深度学习篇---非自回归(Non-Autoregressive)
非自回归(Non-Autoregressive)详解
1. 什么是非自回归?
非自回归(Non-Autoregressive, NAR)是一种并行生成的序列建模方式,它打破了对已生成内容的依赖,一次性独立预测目标序列中的所有词。
生活类比:就像印刷报纸,不是逐字排印,而是一次性印出整版内容。或者像拍全家福,不需要一个个排队,而是所有人站好位,快门一按同时成像。
2. 为什么需要非自回归?
2.1 自回归的瓶颈
-
推理延迟高:必须串行生成,生成N个词需要N步
-
计算效率低:无法充分利用并行硬件
-
误差累积:前面出错会影响后面
2.2 非自回归的定位
自回归(AR) → 非自回归(NAR)
高质量、慢速度 快速度、质量待提升
↓ ↓
需要平衡 需要提升质量
↓ ↓
→→→→→ 半自回归 ←←←←←
平衡点
3. 非自回归的核心原理
3.1 条件独立性假设
自回归的联合概率分解:
P(Y|X) = P(y₁|X) × P(y₂|X,y₁) × P(y₃|X,y₁,y₂) × ...
非自回归的条件独立性假设:
P(Y|X) ≈ P(y₁|X) × P(y₂|X) × P(y₃|X) × ...
即每个词的生成只依赖于源输入,不依赖于其他目标词。
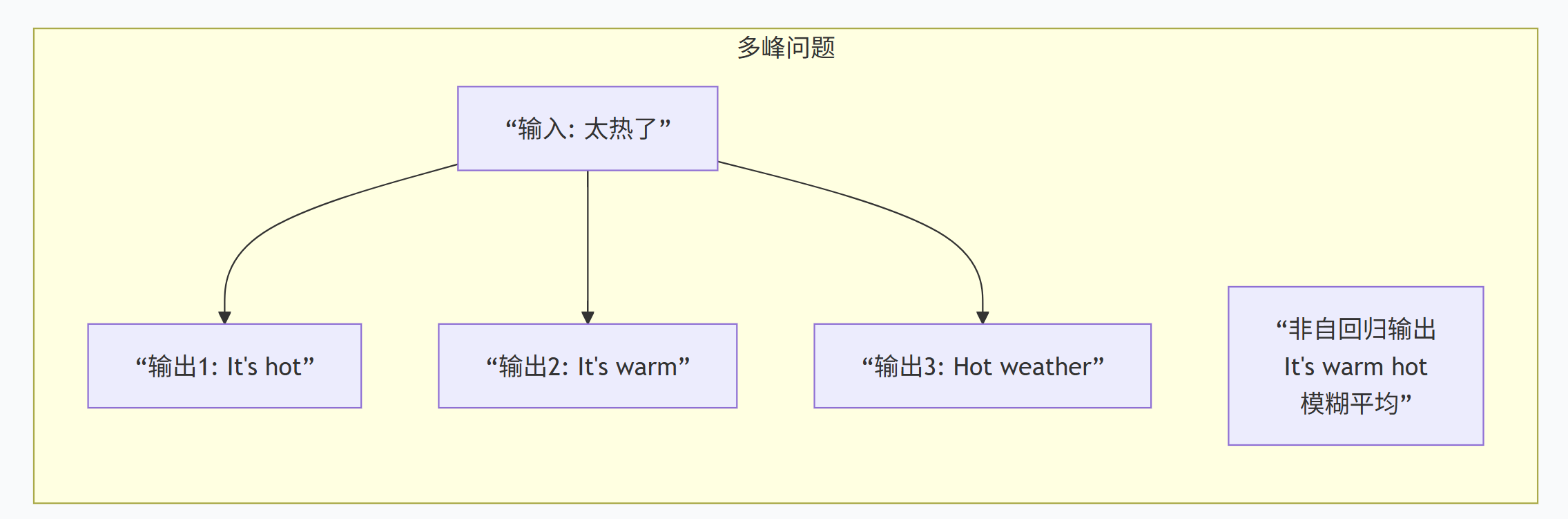
3.2 核心挑战
-
多峰问题:一个源输入可能对应多个合理翻译
-
模态平均:模型可能输出模糊的平均值
-
长度预测:需要先预测输出序列长度
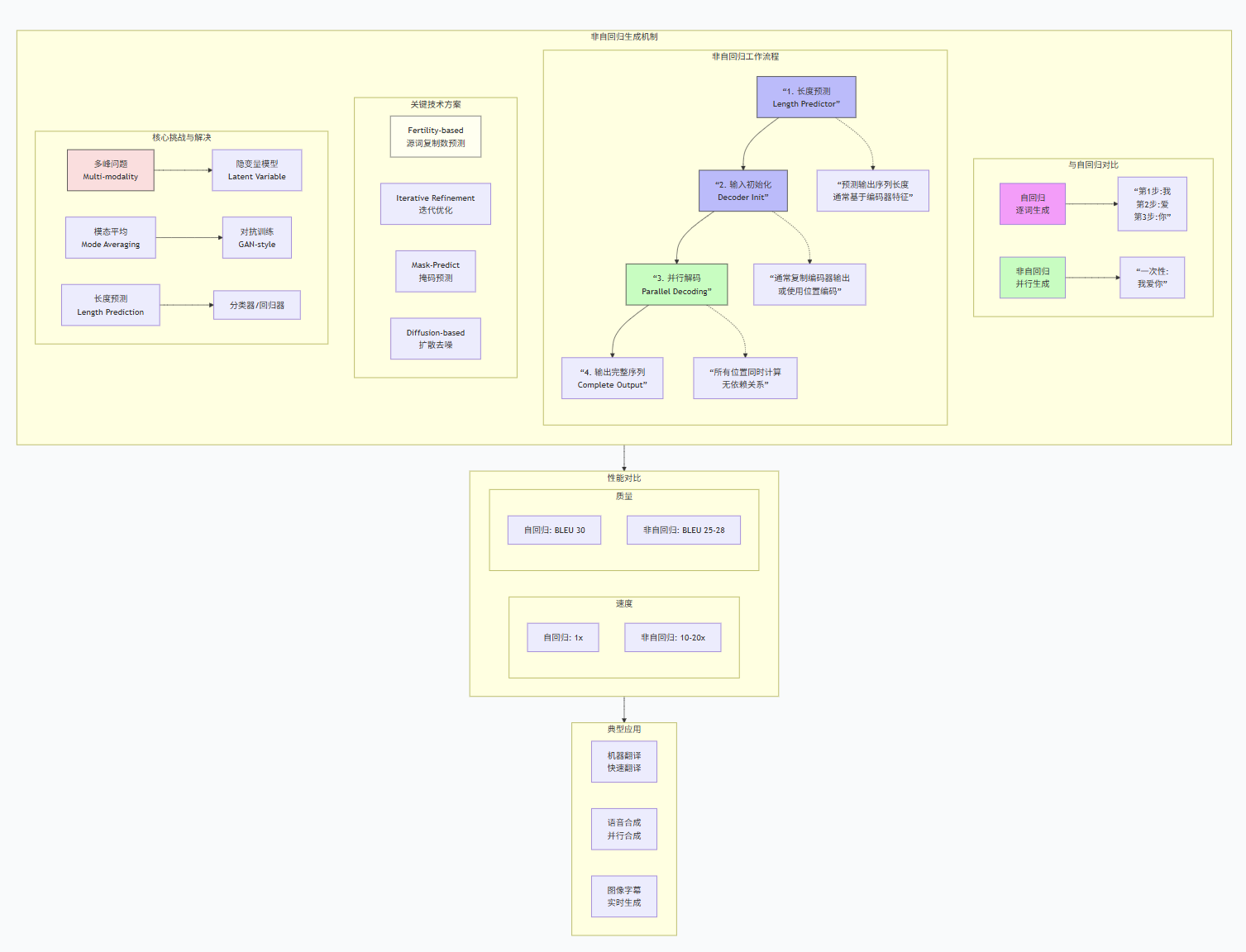
4. 非自回归的实现方式
4.1 基础架构
# 伪代码:非自回归生成过程
def non_autoregressive_generate(encoder_output, max_length):
# 1. 预测序列长度
length = length_predictor(encoder_output)
# 2. 初始化所有位置的输入(通常是复制编码器输出)
decoder_input = initialize_decoder_input(length)
# 3. 并行生成所有词
all_tokens = decoder(decoder_input, encoder_output)
# 4. 一次输出完整序列
return all_tokens # [length] 所有词同时生成4.2 主流方法对比
| 方法 | 核心思想 | 代表工作 |
|---|---|---|
| Fertility-based | 预测每个源词生成几个目标词 | Non-Autoregressive Transformer (NAT) |
