常用图像分类数据集整理(适合深度学习入门与实战)
·
一、为什么图像分类数据集这么重要?
在计算机视觉任务中,图像分类是最基础、也是最关键的一步。
无论是:
- 目标检测
- 语义分割
- 行为识别
本质上都依赖于高质量的数据集。
👉 可以说:模型效果的上限,往往由数据决定
二、常见图像分类数据集类型
根据实际应用场景,图像分类数据集大致可以分为以下几类:
1️⃣ 通用物体分类数据集
这类数据集最常见,适合入门和模型训练。
典型特点:
- 类别丰富
- 数据规模大
- 标注规范
常见内容包括:
- 动物分类
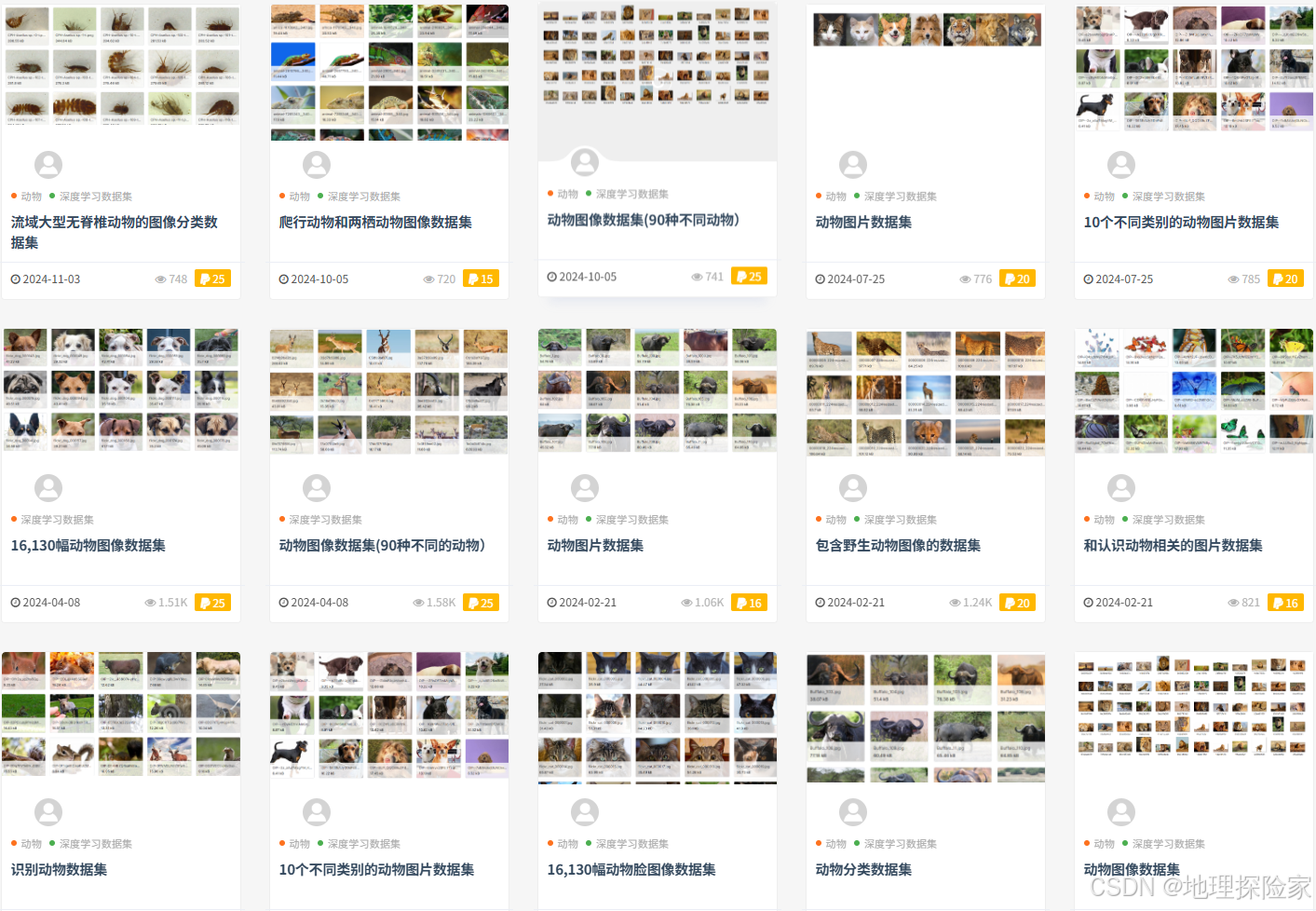
- 日常物体识别
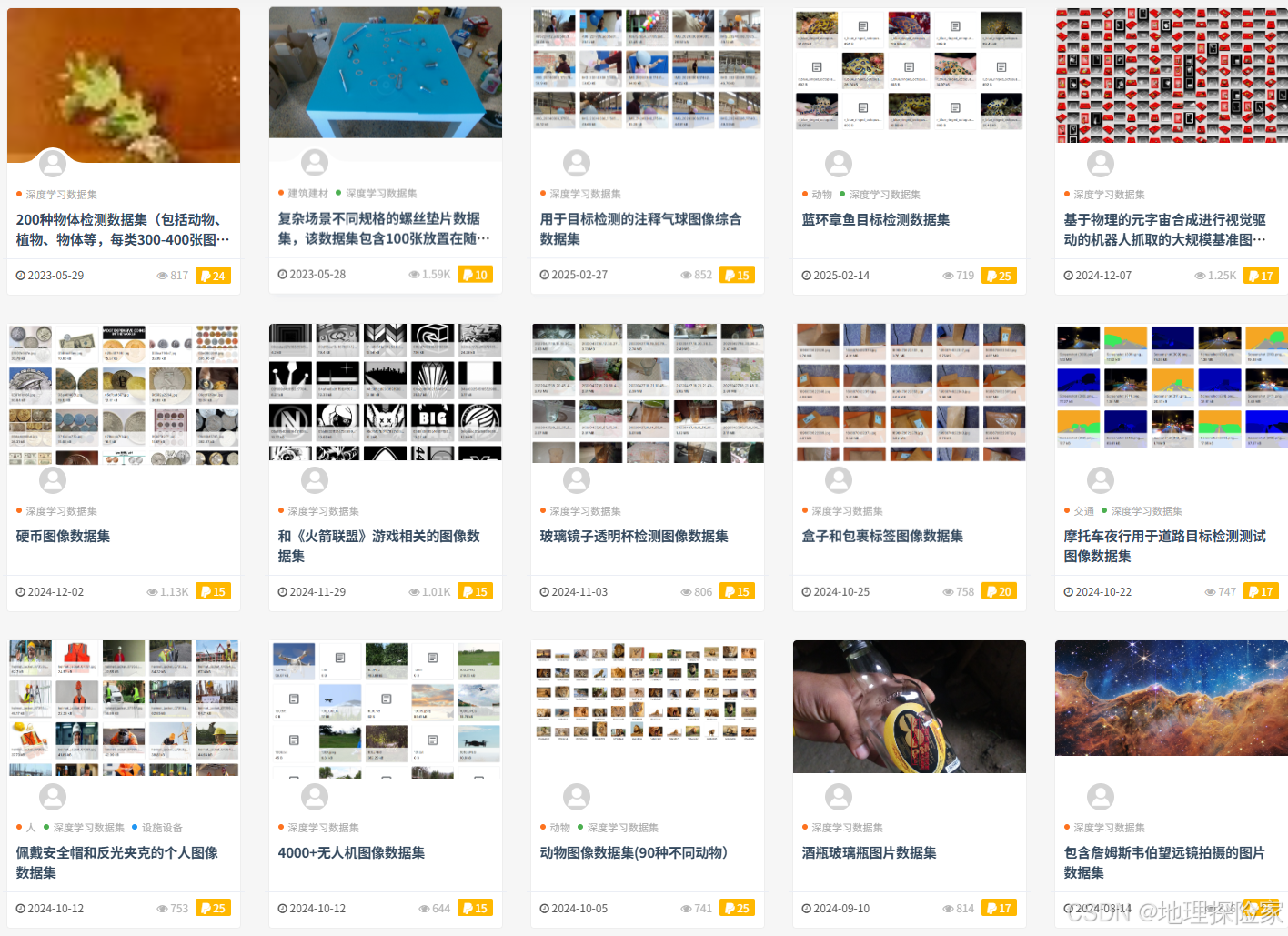
- 场景分类
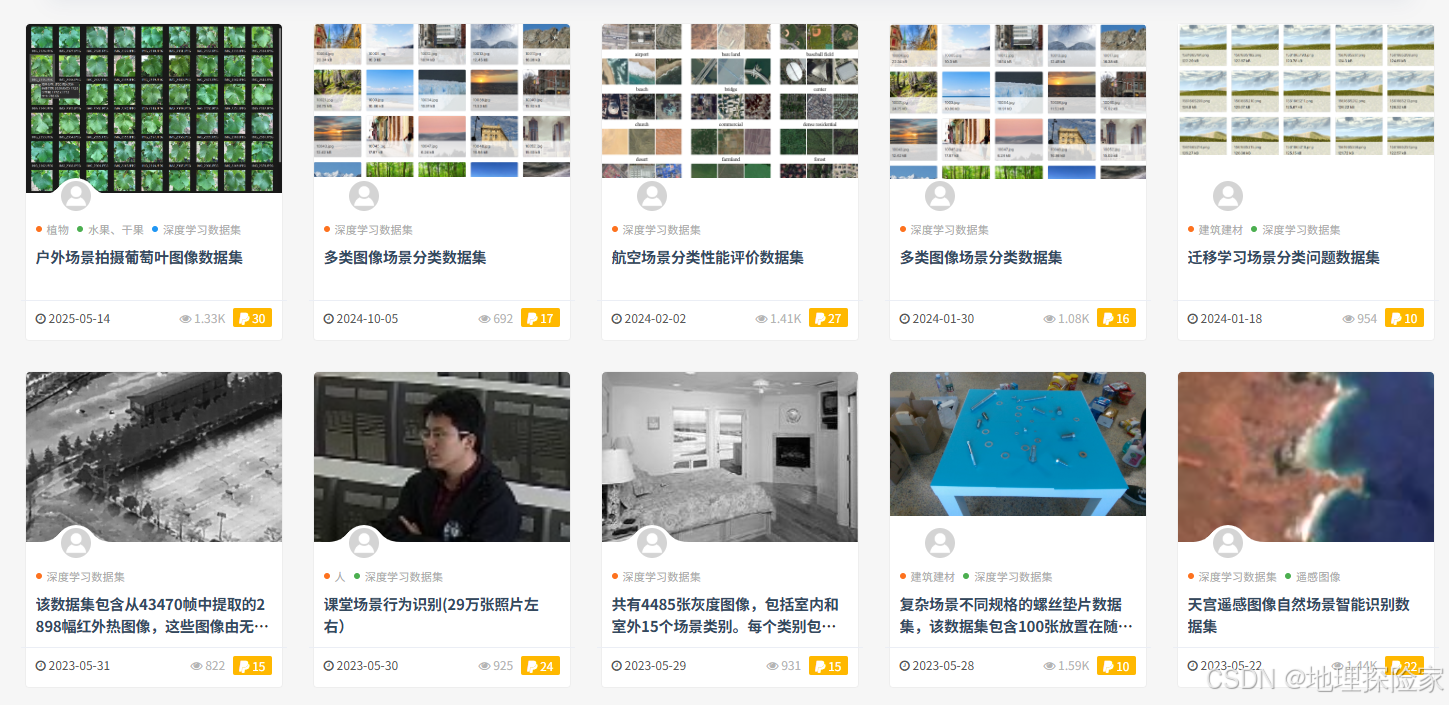
👉 适用于:
- CNN训练
- 图像分类任务
