机器学习之逻辑回归
一、逻辑回归简介(数学基础)
逻辑回归应用场景:解决二分类问题(正反,阳性阴性,是否)
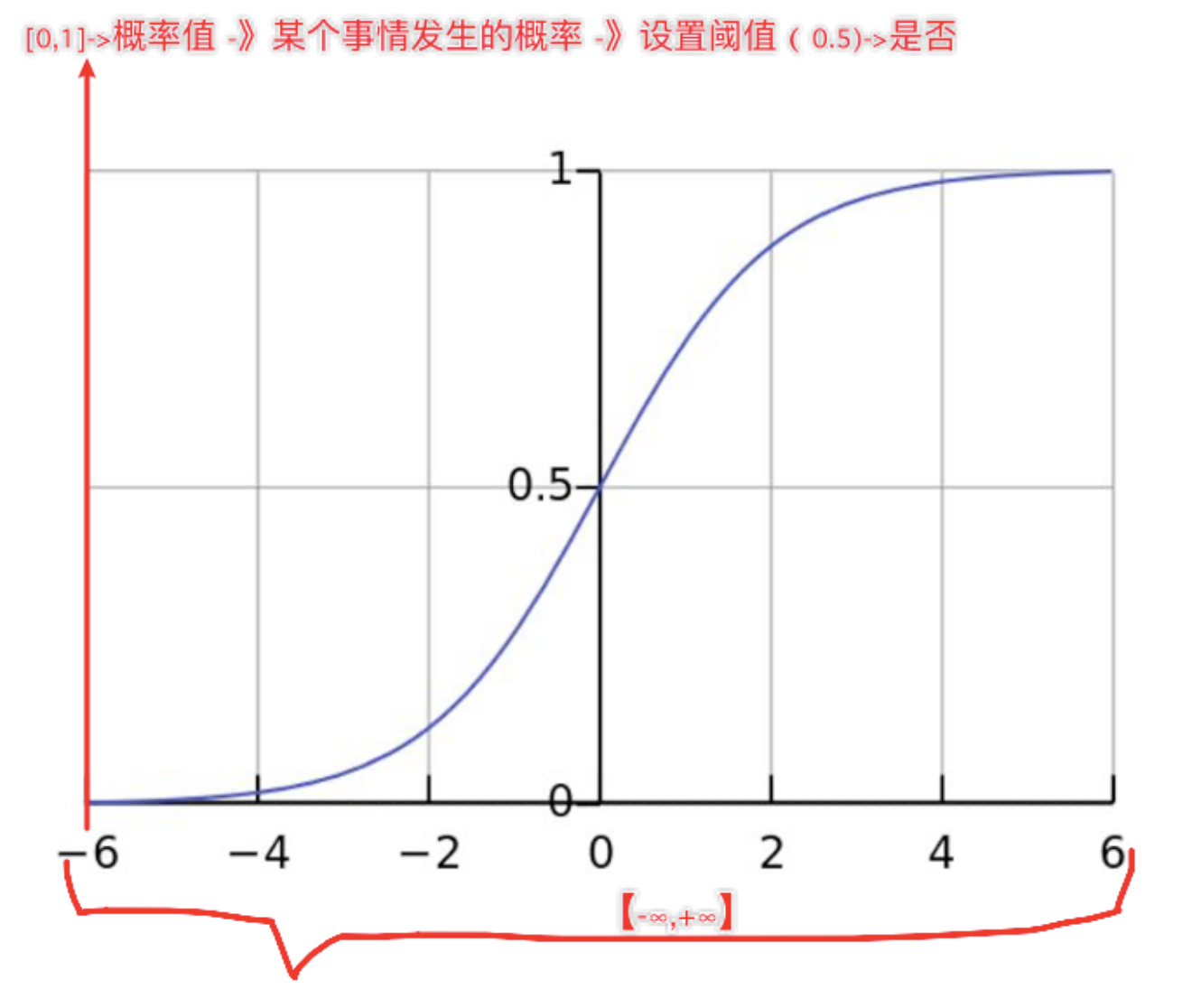
1、sigmoid函数
(1)数学公式:
(2)作用:把(-∞,+∞)映射到 (0,1)
(3)数学性质:单调递增函数,拐点在x=0,y=0.5的位置
(4)导函数公式:f'(x) = f(x)(1-f(x))
2、概率
(1)概率 – 事件发生的可能性
早上堵车概率为0.6,中午堵车概率为0.4,晚上堵车概率为0.3,各自独立
(2)联合概率 – 指两个或多个随机变量同时发生的概率
第一天和第二天早上堵车概率都是0.6,则两天都堵车的概率是0.6*0.6=0.36
(3)条件概率 – 表示事件A在另外一个事件B已经发生条件下的发生概率
早上和中午同时堵车概率为0.24,已知早上堵车概率0.6,则中午堵车概率为0.24/0.6=0.4
(4)联合概率和条件概率是概率论中的基本概念,它们用于描述随机变量之间的关系
3、极大似然估计
核心思想:通过极大化概率事件,来估计最优参数: 设模型中含有待估参数w,可以取很多值。已经知道了样本观测值,从w的一切可能值中(选出一个使该观察值出现的概率为最大的值,作为w参数的估计值,这就是极大似然估计。(顾名思义:就是看上去那个是最大可能的意思)
举个例子:假设有一枚不均匀的硬币,出现正面的概率和反面的概率是不同的。假定出现正面的概率为𝜃, 抛了6次得到如下现象 D = {正面,反面,反面,正面,正面,正面}。每次投掷事件都是相互独立的。 则根据产生的现象D,来估计参数𝜃是多少?
P(D|𝜃) = P {正面,反面,反面,正面,正面,正面}
= P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃)
= 𝜃 *(1-𝜃)*(1-𝜃)𝜃*𝜃*𝜃 =
问题转化为:求此函数的极大值时,估计𝜃为多少?
令导数=0求极值,可估计出
值
从而得: = 0 出现正面的概率为0,即每次抛都是反面(极端,舍弃)
= 1 出现正面的概率为1, 即每次抛都是正面(极端,舍弃)
= 2/3 出现正面的概率为2/3,即反面概率为1/3(正常,取用)
4、对数函数
如果 = N (a > 0, b ≄1), 那么b叫做以a为底N的对数。记为 b =
eg: ,
