【机器学习实战笔记 3】Scikit-Learn使用与进阶 一
《Scikit-Learn使用与进阶 一》
Scikit-Learn最早是由David Cournapeau等人在2007年谷歌编程之夏(Google Summer of Code)活动中发起的一个项目,并与2010年正式开源,目前归属INRIA(法国国家信息与自动化研究所)。而项目取名为Scikit-Learn,也是因为该算法库是基于SciPy来进行的构建,而Scikit则是SciPy Kit(SciPy衍生的工具套件)的简称,而learn则不禁让人联系到机器学习Machine Learning。因此,尽管Scikit-Learn看起来不如NumPy、Pandas短小精悍,但其背后的实际含义也是一目了然。
Scikit-Learn使用
1 Scikit-Learn内容分布与查找
- sklearn的六大功能模块
首先,从建模功能上进行区分,sklearn将所有的评估器和函数功能分为六大类,分别是分类模型(Classification)、回归模型(Regression)、聚类模型(Clustering)、降维方法(Dimensionality reduction)、模型选择(Model selection)和数据预处理六大类。
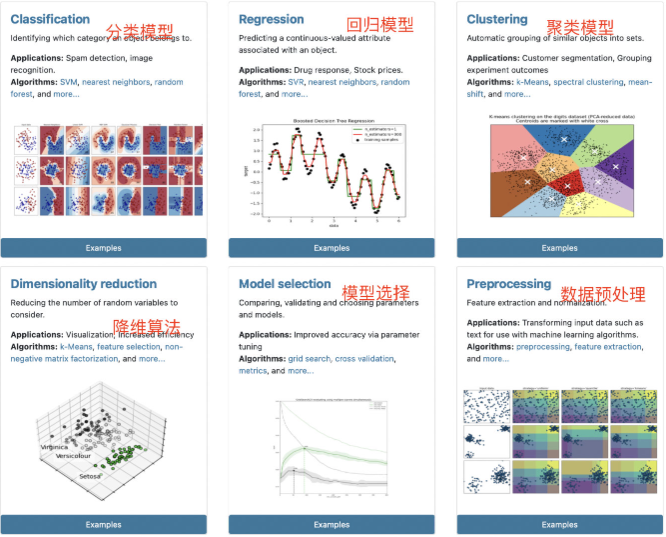
其中分类模型、回归模型和聚类模型是机器学习内主流的三大类模型,其功能实现主要依靠评估器类,并且前两者是有监督学习、聚类模型属于无监督学习范畴。当然,sklearn中并未包含关联规则相关算法,如Apriori或者FP-Growth,这其实一定程度上和sklearn只能处理array-like类型对象有关。而后三者,降维方法、模型选择方法和数据预处理方法,则多为辅助建模的相关方法,并且既有评估器也有实用函数。
值得一提的是,上述六个功能模块的划分其实是存在很多交叉的,对于很多模型来说,既能处理分类问题、同时也能处理回归问题,而很多聚类算法同时也可以作为降维方法实用。不过这并不妨碍我们从这些功能入口出发,去寻找我们需要的评估器或实用函数。例如线性回归对用评估器可从Regression进入进行查找,而对用模型评估指标,由于评估指标最终是指导进行模型选择的,因此模型评估指标计算的实用函数的查找应该从Model selection入口进入,并且在3.3 Metrics and scoring: quantifying the quality of predictions内。
- User Guide:sklearn所有内容的合集文档
此外,我们可以在最上方的User Guide一栏进入sklearn所有内容的合集页面,其中包含了sklearn的所有内容按照使用顺序进行的排序。如果点击左上方的Other versions,则可以下载sklearn所有版本的User Guide的PDF版本。

- API:按照二级模块首字母排序的接口查询文档
如果想根据评估器或实用函数的名字去查找相关API说明文档,则可以点击最上方的API一栏进入到根据二极模块首字母排序的API查询文档中。其中二级模块指的是类似包含线性回归的linear_model模块或者包含MSE的metrics模块。

- 关于源码的阅读
阅读开源算法框架的源码,其实是很多高阶算法工程师自我提升的必经之路。尽管sklearn中出于代码运行速度考虑,有部分算法是用cython重写了,但目前大多数代码都在朝着代码可读性和易用性方向发展(降低协作门槛),因此大部分模块的代码还是相对不难读懂的。