- 模型基准测试
2️⃣ 人体与行为类数据集
包括:
- 手势识别
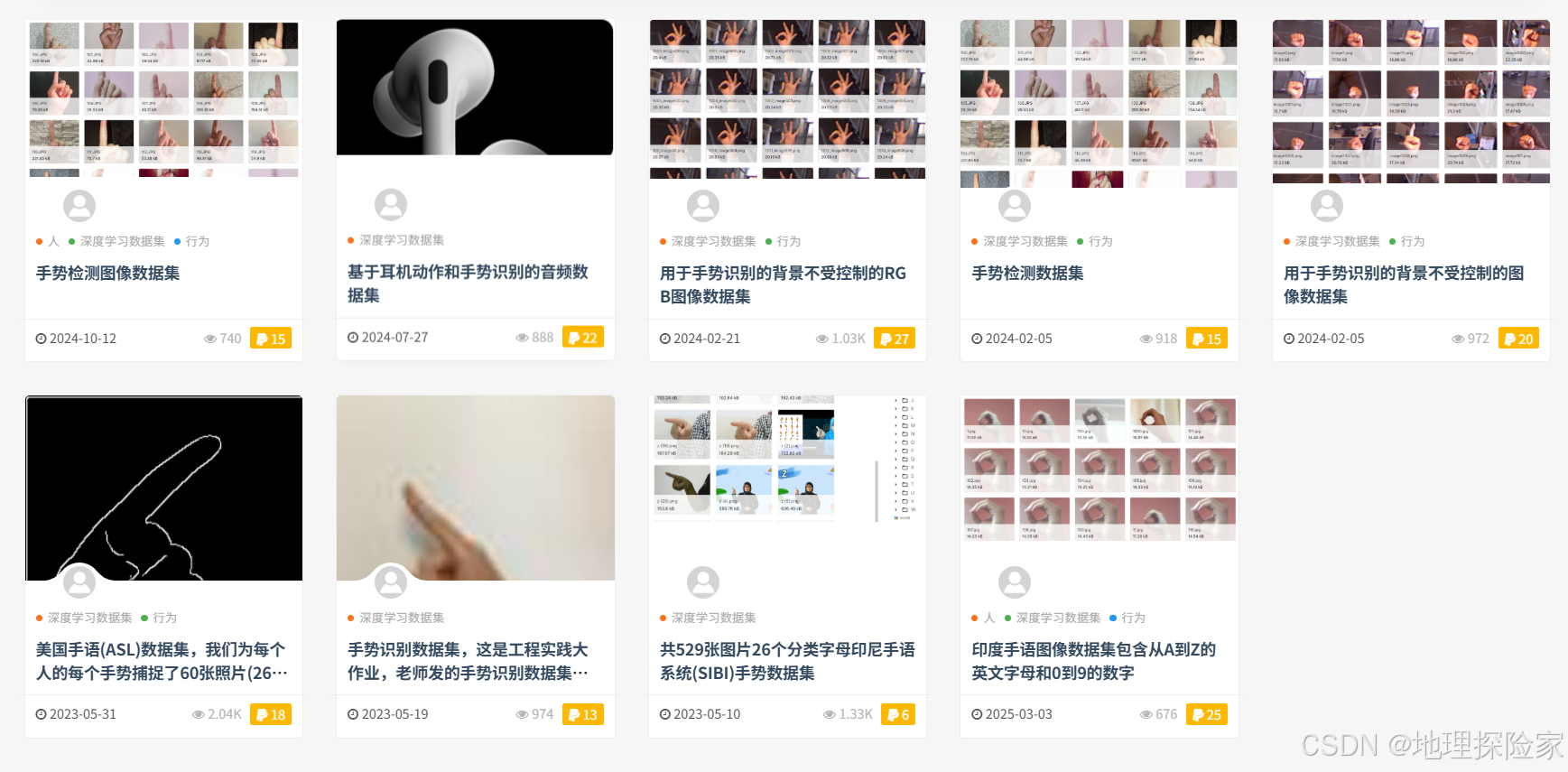
- 人脸识别
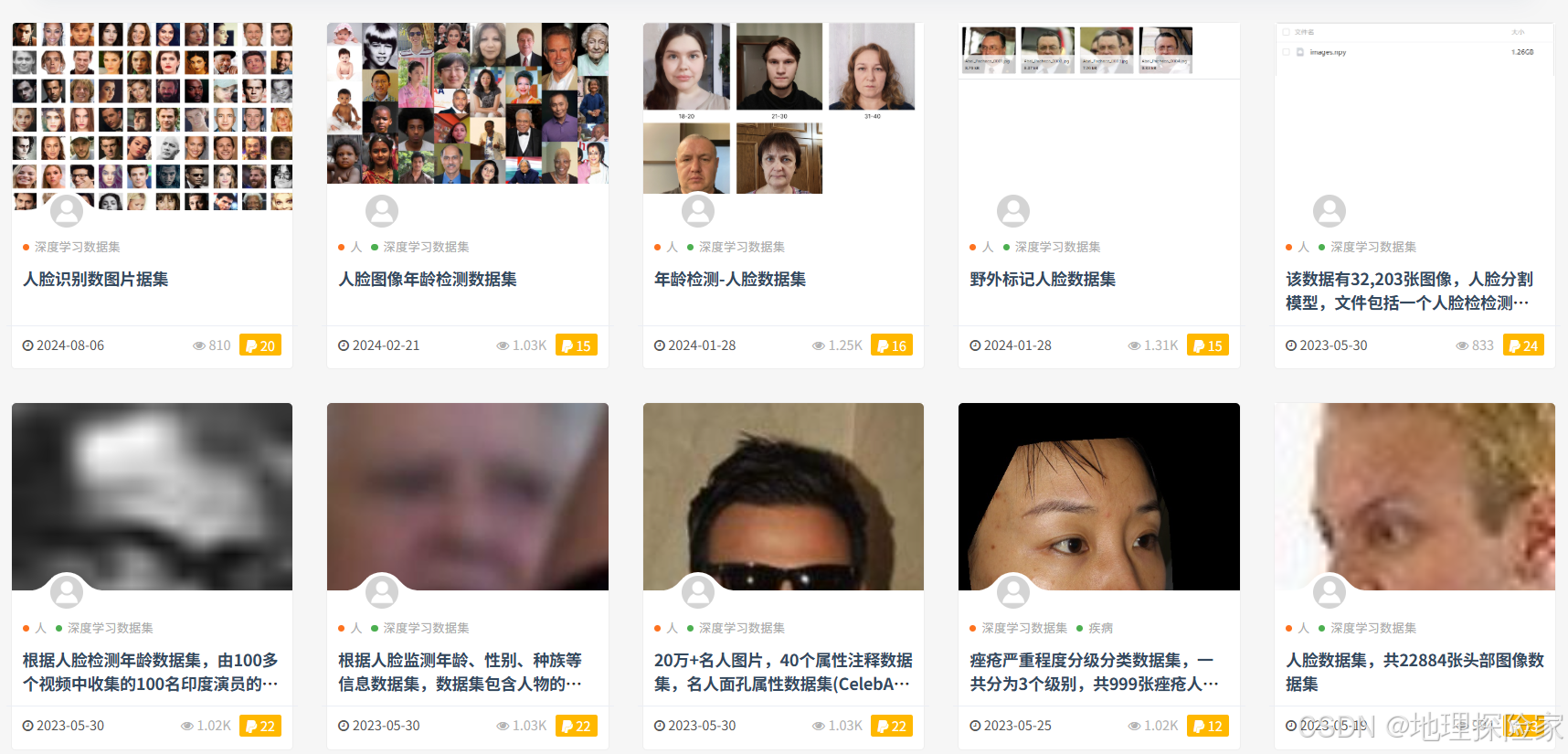
- 动作识别
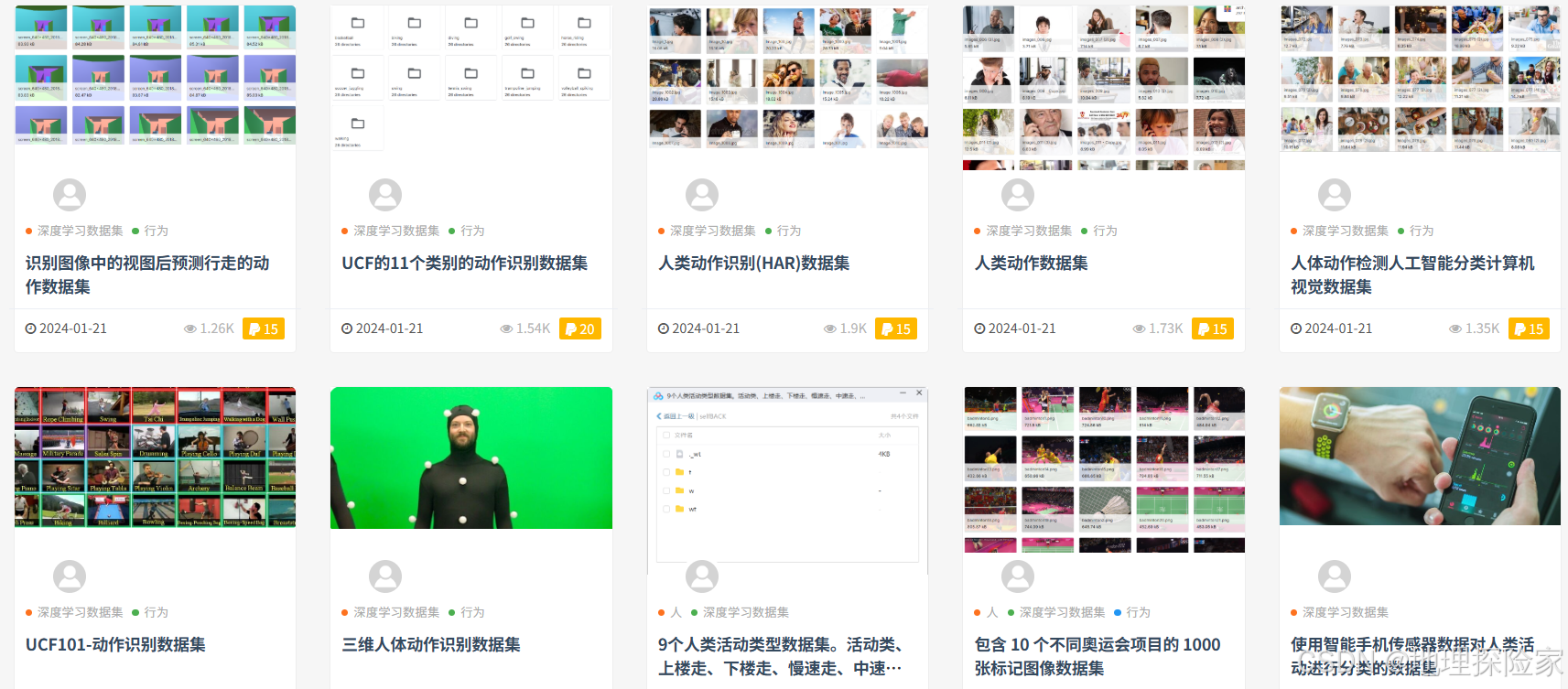
特点:
- 类别细分程度高
- 对模型精度要求高
👉 应用于:
- 安防