注意:a > 1 和 a < 1时对数函数的图像,a(大于1)和1/a的对数函数关于x轴对称
性质: ,
其中a>0,M>0,N>0
二、逻辑回归原理
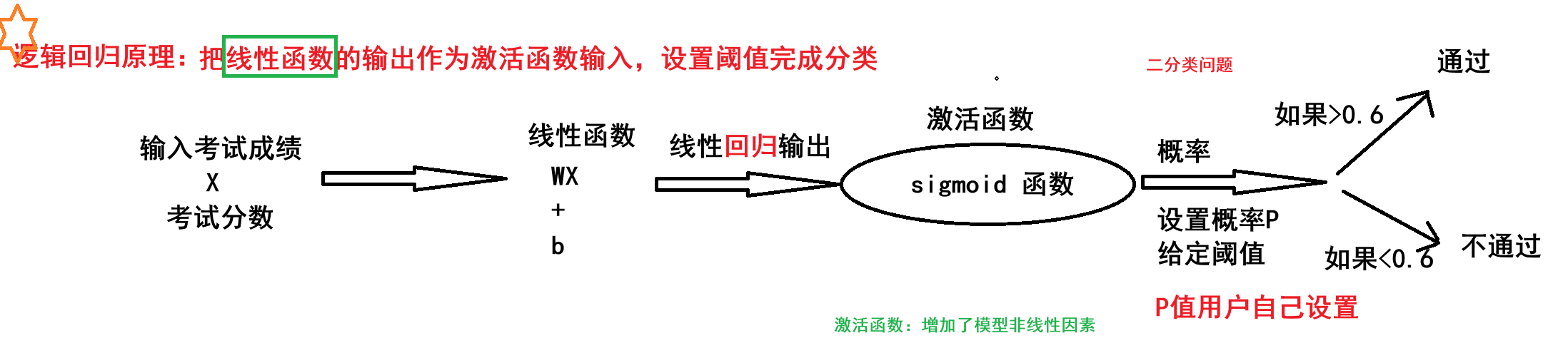
1、逻辑回归概念
一种分类模型,把线性函数的输出作为激活函数的输入,设置阈值完成分类,输出是(0,1)之间的值
2、基本思想
(1)利用线性模型 根据特征的重要性计算出一个值
(2)再使用 sigmoid 函数将 f(x) 的输出值映射为概率值
a. 设置阈值(eg:0.5),输出概率值大于 0.5,则将未知样本输出为 1 类
b. 否则输出为 0 类
3、逻辑回归的假设函数
线性回归的输出,作为逻辑回归的输入
4、图解
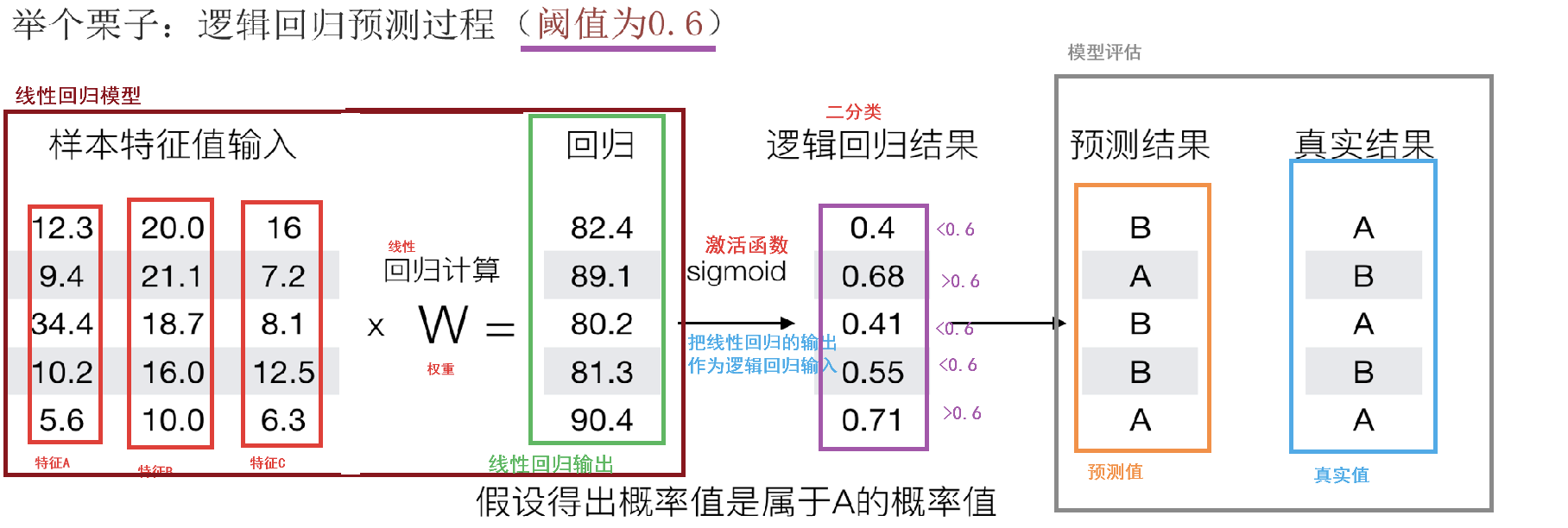
例子:
5、损失函数
(1)数学表达式
m:样本数量 :真实标签(值是0或者1)
是逻辑回归的输出结果
损失函数的工作原理:每个样本预测值有A、B两个类别,真实类别对应的位置,概率值越大
越好。
(2)损失函数内部
a、当真实值标签 = 1 时,损失函数变为
结论:预测概率越接近1,损失越小。预测概率越接近于0,损失越大
当 = 1 的时候,
越接近1越好,根据对数函数性质,
越接近1,
越接近0
那么 也就越接近0,损失越小,说明模型对该样本的预测越准
反之,若 越接近0,
趋紧于负无穷,
趋紧正无穷,损失越大,预测越差
b、当真实值标签 = 1 时,损失函数变为
结论:预测概率越接近0,损失越小。预测概率越接近于1,损失越大
(3)例子

三、逻辑回归API函数和案例
1、API介绍
sklearn.linear_model.LogisticRegression(solver='liblinear', \
penalty=‘l2’, C = 1.0)
(1)solver 损失函数优化方法
a、 liblinear 对小数据集场景训练速度更快,sag 和 saga 对大数据集更快一些
b、正则化: 1. sag、saga 支持 L2 正则化或者没有正则化
2. liblinear 和 saga 支持 L1 正则化
(2)penalty:正则化的种类,l1 或者 l2
(3)C:正则化力度
(4)默认将类别数量少的当作正例
2、案例解析
数据描述:(1)699条样本,共11列数据,第一列用语检索的id,后9列分别是与肿瘤相关的医学特
