《性能之巅:洞悉系统、企业与云计算》-CPU-笔记
《性能之巅:洞悉系统、企业与云计算》第一章(绪论)和第二章(方法)的笔记,请参考Part 1,第三章(操作系统)的笔记,请参考Part 2,第四章(观测工具)的笔记,请参考Part 3,第五章(应用程序)的笔记,请参考Part 4,本文是第六章——CPU。
当需求的CPU资源超过系统力所能及的范围时,进程里的线程(或任务)将会排队,等待轮候自己运行的机会。等待给应用程序的运行带来严重延时,使得性能下降。
从上层来说,可按进程、线程或任务来检查CPU用量。从下层来看,可剖析并研究应用程序和内核里的代码路径。在底层,可研究CPU指令的执行和周期行为。
术语
CPU相关术语如下:
- 处理器:插到系统插槽或处理器板上的物理芯片,以核或硬件线程的方式包含一块或多块CPU;
- 核:一颗多核处理器上的一个独立CPU实例。核的使用是处理器扩展的一种方式,又称为芯片级多处理(chip-level multiprocessing,CMP);
- 硬件线程:一种支持在一个核上同时执行多个线程(包括Intel超线程技术)的CPU架构,每个线程是一个独立的CPU实例。这种扩展的方法又称为多线程;
- CPU指令:单个CPU操作,来源于它的指令集。指令用于算术操作、内存I/O,以及逻辑控制;
- 逻辑CPU:又称为虚拟处理器,一个操作系统CPU的实例(一个可调度的CPU实体)。处理器可通过硬件线程(虚拟核)、一个核,或一个单核的处理器实现;
- 调度器:把CPU分配给线程运行的内核子系统;
- 运行队列:一个等待CPU服务的可运行线程队列。Solaris上常被称为分发器队列;
模型
CPU架构
单个处理器内共有四个核和八个硬件线程。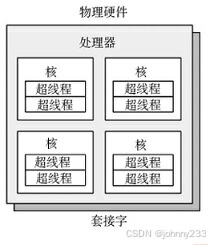
每个硬件线程都可以按逻辑CPU寻址,因此这个处理器看上去有八块CPU。对这种拓扑结构,操作系统可能有一些额外信息,如哪些CPU在同一个核上,可提高调度的质量。
CPU内存缓存
越小则速度越快,并且越靠近CPU。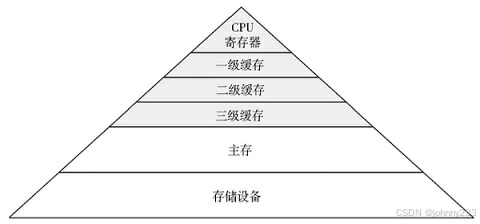
CPU运行队列
概念
时钟频率
时钟是一个驱动所有处理器逻辑的数字信号。每个CPU指令都可能会花费一或多个时钟周期(CPU周期)。有些处理器可改变时钟频率,升频以改进性能或降频以减少能耗。
更快的时钟频率并不一定会提高性能。
指令
一个指令包括以下步骤,每个都由CPU的一个叫作功能单元的组件处理:
- 指令预取
- 指令解码
- 执行
- 内存访问
- 寄存器写回
最后两步是可选的,取决于指令本身。许多指令仅仅操作寄存器,并不需要访问内存。这里每一步都至少需要一个时钟周期来执行。内存访问经常是最慢的,因为它通常需要几十个时钟周期读或写主存,在此期间指令执行陷入停滞(停滞期间的这些周期称为停滞周期)。这就是CPU缓存如此重要的原因:它可以极大地降低内存访问需要的周期数。
指令流水线
指令流水线是一种CPU架构,通过同时执行不同指令的不同部分,来达到同时执行多个指令的结果。
指令宽度
同一种类型的功能单元可以有好几个,这样每个时钟周期里就可以处理更多的指令。这种CPU架构被称为超标量,通常和流水线一起使用以达到高指令吞吐量。
指令宽度描述了同时处理的目标指令数量。现代处理器宽度一般为3或4,意味着它们可以在每个周期里最多完成3~4个指令。如何取得这个结果取决于处理器本身,每个环节都有不同数量的功能单元处理指令。
CPI,IPC