- 人机交互
- 行为分析
3️⃣ 医学影像分类数据集
近年来增长非常快的一类数据:
- 皮肤病变分类
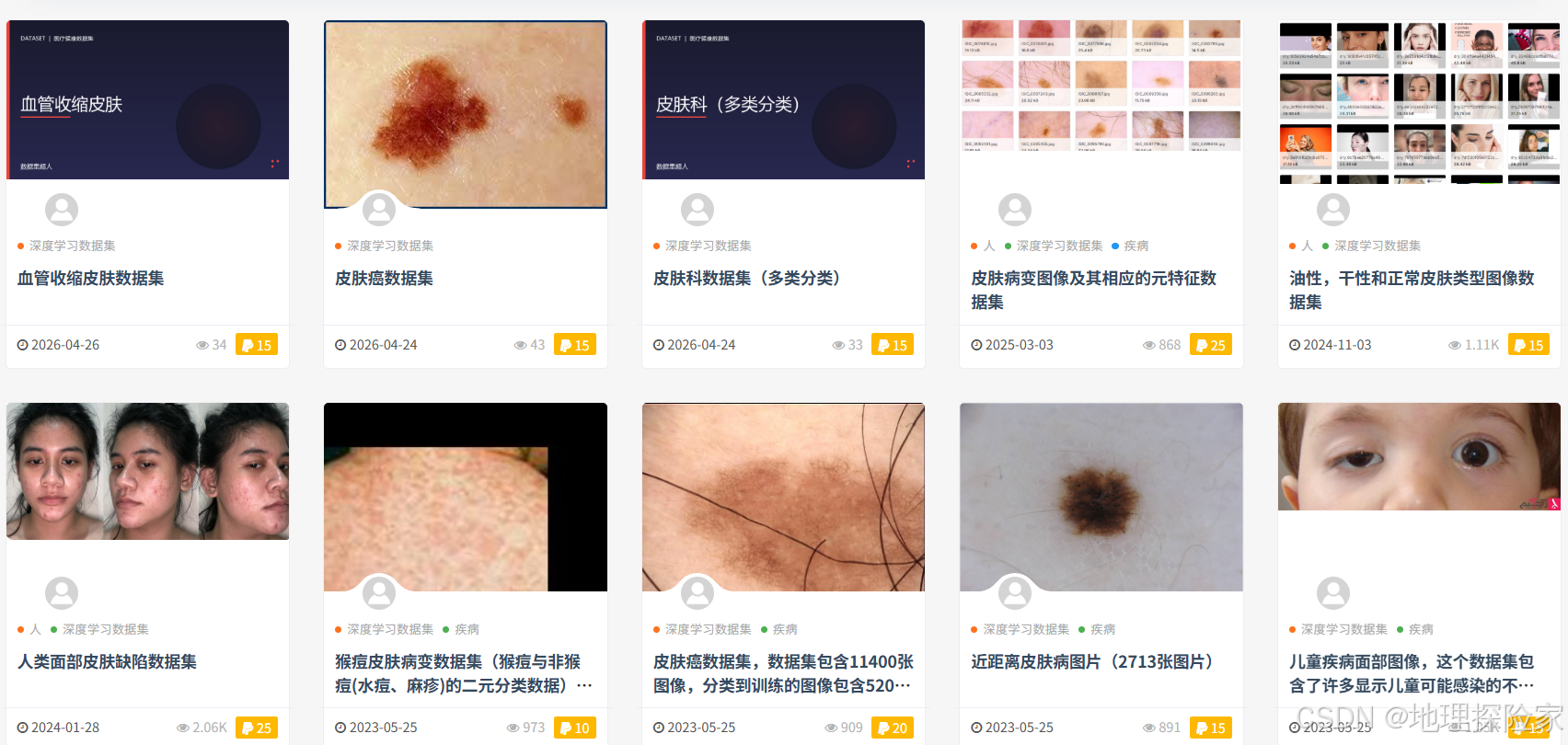
- X光图像识别
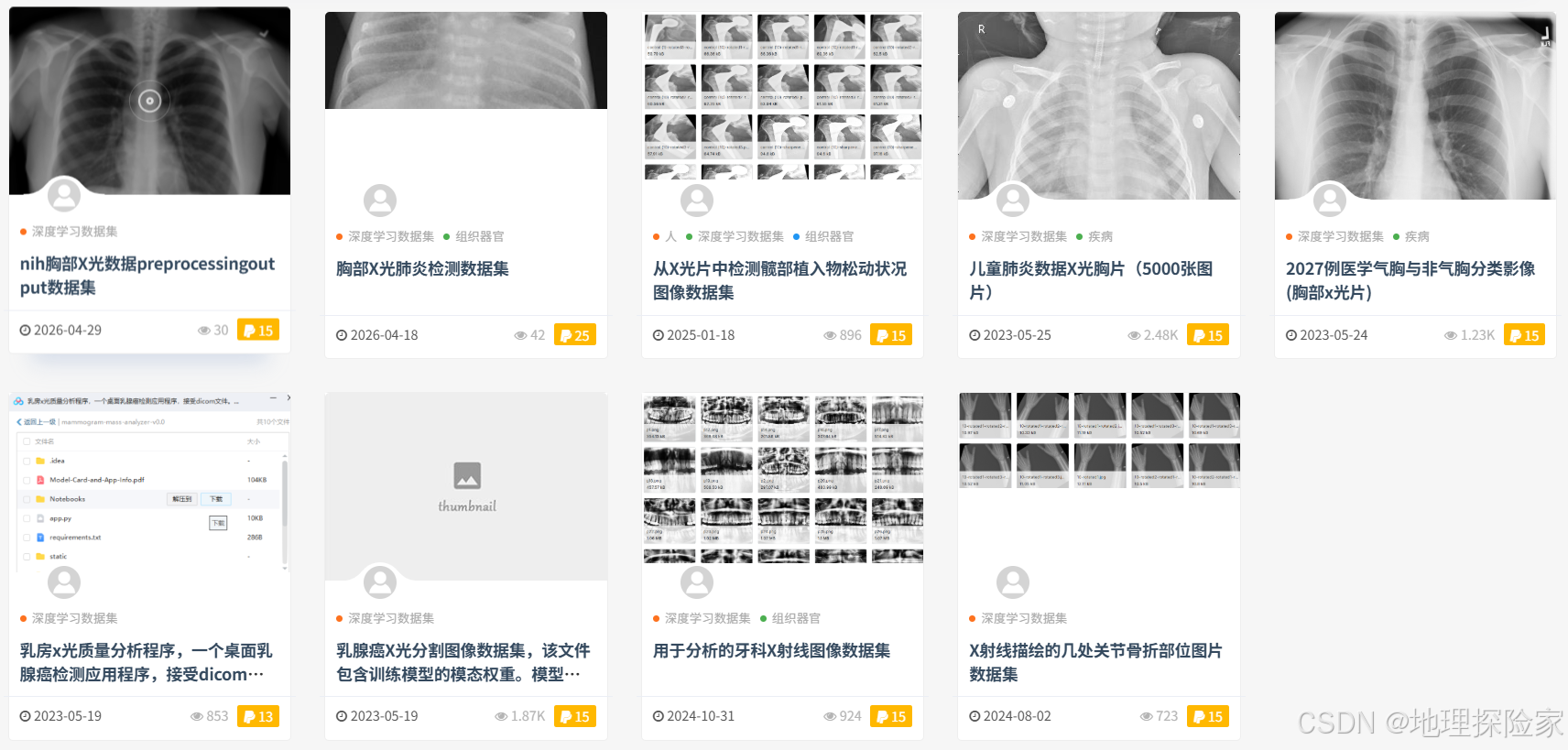
- 眼底图像分析
特点:
- 数据价值高
- 标注成本高
👉 应用于:
- 辅助诊断
- 医疗AI
4️⃣ 农业与自然场景数据集