征,最后一列表示肿瘤类型的数值。
(2)包含16个缺失值,用”?”标出。
(3)2表示良性,4表示恶性
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 1. 准备数据
df = pd.read_csv("breast-cancer-wisconsin.csv")
df.info()
# 2. 数据预处理
df = df.replace("?", np.nan)
df.info()
# 2.2 因为有缺失值,但是缺失值不多,删除即可,按行删除
df.dropna(axis=0, inplace=True)
df.info()
# 3. 特征工程
# 3.1 获取特征和标签
x = df.iloc[:, 1:-1]
y = df.iloc[:, -1]
# y = df.Class y = df["Class"]
print(len(x), len(y))
# 3.3 拆分训练集和数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, \
test_size=0.2, random_state=22)
# 3.4 数据集相差不大,可以不做标准化,但是为了让步骤更透明,还是做标准化处理
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4. 模型训练
# 4.1 创建模型
es = LogisticRegression()
# 4.2 训练模型
es.fit(x_train, y_train)
# 5. 模型预测
y_predict = es.predict(x_test)
# 6. 模型评估
print(f"准确率:{es.score(x_test, y_test)}")
"""
至此,逻辑回归入门API就写完了。但是这里做的是癌症预测。
思考:仅仅靠准确率,来衡量逻辑回归结果合适?
肯定不行的!!!因为只知道准确率,不知道到底是哪些预测成功了,哪些预测失败了?
所以需要进一步评估
比如癌症预测 , 你告诉 张三,你得癌症了。但是本次预测结果准确率只有98%
所以需要加入: 混淆矩阵 : 精确率(掌握),召回率(掌握),F1-score(掌握)
ROC曲线(了解) AUC值(了解)
"""四、分类问题评估
1、混淆矩阵
(1)图解
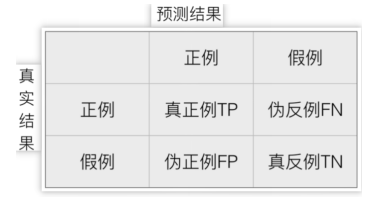