不过在初中级阶段、尤其是以调用评估器建模为主的情况下,还是应以熟练掌握常用评估器和实用函数、以及其背后的实现原理为核心进行学习。因此对大多数小伙伴来说,并不推荐在当前阶段并不推荐进行源码阅读。
2 Scikit-Learn常用功能介绍
2.1 sklearn中的数据集读取
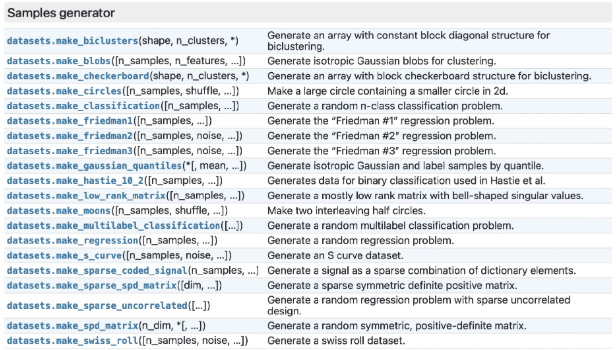
sklearn中的数据集相关功能都在datasets模块下,我们可以通过API文档中的datasets模块所包含的内容对所有的数据集和创建数据集的方法进行概览。不难发现,sklearn中提供了结构化数据集(如经典的鸢尾花数据集、波士顿房价数据集、乳腺癌数据集等),同时也提供了一些如图片数据、文本数据等数据集,可以使用load函数来进行读取;此外,sklearn中还提供了许多能够创建不同数据分布的数据生成器(用make函数创建),和我们此前定义的数据生成器类似,都是可以用于创建测试评估器性能的数据生成器。

2.2 sklearn中的数据集切分方法
在sklearn中,我们可以通过调用train_test_split函数来完成数据集切分,当然数据集切分的目的是为了更好的进行模型性能评估,而更好的进行模型性能评估则是为了更好的进行模型挑选,因此train_test_split函数实际上是在model_selection模块下。
from sklearn.model_selection import train_test_split
2.3 sklearn中的数据标准化与归一化
从功能上划分,sklearn中的归一化其实是分为标准化(Standardization)和归一化(Normalization)两类。其中,此前所介绍的Z-Score标准化和0-1标准化,都属于Standardization的范畴,而在sklearn中,Normalization则特指针对单个样本(一行数据)利用其范数进行放缩的过程。不过二者都属于数据预处理范畴,都在sklearn中的Preprocessing data模块下。
from sklearn import preprocessing
(1) 标准化 Standardization
sklearn的标准化过程,即包括Z-Score标准化,也包括0-1标准化,并且即可以通过实用函数来进行标准化处理,同时也可以利用评估器来执行标准化过程。接下来我们分不同功能以的不同实现形式来进行讨论:
- Z-Score标准化的函数实现方法
实用函数进行标准化处理,尽管从代码实现角度来看清晰易懂,但却不适用于许多实际的机器学习建模场景。其一是因为在进行数据集的训练集和测试集切分后,我们首先要在训练集进行标准化、然后统计训练集上统计均值和方差再对测试集进行标准化处理,因此其实还需要一个统计训练集相关统计量的过程;其二则是因为相比实用函数,sklearn中的评估器其实会有一个非常便捷的串联的功能,sklearn中提供了Pipeline工具能够对多个评估器进行串联进而组成一个机器学习流,从而简化模型在重复调用时候所需代码量,因此通过评估器的方法进行数据标准化,其实是一种更加通用的选择。
from sklearn.preprocessing import StandardScaler
- 0-1标准化的评估器实现方法
类似的,我们可以调用评估器进行0-1标准化。
from sklearn.preprocessing import MinMaxScaler
MinMaxScaler?