例如:
- 植物病害识别
- 动物分类
👉 应用于:
- 智慧农业
- 生态监测
三、一个标准图像数据集包含什么?
一个规范的数据集通常包括:
- 图像文件(jpg/png)
- 分类标签(txt / csv)
- 数据说明文档
- 训练 / 测试划分
👉 一些整理较好的数据集,还会包含:
- 已划分好的train/test
- 统一命名规范
- 可直接训练
四、获取数据集的几种常见方式
在实际项目中,常见的数据获取方式有:
方式1:官方数据集
例如论文作者发布的数据
优点:
- 权威
- 标准化
缺点:
- 下载复杂
- 分散
方式2:开源社区
例如:
- GitHub
优点:
- 免费
- 更新快
缺点:
- 数据质量不稳定
方式3:数据整理平台(推荐)
近年来,越来越多平台开始做一件事:
👉 把数据“整理好”再提供出来
比如:
- 分类整理
- 提供说明文档
- 统一格式
👉 对初学者非常友好,可以直接用于训练
五、个人经验:如何快速找到可用数据集
在实际做项目时,我总结了几点:
✔ 优先选“整理好的数据”
原因很简单:
👉 能节省大量时间(通常超过70%)
✔ 看清数据结构
避免出现:
- 标签混乱
- 数据缺失
✔ 选和任务匹配的数据
例如:
- 分类 → 用分类数据集
- 检测 → 用标注框数据
六、数据获取说明
由于平台规范,本文不直接提供下载链接。
如果你需要:
- 图像分类数据集
- 深度学习训练数据
- 已整理好的数据合集
👉 可以通过搜索关键词获取:
🔍 “图像分类数据集 探险家”
这些数据通常已经按类别整理,例如:
- 动物分类
- 行为识别
- 医学影像
适合直接用于模型训练或实验。
对于深度学习来说:
👉 数据比模型更重要
而真正提高效率的方法不是:❌ 自己到处找数据
而是:✅ 使用已经整理好的数据集合集

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)