MHAF-YOLO:用于精确目标检测的多分支异构辅助融合YOLO
点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
https://arxiv.org/pdf/2502.04656
本工作的源代码可在以下地址获取:https://github.com/yang-0201/MHAF-YOLO。
计算机视觉研究院专栏
Column of Computer Vision Institute
有效杂草管理对保障棉花生产中的作物产量至关重要,但传统深度学习方法在检测小型或被遮挡的杂草时往往表现不佳,且可能受限于大量的参数。

PART/1
概述
由于路径聚合FPN(PAFPN)具备有效的多尺度特征融合能力,它已成为基于YOLO的检测器中广泛采用的组件。然而,PAFPN难以将高层语义线索与低层空间细节整合,这限制了其在实际应用中的性能,尤其是在存在显著尺度变化的场景中。在本文中,我们提出了MHAF-YOLO,这是一种新颖的检测框架,其特征在于采用了名为多分支辅助FPN(MAFPN)的多功能颈部设计,该设计由两个关键模块组成:表层辅助融合(SAF)和高级辅助融合(AAF)。SAF通过融合浅层特征连接骨干网络和颈部,以高保真度有效传递关键的低层空间信息。同时,AAF在颈部较深的层整合多尺度特征信息,为输出层提供更丰富的梯度信息,进一步增强模型的学习能力。为了补充MAFPN,我们引入了全局异构灵活核选择(GHFKS)机制和重参数化异构多尺度(RepHMS)模块来增强特征融合。RepHMS被全局集成到网络中,利用GHFKS为不同特征层选择更大的卷积核,扩大垂直感受野并捕获跨空间层次的上下文信息。在局部层面,它通过在同一层中处理大小核来优化卷积,拓宽横向感受野并保留检测较小目标的关键细节。MHAF-YOLO的小型版本在COCO数据集上仅用710万参数就实现了48.9%的AP,与YOLO11s相比参数量减少了24.4%,同时性能提升了1.9%。此外,我们的模型在实例分割和旋转目标检测任务中均表现出卓越的性能和泛化能力。
PART/2
背景
近年来,人们开发了多种算法以实现高性能的实时目标检测。其中,从YOLOv1到YOLOv12的一系列YOLO算法,由于在速度和精度之间取得了平衡,发挥着日益重要的作用。
特征金字塔网络(FPN)采用自上而下的架构,用高层语义信息丰富低层特征,有效生成多尺度特征图。在FPN的基础上,路径聚合特征金字塔网络(PAFPN)引入了自下而上的路径,使低层的精确定位信息能更有效地向上传递。这一改进提升了特征金字塔的整体定位能力。此外,由于其直接高效的融合机制,PAFPN在YOLO系列模型中得到了广泛应用。在图1(a)中,P2-P5层代表骨干网络不同层级的输出信息。YOLO系列的颈部结构采用传统的PAFPN,该结构包含两条主要路径用于多尺度特征融合。然而,我们发现PAFPN仍存在两个显著的局限性。