(2) 归一化 Normalization
和标准化不同,sklearn中的归一化特指将单个样本(一行数据)放缩为单位范数(1范数或者2范数为单位范数)的过程,该操作常见于核方法或者衡量样本之间相似性的过程中。这些内容此前我们并未进行介绍,但出于为后续内容做铺垫的考虑,此处先介绍关于归一化的相关方法。
from sklearn.preprocessing import Normalizer
值得注意,除了标准化和归一化之外,还有一个正则化(Regularization)的概念,所谓正则化,往往指的是通过在损失函数上加入参数的1-范数或者2-范数的过程,该过程能够有效避免模型过拟合。
关于评估器、解释器、转化器等名词的辨析:
其实这一组概念广泛存在于不同的算法库和算法框架中,但不同的算法库对其的定义各有不同,并且sklearn对其定义也并不清晰。因此,为了统一概念,课上称所有的sklearn中类的调用为评估器的调用,而不区分评估器与转化器。
尝试使用逻辑回归评估器
# 导入逻辑回归评估器
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# 数据准备
X, y = load_iris(return_X_y=True)
# 实例化模型,使用默认参数
clf_test = LogisticRegression(max_iter=1000, multi_class='multinomial')
# 带入全部数据进行训练
clf_test.fit(X, y)
# 查看线性方程系数
clf_test.coef_
# 在全部数据集上进行预测
clf_test.predict(X)[:10]
# 查看概率预测结果
clf_test.predict_proba(X)[:10]
2.4 sklearn中的构建机器学习流
所谓机器学习流,其实就指的是将多个机器学习的步骤串联在一起,形成一个完整的模型训练流程。在sklearn中,我们可以借助其make_pipline类的相关功能来实现,当然需要注意的是,sklearn中只能将评估器类进行串联形成机器学习流,而不能串联实用函数,并且最终串联的结果其实也等价于一个评估器。当然,这也从侧面说明sklearn评估器内部接口的一致性。接下来,我们就利用sklearn中构建机器学习流的方法将上述数据归一化、逻辑回归进行多分类建模等过程串联在一起,并提前进行数据切分,即执行一个更加完整的机器学习建模流程。
学习流的构建
from sklearn.pipeline import make_pipeline
# 在make_pipeline中输入评估器的过程同时对评估器类进行参数设置
pipe = make_pipeline(StandardScaler(),LogisticRegression(max_iter=1000))
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
pipe.fit(X_train, y_train)
pipe.predict(X_test)
pipe.score(X_test, y_test)
pipe.score(X_train, y_train)
当模型构建完毕之后,我们即可借助joblib包来进行sklearn的模型存储和读取,相关功能非常简单,我们可以使用dump函数进行模型保存,使用load函数进行模型读取:
import joblib
joblib.dump(pipe,'pipe.model')
pipe1 = joblib.load('pipe.model')
pipe1.score(X_train, y_train)
3 正则化与sklearn逻辑回归参数详解
3.1 过拟合、正则化、特征衍生与特征重要性评估
3.1.1 正则化(Regularization)的基本概念