简洁记忆:第一个字为预测结果对真实结果的判断,若相同则为真,若不同则是伪
第二个字为预测结果,若预测结果是正则为正,若预测结果是假例则为反
(2)混淆矩阵的四个指标
TP: 真实值为正例,预测值为正例,这个值称为真正例,即TP
TN:真实值为假例,预测值为假例,这个值称为真反例,即TN
FP: 真实值为假例,预测值为正例,这个值称为伪正例,即FP
FN:真实值为正例,预测值为假例,这个值称为伪反例,即FN
(3)分类评估方法 – 精确率、召回率、F1
1、精确率(Precision)
查准率,对正例样本的预测准确率。
比如:把恶性肿瘤当做正例样本,想知道模型对恶性肿瘤的预测准确率。
计算方法:P = TP /(TP+ FP)
2、召回率(Recall)
也叫查全率,指的是预测为真正例样本占所有真实正例样本的比重
例如:恶性肿瘤当做正例样本,则我们想知道模型是否能把所有的恶性肿瘤患者都预测出来
计算方法:P = TP /(TP+ FN)
3、F1- score
对模型的精度、召回率都有要求,计算得到模型在这两个评估方向的综合预测能力
计算方法:
(4)AUC指标、ROC曲线
1、真正率TPR与假正率FPR
a、正样本中被预测为正样本的概率TPR (True Positive Rate)
b、负样本中被预测为正样本的概率FPR (False Positive Rate)
c、通过这两个指标可以描述模型对正/负样本的分辨能力
2、ROC曲线(Receiver Operating Characteristic curve)
是一种常用于评估分类模型性能的可视化工具。ROC曲线以模型的真正率TPR为纵轴,假正
率FPR为横轴,它将模型在不同阈值下的表现以曲线的形式展现出来
3、AUC (Area Under the ROC Curve)曲线下面积
ROC曲线的优劣可以通过曲线下的面积(AUC)来衡量,AUC越大表示分类器性能越好。
当AUC=0.5时,表示分类器的性能等同于随机猜测
当AUC=1时,表示分类器的性能完美,能够完全正确地将正负例分类。
4、ROC 曲线图像中,4 个特殊点的含义(图解)

5、ROC 曲线的绘制(图解)
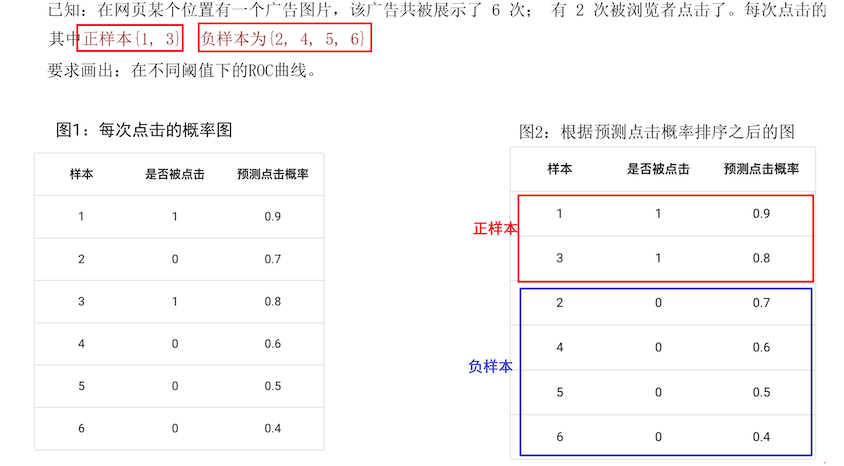
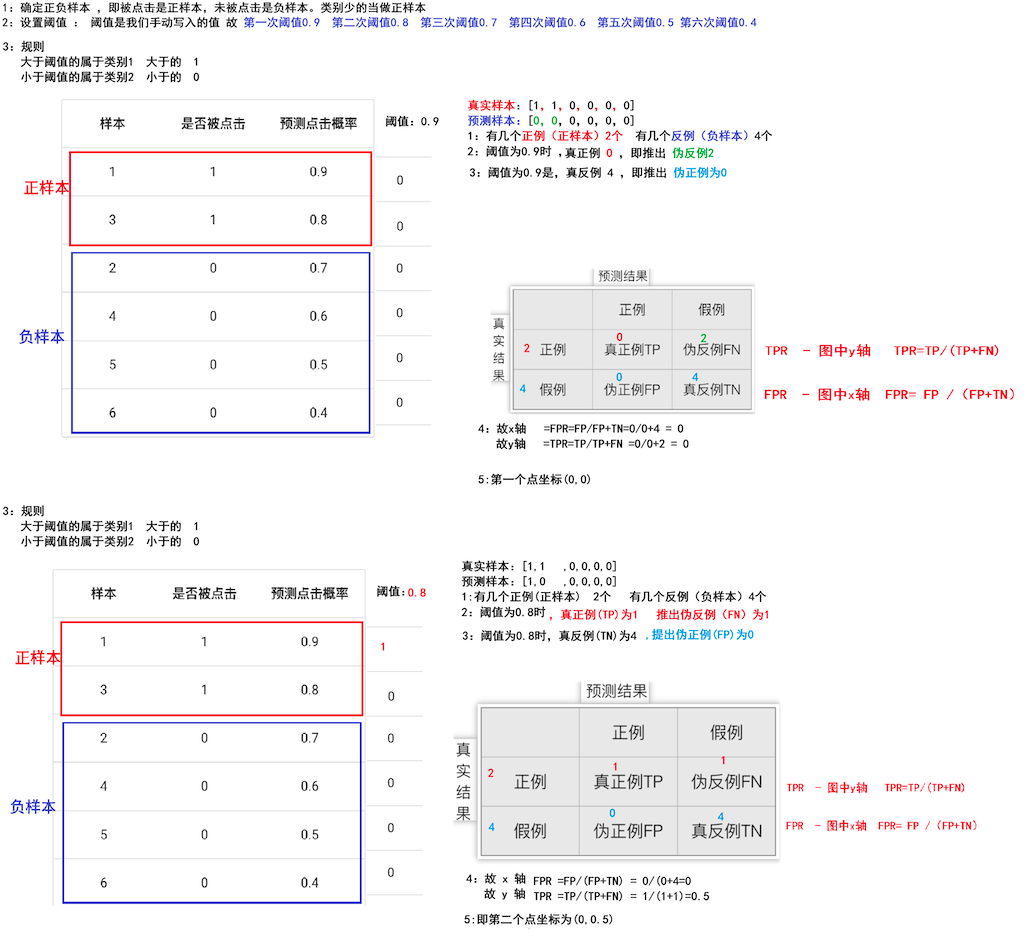
(4)代码演示
import pandas as pd
