手把手搭建 SQLAgent智能问答 ,自然语言直查数据库
还在为写 SQL 查询语句头疼?还在因不懂数据库结构而无从下手?今天教你用 LangChain 快速搭建SQL 智能问答 Agent,让 AI 替你完成「分析问题→生成 SQL→执行查询→返回结果」全流程,只需输入自然语言,就能直接查询 SQL 数据库,零基础也能轻松上手!
一、核心原理:SQL Agent 到底能做什么?
SQL Agent 是 LangChain 基于智能体能力打造的数据库交互工具,核心是让大模型结合数据库工具,模拟人类操作数据库的思维流程,无需手动写 SQL,实现自然语言与数据库的双向交互。
一个完整的 SQL Agent 工作流程包含 8 个核心步骤,全程自动化执行:
-
从数据库中获取所有可用的表和表结构;
-
分析用户自然语言问题,判断相关联的表;
-
提取关联表的详细 schema(字段、类型、主键外键等);
-
结合问题和表结构,生成语法正确的 SQL 查询语句;
-
调用大模型校验 SQL 语句,排查语法、关联错误等常见问题;
-
执行 SQL 语句,从数据库获取查询结果;
-
若执行报错,根据数据库引擎的错误信息修正 SQL,直至执行成功;
-
将查询结果整理成自然语言,返回给用户。
安全提醒
由于 Agent 会自动生成并执行 SQL,务必严格限制数据库连接的权限,仅赋予 Agent「查询(SELECT)」权限,禁止增删改(INSERT/UPDATE/DELETE/DROP)权限,降低模型驱动系统的固有风险。
二、前置准备:环境安装与配置
1. 安装核心依赖
本次实战需要 LangChain 核心包、数据库工具包、LangGraph(智能体流控)等,执行以下命令一键安装:
pip install langchain langgraph langchain-community
pip install -U "langchain[openai]"
pip install -U pymysql
pip install -U SQLAlchemy
三、分步实现:搭建 SQL 智能问答 Agent
步骤 1:初始化数据库
创建 部门表(dept)和员工表(emp)
create database testdb;
use testdb;-- 创建用户并授权CREATE USER IF NOT EXISTS 'sun'@'localhost' IDENTIFIED BY 'sun';GRANT SELECT ON testdb.* TO 'sun'@'localhost';FLUSH PRIVILEGES;DROP TABLE IF EXISTS dept;CREATE TABLE dept (dept_id INT AUTO_INCREMENT COMMENT '部门ID(主键)',dept_name VARCHAR(50) NOT NULL COMMENT '部门名称',dept_desc VARCHAR(200) DEFAULT '' COMMENT '部门描述',create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (dept_id),-- 确保部门名称唯一UNIQUE KEY uk_dept_name (dept_name)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='部门表'; DROP TABLE IF EXISTS emp; CREATE TABLE emp ( emp_id INT AUTO_INCREMENT COMMENT '员工ID(主键)',emp_name VARCHAR(50) NOT NULL COMMENT '员工姓名',gender CHAR(1) NOT NULL COMMENT '性别(男/女)',age TINYINT UNSIGNED NOT NULL COMMENT '年龄',phone VARCHAR(20) DEFAULT '' COMMENT '联系电话',email VARCHAR(100) DEFAULT '' COMMENT '邮箱',dept_id INT COMMENT '所属部门ID(外键)',hire_date DATE NOT NULL COMMENT '入职日期',salary DECIMAL(10,2) NOT NULL COMMENT '月薪',create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (emp_id),-- 外键关联部门表,保证员工所属部门必须存在CONSTRAINT fk_emp_dept FOREIGN KEY (dept_id) REFERENCES dept (dept_id)ON DELETE SET NULL -- 部门删除时,员工的部门ID设为NULLON UPDATE CASCADE -- 