元数据-Apache Gravitino 多模态统一元数据
·
以下是关于 Apache Gravitino 统一元数据之统一血缘的详细总结,基于提供的网页内容整理:
📚 一、多云与 AI 时代的数据治理挑战
企业面临三大核心痛点:
- 数据孤岛问题
- 多云架构(私有云+公有云)导致数据天然割裂,叠加跨境数据合规要求(如GDPR),加剧数据隔离。
- 数据源类型多样化
- 企业数据涵盖传统数据库、数据仓库、实时/离线数据湖、AI非结构化数据(文本/图片/音视频),统一管理难度大。
- 元数据信息被忽视
- 元数据(如数据连接信息、属主、权限、分类分级、生命周期)是数据价值的“冰山之下”,缺乏管理将影响数据使用效率与合规性。
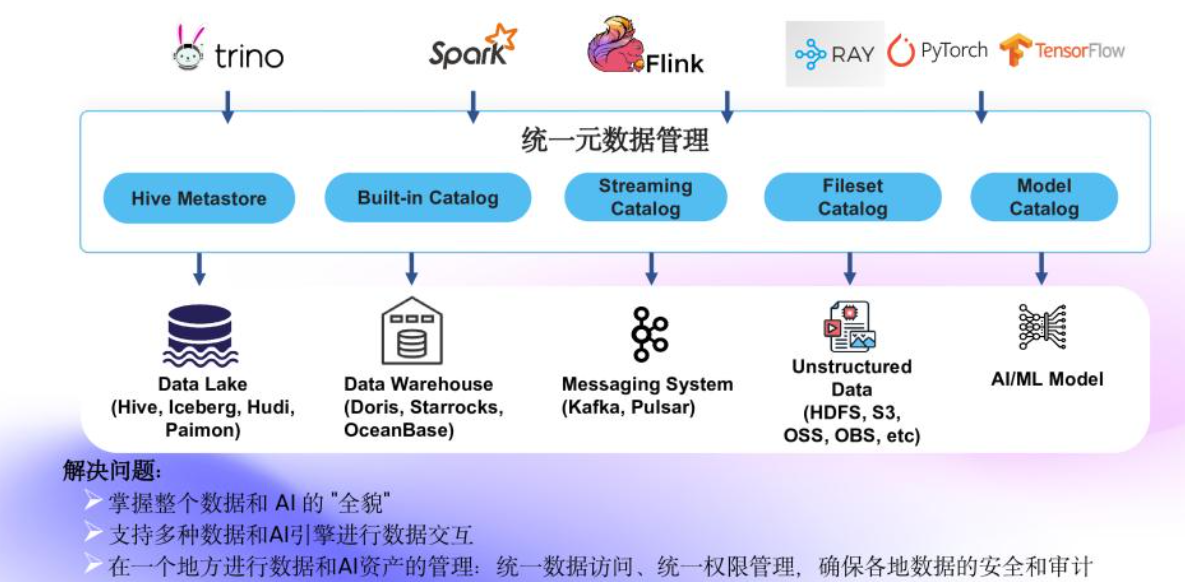
🛠️ 二、Apache Gravitino 统一元数据架构
1. 项目定位
- 统一支持多源异构元数据湖(Metadata Lake),兼容主流数据湖(Hive/Iceberg/Hudi/Paimon)、数据仓库(Doris/StarRocks)、消息队列(Kafka),并扩展至非结构化数据(Fileset Catalog)和AI模型(Model Catalog)。
- 通过RESTful API、SDK及Connector接入引擎(如Spark/Flink)和AI生态(PyTorch/TensorFlow),实现元数据统一管理。
2. 核心架构
- Metalake:联邦数据目录,整合多数据源形成统一元数据层。
- 访问层:
- 表格数据:支持SQL操作元数据与数据增删改查。
- 非表格数据:通过虚拟文件系统(GVFS)屏蔽底层存储差异(如S3/HDFS/OSS),提供逻辑目录访问。
- 标准化管理:为数据资产分配全局唯一坐标
<catalog.schema.asset>,降低物理连接复杂度。 - 安全管控:统一授权鉴权,满足数据治理合规要求。
🔗 三、统一数据血缘的价值
- 提升数据质量与可信度
- 完整追溯数据从产生到应用的全链路,快速定位异常根源(如报表错误溯源至原始数据采集问题)。
- 强化合规与风险管控
- 记录敏感数据流转路径(系统→加工环节→业务引用),确保符合GDPR等法规要求,降低审计风险。
- 优化资产利用与业务协同
- 打破数据孤岛,减少重复劳动;支持数据模型优化与系统升级,提升业务响应速度。
⚙️ 四、统一数据血缘的实现方案
1. 技术框架:OpenLineage + Gravitino
- OpenLineage:标准化血缘采集协议,定义核心概念:
Dataset(数据实体)、Job(处理任务)、Run(任务实例)、Facet(扩展元数据)。- 通过事件机制(Start Event + Complete Event)构建血缘关系。
- Gravitino 集成:
- 提供Lineage API接收OpenLineage事件,通过Processor扩展机制自定义血缘转换规则。
- 支持Spark引擎自动化采集(Hive/Iceberg/MySQL/Fileset等),Flink/Trino支持规划中。
2. 核心优势
- 标准化采集:通过OpenLineage插件兼容多引擎。
- 统一命名空间:物理数据源映射为逻辑名称,解决血缘图混乱问题。
- 灵活处理管道:自定义Processor实现血缘转换规则。
💎 总结
Apache Gravitino通过统一元数据管理架构,解决了多云与AI时代的数据孤岛、多样化数据源治理难题,并基于OpenLineage实现标准化数据血缘追踪,为企业提供数据质量、合规性与资产利用的全方位提升。其开放社区模式有望推动元数据领域标准化进程。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)