刘二大人PyTorch深度学习实践第12讲循环神经网络
·
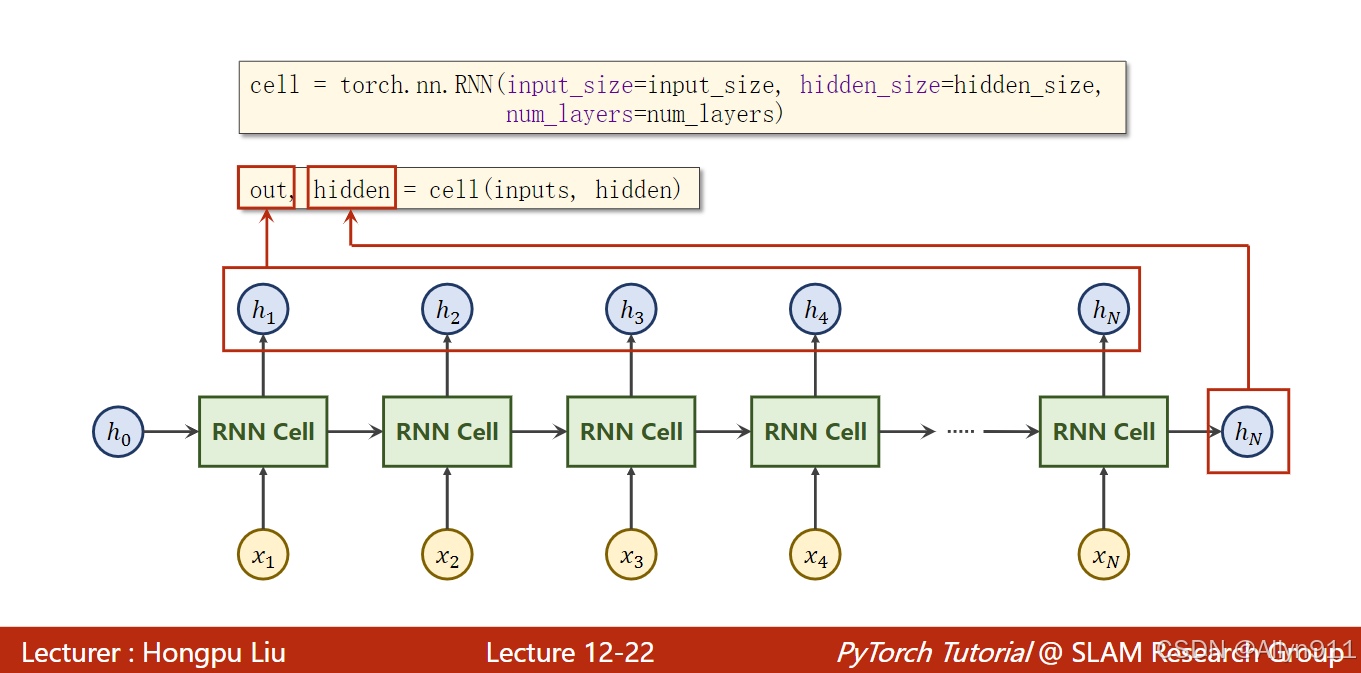
- RNN输入输出参数
如图所示,input输入维度,hidden隐层维度,output输出维度
注:seqSize=seqLen,即序列长度

当batch_first=True时,input维度顺序改变,如图所示

输出为out和hidden,out为所有隐层数据,即h1-hn;hidden为最后一层隐层数据,即hn
- nn.Embedding
将高维、稀疏的独热编码映射到低维、稠密的空间里(即降维)
深入理解PyTorch中的nn.Embedding的使用 / 张生荣
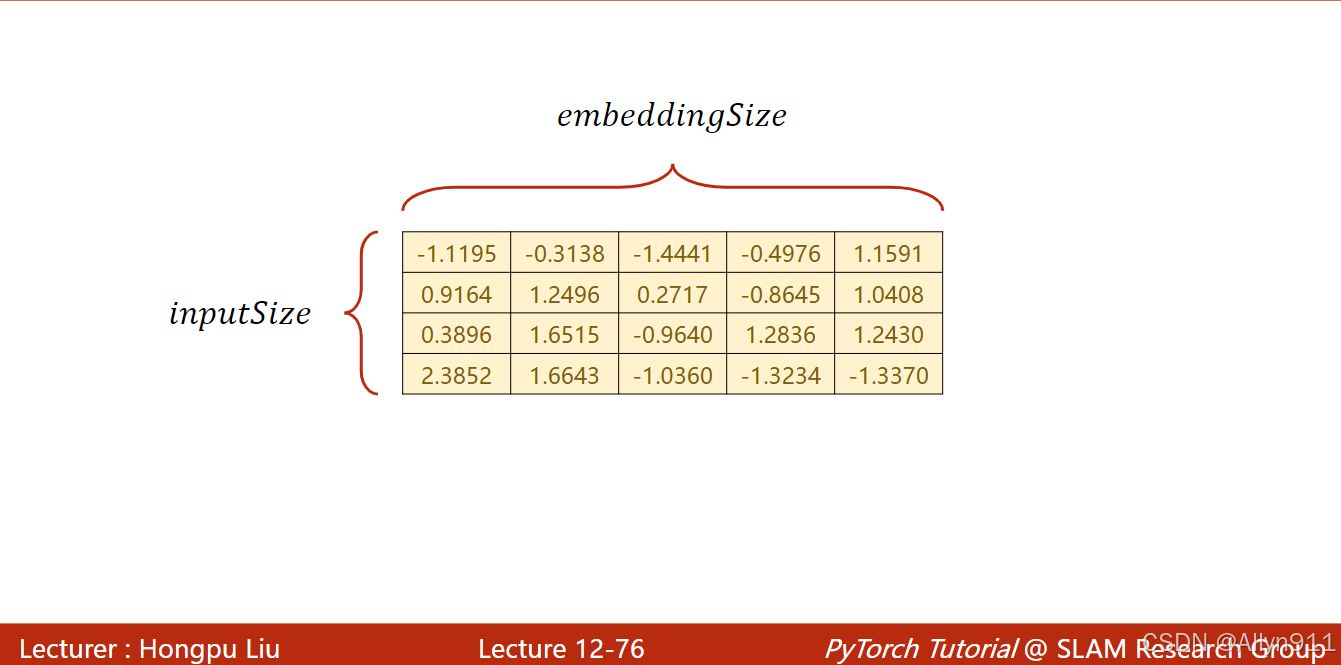
实质是一张查找表,映射关系如图所示:
输入参数如图所示:
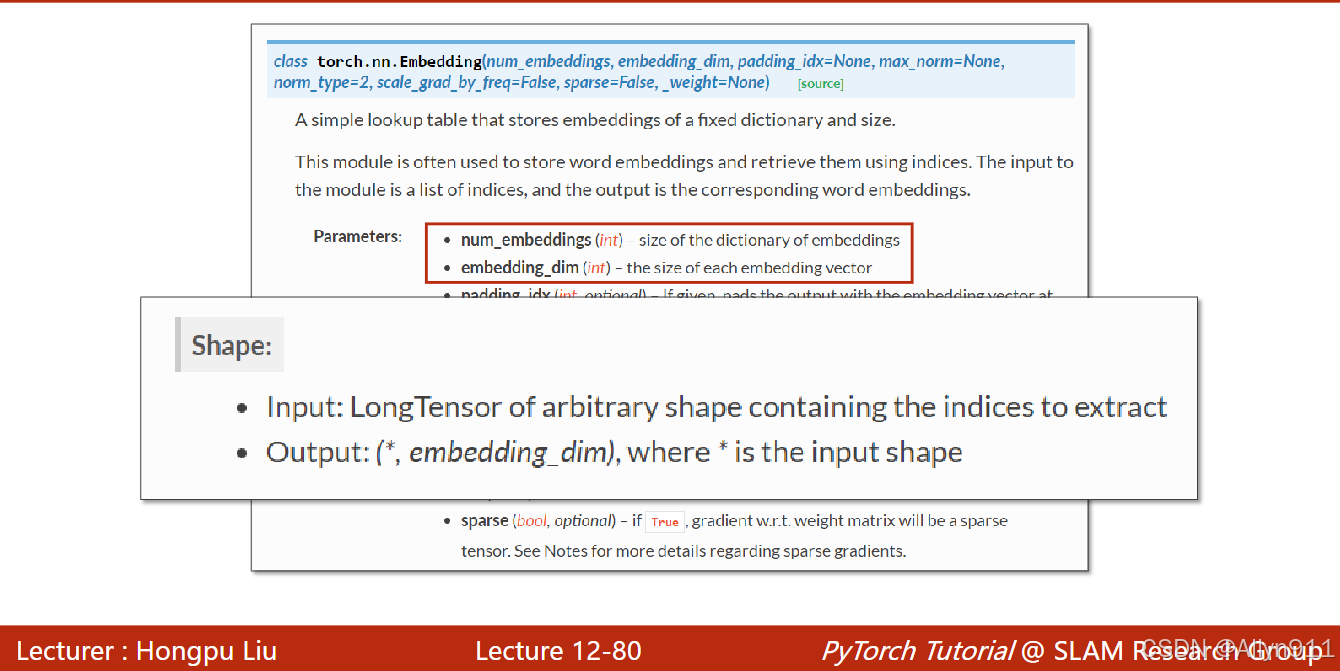
embedding_dim大小的设置原则:
【PyTorch单点知识】torch.nn.Embedding模块介绍:理解词向量与实现-CSDN博客