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
# todo 1、定义数据集 真实样本(10个 6个恶性,4个良性) -> 手动设置 恶性(正例) 良性(反例)
y_train = ['恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '良性', '良性', '良性', '良性']
# todo 2、定义标签名
label = ['恶性', '良性'] # 标签1:正样本(正例) 标签2: 负样本(反例)
df_label = ['恶性(正例)', '良性(反例)'] # 这是为了让格式好看
# todo 3、定义 预测结果A 3个恶性,4个良性 改完后数据集有 3个恶性,7个良性
# todo 3、定义 预测结果B 6个恶性,1个良性 改完后数据集有 9个恶性,1个良性
y_pre_A = ['恶性', '恶性', '恶性', '良性', '良性', '良性', '良性', '良性', '良性', '良性']
y_pre_B = ['恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '恶性', '良性']
# todo 4、把上述的预测结果A和B 转化为 混淆矩阵
cm_A = confusion_matrix(y_train, y_pre_A, labels=label)
cm_B = confusion_matrix(y_train, y_pre_B, labels=label)
print(f"混淆矩阵A:\n{cm_A}")
print(f"混淆矩阵B:\n{cm_B}")
# todo 5、把 混淆矩阵 转化为 DataFrame格式
df_A = pd.DataFrame(cm_A, index=df_label, columns=df_label)
df_B = pd.DataFrame(cm_B, index=df_label, columns=df_label)
print(f"混淆矩阵A:\n{df_A}")
print(f"混淆矩阵B:\n{df_B}")
# todo 6、打印预测结果
# 精确率 参1: 真实样本 参2: 预测样本 参3: 正例标签
print(f"预测结果A的精确率:{precision_score(y_train, y_pre_A, pos_label='恶性')}")