| Iterative Refinement | 多次迭代优化 | Iterative Refinement NAT |
| Mask-based | 掩码预测 + 并行解码 | Mask-Predict |
| Diffusion-based | 扩散过程逐步去噪 | DiffuSeq |
5. 非自回归的技术细节
5.1 Fertility模型
源词: I love you Fertility: [1, 1, 1] → 一对一翻译 源词: 我喜欢你 Fertility: [1, 1, 1] # "我"→"I","喜欢"→"like","你"→"you" 源词: 中华人民共和国 Fertility: [1, 2] # "中华"→"China","人民共和国"→"People's Republic"
5.2 迭代精炼过程
第1轮: 我 * * * * (随机初始化) 第2轮: 我爱 * * * (基于置信度选择) 第3轮: 我爱中 * * (逐步填充) 第4轮: 我爱中国 (完成)
5.3 Mask-Predict机制
def mask_predict_step(current_sequence, confidence_scores):
# 1. 掩码低置信度的位置
mask_positions = get_low_confidence_positions(confidence_scores)
# 2. 并行预测被掩码的位置
masked_sequence = apply_mask(current_sequence, mask_positions)
new_predictions = model(masked_sequence)
# 3. 更新序列和置信度
return update_sequence(new_predictions)6. Mermaid总结框图
7. 典型模型详解
7.1 NAT (Non-Autoregressive Transformer)
架构特点:
编码器: 标准Transformer编码器 解码器: 修改版(无自回归掩码) 长度预测器: 基于编码器输出预测目标长度 Fertility预测器: 预测每个源词的复制次数
训练过程:
# 训练时已知目标长度和fertility
fertility = fertility_predictor(encoder_output)
decoder_input = repeat_source_by_fertility(source, fertility)
output = decoder(decoder_input, encoder_output)7.2 Mask-Predict (BERT-like Generation)
核心思想:
# 多轮迭代
for step in range(iterations):