CPI:cycles per instruction,每指令周期数,描述CPU如何使用它的时钟周期,也可用来理解CPU使用率本质。
IPC:instructions per cycle,每周期指令数,CPI的倒数。
CPI较高代表CPU经常陷入停滞,通常都是在访问内存。CPI较低则代表CPU基本没有停滞,指令吞吐量较高。
内存访问密集的负载,提高性能的方法,如使用更快的内存(DRAM)、提高内存本地性(软件配置)、减少内存I/O数量。使用更高时钟频率的CPU并不能达到预期的性能目标,因为CPU还是需要为等待内存I/O完成而花费同样的时间。换句话说,更快的CPU意味着更多的停滞周期,而指令完成速率不变。
CPI的高低与否实际上和处理器以及处理器功能有关,可通过实验方法运行已知的负载得出。例如,你会发现高CPI的负载可以使CPI达到10或更高,而在低CPI的负载下,CPI低于1(受益于前述的指令流水线和宽度技术,这是可以达到的)。
CPI代表指令处理的效率,但并不代表指令本身的效率。假设有一个软件改动,加入一个低效率的循环,这个循环主要在操作CPU寄存器(没有停滞周期):这种改动可能会降低总体CPI,但会提高CPU的使用和利用度。
使用率
CPU使用率通过测量一段时间内CPU实例忙于执行工作的时间比例获得,以百分比表示。它也可以通过测量CPU未运行内核空闲线程的时间得出,这段时间内CPU可能在运行一些用户态应用程序线程,或其他的内核线程,或在处理中断。
高CPU使用率并不一定代表着问题,仅仅表示系统正在工作。有些人认为这是ROI的指示器:高度利用的系统被认为有着较好的ROI,而空闲的系统则是浪费。和其他类型的资源(磁盘)不同,在高使用率的情况下,性能并不会出现显著下降,因为内核支持优先级、抢占和分时共享。这些概念加起来让内核决定了什么线程的优先级更高,并保证它优先运行。
CPU使用率的测量包括了所有符合条件活动的时钟周期,包括内存停滞周期。虽然看上去有些违反直觉,但CPU有可能像前面描述的那样,会因为经常停滞等待I/O而导致高使用率,而不仅是在执行指令。
CPU使用率通常被分成内核时间和用户时间两个指标。
用户时间/内核时间
CPU花在执行用户态应用程序代码的时间称为用户时间,而执行内核态代码的时间称为内核时间。内核时间包括系统调用、内核线程和中断的时间。当在整个系统范围内进行测量时,用户时间和内核时间之比可揭示运行的负载类型。
计算密集型应用会把大量时间用在用户态代码上,用户/内核时间之比接近99/1。如:图像处理、基因组学和数据分析。
I/O密集型应用的系统调用频率较高,通过执行内核代码进行I/O操作。例如,一个进行网络I/O的Web服务器的用户/内核时间比大约为70/30。
饱和度
CPU饱和:100%使用率的CPU,线程在这种情况下会碰上调度器延时,需要等待才能在CPU上运行,降低总体性能。这个延时是线程花在等待CPU运行队列或其他管理线程的数据结构上的时间。
另一个CPU饱和度的形式则和CPU资源控制有关,这个控制会在云计算环境下发生。尽管CPU并没有100%地被使用,但已经达到控制的上限,因此可运行的线程就必须等待轮到它们的机会。这个过程对用户的可见度取决于使用的虚拟化技术。
一个饱和运行的CPU不像其他类型资源那样问题重重,因为更高优先级的工作可以抢占当前线程。
抢占
抢占允许更高优先级的线程抢占当前正在运行的线程,并开始执行。节省更高优先级工作的运行队列延时时间,提高性能。
优先级反转
优先级反转指的是一个低优先级线程拥有一项资源,从而阻塞高优先级线程运行的情况。高优先级工作被迫阻塞等待,性能降低。
Solaris内核实现了一套完整的优先级继承机制,以避免优先级反转。