首先,PAFPN结构主要侧重于融合相似尺度的特征图,但在有效处理和整合来自不同分辨率层的多尺度信息方面存在不足。这种保守的特征融合方法可能会阻碍模型在不同层级间充分交互的能力,有可能导致深层细节信息的丢失,并在每个尺度上产生过于简化的结果。例如,在PAFPN的Block1中,输入将上采样的P5层与相邻的P4层融合,忽略了P3层中存在的关键浅层、低层空间细节。类似地,在Block2中,明显缺乏与P2层的直接融合,而P2层对于捕捉小目标细节至关重要。这一缺陷在Block3和Block4中也很明显,限制了特征融合过程的整体有效性。
其次,小目标检测层的架构策略是通过单一的自上而下路径和两个相关模块来设计的。这种配置大大削弱了模型有效学习和表示小目标特征的能力,因为小目标检测层缺乏来自额外特征层的足够补充信息。此外,PAFPN中的每个特征提取模块通常由改进的跨阶段局部网络(CSPNet)和固定的3×3卷积组成,这限制了网络的灵活性,并使其捕获更大感受野的能力受到局限。在实际应用中,这些局限性可能导致PAFPN在同时分布有不同尺度目标的场景或密集小目标场景中表现不佳。例如,在图1(b)和(c)中,采用PAFPN的YOLOv10模型对密集小人群的激活水平明显低于本文提出的MAFPN。
我们开展了大量实验以验证MHAF-YOLO的有效性,对模型规模进行调整,提供了lite-nano、nano、small和medium等变体,以适应不同的应用场景。如图2所示,MHAF-YOLO在参数更少、计算成本更低的情况下实现了最高精度,超越了所有最先进(SOTA)的YOLO检测器。这种降低的计算负载在计算资源有限的设备上尤为宝贵。本文的主要贡献总结如下:
l我们提出了一种新的即插即用颈部结构,称为多分支辅助FPN(MAFPN),以实现更丰富的特征交互与融合。在MAFPN中,表层辅助融合(SAF)通过双向连接保留浅层骨干网络信息,增强网络对小目标的检测能力。此外,高级辅助融合(AAF)通过多向连接丰富输出层的梯度信息。而且,MAFPN可无缝集成到任何其他检测器中,以增强其多尺度表示能力。
l我们设计了重参数化异构多尺度(RepHMS)模块,具有高参数利用率。该模块通过将大核卷积与多个小核卷积并行化,在不增加额外推理成本的同时扩大感知范围,并保留小目标信息。RepHMS可无缝集成到骨干网络或FPN中,提升任何网络的性能。
l我们提出了全局异构灵活核选择(GHFKS)机制,通过调整网络不同分辨率特征层中RepHMS的核大小,自适应地扩大整个网络的有效感受野。
多分支异构辅助融合YOLO(MHAF-YOLO)凭借其极高的参数利用率,在COCO数据集的目标检测任务中实现了最先进的性能,超越了现有实时目标检测器。此外,MHAF-YOLO在实例分割和旋转目标检测任务中表现出卓越性能,展现出其强大的泛化能力。
PART/3
新算法框架解析
宏观架构
如图4所示,我们将单阶段目标检测器的宏观架构分解为三个主要组件:骨干网络、颈部和头部。在提出的MHAF-YOLO中,输入图像首先经过骨干网络,该骨干网络包含四个阶段:P2、P3、P4和P5。MAFPN被设计为颈部结构。在第一条自底向上的路径中,SAF模块负责从骨干网络中提取多尺度特征,并在颈部的浅层进行初步辅助融合。同时,AAF通过第二条自上而下路径中的密集连接从每个深层收集梯度信息,最终引导头部在三种分辨率下获取多样化的输出信息。上述两种结构均采用RepHMS模块进行特征提取,无缝集成GHFKS概念,以利用动态尺寸的卷积核,在不同层实现自适应感受野。最后,检测头基于每个尺度的特征图预测目标边界框及其对应类别,以计算其损失。