从说明文档中得知,就是在sklearn中,逻辑回归模型是默认进行正则化的,即上文所述“Regularization is applied by default”,这是一种在机器学习建模过程中常见的用法,但并非统计学常用方法。据此我们也知道了统计学和机器学习方法之间的又一个区别,并且能够清楚的感受到sklearn是一个非常“机器学习”的算法库,很多时候会从便于机器学习建模的角度出发对算法进行微调,而这也是sklearn算法库的一大特性,这个特性在导致其非常易用的同时,也使得其很多算法和原始提出的算法会存在略微的区别,这点也是初学者需要注意的。
- 什么是正则化/如何进行正则化
其实机器学习中正则化(regularization)的外在形式非常简单,就是在模型的损失函数中加上一个正则化项(regularizer),有时也被称为惩罚项(penalty term),如下方程所示,其中L为损失函数,J为正则化项。通常来说,正则化项往往是关于模型参数的1-范数或者2-范数,当然也有可能是这两者的某种结合,例如sklearn的逻辑回归中的弹性网正则化项,其中加入模型参数的1-范数的正则化也被称为 l 1 l1 l1正则化,加入模型参数的2-范数的正则化也被称为 l 2 l2 l2正则化。
1 N ∑ i = 1 N L ( y i , f ( x i ) ) + λ J ( f ) \frac{1}{N}\sum^{N}_{i=1}L(y_i,f(x_i))+\lambda J{(f)} N1i=1∑NL(yi,f(xi))+λJ(f) - 为何需要正则化
一般来说,正则化核心的作用是缓解模型过拟合倾向,此外,由于加入正则化项后损失函数的形体发生了变化,因此也会影响损失函数的求解过程,在某些时候,加入了正则化项之后会让损失函数的求解变得更加高效。如此前介绍的岭回归,其实就是在线性回归的损失函数基础上加入了w的1-范数,而Lasso则是加入了w的2-范数。并且,对于逻辑回归来说,如果加入 l 2 l2 l2正则化项,损失函数就会变成严格的凸函数。 - 经验风险与结构风险
要讨论正则化是如何缓解过拟合倾向的问题,需要引入两个非常重要的概念:经验风险和结构风险。
在我们构建损失函数求最小值的过程,其实就是依据以往经验(也就是训练数据)追求风险最小(以往数据误差最小)的过程,而在给定一组参数后计算得出的损失函数的损失值,其实就是经验风险。而所谓结构风险,我们可以将其等价为模型复杂程度,模型越复杂,模型结构风险就越大。而正则化后的损失函数在进行最小值求解的过程中,其实是希望损失函数本身和正则化项都取得较小的值,即模型的经验风险和结构风险能够同时得到控制。
模型的经验风险需要被控制不难理解,因为我们希望模型能够尽可能的捕捉原始数据中的规律,但为何模型的结构风险也需要被控制?核心原因在于,尽管在一定范围内模型复杂度增加能够有效提升模型性能,但模型过于复杂可能会导致另一个非常常见的问题——模型过拟合,关于模型过拟合的概念我们稍后会进行更加详细的介绍,但总的来说,一旦模型过拟合了,尽管模型经验风险在降低、但模型的泛化能力会下降。因此,为了控制模型过拟合倾向,我们可以把模型结构风险纳入损失函数中一并考虑,当模型结构风险的增速高于损失值降低的收益时,我们就需要停止参数训练(迭代)。
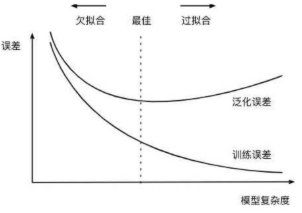
同时要求模型性能和模型复杂度都在一个合理的范围内,其实等价于希望训练得到一个较小的模型同时具有较好的解释数据的能力(规律捕捉能力),这也符合奥卡姆剃刀原则。
3.1.2 过拟合概念介绍
此前我们曾深入探讨过关于机器学习建模有效性的问题,彼时我们得出的结论是当训练数据和新数据具有规律的一致性时,才能够进行建模,而只有挖掘出贯穿始终的规律(同时影响训练数据和新数据的规律),模型才能够进行有效预测。不过,既然有些贯穿始终的全局规律,那就肯定存在一些只影响了一部分数据的局部规律。一般来说,由于全局规律影响数据较多,因此更容易被挖掘,而局部规律只影响部分数据,因此更难被挖掘,因此从较为宽泛的角度来看,但伴随着模型性能提升,也是能够捕获很多局部规律的。但是需要知道的是,局部规律对于新数据的预测并不能起到正面的作用,反而会影响预测结果,此时就出现模型过拟合现象。
3.1.3 正则化进行特征筛选与缓解过拟合倾向