Linux 2.6.18提供一个支持优先级继承的用户态mutex,用于实时负载。
多进程,多线程
大多数处理器都以某种形式提供多个CPU。对于想使用这个功能的应用程序来说,需要开启不同的执行线程以并发运行。对于一个64颗CPU的系统来说,这意味着一个应用程序如果同时用满所有CPU,可达到最快64倍的速度,或处理64倍的负载。应用程序可根据CPU数目进行有效放大的能力又称为扩展性。
应用程序在多CPU上扩展的技术分为多进程和多线程,对比见下表
| 属性 | 多进程 | 多线程 |
|---|---|---|
| 开发 | 较简单,使用fork() |
使用线程API |
| 内存开销 | 每个进程不同的地址空间消耗一些内存资源 | 小,只需要额外的栈和寄存器空间 |
| CPU开销 | fork()/exit()开销,MMU还需要管理地址空间 |
小,API调用 |
| 通信 | 通过IPC,导致CPU开销,包括为了在不同地址空间之间移动数据而导致的上下文切换,除非使用共享内存区域 | 最快。直接存储共享内存。通过同步原语保证数据一致性(如mutex锁) |
| 内存使用 | 虽然有一些冗余的内存使用,但不同的进程可以exit(),并向系统返还所有的内存 |
通过系统分配器。可能导致多线程之间的CPU竞争和内存碎片化问题 |
不管使用何种技术,重要的是要创建足够的进程或线程,以占据预期数量的CPU——如果要最大化性能,即所有的CPU。有些应用程序可能在更少的CPU上跑得更快,这是因为线程同步和内存本地性下降反而吞噬更多CPU资源。
字长
处理器是围绕最大字长(32或64位)设计的这是整数大小和寄存器宽度。字长也普遍使用,表示地址空间大小和数据通路宽度(有时也称为位宽),取决于不同的处理器实现。
更宽的字长意味着更好的性能,但也可能会在某些数据类型下因未使用的位而导致额外的内存开销。数据的大小也会因为指针大小的增加而增加,导致需要更多的内存I/O。对64位的x86架构来说,寄存器的增加和更有效的调用约定抵消这些开销,因此64位应用程序会比它们32位的版本跑得更快。
处理器和操作系统支持多种字长,可以同时运行编译成不同字长的应用程序。如果软件被编译成较小的字长,它可能会成功运行但是慢得多。
编译器优化
应用程序在CPU上的运行时间可通过编译器选项(包括字长设置)来大幅改进。编译器也频繁地更新以利用最新的CPU指令集以及其他优化。有时应用程序性能可通过使用新的编译器显著地提高。
架构
硬件
CPU硬件包括处理器和它的子系统,以及多处理器之间的CPU互联。
通用双核处理器组件构成如下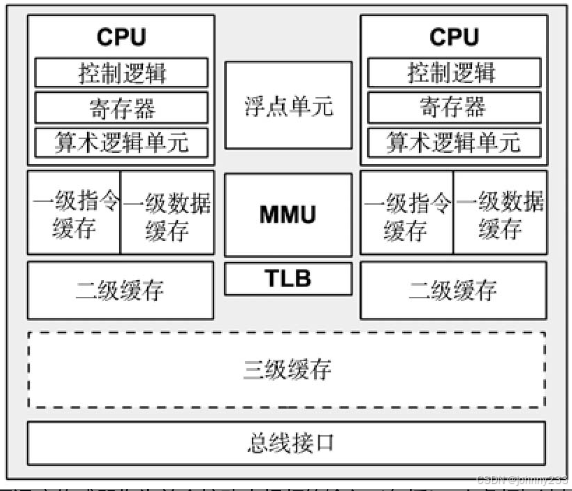
相联性是定位缓存新条目范围的一种缓存特性,类型如下:
- 全关联:缓存可在任意地方放置新条目。例如,一个LRU算法可以剔除整个缓存里最老的条目;
- 直接映射:每个条目在缓存里只有一个有效的地方,例如,对内存地址使用一组地址位进行哈希,得出缓存中的地址;
- 组关联:首先通过映射(例如哈希)定位出缓存中一组地址,然后再对这些使用另一个算法(例如LRU)。这个方法通过组大小描述。例如,四路组关联把一个地址映射到四个可能的地方,然后在这四个地方中挑选最合适的一个。
CPU缓存经常使用组关联方法,在全关联(开销过大)与直接映射(命中过低)中间找一个平衡点。
互联可连接除了处理器之外的组件,如I/O控制器。例子包括Intel的快速通道互联(Quick Path Interconnect,QPI)和AMD的HyperTransport(HT)。一个四处理器系统的Intel QPI架构示例如图所示。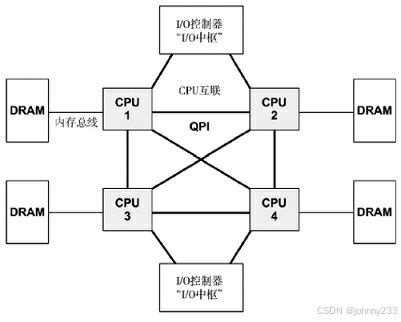
