算法类学习笔记 ———— BEV常用数据集(nuScenes)
文章目录
nuScenes
介绍
nuScenes 数据集是一个用于自动驾驶的公共大规模数据集,由 Motional(前身为 nuTonomy)的团队开发。Motionals 旨在支持对计算机视觉和自动驾驶的公共研究。为此,Motional在波士顿和新加坡收集了 1000 个驾驶场景。nuScenes 的丰富复杂性将鼓励开发方法,使每个场景都有几十个对象的城市地区能够安全驾驶。收集不同大陆的数据进一步使我们能够研究计算机视觉算法在不同位置、天气条件、车辆类型、植被、道路标记和左侧与右侧交通中的泛化。为了方便常见的计算机视觉任务,例如目标检测和跟踪,我们在整个数据集中使用 2Hz 的精确 3D 边界框注释 23 个对象类。此外,我们还注释了对象级属性,例如可见性、活动和姿势。2019 年 3 月,nuScenes 发布了包含所有 1,000 个场景的完整 nuScenes 数据集。完整的数据集包括大约 1.4M 相机图像、390k 激光雷达扫描、1.4M 雷达扫描和 40k 关键帧中的 1.4M 对象边界框。nuScenes 数据集的灵感来自开创性的 KITTI 数据集。nuScenes 是第一个提供来自自动驾驶汽车整个传感器套件(6 个摄像头、1 个 LIDAR、5 个 RADAR、GPS、IMU)的数据的大规模数据集。与 KITTI 相比,nuScenes 包含了 7 倍多的对象注释。虽然之前发布的大多数数据集都专注于基于摄像头的目标检测(城市景观、Mapary Vistas、阿波罗景观、伯克利深度驱动),但 nuScenes 的目标是查看整个传感器套件。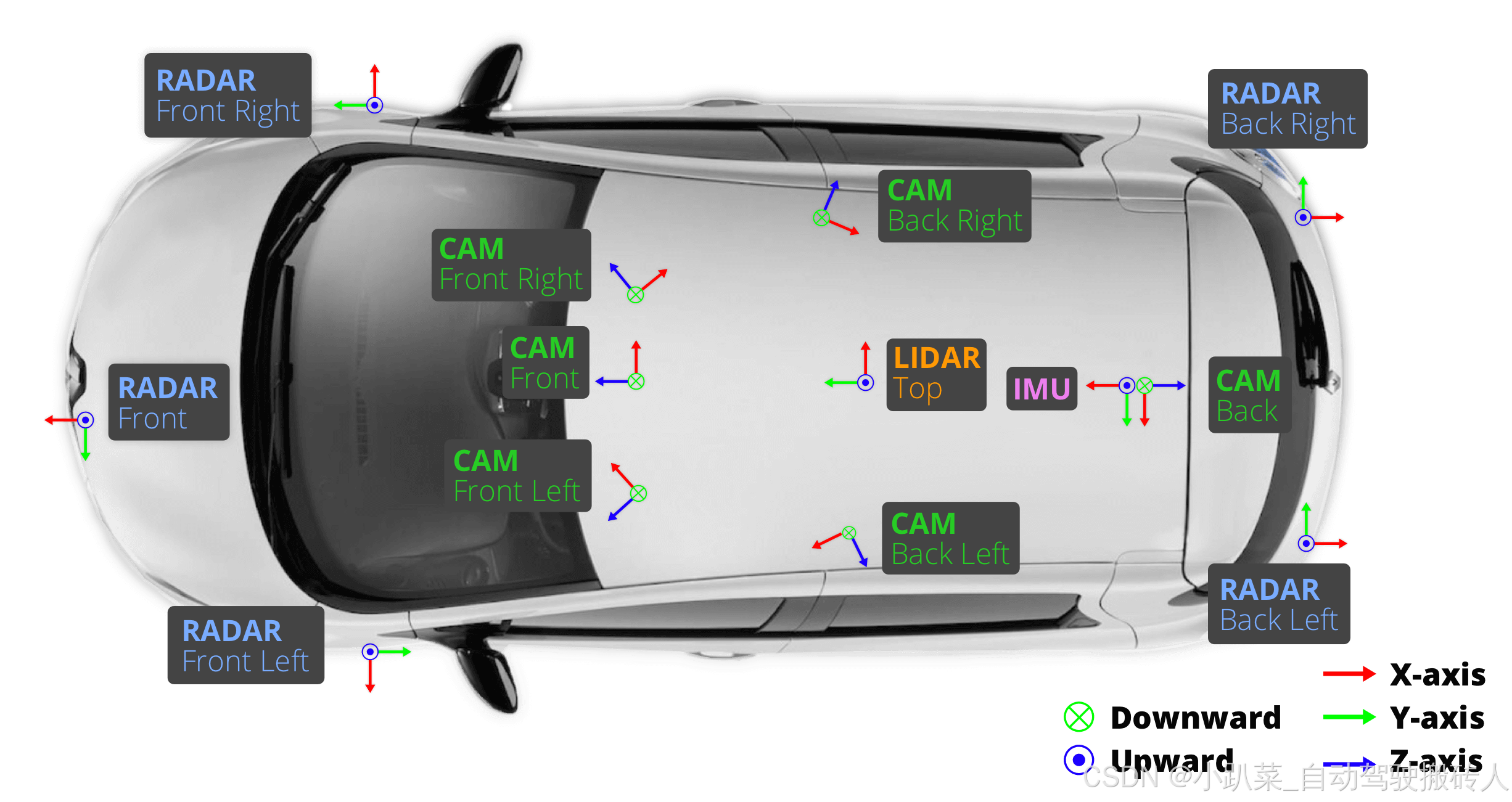
2020 年 7 月,我们发布了 nuScenes-lidarseg。在 nuScenes-lidarseg 中,我们使用 32 个可能的语义标签之一(即激光雷达语义分割)从 nuScenes 中的关键帧中注释每个激光雷达点。因此,nuScenes-lidarseg 包含了跨越 40,000 个点云和 1000 个场景(用于训练和验证的 850 个场景,以及用于测试的 150 个场景)的 14 亿个注释点。nuScenes 数据集可免费使用,严格用于非商业目的。
Data format