# 掩码比例逐渐降低
mask_ratio = 1.0 - step / iterations
# 掩码低置信度位置
to_mask = select_low_confidence(current_output, mask_ratio)
masked_input = mask_positions(current_output, to_mask)
# 并行预测
predictions = model(masked_input)
# 更新
current_output = update_predictions(predictions, to_mask)8. 非自回归的变体演进
| 时间 | 模型 | 创新点 | 质量提升 |
|---|---|---|---|
| 2018 | NAT | 首次提出非自回归 | BLEU -8 |
| 2019 | Iterative NAT | 迭代优化 | BLEU -4 |
| 2020 | Mask-Predict | 掩码策略 | BLEU -2 |
| 2021 | GLAT | 对齐训练 | BLEU -1 |
| 2022 | DiffuSeq | 扩散模型 | 接近AR |
9. 非自回归的应用场景
9.1 适合场景
-
实时翻译:需要低延迟
-
大规模部署:节省计算资源
-
短文本生成:长度较短的序列
-
对质量要求适中的场景
9.2 不适合场景
-
长文本生成:容易丢失一致性
-
对话系统:需要强上下文依赖
-
故事生成:需要长程连贯性
10. 通俗理解总结
把非自回归想象成"多人同时作画":
-
自回归模式:一位画家逐笔作画,每一步都要参考已画的部分
-
非自回归模式:多位画家同时作画,每人画一部分,最后拼接成完整画作
三种生成模式的直观对比:
| 模式 | 烹饪类比 | 速度 | 质量 | 适用场景 |
|---|---|---|---|---|
| 自回归 | 逐道烹饪 | 慢 | 高 | 精致法餐 |
| 半自回归 | 批量备菜 | 中 | 中高 | 家庭聚餐 |
| 非自回归 | 自助餐 | 快 | 中 | 快餐 |
为什么非自回归质量会下降?
解决方案的关键洞察:
非自回归的核心挑战在于如何在不知道邻居的情况下,做出正确的局部决策。就像拼图时不看相邻片,全靠图案特征判断位置。现代NAR模型通过各种技巧(隐变量、迭代优化、掩码预测)让模型能够在不完全依赖上下文的情况下,仍然做出合理预测。
随着技术的发展,非自回归模型正在逐步缩小与自回归的质量差距,同时保持其速度优势,成为低延迟场景下的重要选择。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 27
27 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)