我们发现,在回归模型中中Lasso的惩罚力度更强,并且迅速将一些参数清零,而这些被清零的参数,则代表对应的参数在实际建模过程中并不重要,从而达到特种重要性筛选的目的。而在实际的建模过程中,l2正则化往往应用于缓解过拟合趋势,而l1正则化往往被用于特征筛选的场景中。
其实特征重要性和(线性方程中)特征对应系数大小并没有太大的关系,判断特种是否重要的核心还是在于观察抛弃某些特征后,建模结果是否会发生显著影响。
有上述过程,我们不难发现,l2缓解过拟合效果更好(相比l1正则化,l2正则化在参数筛选时过程更容易控制),而l1正则化的运算结果说明,上述10个特征中,第一个、第三个和最后一个特征相对重要。而特征重要的含义,其实是代表哪怕带入上述3个特征建模,依然能够达到带入所有特征建模的效果。从上述过程中,我们其实能够总结一套建模策略:
- 当模型效果(往往是线性模型)不佳时,可以考虑通过特征衍生的方式来进行数据的“增强”;
- 如果出现过拟合趋势,则首先可以考虑进行不重要特征的筛选,过多的无关特征其实也会影响模型对于全局规律的判断,当然此时可以考虑使用l1正则化配合线性方程进行特征重要性筛选,剔除不重要的特征,保留重要特征;
- 对于过拟合趋势的抑制,仅仅踢出不重要特征还是不够的,对于线性方程类的模型来说,l2正则化则是缓解过拟合非常好的方法,配合特征筛选,能够快速的缓解模型过拟合倾向;
当然,除此以外,还有一些注意事项:
- 首先,哪怕不进行特征筛选,l2正则化也可以帮助线性方程抑制过拟合,但特征太多其实会影响l2正则化的参数取值范围,进而影响alpha参数惩罚力度的有效性;
- 其次,上述参数的选取和过拟合倾向的判断,其实还是主观判断成分较多,一个更加严谨的流程是,先进行数据集的划分,然后选取更能表示模型泛化能力的评估指标,然后将特征提取(如果要做的话)、l2正则化后的线性方程组成一个Pipeline,再利用网格搜索,确定一组最优的参数组合。相关方法我们会在下一小节进行介绍。
- 最后,需要强调的是,并非所有模型都需要/可以通过正则化来进行过拟合修正,典型的可以通过正则化来进行过拟合倾向修正的模型主要有线性回归、逻辑回归、LDA、SVM以及一些PCA衍生算法(如SparsePCA)。而树模型则不用通过正则化来进行过拟合修正。
3.2 sklearn中逻辑回归的参数解释
在补充了关于正则化的相关内容之后,接下来,我们来详细讨论关于逻辑回归的参数解释。

3.2.1 说明文档中的内容解释
- sklearn中逻辑回归损失函数形态
在了解了正则化的相关内容后,接下来我们观察sklearn官网中给出的逻辑回归加入正则化后的损失函数表达式,我们发现该表达式和此前我们推到的交叉熵损失函数的表达式还是略有差异,核心原因是sklearn在二分类的时候默认两个类别的标签取值为-1和1,而不是0和1。 - 正则化后损失函数表达式
相比原始损失函数,正则化后的损失函数有两处发生了变化,其一是在原损失函数基础上乘以了系数C,其二则是加入了正则化项。其中系数C也是超参数,需要人工输入,用于调整经验风险部分和结构风险部分的权重,C越大,经验风险部分权重越大,反之结构风险部分权重越大。此外,在 l 2 l2 l2正则化时,采用的 w T w 2 \frac{w^Tw}{2} 2wTw表达式,其实相当于是各参数的平方和除以2,在求最小值时本质上和w的2-范数起到的作用相同,省去开平方是为了简化运算,而除以2则是为了方便后续求导运算,和2次方结果相消。
另外,sklearn中还提供了弹性网正则化方法,其实是通过 ρ \rho ρ控制 l 1 l1 l1正则化和 l 2 l2 l2正则化惩罚力度的权重,是一个更加综合的解决方案。不过代价是增加了一个超参数 ρ \rho ρ,并且由于损失函数形态发生了变化,导致部分优化方法无法使用。
3.2.2 sklearn中逻辑回归评估器的参数解释
| 参数 | 解释 |
|---|---|
| penalty | 正则化项 |
| dual | 是否求解对偶问题* |
| tol | 迭代停止条件:两轮迭代损失值差值小于tol时,停止迭代 |
| C | 经验风险和结构风险在损失函数中的权重 |
| fit_intercept | 线性方程中是否包含截距项 |