下面将介绍说明nuImages里所使用的数据模型,所有的注释和元数据(包括校准、地图、车辆坐标等)都包含在相关数据库中。星号表示与nuscenes模式相比的修改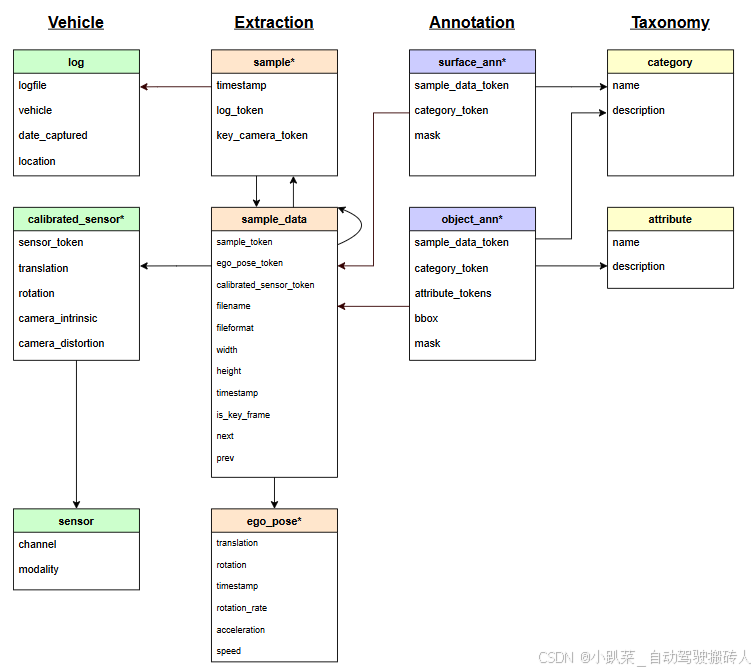
Attributes
属性是实例的属性,它可以在类别保持不变的情况下发生变化。例如:一辆正在停放/停止/移动的车辆,以及一辆自行车是否有人骑。nuImages中的属性是nuScenes中的属性的超集。
atrribute{
token: <str>-Unique record identifier
name: <str>-attribute name
description: <str>-attribute description
}
Calibrated_sensor
在特定车辆上校准的特定摄像头的定义。给出了车身框架的所有外在参数。与nuScenes相反,所有的相机图像都是扭曲的,未经校正的。
calibrated_sensor{
token: <str>-Unique record identifier
sensor_token: <str>-Foreign key pointing to the sensor type
translation: <float>[3]-Coordinate system origin in meters: x, y, z.
rotation: <float>[4]-Coordinate system orientation as quaternion: w, x, y, z.
camera_intrinsic: <float>[3,3]-Intrinsic camera calibration. Empty for sensors that are not cameras.
camera_distortion: <float>[5 or 6]-Camera calibration parameters [k1, k2, p1, p2, k3, k4]. We use the 5 parameter camera convention of the CalTech camera calibration toolbox, that is also used in OpenCV. Only for fish-eye lenses in CAM_BACK do we use the 6th parameter (k4).