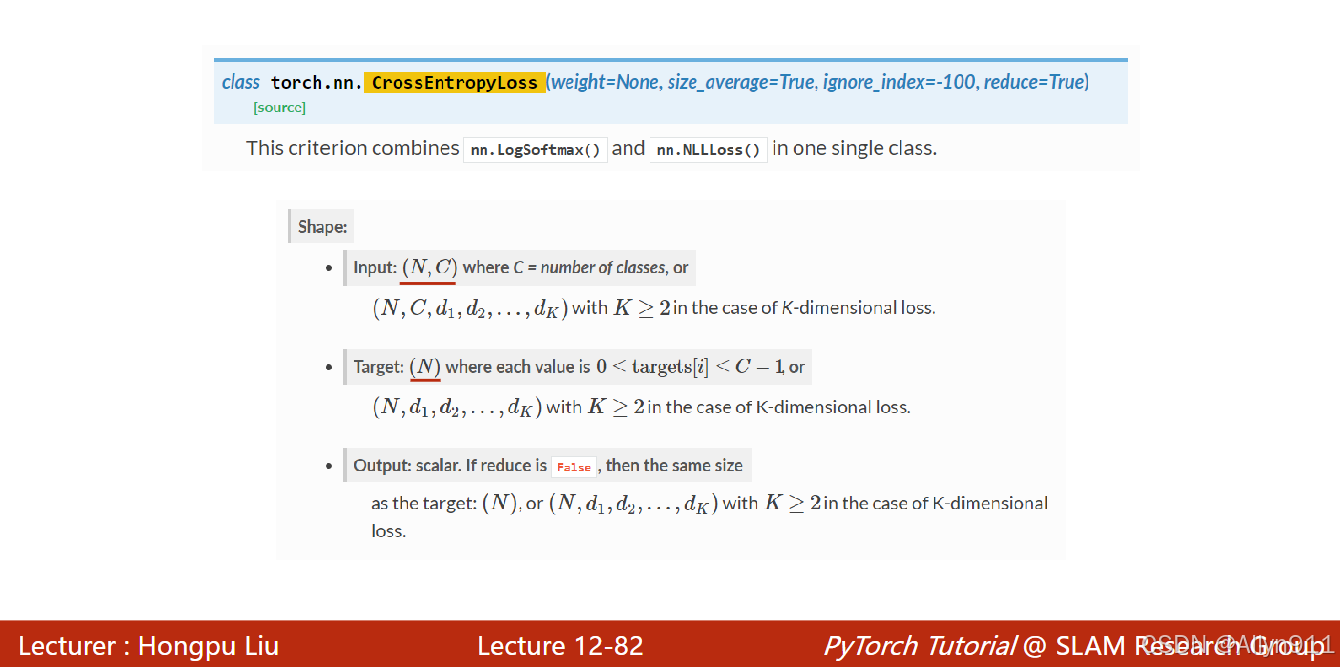
- 交叉熵损失的参数维度要求
- 代码
# 循环神经网络 训练模型:‘hello’→‘ohlol’
import torch
input_size = 4 # 输入大小
hidden_size = 8 # 隐藏层大小
batch_size = 1
num_layers = 2 # RNN层数
seq_len = 5 # 序列长度 x1,x2,x3,x4,x5
embedding_size = 10 # embedding大小
num_class = 4 # 最终输出的类别数
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]] # size:[1,5,4] (batch_size,seq_len,input_size)
y_data = [3, 1, 2, 3, 2] # size:[5]
# nn.Embedding要求输入是LongTensor型
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