部门ID更新时,员工的部门ID同步更新) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工表';-- ------------------------------ 分别 插入测试数据-- ----------------------------INSERT INTO dept (dept_name, dept_desc) VALUES('研发部', '负责公司产品的研发和迭代'),('人事部', '负责人力资源管理、招聘、培训'),('财务部', '负责公司财务核算、资金管理'),('市场部', '负责市场推广、客户拓展'),('销售部', '负责产品销售、客户维护');INSERT INTO emp (emp_name, gender, age, phone, email, dept_id, hire_date, salary) VALUES('张三', '男', 30, '13800138000', 'zhangsan@company.com', 1, '2020-01-15', 15000.00),('李四', '女', 28, '13900139000', 'lisi@company.com', 1, '2021-03-20', 12000.00),('王五', '男', 35, '13700137000', 'wangwu@company.com', 2, '2018-05-10', 18000.00),('赵六', '女', 26, '13600136000', 'zhaoliu@company.com', 3, '2022-07-08', 10000.00),('孙七', '男', 40, '13500135000', 'sunqi@company.com', 4, '2015-09-01', 20000.00),('周八', '女', 32, '13400134000', 'zhouba@company.com', 5, '2019-11-12', 16000.00),('吴九', '男', 29, '13300133000', 'wJiu@company.com', NULL, '2023-01-05', 8000.00);
核心代码与提示词:
import ast
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain_community.agent_toolkits import create_sql_agent, SQLDatabaseToolkit
from langchain_community.tools import QuerySQLDatabaseTool
from langchain_community.utilities import SQLDatabase
BASE_URL = "http://localhost:11434/v1"
llm = init_chat_model(
model="qwen2.5:1.5b",
model_provider="openai",
base_url=BASE_URL,
api_key="EMPTY",
temperature=0
)
#
db_user = "sun"
db_password = "sun"
db_host = "localhost"
db_name = "testdb"
db = SQLDatabase.from_uri(f"mysql+pymysql://{db_user}:{db_password}@{db_host}/{db_name}")
toolkit = SQLDatabaseToolkit(db=db,
llm=llm)
# 自定义系统提示词,适配当前数据库方言和查询规则
system_prompt = """
# 角色定义
你是一个专业的SQL数据库查询智能体,专门用于与{dialect}数据库交互。核心任务:理解问题 → 生成SQL → 执行查询 → 返回结果。
# 工作流程(严格按顺序)
1. 【元数据发现】首先执行 `SHOW TABLES;` 查看可用表,禁止跳过
2. 【结构探查】查询 `information_schema.COLUMNS` 或 `DESCRIBE` 获取相关表字段信息
3. 【SQL生成】编写{dialect}查询语句:
- 仅选择问题相关列,禁止 `SELECT *`
- 默认添加 `LIMIT {top_k}`(用户指定数量时除外)
- 按需添加 `ORDER BY` 提升相关性
- 严禁使用DML语句(INSERT/UPDATE/DELETE/DROP/ALTER等)
4. 【预执行检查】验证语法、表名、字段名、权限
5. 【执行与容错】执行查询;若报错,分析修正后重试(最多2次)
6. 【结果返回】严格按下方格式输出
# 输出规范(强制遵守)
- ✅ 仅输出Python列表格式,元素为元组,每行数据对应一个元组:
[(val1_col1, val1_col2, ...), (val2_col1, val2_col2, ...), ...]
