大模型技术如何应用在目标检测业务中
关键词:人工智能大模型 人工智能培训 大模型培训 具身智能培训 智能体 VLA
大模型(Large Models),尤其是视觉大模型(如 Vision Transformers、SAM、DINOv2、Grounding DINO 等)在目标检测业务中的应用正迅速发展。它们通过更强的泛化能力、零样本/少样本学习能力以及多模态理解能力,显著提升了传统目标检测系统的性能与灵活性。以下是大模型技术在目标检测业务中的主要应用方式:
-
开集(Open-Vocabulary)目标检测
传统目标检测模型(如 Faster R-CNN、YOLO)只能识别训练集中预定义的类别。而大模型(如 Grounding DINO、OWL-ViT)支持开放词汇检测,即:
用户可通过自然语言(如“红色消防栓”、“破损的轮胎”)指定任意目标;
模型无需重新训练即可检测新类别。
✅ 应用场景:工业质检中检测未知缺陷类型、安防中识别新型可疑物品等。 -
零样本 / 少样本迁移学习
大模型在海量数据上预训练,具备强大的通用视觉表征能力。在目标检测任务中:
只需少量标注样本(甚至无标注),即可微调或提示(prompt)模型适配新领域;
减少对大规模标注数据的依赖,降低部署成本。
✅ 应用场景:医疗影像中罕见病灶检测、农业中稀有虫害识别等数据稀缺场景。 -
多模态融合检测
结合文本、图像甚至语音信息进行联合推理。例如:
CLIP + 检测头:利用 CLIP 的图文对齐能力,将文本语义嵌入到检测流程中;
Grounding DINO:直接根据文本描述定位图像中的目标。
✅ 应用场景:智能零售(“找出货架上缺货的商品”)、自动驾驶(“注意穿黄色雨衣的行人”)。 -
通用分割与检测一体化
如 Meta 的 SAM(Segment Anything Model) 虽主要用于分割,但可与检测模型结合:
先用 SAM 生成高质量候选区域(proposals);
再用分类器或文本编码器判断类别;
实现“检测+分割”端到端流程。
✅ 应用场景:遥感图像分析、机器人抓取(需精确定位边界)。 -
自监督 / 弱监督预训练提升小模型性能
大模型可作为教师模型(Teacher),通过知识蒸馏(Knowledge Distillation)指导轻量级检测模型(如 YOLOv8):
提升小模型在边缘设备上的精度;
保持低延迟与低功耗。
✅ 应用场景:无人机巡检、移动端AR应用等资源受限环境。 -
动态场景理解与长尾分布处理
大模型对长尾类别(出现频率低但重要的类别)有更好的识别能力,因其在预训练阶段接触过更广泛的数据分布。
✅ 应用场景:城市治理(识别“乱堆垃圾”“违规广告牌”等长尾事件)。
实施建议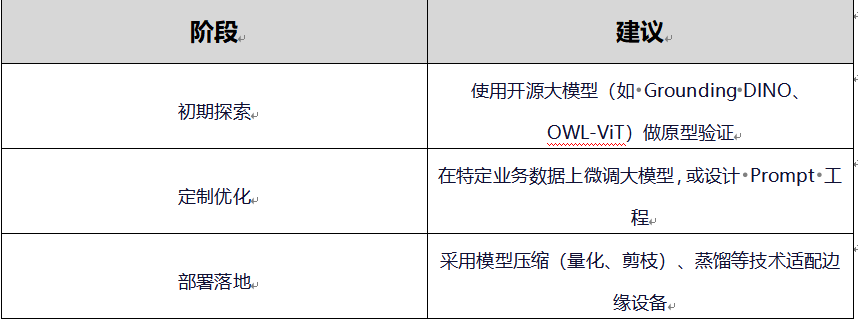
主流开源工具推荐
Grounding DINO(开放词汇检测)
SAM + MobileSAM(分割辅助检测)
DINOv2(强大视觉特征提取器)
OWL-ViT / GLIP(多模态检测)
点击下面微信名片,获取更多资源!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)