print(f"预测结果B的精确率:{precision_score(y_train, y_pre_B, pos_label='恶性')}")
# 召回率
print(f"预测结果A的召回率:{recall_score(y_train, y_pre_A, pos_label='恶性')}")
print(f"预测结果B的召回率:{recall_score(y_train, y_pre_B, pos_label='恶性')}")
# F1-score
print(f"模型A的F1-score:{f1_score(y_train, y_pre_A, pos_label='恶性')}")
print(f"模型B的F1-score:{f1_score(y_train, y_pre_B, pos_label='恶性')}")五、题目解答
1:逻辑回归主要解决什么类型的问题?逻辑回归的流程是什么 ?
2:混淆矩阵的四个基本元素(TP、TN、FP、FN)分别代表什么含义?
3:精确率(Precision)、召回率(Recall)的计算公式是什么?分别反映模型的什么能力?
4:ROC 曲线的横纵轴分别是什么?曲线上的每个点代表什么含义?
5:AUC 指标的含义是什么?其取值范围是多少?AUC=0.5、AUC=1 、AUC=0分别说明模型的什么性能?6:代码题:电信客户流失预测案例
案例需求: 已知:用户个人,通话,上网等信息数据(churn.csv)
需求:通过分析特征属性确定用户流失的原因,以及哪些因素可能导致用户流失。建
立预测模型来判断用户是否流失,并提出用户流失预警策略。
案例步骤分析:1、数据基本处理
主要是查看数据行/列数量
对类别数据数据进行one-hot处理
查看标签分布情况
2、特征筛选
分析哪些特征对标签值影响大
对标签进行分组统计,对比0/1标签q分组后q的均值等
初步筛选出对标签影响比较大的特征,形成x、y
3、模型训练
样本均衡情况下模型训练
样本不平衡情况下模型训练
交叉验证网格搜索等方式模型训练
4、模型评估
精确率
Roc_AUC指标计算

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 47
47 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)