机器学习——学习笔记:词汇理解Day2
平方误差 vs 对数损失
平方误差(Squared Error)和对数损失(Log Loss,又称交叉熵损失)是机器学习中两种最常用的损失函数,它们的核心作用是量化 “模型预测值” 与 “真实值” 之间的差距,但适用场景和计算逻辑有显著差异。
一、平方误差(Squared Error)
1、含义:衡量 “数值差异的平方”
平方误差的计算逻辑非常直观:先求 “预测值与真实值的差”,再对这个差值求平方。对于单个样本,公式为:
![]()
若要计算整个数据集的损失,通常取平均值(均方误差 MSE):
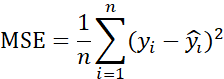
2、核心特点:
对 “大误差” 更敏感:由于做了平方运算,较大的误差会被放大,而小误差影响较小,甚至更小,如。
例:
真实值 = 10,预测值 = 8 → 误差 = 2 → 平方误差 = 4
真实值 = 10,预测值 = 5 → 误差 = 5 → 平方误差 = 25(误差放大了 5 倍)
输出是 “连续数值”:平方误差要求模型的预测结果是连续的实数(如房价、温度),而非概率或类别。
3、应用场景:回归任务
平方误差是回归问题的首选损失函数,即当目标是预测 “连续数值” 时使用。
4、典型模型:线性回归、多项式回归、神经网络(回归任务)等。
二、对数损失(Log Loss / 交叉熵损失)
1、含义:衡量 “概率分布的差异”
对数损失专门用于分类任务,核心是计算 “模型预测的概率分布” 与 “真实标签的概率分布” 之间的差距。根据分类类型(二分类 / 多分类),公式略有不同:
二分类场景:真实标签y是 0 或 1(0 表示负类,1 表示正类),模型输出 “样本属于正类的概率”p(0≤p≤1)。单个样本的对数损失公式:
L对数损失=−[y⋅log(p)+(1−y)⋅log(1−p)]
当y=1(真实为正类):公式简化为-log(p),p越接近 1,损失越小;
当y=0(真实为负类):公式简化为-log(1-p),p越接近 0,损失越小。
多分类场景:真实标签用独热编码表示(如 3 类时y=[1,0,0]表示属于第 1 类),模型输出 “每个类别的概率分布”p₁,p₂,...,pₖ(总和为 1)。单个样本的对数损失公式:
![]()
2、核心特点:
对 “错误预测” 的惩罚更直接:当预测概率与真实标签完全相反时(如真实为 1,预测 p=0.1),损失会急剧增大(-log(0.1)≈2.3);而预测准确时(p=0.9),损失很小(-log(0.9)≈0.1)。
输出是 “概率”:对数损失要求模型输出概率值(或可转化为概率的分数),而非直接的类别标签。
3、应用场景:分类任务
对数损失是分类问题的首选损失函数,即当目标是预测 “离散类别” 时使用:
(1)二分类:垃圾邮件识别(是 / 否)、疾病诊断(患病 / 健康)、欺诈交易检测(是 / 否)
(2)多分类:手写数字识别(0-9)、图片分类(猫 / 狗 / 鸟)、用户兴趣标签(科技 / 娱乐 / 教育)
4、典型模型:逻辑回归、XGBoost(分类模式)、SVM(概率输出)、神经网络(分类任务)等。
三、关键区别与选择依据
|
维度 |
平方误差(Squared Error) |
对数损失(Log Loss) |
|
预测目标类型 |
连续数值(回归任务) |
离散类别(分类任务) |
|
模型输出形式 |
直接预测数值(如房价 = 200 万) |
预测概率(如属于正类的概率 = 0.8) |
|
对误差的敏感性 |
对大误差更敏感(平方放大) |
对错误预测的概率更敏感(对数放大) |
|
适用模型 |
线性回归、回归树、神经网络(回归) |
逻辑回归、分类树、神经网络(分类)、XGBoost(分类) |
|
典型场景 |
房价预测、销量预测、温度预测 |
垃圾邮件识别、疾病诊断、手写数字识别 |
四、为什么 “分类不用平方误差,回归不用对数损失”?