处理器之间的私有连接提供无须竞争的访问以及比共享系统总线更高的带宽。
CPC:CPU Performance Counter,CPU性能计数器,有许多别名,包括性能测量点计数器(PIC)、性能监控单元(PMU)、硬件事件和性能监控事件。它们是可以计数低级CPU活动的处理器寄存器。通常包括下列计数器:
- CPU周期:包括停滞周期和停滞周期类型;
- CPU指令:引退的(执行过的);
- 一级、二级、三级缓存访问:命中,未命中;
- 浮点单元:操作;
- 内存I/O:读、写、停滞周期;
- 资源I/O:读、写、停滞周期。
软件
支撑CPU的内核软件包括调度器、调度器类和空闲线程(空闲任务)。
调度器
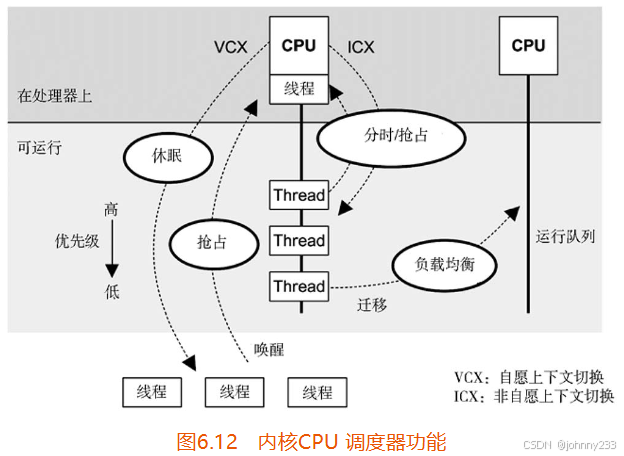
功能:
- 分时:可运行线程之间的多任务,优先执行最高优先级任务;
- 抢占:一旦有高优先级线程变为可运行状态,调度器能够抢占当前运行的线程,这样较高优先级的线程可以马上开始运行;
- 负载均衡:把可运行的线程移到空闲或较不繁忙的CPU队列中。
在Linux上,分时通过系统时钟中断调用scheduler_tick()实现。这个函数调用调度器类函数管理优先级和称为时间片的CPU时间单位的到期事件。当线程状态变成可运行后,就触发抢占,调度类函数check_preempt_curr()被调用。线程的切换由__schedule()管理,后者通过pick_next_task()选择最高优先级的线程运行。负载均衡由load_balance()负责执行。
调度类
调度类管理可运行线程的行为,特别是它们的优先级,还有CPU时间是否分片,以及这些时间片的长度(时间量子)。通过调度策略还可施加其他控制,在一个调度器内进行选择,控制同一个优先级线程间的调度。
用户线程优先级受一个用户定义的nice值影响。在Linux上,nice值设置线程的静态优先级,与调度器计算的动态优先级有所区别。
Linux和Solaris的内核优先级范围是相反的。原来的UNIX优先级范围(第6版)把较小数字用在高优先级线程上,Linux继承这一点。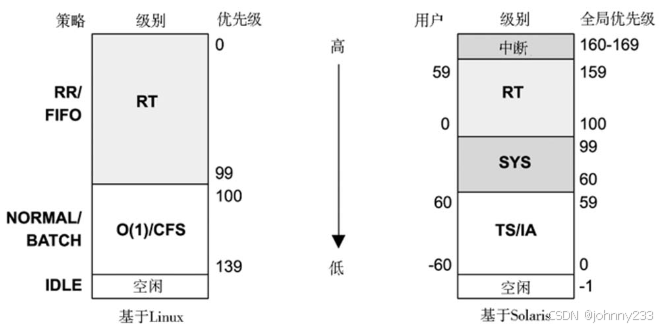
Linux内核调度器类:
- RT:为实时类负载提供固定的高优先级。内核支持用户和内核级别的抢占,允许RT任务以短延时分发。优先级范围为0~99(MAX_RT_PRIO-1)。
- O(1): O ( 1 ) O(1) O(1)调度器在Linux 2.6作为默认用户进程分时调度器引入。先前的调度器包含一个遍历所有任务的函数,算法复杂度为 O ( n ) O(n) O(n),扩展性有问题。相对于CPU消耗型线程, O ( 1 ) O(1) O(1)调度器动态地提高I/O消耗型线程的优先级,以降低交互和I/O负载的延时。
- CFS:Linux 2.6.23引入完全公平调度作为默认用户进程分时调度器。这个调度器使用红黑树取代传统运行队列来管理任务,以任务的CPU时间作为键值。这使得CPU的少量消费者相对于CPU消耗型负载更容易被找到,提高交互和I/O消耗型负载的性能。
用户级进程可通过调用sched_setscheduler()设置调度器策略以调整调度类的行为。RT类支持SCHED_RR和SCHED_FIFO策略,CFS类支持SCHED_NORMAL和SCHED_BATCH。
调度器策略如下:
