吴恩达机器学习 - 第八章 逻辑回归的代价函数以及具体实现
·

📘 吴恩达机器学习 - 第八章 逻辑回归的代价函数以及具体实现
“代价函数不是神经网络的附庸,而是评判其学习是否成功的裁判。”
—— 徐策(逻辑王子)
🧠 8.1 逻辑回归的代价函数
在线性回归中,我们采用的是均方误差(MSE)作为代价函数。然而,当模型的输出目标为 0 或 1 时(例如是否患病、是否为垃圾邮件等分类问题),我们必须抛弃均方误差,转而引入新的、更适合概率判别的度量标准。
在逻辑回归中,我们用的是 对数损失函数(Log Loss):
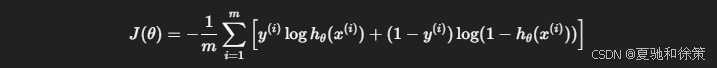
其中:

这个代价函数有如下优点:
-
对数性质:当模型预测越接近真实标签时,损失越小;
-
凸性:代价函数是凸的,有助于优化算法收敛到全局最优。
✂️ 8.2 简化版代价函数(向量化表达)
吴恩达在视频中演示了如何对逻辑回归的代价函数进行向量化简化,使其便于实现:
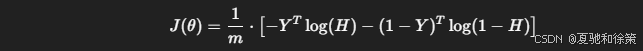
其中:
-
Y∈Rm×1Y \in \mathbb{R}^{m \times 1},表示所有真实标签组成的向量;
-
H=sigmoid(X⋅θ)∈Rm×1H = sigmoid(X \cdot \theta) \in \mathbb{R}^{m \times 1},表示所有预测概率组成的向量。
这样,整个代价函数计算过程可高度并行化,适合在 GPU 上高效训练。
🔁 换个角度直观理解一下
逻辑回归的代价函数其实是在惩罚“自信但错”的预测:
-
如果你预测是 1,结果也是 1 → 代价接近 0;
-
如果你预测是 1,结果却是 0 → 代价爆炸(log(0) 趋近于 -∞);
-
如果你预测接近 0.5,系统认为你“模棱两可”,惩罚较轻。
这正体现了人类对“错误判断”天然的惩罚机制。
🧪 代码实现(基于 Python)
import numpy as np
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def compute_cost(theta, X, y):
m = len(y)
h = sigmoid(X @ theta)
epsilon = 1e-5 # 防止 log(0)
cost = -(1/m) * (y.T @ np.log(h + epsilon) + (1 - y).T @ np.log(1 - h + epsilon))
return cost
✅ 总结一句话:
逻辑回归的代价函数,不只是优化目标,它是机器理解分类“对错”的逻辑边界。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)