1、分类任务不用平方误差:分类模型的输出是概率(如 sigmoid 函数输出 0~1 的概率),平方误差会导致梯度不稳定(当预测概率接近 0 或 1 时,梯度几乎为 0,模型难以优化)。而对数损失的梯度与 “预测误差” 直接相关,能高效引导模型学习。
2、回归任务不用对数损失:回归的目标是连续数值(如 100、200),无法用 “概率分布” 表示,对数损失的公式(基于 log 函数)也不适用于非概率的输出。平方误差能直接量化数值差异,更符合回归任务的目标。
总结
1、平方误差:适合 “预测连续数值”,核心是衡量 “数值差的平方”,对大误差敏感,是回归任务的标配。
2、对数损失:适合 “预测离散类别”,核心是衡量 “概率分布的差异”,对错误预测敏感,是分类任务的标配。
选择的核心依据是任务类型:预测连续值用平方误差,预测类别用对数损失。
学习率
学习率(Learning Rate,常用符号η表示)是机器学习中控制模型参数更新幅度的关键超参数,可以理解为模型 “调整参数的步长”。
场景切入
你站在半山腰(当前模型参数),想最快走到山底(损失函数最小值,即最优参数);
梯度(Gradient)告诉你 “往哪个方向走”(梯度的反方向);
学习率则告诉你 “每一步走多大”(步长)。
不同学习率的效果差异:
(1)学习率太小(如 η=0.0001):就像小碎步走路,每一步移动距离很短,需要走很多步才能到山底(训练效率低,耗时久);
(2)学习率太大(如 η=10):就像大步跨跳,可能一步跨过山底,甚至跑到对面山坡上(参数更新幅度过大,损失值震荡甚至上升,无法收敛);
(3)学习率适中(如 η=0.01):步长合理,能快速逼近山底,且不会跨过头(训练效率高,易收敛到最优解)。
一、数学视角:学习率如何影响参数更新
在梯度下降算法中,参数更新公式为:
![]()
其中:
w是模型参数(如权重、偏置);
∇L(w)是损失函数在当前参数处的梯度(方向 + 陡峭程度);
η就是学习率,直接决定 “参数调整的幅度”:
梯度∇L(w)的大小固定时,η越大,参数更新幅度越大;
梯度为正时,参数会减小(减号作用);梯度为负时,参数会增大,最终向损失减小的方向调整。
二、学习率的核心作用:平衡 “收敛速度” 与 “收敛稳定性”
学习率是控制模型训练过程的 “旋钮”,核心作用是在 “快速收敛” 和 “稳定收敛” 之间找平衡:
(1)影响收敛速度:学习率太小,参数更新慢,需要更多迭代次数才能达到损失最小值(训练时间长);学习率太大,参数更新快,可能在较少迭代次数内接近最优解(但风险高)。
(2)影响收敛稳定性:学习率太小,参数调整平稳,不易震荡,但可能陷入 “局部最小值”(比如卡在小山谷里走不出来);学习率太大,参数调整剧烈,损失值可能在最小值附近来回震荡,甚至发散(损失越来越大)。
三、如何选择合适的学习率?
没有 “万能的最佳学习率”,需要根据模型和数据调整,常见策略:
1、初始学习率的经验值
大多数场景:η=0.01(经典默认值,适用性广);
数据简单 / 模型简单(如线性回归):可尝试η=0.1;
数据复杂 / 模型复杂(如深层神经网络):可尝试η=0.001或更小。
2、学习率调度(Learning Rate Scheduling):动态调整学习率
实际训练中,固定学习率往往不是最优解,通常会采用 “动态调整策略”:
(1)衰减策略:随着训练进行,逐渐减小学习率(如每迭代 100 次,学习率乘以 0.9)。
—— 前期用较大学习率快速逼近最优解,后期用较小学习率精细调整,避免震荡。
(2)阶梯式衰减:设定多个 “里程碑”,到达后学习率按比例下降(如迭代到 5000 步,学习率从 0.01→0.001)。
(3)自适应学习率算法:让模型自动调整学习率(无需手动设置),如 Adam、RMSprop、Adagrad 等。
这些算法会根据梯度的历史信息动态调整步长(梯度大时步长小,梯度小时步长大),稳定性和效率都优于固定学习率。
3、学习率的 “试错法”
最实用的方法是通过实验找到合适的学习率:
从一个较小的学习率(如 0.001)开始,观察损失曲线:
若损失下降缓慢,逐步增大学习率(如 0.005→0.01→0.05);
若损失开始震荡或上升,立即减小学习率(如从 0.1 降到 0.01)。
绘制 “学习率 - 损失” 曲线:在训练初期,尝试不同学习率,记录对应的损失变化,选择 “损失下降最快且稳定” 的学习率。
四、常见问题与解决
1、学习率太小导致的问题:
症状:损失下降极慢,训练很久仍未收敛;
解决:增大学习率(如从 0.0001→0.001),或改用自适应学习率算法(如 Adam)。
2、学习率太大导致的问题:
症状:损失值剧烈震荡,甚至越来越大(不收敛);
解决:减小学习率(如从 0.1→0.01),并增加迭代次数。