- RR:SCHED_RR,轮转调度。一旦一个线程用完它的时间片,它就被挪到自己优先级运行队列的尾部,这样同等优先级的其他线程可运行;
- FIFO:SCHED_FIFO,先进先出调度,一直运行队列头的线程直到它自愿退出,或一个更高优先级的线程抵达。线程会一直运行,即便在运行队列当中存在相同优先级的其他线程;
- NORMAL:SCHED_NORMAL(以前称为SCHED_OTHER)是一种分时调度,是用户进程的默认策略。调度器根据调度类动态调整优先级。对于O(1),时间片长度根据静态优先级设置,即更高优先级的工作分配到更长的时间。对于CFS,时间片是动态的;
- BATCH:SCHED_BATCH和SCHED_NORMAL类似,但期望线程是CPU消耗型的,这样就不会打断其他I/O消耗型交互工作。
其他类和策略可能会不断加入。已研究过的调度算法包括感知超线程的和感知温度的,通过考虑额外的处理器因素优化性能。当没有线程可运行时,一个特殊的空闲线程作为替代者运行,直到有其他线程可运行。
Solaris内核,省略。
空闲线程
空闲线程是一个特例,以最低优先级运行。
内核空闲线程只在没有其他可运行线程时才在CPU上运行,优先级尽可能地低。它通常被设计为通知处理器CPU执行停止(停止指令)或减速以节省资源。CPU会在下一次硬件中断醒来。
NUMA分组
NUMA系统性能可通过使内核感知NUMA而得到极大提高,可做出更好的调度和内存分配决定。它可自动检测并创建本地化的CPU和内存资源组,并按照反映NUMA架构的拓扑结构组织起来。这种结构可以预估任意的内存访问开销。
Linux上,这些被称为调度域,这些域处于一个以根域为起点的拓扑结构里。在Solaris上,这些被称为本地组(lgrps)并以根组为起点。系统管理员可以手动进行分组,可以把多个进程绑定在一或多个CPU上运行,也可以创建一组CPU,不允许某些进程在上面运行。
处理器资源感知
和NUMA不同,内核也可以理解CPU资源拓扑结构,这样可以为了资源管理和负载均衡做出更好的调度决定。Solaris上由处理器组实现。
方法
跟第二章类似。
| 方法 | 类型 |
|---|---|
| 工具法 | 观测分析 |
| USE方法 | 观测分析,容量规划 |
| 负载特征归纳 | 观测分析 |
| 剖析 | 观测分析 |
| 周期分析 | 观测分析 |
| 性能监控 | 观测分析,容量规划 |
| 静态性能监控 | 观测分析,容量规划 |
| 优先级调优 | 调优 |
| 资源控制 | 调优 |
| CPU绑定 | 调优 |
| 微型基准测试 | 实验分析 |
| 扩展 | 容量规划,调优 |
使用顺序:性能监控、USE方法、剖析、微型基准测试和静态分析。
工具法
USE方法
负载特征归纳
剖析
周期分析
性能监控
CPU关键指标:
- 使用率:繁忙百分比。
- 饱和度:从系统负载推算出来的运行队列长度,或者是线程调度器延时的数值
使用率应该对每个CPU分别监控,以发现线程的扩展性问题。
监控CPU用量的一个挑战在于挑选合适的测量和归档时间间隔。
静态性能调优
关注配置环境的问题,检查下列静态配置:
- 有多少CPU可用?是核吗?还是硬件线程?
- CPU的架构是单处理器还是多处理器?
- CPU缓存的大小是多少?是共享的吗?
- CPU时钟频率是多少?是动态的(例如Intel 睿频加速和SpeedStep)吗?这些动态特性在BIOS启用了吗?
- BIOS 里启用或者禁用了其他什么CPU 相关的特性?
- 这款型号的处理器有什么性能问题(bug)?出现在处理器勘误表上了吗?