}
Category
物体类别的分类法(例如车辆、人类)。子类别通过 · 来划分(例如human.pedestrian.audlt)。nuImages中的类别与nuScenes(无lidarseg)中的相同,加上flat.driveable_surface。
category{
token: <str>-Unique record identifier
name: <str>-Category name.Subcategories indicated by period
description: <str>-Category description
}
ego_pose
特定时间戳下本车(自身车辆)的位姿。是相对于日志地图的全局坐标系给出的。ego_pose是本文中描述的基于激光雷达地图的定位算法的输出。定位在x-y平面上是二维的。需要注意的是nuImages是从近500个不同地图版本的日志中收集的。因此,坐标不应该在日志之间进行比较,也不应该在nuScenes的语义地图上呈现。
ego_pose {
token: <str>-Unique record identifier
translation: <float>[3]-Coordinate system origin in meters: x, y, z. Note that z is always 0
rotation: <float>[4]-Coordinate system orientation as quaternion: w, x, y, z
timestamp: <int>-Unix time stamp
rotation_rate: <float>[3]-The angular velocity vector (x, y, z) of the vehicle in rad/s. This is expressed in the ego vehicle frame
acceleration: <float>[3]-Acceleration vector (x, y, z) in the ego vehicle frame in m/s/s. The z value is close to the gravitational acceleration `g = 9.81 m/s/s`
speed: <float>-The speed of the ego vehicle in the driving direction in m/s
}
log
有关提取数据的日志的相关信息。
log {
token: <str>-Unique record identifier
logfile: <str>-Log file name
vehicle: <str>-Vehicle name
date_captured: <str>-Date (YYYY-MM-DD)
location: <str>-Area where log was captured, e.g. singapore-onenorth.
}
object_ann
对图像中前景对象(汽车、自行车、行人)的注释。每个前景对象都带有一个2d框、一个2d实例掩码和特定类别的属性。
object_ann {
token: <str>-Unique record identifier
sample_data_token: <str>-Foreign key pointing to the sample data, which must be a keyframe image
category_token: <str>-Foreign key pointing to the object category
attribute_tokens: <str>[n]-Foreign keys. List of attributes for this annotation
bbox: <int>[4]-Annotated amodal bounding box. Given as [xmin, ymin, xmax, ymax]
mask: <RLE>-Run length encoding of instance mask using the pycocotools package
}
sample_data
Sample_data包含图像及其捕获时间的信息。Sample_data覆盖所有图像,不管它们是否是关键帧。只有关键帧被注释。对于每个关键帧,我们还包括多达6个过去和6个未来扫描在2赫兹。我们可以使用prev和next指针在连续的图像之间导航。样本时间戳继承自关键帧相机sample_data时间戳。
sample_data {
token: <str>-Unique record identifier
sample_token: <str>-Foreign key. Sample to which this sample_data is associated
ego_pose_token: <str>-Foreign key
calibrated_sensor_token: <str>-Foreign key
filename: <str>-Relative path to data-blob on disk
fileformat: <str>-Data file format
width: <int>-If the sample data is an image, this is the image width in pixels
height: <int>-If the sample data is an image, this is the image height in pixels
timestamp: <int>-Unix time stamp
is_key_frame: <bool>-True if sample_data is part of key_frame, else False
next: <str>-Foreign key. Sample data from the same sensor that follows this in time. Empty if end of scene
prev: <str>-Foreign key. Sample data from the same sensor that precedes this in time. Empty if start of scene
}
Smaple
Smaple是从日志中的大量图像池中选择的带注释的关键帧。每个样本最多有13个相机sample_data与之对应。其中包括关键帧,它可以通过key_camera_token访问。
sample {
token: <str>-Unique record identifier
timestamp: <int>-Unix time stamp
log_token: <str>-Foreign key pointing to the log
key_camera_token: <str>-Foreign key of the sample_data corresponding to the camera keyframe.