3、学习率合适但后期收敛慢:
症状:前期损失下降快,后期几乎不变(卡在局部最优);
解决:采用学习率衰减策略(如每 10 轮衰减为原来的 0.5),让后期精细化调整。
总结
学习率是模型训练的 “步长控制器”:
本质:控制参数更新的幅度,平衡 “收敛速度” 和 “稳定性”;
核心原则:既不能太小(效率低),也不能太大(易震荡);
实用策略:初期可尝试经验值(如 0.01),结合动态衰减或自适应算法(如 Adam),通过实验找到适合当前任务的学习率。
损失函数
损失函数(Loss Function)是机器学习中衡量模型预测结果与真实结果差距的工具,相当于给模型一个 “评分标准”—— 预测越准,得分(损失值)越低;预测越差,得分越高。模型训练的核心目标,就是通过调整参数不断 “降低这个得分”。
场景切入
假设你是老师,给学生批改作业:
- 学生答案与标准答案完全一致 → 差距 0(损失值 0);
- 学生答案错了一点(如计算错一个数字) → 差距小(损失值小);
- 学生答案完全错误(如答非所问) → 差距大(损失值大)。
这里的 “差距” 就是损失函数计算的核心,不同的 “评分标准”(如严格扣分、宽松扣分)对应不同的损失函数。
一、损失函数的核心作用
1、量化误差:将 “预测与真实的差异” 转化为具体数值(损失值),让模型能 “感知” 自己的表现;
2、引导优化:模型通过损失函数的 “梯度”(变化方向)调整参数,逐步降低损失值(让预测更准);
3、适配任务:不同任务(分类、回归等)需要不同的损失函数(就像不同考试有不同评分标准)。
二、常见损失函数及适用场景
根据任务类型(回归 / 分类),损失函数可分为几大类:
1、回归任务(预测连续数值,如房价、温度)
回归任务的目标是预测 “连续的实数”,损失函数需衡量 “数值差异”:
-
均方误差(MSE, Mean Squared Error)公式:
——yi是真实值,y_i是预测值,n 是样本数- 特点:对 “大误差” 惩罚更重(平方放大),适合大多数回归场景(如房价预测)。
-
平均绝对误差(MAE, Mean Absolute Error)公式:
-
特点:对异常值更稳健(不平方),适合数据中存在极端值的场景(如收入预测,少数人收入极高)。
-
-
Huber 损失(平滑 L1 损失)公式:
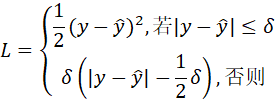
-
特点:结合 MSE 和 MAE 优势,小误差用平方(光滑易优化),大误差用绝对值(抗异常值),适合自动驾驶等对异常值敏感的场景。
2、分类任务(预测离散类别,如垃圾邮件 / 正常邮件)
分类任务的目标是预测 “离散类别”,损失函数需衡量 “概率分布差异”:
-
交叉熵损失(Cross Entropy Loss,又称对数损失)
-
二分类公式:
-
y_i是真实标签 0/1,p_i是预测为 1 的概率
-
-
多分类公式:
-
y_ik是第 i 个样本是否属于类别 k,p_ik是预测概率
-
特点:直接衡量 “预测概率与真实类别的匹配度”,是分类任务的首选(如逻辑回归、XGBoost 分类)。
-
-
-
Hinge 损失(合页损失)公式(二分类,标签为 1/-1):
-
y_i是模型输出的得分,非概率
-
特点:更关注 “分类正确与否” 而非概率精准度,是 SVM(支持向量机)的默认损失函数。
-
-
Focal Loss公式:
-
α平衡类别比例,γ聚焦难分类样本
-
特点:解决 “类别不平衡” 问题(如 1% 正样本,99% 负样本),让模型更关注少数类和难分类样本,常用于目标检测。
-
三、选择损失函数的核心原则
1、匹配任务类型:回归用 MSE/MAE,分类用交叉熵,这是最基本的准则
2、考虑数据特点:
- 数据有异常值 → 选 MAE/Huber 损失(抗极端值);
- 类别不平衡 → 选 Focal Loss 或带权重的交叉熵;
3、兼顾优化难度:MSE 比 MAE 更 “光滑”(导数连续),训练时更容易收敛;
4、贴合业务目标:比如预测用户流失时,“漏判一个高价值用户” 的损失可能远大于 “误判一个低价值用户”,需自定义损失函数(如给高价值用户错误加权重)。
四、自定义损失函数
在复杂场景中,内置损失函数可能无法满足需求,此时可自定义损失函数,例如:
- 电商销量预测:高估损失(备货过多)和低估损失(缺货)不同,可设计
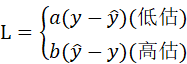
其中,a,b根据业务成本设定。
- 风控场景:将 “漏判欺诈用户” 的损失设为 “误判正常用户” 的 10 倍,加大对漏判的惩罚。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)