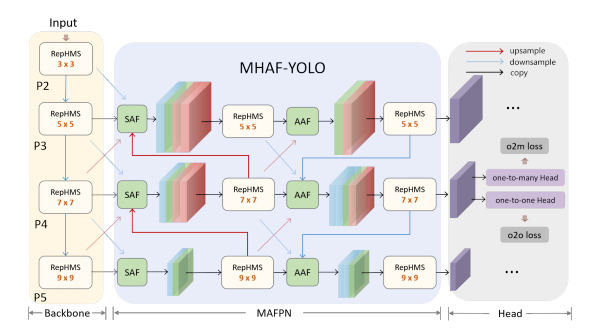
图4
全局自适应异构灵活核选择机制
Transformer 有效性的一个重要因素是其自注意力机制,该机制在全局或更大的窗口尺度上执行查询-键-值操作。类似地,大卷积核可捕获局部和全局特征,多项研究已证明,使用适度大的卷积核来增加有效感受野是有效的。Trident Network的研究表明,具有更大感受野的网络更适合检测较大的目标,反之,较小尺度的目标则受益于较小的感受野。YOLOMS引入了异构核选择(HKS)协议的概念,在骨干网络中采用3、5、7和9的递增卷积核设计,以平衡性能和速度。受此工作启发,我们将其扩展为全局异构灵活核选择(GHFKS)机制,将异构大卷积核的概念整合到整个MHAF-YOLO架构中。除了骨干网络RepHMS中逐渐增大的卷积核外,我们还在MAFPN中引入5、7和9的大卷积核,以适应不同分辨率的需求,从而逐步获取多尺度感受野信息。
多分支辅助FPN
精确的定位依赖于浅层网络的详细边缘信息,而精准的分类则需要深层网络捕获粗粒度信息。我们认为,一个有效的FPN应支持浅层和深层网络信息流的充分且足够的融合。
表层辅助融合
在骨干网络中保留浅层空间信息对于增强小目标的检测能力至关重要。然而,骨干网络提供的信息相对基础,且易受干扰。因此,我们将浅层信息作为辅助分支融入更深的网络,以确保后续层学习的稳定性。遵循这些原则,我们开发了SAF模块,如图5所示。
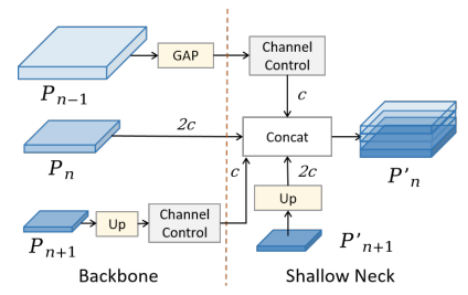
图5
SAF的主要目标是将深层信息与骨干网络内多尺度特征层中嵌入的浅层空间信息相融合,旨在保留丰富的定位细节,从而增强网络的空间表示能力。此外,我们利用1×1卷积来控制浅层信息的通道数,确保其在拼接(concat)操作中占比更小,同时不影响后续学习。应用SAF后的输出结果如下:
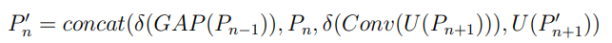
高级辅助融合
为进一步增强特征层信息的交互利用,我们在MAFPN的更深层中采用AAF模块以实现多尺度信息整合。
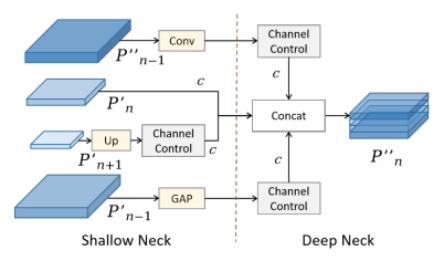
具体而言,图6展示了AAF连接,其涉及浅层高分辨率层、浅层低分辨率层、同级浅层以及前一层之间的信息聚合。此时,最终输出层P4可同时融合来自四个不同层的信息,从而显著提升中型目标的检测性能。AAF同样采用1×1卷积来控制通道数,以调节每一层对结果的影响。通过实验我们发现,当采用SAF中的策略(即把三个浅层的通道数设为深层通道数的一半)时,性能会略有下降。借鉴FPN的传统单路径架构,我们推测初始引导信息已嵌入MAFPN的浅层中。因此,我们将各层的通道数设置为相同,以确保模型获得多样化的输出。应用AAF后的输出结果如下:
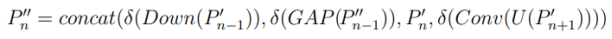
重参数化异构多尺度模块