- 这个BIOS 固件版本有什么性能问题(bug)吗?
- 有软件的CPU 使用限制(资源控制)吗?是什么?这些问题的答案可能能够暴露之前忽视的配置选择。云计算环境要特别注意最后的问题,CPU 使用经常受到限制。
优先级调优
UNIX一直都提供nice()系统调用,通过设置nice值以调整进程优先级,范围为-20~+19。正nice值代表降低进程优先级(更友好),而负值(只能由超级用户设置)代表提高优先级。nice(1)可指定nice值以启动程序,BSD上的renice(1M)可用来调整已经在运行的进程的优先级。
在竞争CPU时,最为有效的方法是为高优先级工作制造一些调度器延时。你的任务是找出低优先级工作,可能包括监控代理程序和定期备份,也可能是修改这些程序,以某个nice值启动,还可以做一些分析,检查调优是否有效,特别是高优先级工作的调度器延时要低。
除了nice值,操作系统可能还为进程优先级提供更高级的控制,例如更改调度类或调度器策略,或更改那个类的调优。Linux和Solaris都包含实时调度类,这个类允许进程抢占其他所有的工作。虽然这样可以消除调度器延时(除了其他实时进程和中断),但你最好明白这样的后果。如果实时应用程序有个Bug导致多个线程陷入无限循环,就会造成所有的进程都不能使用CPU——包括需要用来修复问题的管理控制台。这种问题通常只能用重启系统来修复。
资源控制
操作系统可能为给进程或进程组分配CPU资源提供细粒度控制。这可能包括CPU使用率的固定限制和更灵活的共享方式——允许基于一个共享值,消耗空闲CPU周期。运作原理与实现相关。
CPU绑定
把进程和线程绑定在CPU上,可增加进程的CPU缓存温度,提高内存I/O性能。对NUMA系统这可以提高内存本地性,同样也提高性能。有两个实现方式:
- 进程绑定:配置一个进程只跑在单个CPU上,或预定义CPU组中的一个
- 独占CPU组:分出一组CPU,让这些CPU只能运行指定的进程。可更大地提升CPU缓存效率,因为当进程空闲时,其他进程不能使用CPU,保证缓存温度。
Linux上,独占CPU组可通过cpuset实现。Solaris上称为处理器组。
微型基准测试
扩展
一个基于资源的容量规划简单的扩展方法:
- 确定目标用户数或应用程序请求频率;
- 转化成每用户或每请求CPU使用率。对于现有系统,CPU用量可通过监控获得,再除以现有用户数或请求数。对于未投入使用系统,负载生成工具可以模拟用户,以获得CPU用量;
- 推算出当CPU资源达到100%使用率时的用户或请求数。这就是系统的理论上限。
对系统扩展性进行建模,考虑竞争和一致性延时条件,可获得更实际的性能预测。
分析
CPU分析工具
| Linux | Solaris | 描述 |
|---|---|---|
| uptime | uptime | 平均负载 |
| vmstat | vmstat | 包括系统范围的CPU平均负载 |
| mpstat | mpstat | 单个CPU统计信息 |
| sar | sar | 历史统计信息 |
| ps | ps | 进程状态 |
| top | prstat | 监控每个进程/线程CPU用量 |
| pidstat | prstat | 每个进程/线程CPU用量分解 |
| time | ptime | 给一个命令计时,带CPU用量分解 |
| DTrace,perf | DTrace | CPU剖析和跟踪 |
| perf | cpustat | CPU性能计数器分析 |
uptime
vmstat
虚拟内存统计信息命令
mpstat
多处理器统计信息工具,能够报告每个CPU的统计信息。
sar
系统活动报告器,可用来观察当前的活动,以及配置用以归档和报告历史统计信息。
Linux版本有以下选项:
-P ALL:与mpstat的-P ALL选项相同;-u:与mpstat(1)的默认输出相同,仅包括系统范围的平均值;-q:包括运行队列长度列runq-sz(等待数加上运行数,与vmstat的r列相同)和平均负载。
Solaris版本提供的选项:
-u:系统范围内的%usr、%sys、%wio(零)和%idl的平均值;-q:包括运行队列长度列runq-sz(仅包括等待数),和运行队列中有线程等待的百分比时间%runocc,虽然这个值在0和1之间并不准确。
Solaris上没有提供单个CPU的统计信息。
ps
top
prstat
pidstat
Linux上pidstat(1)按进程或线程打印CPU用量,包括用户态和系统态时间的分解。默认情况下,仅循环输出活动进程的信息。
time和ptime
DTrace
SystemTap