}
Sensor
sensor {
token: <str>-Unique record identifier
channel: <str>-Sensor channel name
modality: <str>-Sensor modality. Always "camera" in nuImages
}
Surface_ann
图像中背景对象的注释。每个背景对象都用二维语义分割掩码进行标注。
surface_ann {
token: <str>-Unique record identifier
sample_data_token: <str>-Foreign key pointing to the sample data, which must be a keyframe image
category_token: <str>-Foreign key pointing to the surface category
mask: <RLE>-Run length encoding of segmentation mask using the pycocotools package
}
Data annotation
在收集驾驶数据后,nuScenes数据集以2Hz的频率采样同步良好的关键帧(图像、LIDAR、RADAR),并将其发送给标注合作伙伴进行标注。使用专家注释器和多个验证步骤,实现了高度准确的注释。nuScenes数据集中的所有对象都有一个语义类别,以及一个3D边界框和它们出现的每一帧的属性。与2D边界框相比,可以准确地推断物体在空间中的位置和方向。nuScenes为23个对象类提供了基本真值标签。有关每个类和示例图像的详细定义,请参阅注释器说明。对于完整的nuScenes数据集,我们为以下类别(不包括测试集)提供注释:
对于nuScenes-lidarseg,我们用语义标签标注激光雷达点云中的每个点。除了来自nuScenes的23个前景类(东西),我们还包括9个背景类(东西)。有关每个类和示例图像的详细定义,请参阅nuScenes和nuScenes-lidarseg的注释器说明。我们为以下类别提供注释(不包括测试集):
| NO. | Category | nuScenes Cuboids | Cuboid Ratio | LidarSeg Points | Point Ratio |
|---|---|---|---|---|---|
| 1 | animal | 787 | 0.07% | 5385 | 0.01% |
| 2 | human.pedestrian.audlt | 208240 | 17.86% | 2156470 | 2.73% |
| 3 | human.pedestrian.child | 2066 | 0.18% | 9655 | 0.01% |
| 4 | human.pedestrian.construction_worker | 9161 | 0.79% | 139443 | 0.18% |
| 5 | human.pedestrian.personal_mobility | 395 | 0.03% | 8723 | 0.01% |
| 6 | human.pedestrian.police_officer | 727 | 0.06% | 9159 | 0.01% |
| 7 | human.pedestrian.stroller | 1072 | 0.09% | 8809 | 0.01% |
| 8 | human.pedestrian.wheelchair | 503 | 0.04% | 12168 | 0.02% |
| 9 | movable_object.barrier | 152087 | 13.04% | 9305106 | 11.79% |
| 10 | movable_object.debris | 3016 | 0.26% | 66861 | 0.08% |
| 11 | movable_object.pushable_pullable | 24605 | 2.11% | 718641 | 0.91% |
| 12 | movable_object.trafficcone | 97959 | 8.40% | 736239 | 0.93% |
| 13 | static_object.bicycle_rack* | 2713 | 0.23% | 163126 | 0.21% |
| 14 | vehicle.bicycle | 11859 | 1.02% | 141351 | 0.18% |
| 15 | vehicle.bus.bendy | 1820 | 0.16% | 357463 | 0.45% |
| 16 | vehicle.bus.rigid | 14501 | 1.24% | 4247297 | 5.38% |
| 17 | vehicle.car | 493322 | 42.30% | 38104219 | 48.27% |
| 18 | vehicle.construction | 14671 | 1.26% | 1514414 | 1.92% |
| 19 | vehicle.emergency.ambulance | 49 | 0.00% | 2218 | 0.00% |
| 20 | vehicle.emergency.police | 638 | 0.05% | 59590 | 0.08% |
| 21 | vehicle.motorcycle | 12617 | 1.08% | 427391 | 0.54% |
| 22 | vehicle.trailer | 24860 | 2.13% | 4907511 | 6.22% |
| 23 | vehicle.truck | 88519 | 7.59% | 15841384 | 20.07% |
| Total | 1166187 | 100.00% | 78942623 | 100.00% | |
| 1 | flat.driveable_surface | - | - | 316958899 | 28.64% |
| 2 | flat.other | - | - | 8559216 | 0.77% |
| 3 | flat.sidewalk | - | - | 70197461 | 6.34% |
| 4 | flat.terrain | - | - | 70289730 | 6.35% |
| 5 | static.manmade | - | - | 178178063 | 16.10% |
| 6 | static.other | - | - | 817150 | 0.07% |
| 7 | static.vegetation | - | - | 122581273 | 11.08% |
| 8 | vehicle.ego | - | - | 337070621 | 30.46% |
| 9 | noise | - | - | 2061156 | 0.19% |
| Total | - | - | 1106713569 | 100.00% | |
注:static_object.Bicycle_rack类别可以包括没有单独注释的自行车。在训练过程中,我们用它来忽略大量的共享单车,以避免我们的目标检测器偏向共享单车。此外,nuScenes中的某些类具有特殊属性:
| Attribute | Annotations |
|---|---|
| vehicle.moving | 149203 |
| vehicle.stopped | 65975 |
| vehicle.parked | 420226 |
| cycle.with_rider | 7331 |
| cycle.without_rider | 17345 |
| pedestrian.sitting_lying_down | 13939 |
| pedestrian.standing | 46530 |
| pedestrian.moving | 157444 |
| Total | 877993 |

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)