在前一节设计了MAFPN结构之后,另一个挑战在于在整个架构中高效设计特征提取块。本节介绍一种强大的编码器架构设计,它能高效学习具有表现力的多尺度特征表示,且具有极高的参数利用率。RepHMS的结构如图7(a)所示。
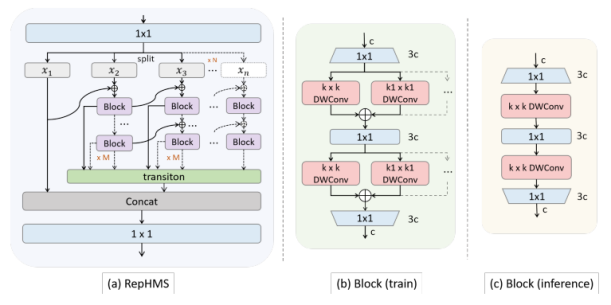
图7
首先,输入信息经过1×1卷积和分割(Split)操作,产生N条信息流。第一个分支保留原始浅层信息。从第二个分支开始,输入信息通过M个串联的块来增强特征提取能力。融入ELAN的思想,每个块的输出都被保留并整合到最终输出层中。此外,每个分支都包含级联概念,使得即使是并行分支也能接收来自前一个分支的浅层信息,从而丰富梯度流。最后一个分支输出最深层的信息,最终的拼接和1×1卷积操作整合并输出不同分支的信息。通过调整系数M和N,我们可以轻松控制RepHMS的特征提取能力。RepHMS尽可能保留每个分支中的梯度流信息,同时通过级联连接逐步整合来自前一层的更深信息。随着过程的持续,分支中的信息变得越来越多样化,特征提取也变得更加彻底,将信息表示优化到极致。因此,RepHMS模块可以无缝集成到任何先进的检测器中,显著提升其性能。
如图7(b)所示,每个块由若干深度可分离(DW)卷积组成,并结合先进的重参数化技术以实现高参数效率。第一个1×1卷积用于扩展通道数,每个RepHConv后跟着一个逐点卷积,以弥补深度可分离卷积的性能损失。最终的卷积用于缩放通道数。
重参数化异构深度可分离卷积
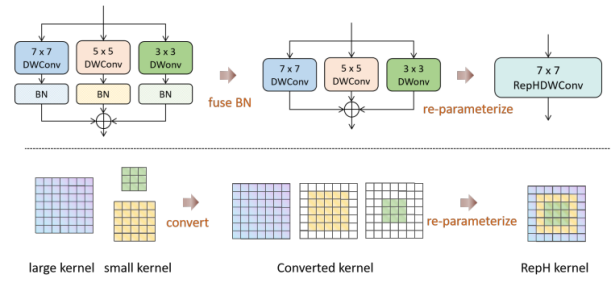
首先,我们在全局架构中采用大核深度可分离卷积来实现上述GHFKS机制。我们的研究还表明,虽然更大的卷积核可能通过编码更广泛的区域来提升性能,但它们可能会无意中掩盖与小目标相关的细节,因此存在进一步改进的空间。因此,我们将异构思想从全局架构转移到单个卷积中,并融入重参数化思想以实现RepHConv。具体而言,我们通过同时运行大小不同的卷积核来补充对小目标的检测。不同尺寸的卷积核既增强了网络的有效感受野(ERF),又丰富了特征的多样化表示。
如图7(b)和(c)所示,该模块在训练和推理阶段存在一定差异。在训练时,网络并行运行n个不同尺寸的深度可分离卷积(DWConv)操作;而在推理时,这些卷积会被合并为一个,因此不会降低推理速度。我们认为RepHDWConv是一种更优的卷积策略,能够在损失极小的情况下增强多尺度下的表示能力。
图8展示了7×7 RepHDWConv的重参数化步骤。
PART/4
实验及可视化
表6
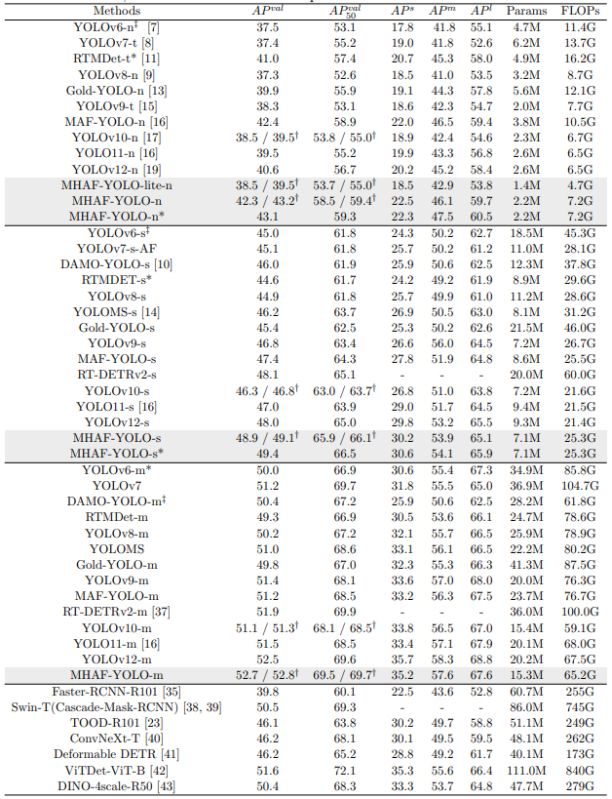
表6展示了我们提出的MHAF-YOLO与其他最先进的实时目标检测器的对比结果。我们首先将MHAF-YOLO与其基线模型(即YOLOv10)进行对比。在N/S/M三种变体上,我们的模型实现了3.8%/2.6%/1.6%的AP提升,同时参数更少。与其他YOLO模型相比,MHAF-YOLO在精度和计算成本之间也表现出更优的权衡。例如,与Gold-YOLO相比,MHAF-YOLO在参数利用方面展现出非凡的效率,MHAF-YOLO N/S/M的参数数量比Gold-YOLO少60%/67%/63%,但仍实现了2.4%/3.5%/2.9%的性能提升。