Linux上可使用SystemTap以跟踪调度器时间。
perf
cpustat
其他工具
Linux其他CPU性能工具:
- oprofile:最初的CPU剖析工具;
- htop:包括CPU用量的ASCII柱状图,比最初的
top(1)有更强大的交互模式; - atop:包括更多的系统级统计信息,使用进程核算统计捕捉短命进程的存在;
/proc/cpuinfo:可以获得处理器详细信息,包括时钟频率和特性标志位;getdelays.c:用于延时核算,包括每个进程的CPU调度器延时;- valgrind:内存调试和剖析工具组,包括:
- callgrind:跟踪函数调用并生成调用图的工具;
- kcachegrind:可视化;
- cachegrind:可用来分析一个给定程序的硬件缓存用量。
其他Solaris工具:
- lockstat/plockstat:锁分析,包括自旋锁和自适应互斥量上的CPU消耗;
- psrinfo:处理器状态和信息(-vp);
- fmadm faulty:检查CPU是否因为不断增加的可更正ECC错误而进入预测故障模式。另参见fmstat(1M);
isainfo -x:列出处理器特性标志位;- pginfo,pgstat:处理器组统计信息,展示CPU拓扑以及CPU资源是如何共享的;
- lgrpinfo:本地性组统计信息。这有助于检查使用中的
lgrps,因为它需要处理器和操作系统的支持。
可视化
实验
使用这些工具时,最好让mpstat(1)持续运行,以确认CPU用量和并发度。
Ad Hoc
创建一个单线程的CPU密集型负载:while :; do :; done &
SysBench
SysBench系统基准测试套件有一个计算质数的简单CPU基准测试工具。
sysbench --num-threads=8 --test=cpu --cpu-max-prime=100000 run:执行八个线程,最多计算100000个质数。
调优
对于CPU而言,最大的性能收益往往源于排除不必要的工作。调优的具体事项(可用的选项以及设置成什么)取决于处理器类型、操作系统版本和期望的任务。
编译器选项
编译器及其提供的优化代码选项,对CPU性能有很大影响。一般的选项包括了编译为64位而非32位程序,以及优化级别。
调度优先级和调度类
Linux上chrt(1)可显示并直接设置优先级和调度策略。调度优先级也可通过setpriority()系统调用直接设置,而优先级和调度策略可通过sched_setscheduler()设置。
Solaris上,可通过priocntl(1)直接设置调度类和优先级。
priocntl -s -c RT -p 10 -i pid PID:对目标ID的进程设置,使其以优先级10在实时调度类下运行。如果实时线程耗光所有的CPU资源,你可能会把系统锁死。
调度器选项
Linux 3.2.6内核调度器配置选项
| 选项 | 默认值 | 描述 |
|---|---|---|
| CONFIG_CGROUP_SCHED | y | 允许任务编组,以组为单位分配CPU时间 |
| CONFIG_FAIR_GROUP_SCHED | y | 允许编组CFS任务 |
| CONFIG_RT_GROUP_SCHED | y | 允许编组实时任务 |
| CONFIG_SCHED_AUTOGROUP | y | 自动识别并创建任务组(例如,构建任务) |
| CONFIG_SCHED_SMT | y | 超线程支持 |
| CONFIG_SCHED_MC | y | 多核支持 |
| CONFIG_HZ | 1000 | 设置内核时钟频率(时钟中断) |
| CONFIG_NO_HZ | y | 无tick内核行为 |
| CONFIG_SCHED_HRTICK | y | 使用高精度定时器 |
| CONFIG_PREEMPT | n | 全内核抢占(除了自旋锁区域和中断) |
| CONFIG_PREEMPT_NONE | n | 无抢占 |
| CONFIG_PREEMPT_VOLUNTARY | y | 在自愿内核代码点进行抢占 |
有些Linux内核还提供额外的可调参数(例如在/proc/sys/sched中)。
Solaris调度器可调参数
| 参数 | 默认值 | 描述 |
|---|---|---|
| rechoose_interval | 3 | CPU关联持续时间(时钟tick) |
| nosteal_nsec | 100000 | 如果线程在最近时间(纳秒级)运行过则避免线程偷取(空闲CPU找活干) |
| hires_tick | 0 | 设为1代表把内核时钟频率设置到1000Hz,而不是默认的100Hz |