class model(torch.nn.Module):
def __init__(self):
super(model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers,
batch_first=True)
# batch_first=True时,input维度为(batch_size,seq_len,input_size),否则为(seq_len,batch_size,input_size)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
# x由[1,5,4]->[5,4],为了符合之后的CrossEntropyLoss的参数维度要求
return x.view(-1, num_class)
net = model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
outputs = net(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1) # 选择每一列(dim=0)/行(dim=1)的最大值,输出为(值,索引)
idx = idx.data.numpy()
print('Predicted:', ''.join([idx2char[x] for x in idx]), end='')
print(',Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
- 结果

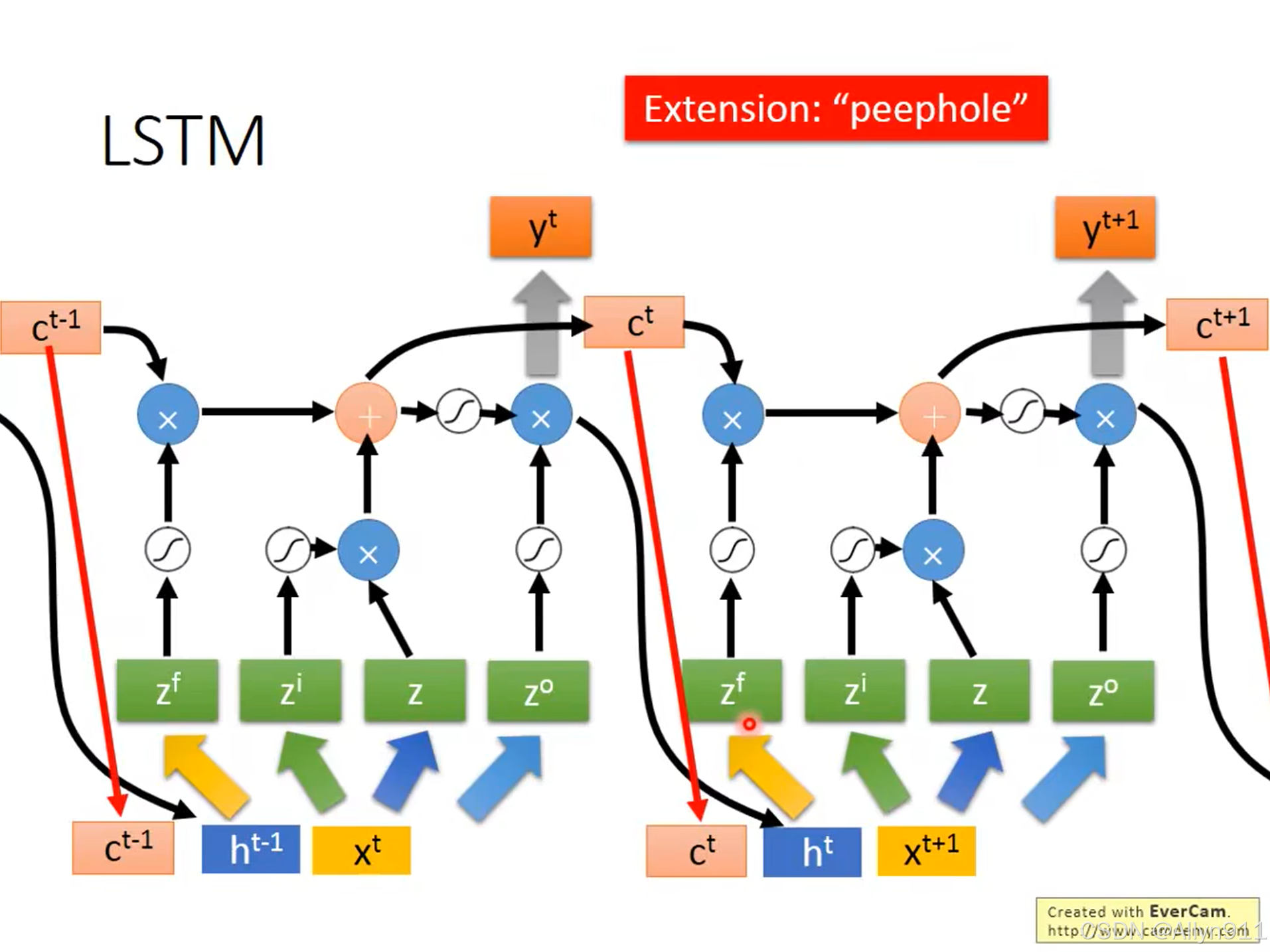
- 作业:LSTM、GRU
详解pytorch中循环神经网络(RNN、LSTM、GRU)的维度_pytorch gru-CSDN博客
PyTorch序列预测实战:RNN、LSTM、GRU模型构建-CSDN博客
LSTM
GRU
代码参考:pytorch深度学习实践(刘二大人)课堂代码&作业——循环神经网络基础篇_pytorch深度学习实践 作业-CSDN博客

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)