动手学深度学习笔记|3.1线性回归(附课后习题答案)
动手学深度学习笔记|3.1线性回归(附课后习题答案)
来源: myluster的github笔记,求个star说是
线性回归
- 回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。 在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
线性回归基于几个简单的假设:
- 首先,假设自变量X和因变量y之间的关系是线性的, 即y可以表示为X中元素的加权和,这里通常允许包含观测值的一些噪声;
- 其次,我们假设任何噪声都比较正常,如噪声遵循正态分布。
即有:
y ^ = w 1 x 1 + ⋯ + w d x d + b \hat{y} = w_1 x_1 + \dots + w_d x_d + b y^=w1x1+⋯+wdxd+b
y ^ \hat{y} y^为目标,
x 1 x_1 x1、 x 2 x_2 x2为特征,
w 1 w_1 w1、 w 2 w_2 w2为对应的权重(weight)
b b b为偏置(bias)、偏移量(offset)或截距(intercept),反映了噪声
严格来说上式是输入特征的一个仿射变换(affine transformation)。
仿射变换的特点是通过加权和对特征进行线性变换(linear transformation), 并通过偏置项来进行平移(translation)。
通过高等代数的知识我们自然可以将上式变为矩阵点积的形式来简洁的表达和便于数据访问,即
ŷ = X W + b
线性回归的目的就是为了寻找最好的模型参数W
为此我们需要两样工具:
- 【1】一种能度量模型质量的方式,如损失函数
- 【2】一种能根据模型质量更新模型以提高模型预测质量的方法,如随机梯度下降
虽然线性回归模型存在解析解,但并不是所有模型都有解析解,所以熟悉上面两种工具的思想对于掌握其他模型很有必要
解析解
此为在高等代数中学过的最小二乘问题,公式为:
W = (XT X)-1 XT y
注意:
- 【1】有解析解的条件为与特征矩阵X相关的XT X是可逆的
- 【2】计算复杂度:需要计算矩阵的逆,时间复杂度为O(n3),其中n是特征数量
- 【3】解析解适用于小规模数据集,对于大规模数据集,还是使用梯度下降等迭代方
损失函数(loss function)
- 用于量化目标的实际值与预测值之间的差距,通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。
- 回归问题中最常用的损失函数是平方误差函数:
L ( W , b ) = 1 n ∑ i = 1 n 1 2 ( y ^ ( i ) − y ( i ) ) 2 L(W,b)=\frac{1}{n}\sum_{i=1}^{n}\frac{1}{2}\left( \hat{y}^{(i)}-y^{(i)}\right)^2 L(W,b)=n1i=1∑n21(y^(i)−y(i))2
其中常数1/2不会带来本质上的差别,但是在形式上稍微简单一些,可以使对平方乡求导后的常数系数为1,方便后续梯度下降。
在训练模型时,我们的目的是找到一组参数(w_1,w_2,b)能最小化在所有训练样本上的总损失
随机梯度下降:
-
本书中我们用到一种名为梯度下降(gradient descent)的方法, 这种方法几乎可以优化所有深度学习模型。 它通过不断地在损失函数递减的方向上更新参数来降低误差。
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值) 关于各个模型参数的偏导数(其组成的向量为梯度)。
但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。 因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本, 这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)。
更新公式如下: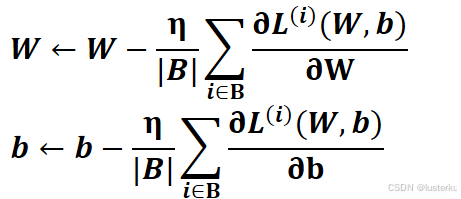
其中:- B代表每次随机均匀采样的一个由固定数目训练数据样本所组成的小批量(mini -batch)
- |B|代表每个小批量中的样本个数(batch size)
- η代表学习率(learning rate)并取正数,可以控制参数更新的幅度,避免更新过大(导致震荡)或过小(导致收敛慢)
-
思想:
- 【1】梯度的方向是函数值增长最快的方向,因此梯度的反方向指向函数值下降最快的方向
- 【2】为什么要除以批量大小:为了计算梯度的平均值而不是梯度的总和
-
值得注意的是这里批量大小和学习率的值是人为设定的,而不是通过模型训练得到的。
-
这些可以调整但不在训练过程中更新的参数称为超参数(hyperparameter)。
-
调参(hyperparameter tuning)是选择超参数的过程, 通常是根据训练迭代结果(或经验)来调整的。
-
在训练了预先确定的若干迭代次数后(或者直到满足某些其他停止条件后),我们停止训练。
从线性回归到神经网络初步:
- 神经网络图用来直观的表现模型结构,线性回归模型对应的图如下
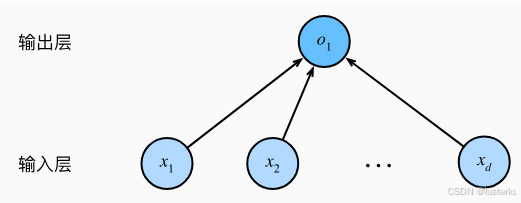
网络输入为X, 因此输入层中的输入数(或称为特征维度,feature dimensionality)为|X|。
网络的输出为O,因此输出层中的输出数是1。
需要注意的是,输入值都是已经给定的,并且只有一个计算神经元。 由于模型重点在发生计算的地方,所以通常我们在计算层数时不考虑输入层。 也就是说, 图中的神经网络的层数为1。
我们可以将线性回归模型视为仅由单个人工神经元组成的神经网络,或称为单层神经网络。
对于线性回归,每个输入都与每个输出(在本例中只有一个输出)相连, 我们将这种变换( 图中的输出层) 称为全连接层(fully-connected layer)或称为稠密层(dense layer)。
练习

如果有用求个star说是:myluster的github笔记

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)