Solaris同样也提供方法,通过dispadmin(1)修改调度器类使用的时间片和优先级。
dispadmin -c TS -g -r 1000输出如下内容:
ts_quantum:时间片,单位为毫秒,精度通过-r 1000设置;ts_tqexp:线程当前时间片过期之后的新优先级(优先级削减);ts_slpret:在线程睡眠(I/O)之后醒来的新优先级(优先级提升);ts_maxwait:在线程被提升至ts_lwait一栏的优先级前等待CPU的最大秒数;- PRIORITY LEVEL:优先级值;
这些配置可以写到一个文件中,修改后由dispadmin(1M)重新载入。
进程绑定
一个进程可绑定在一或多个CPU上,可通过提高缓存温度和内存本地性来提高性能。
Linux通过taskset(1)实现,可使用CPU掩码或范围设置CPU关联性。
taskset -pc 7-10 10790:限定PID为10790的进程只能跑在CPU 7到10之间。
Solaris通过pbind(1)来实现。pbind -b 10 11901:限定PID为11901的进程只能跑在CPU 10上。不能指定多个CPU。如果想要达到类似的功能,需使用独占CPU组。
独占CPU组
Linux提供CPU组,允许编组CPU并为其分配进程。和进程绑定类似,可提高性能,但还可通过使得CPU组独占(不允许其他进程使用)而进一步提高性能。这种权衡另一方面减少系统其他部分的可用CPU数量。
Solaris上可通过psrset(1M)命令创建独占CPU组。
资源控制
除了把进程和整个CPU关联以外,现代操作系统还对CPU用量分配提供细粒度资源控制。
Solaris把对进程或进程组的资源控制(Solaris9加入)机制称为项目。CPU用量可以使用公平份额调度器和份额以灵活控制,这个机制控制了对空闲CPU有需求的进程消耗CPU的行为。在一致性比份额动态行为更加重要的情况下,还可以对CPU总使用率的百分比设置一些限制。
Linux上的控制组(cgroups),通过进程或进程组控制资源用量。CPU用量可使用份额进行控制,而CFS调度器允许对每段时间内分配的CPU微秒数周期,设置固定上限(CPU带宽),3.2版加入。
处理器选项(BIOS调优)
处理器通常提供一些设置,以启用、禁用和调优处理器级别的特性。在x86系统上,这些选项通常在启动时通过BIOS设置菜单管理。
设置通常默认提供最大性能而不需要调整。现在调整它们最经常的理由是禁用Intel睿频,这样CPU基准测试就会运行在一致的时钟频率上(记住在生产环境里,为了少许更好性能应该启用睿频)。
练习
CPU术语类问题:
- 进程(process)和处理器(processor)之间的区别是什么?
- 什么是硬件线程?
- 什么是运行队列(分发器队列)?
- 用户态时间和内核态时间的区别是什么?
- 什么是CPI?
概念问题:
- 描述CPU使用率和饱和度。
- 描述指令流水线是如何提高CPU吞吐量的。
- 描述处理器指令宽度是如何提高CPU吞吐量的。
- 描述多进程和多线程模型的优点。
更深入的问题:
- 描述当系统CPU内可运行任务过载时的情形,包括对应用程序性能的影响。
- 当没有可运行任务时,CPU会做什么?
- 在处理一个可能的CPU性能问题时,说出三种你将使用的早期调查方法,并解释为什么。
给操作系统开发以下流程:
- 一个CPU资源的USE方法检查清单。包括如何获得每项指标(例如,执行哪条命令)以及如何解释结果。在安装或使用额外软件产品前,尽量使用已有的操作系统观察工具。
- 一个CPU资源的负载特征归纳检查清单。包括如何获取每项指标,首先尽量使用已有的操作系统观察工具。
执行这些任务:
- 计算下面处于稳定状态的系统的平均负载:
- 系统有64颗CPU
- 系统范围内CPU使用率为50%
- 系统范围内CPU饱和度为2.0,这是根据队列中可运行和排队中的线程平均数得出的。
- 选择一个应用程序,剖析它的用户级CPU用量。展示出哪条代码路径消耗了最多的CPU。
- 单从这个Solaris系统的截图,描述可见CPU行为。
(可选,高级)开发bustop(1)(一个展示物理总线或者互联使用率的工具)带类似iostat(1)的输出:一个总线的列表,每个方向吞吐量和使用率的信息栏。可能的话,包括饱和度和错误指标,这需要使用CPC。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 23
23 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)