- ✅ 无结果时输出:`[]`
- ❌ 禁止输出:SQL语句、列名、解释、日志、Markdown、额外文字或标点
""".format(
dialect=db.dialect,
top_k=10
)
agent = create_agent(llm, tools, system_prompt=system_message)
resp = agent.invoke(input = {"messages": [{"role": "user", "content": "帮我查一下研发部有哪些员工?"}]})
for res in resp['messages']:
res.pretty_print()执行结果与日志:
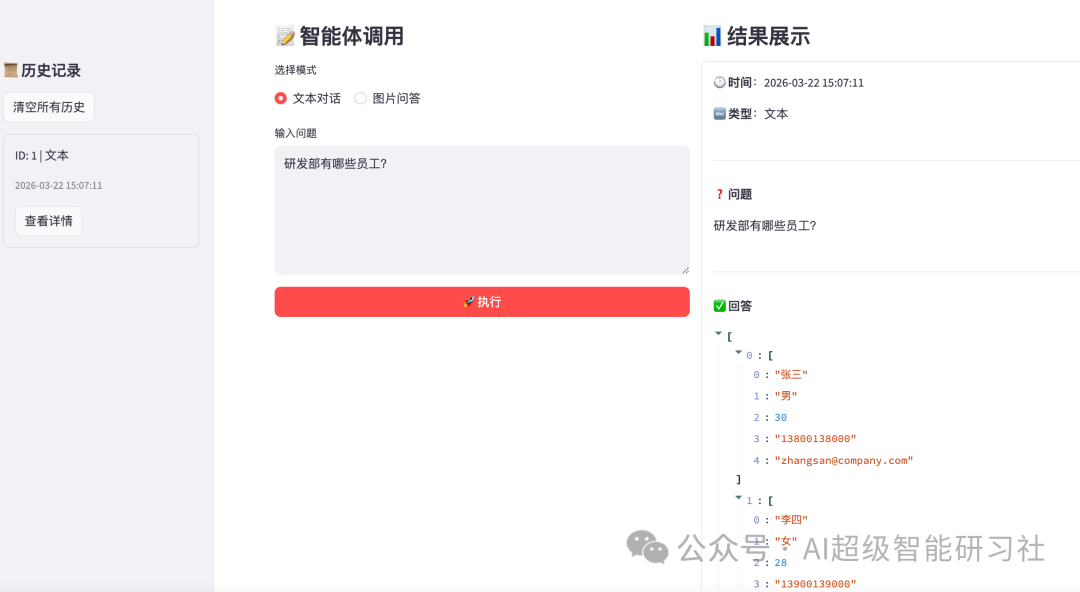
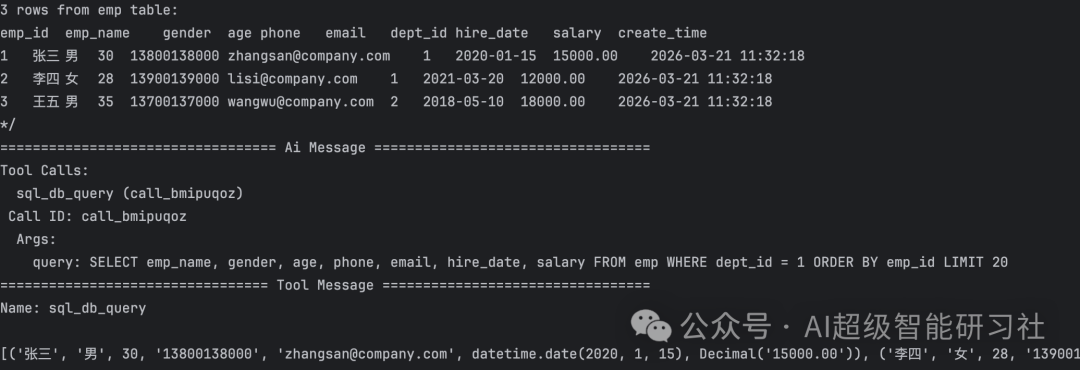
用sql验证一下

总结:
-
进行sqlagent开发主要使用了核心工具
SQLDatabaseToolkit封装了数据库交互的所有核心工具,无需手动开发。
SQL Agent 彻底打破了「自然语言」和「数据库」之间的壁垒,让不懂 SQL 的产品、运营、业务人员也能快速查询数据库数据,大幅提升数据获取效率。本次实战的代码可直接复用,只需根据自身需求替换数据库和大模型,即可快速落地到实际工作中。后续可结合可视化组件生成数据报表,关注我,解锁更多 AI 自动化实战技巧!


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)