| intercept_scaling | 相当于此前讨论的特征最后一列全为1的列,当使用liblinear求解参数时用于捕获截距 |
| class_weight | 各类样本权重* |
| random_state | 随机数种子 |
| solver | 损失函数求解方法* |
| max_iter | 求解参数时最大迭代次数,迭代过程满足max_iter或tol其一即停止迭代 |
| multi_class | 多分类问题时求解方法* |
| verbose | 是否输出任务进程 |
| warm_start | 是否使用上次训练结果作为本次运行初始参数 |
| l1_ratio | 当采用弹性网正则化时, l 1 l1 l1正则项权重,就是损失函数中的 ρ \rho ρ |
- dual:是否求解对偶问题
对偶问题是约束条件相反、求解方向也相反的问题,当数据集过小而特征较多时,求解对偶问题能一定程度降低运算复杂度,其他情况建议保留默认参数取值。 - class_weight:各类样本权重
class_weight其实代表各类样本在进行损失函数计算时的数值权重,例如假设一个二分类问题,0、1两类的样本比例是2:1,此时可以输入一个字典类型对象用于说明两类样本在进行损失值计算时的权重,例如输入:{0:1, 1:3},则代表1类样本的每一条数据在进行损失函数值的计算时都会在原始数值上*3。而当我们将该参数选为balanced时,则会自动将这个比例调整为真实样本比例的反比,以达到平衡的效果。 - solver:损失函数求解方法
其实除了最小二乘法和梯度下降以外,还有非常多的关于损失函数的求解方法,而选择损失函数的参数,就是solver参数。
而当前损失函数到底采用何种优化方法进行求解,其实最终目的是希望能够更快(计算效率更高)更好(准确性更高)的来进行求解,而硬性的约束条件是损失函数的形态,此外则是用户自行选择的空间。
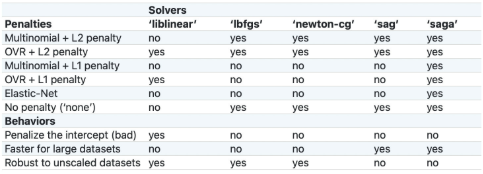
逻辑回归可选的优化方法包括:
liblinear,这是一种坐标轴下降法,并且该软件包中大多数算法都有C++编写,运行速度很快,支持OVR+L1或OVR+L2;
lbfgs,全称是L-BFGS,牛顿法的一种改进算法(一种拟牛顿法),适用于小型数据集,并且支持MVM+L2、OVR+L2以及不带惩罚项的情况;
newton-cg,同样也是一种拟牛顿法,和lbfgs适用情况相同;
sag,随机平均梯度下降,随机梯度下降的改进版,类似动量法,会在下一轮随机梯度下降开始之前保留一些上一轮的梯度,从而为整个迭代过程增加惯性,除了不支持L1正则化的损失函数求解以外(包括弹性网正则化)其他所有损失函数的求解;
saga,sag的改进版,修改了梯度惯性的计算方法,使得其支持所有情况下逻辑回归的损失函数求解;
对于逻辑回归来说,求解损失函数的硬性约束其实就是多分类问题时采用的策略以及加入的惩罚项,所以大多数情况,我们会优先根据多分类问题的策略及惩项来选取优化算法,其次,如果有多个算法可选,那么我们可以根据其他情况来进行求解器的选取,如:
Penalize the intercept (bad),如果要对截距项也进行惩罚,那只能选取liblinear;
Faster for large datasets,如果需要对海量数据进行快速处理,则可以选取sag和saga;
Robust to unscaled datasets,如果未对数据集进行标准化,但希望维持数据集的鲁棒性(迭代平稳高效),则可以考虑使用liblinear、lbfgs和newton-cg三种求解方法。
- multi_class:选用何种方法进行多分类问题求解
可选OVR和MVM,当然默认情况是auto,此时模型会优先根据惩罚项和solver选择OVR还是MVM,但一般来说,MVM效果会好于OVR。
至此,我们即完成逻辑回归所有参数的解释,当然对于这些参数更深层次的理解,则需要长期的积淀、以及其他知识的补充。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)