计算测试集上的准确率,取值范围[0, 1],越接近 1 模型分类效果越好。
通过混淆矩阵可分析模型的误判类型,比准确率更全面。
class_report = classification_report(y_test, y_pred)。函数解读:报告包含每个类别的精确率、召回率、F1 值,以及整体的宏平均、加权平均。
# 7. 模型评估(分类任务专用指标)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
# 计算混淆矩阵
conf_mat = confusion_matrix(y_test, y_pred)
# 生成分类报告
class_report = classification_report(y_test, y_pred)
# 打印评估结果
print(f"测试集准确率(Accuracy):{accuracy:.4f}")
print("=" * 60)
print("混淆矩阵(Confusion Matrix):")
print(conf_mat)
print("=" * 60)
print("分类报告(Classification Report):")
print(class_report)
print("=" * 60)模块七
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1;
作用:获取特征 1(X [:, 0])的最小值(减 1)和最大值(加 1),确定网格的 x 轴范围,留出边界余量,让图表更美观。
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1;
作用:获取特征 2(X [:, 1])的最小值(减 1)和最大值(加 1),确定网格的 y 轴范围。
xx, yy = np.meshgrid(...);
作用:生成二维网格数据,xx和yy的形状均为(200,200),对应 200×200 个网格点,覆盖整个数据区间。
grid_data = np.c_[xx.ravel(), yy.ravel()];
将网格点转换为模型可接受的特征数组,每个网格点对应一个 “虚拟样本”。
grid_pred = grid_pred.reshape(xx.shape);
作用:将展平的预测结果转换为(200,200)的网格形状,与xx、yy对应,方便后续绘制填充图。
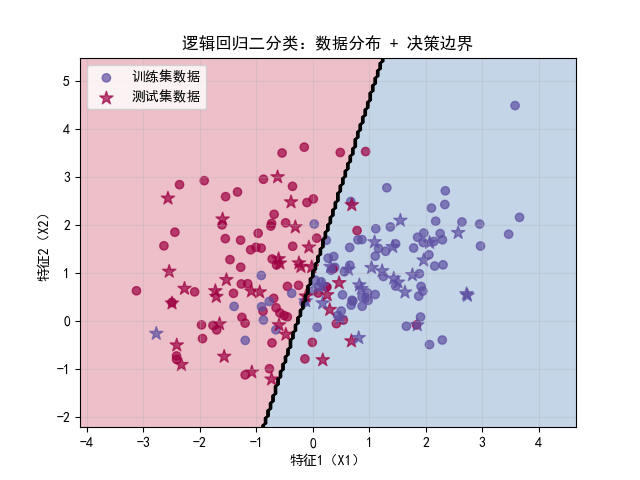
plt.contourf(xx, yy, grid_pred, alpha=0.3, cmap=plt.cm.Spectral);
作用:绘制类别区域填充图,用不同颜色区分两个类别的区域,alpha=0.3设置透明度,避免遮挡散点。
plt.contour(xx, yy, grid_pred, colors="k", linewidths=1);
作用:绘制决策边界(黑色实线),即两个类别区域的分界线,linewidths=1设置线宽为 1 像素。
# 8. 结果可视化(散点图 + 决策边界)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 解决中文显示问题
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# 8.1 生成网格数据,用于绘制决策边界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200), np.linspace(y_min, y_max, 200))
grid_data = np.c_[xx.ravel(), yy.ravel()] # 转换为模型可接受的2维特征数组
grid_pred = lr_clf.predict(grid_data) # 预测网格数据的类别
grid_pred = grid_pred.reshape(xx.shape) # 转换为网格形状,用于绘制填充图
# 8.2 绘制决策边界和背景填充
plt.contourf(xx, yy, grid_pred, alpha=0.3, cmap=plt.cm.Spectral)
plt.contour(xx, yy, grid_pred, colors="k", linewidths=1)
# 8.3 绘制训练集和测试集散点图
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=plt.cm.Spectral, label="训练集数据", alpha=0.7)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=plt.cm.Spectral, marker="*", s=100, label="测试集数据", alpha=0.7)
# 8.4 设置图表标签和图例
plt.xlabel("特征1(X1)")
plt.ylabel("特征2(X2)")
plt.title("逻辑回归二分类:数据分布 + 决策边界")
plt.legend()
plt.grid(True, alpha=0.3)
# 8.5 显示图表
plt.show()运行结果
分类报告(Classification Report):
precision recall f1-score support
0 0.96 0.79 0.87 34
1 0.78 0.96 0.86 26
accuracy 0.87 60
macro avg 0.87 0.88 0.87 60
weighted avg 0.88 0.87 0.87 60
四、总结
谢谢大家观看!如有不足,请大家进行批评指证。之后我也会更新机器学习的其它方法。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)