对于更小规模的模型,我们的模型也具有显著优势,与YOLOv6-n、YOLOv7-t、YOLOv8-n、YOLOv9-t、YOLOv10-n相比,MHAF-YOLO-lite-nano模型在参数上减少了30%到77%,计算需求减少了30%到66%,同时保持了相当的平均精度(AP)分数,展现出显著的轻量化潜力。与最新的YOLO11相比,我们的三尺度模型参数更少,但分别以2.8%、1.9%和1.2%的优势超过YOLO11-n、YOLO11-s和YOLO11-m。这凸显了我们的模型在以最少资源消耗实现高性能方面的卓越性,使其成为效率和紧凑性至关重要的应用的理想选择。此外,我们还展示了在一些两阶段和基于Transformer的检测器中,我们的模型表现更优且更轻量化。此外,得益于MAFPN和多尺度感受野模块,我们的模型在多尺度目标检测方面显著优于其他模型。
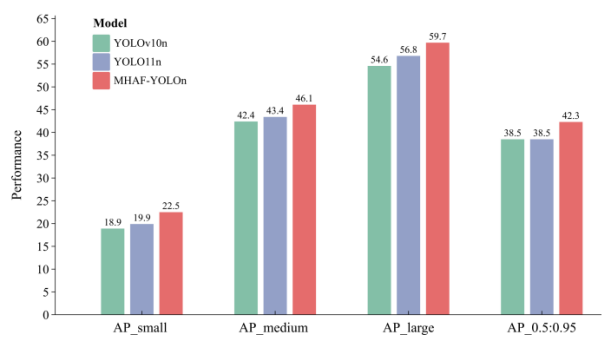
图9
如图9所示,我们以柱状图呈现了三种不同尺度目标的检测性能,其中MHAF-YOLO在所有指标上均持续优于YOLOv10和YOLO11。不同算法在COCO验证集上的部分检测结果如图10所示。

图10
表9
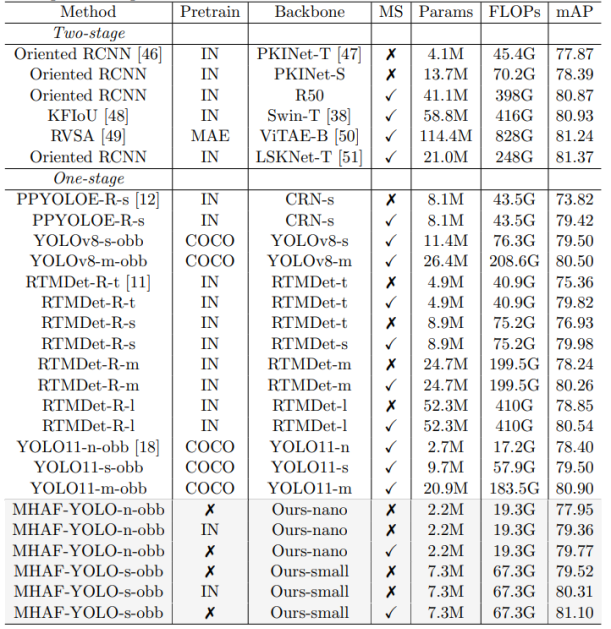
在表9中,我们在DOTA-v1.0数据集上对比了MHAF-YOLO-obb与之前的最先进方法。在单尺度训练和推理时,模型面临更复杂的小目标检测问题。MHAF-YOLO-n-obb和MHAF-YOLO-s-obb分别实现了79.36%和80.31%的mAP,分别超越了几乎所有单尺度方法。具体而言,我们的nano模型仅用约RTMDet-R-l模型1/20的参数和计算成本,就实现了0.51%的性能提升,最终达到79.36%的AP。在没有ImageNet预训练的情况下,我们的small模型也达到了79.52%的AP,以46.7%的参数减少量,超越了采用最先进骨干PKINet-S的O-RCNN方法1.13%。在多尺度训练和测试中,YOLOv8和YOLO11采用COCO预训练策略,显著提升了性能。在相同的COCO训练策略下,我们未预训练的MHAF-YOLO-n-obb仍分别比YOLO11-n-obb和YOLO11-s-obb高出1.37%和0.27%。我们的MHAF-YOLO-s-obb在多尺度设置下实现了81.10%的AP,几乎与最先进的旋转目标检测方法相当。例如,RVSA需要一个极其庞大的模型并在大规模数据集上预训练才能勉强超过81 AP。与最先进的方法LSKNet-T相比,我们的模型在参数数量和计算成本上均显示出明显优势。我们相信,通过更强的预训练和在旋转目标检测方面的进一步优化,我们的模型未来可以实现更先进的性能。
有相关需求的你可以联系我们!


END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
往期推荐
🔗

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 12
12 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)