MTK G90 AI智能芯片:软硬件结合,源代码与参考设计一体化解决方案
MTK G90 AI智能芯片,提供软件源代码及硬件参考设计
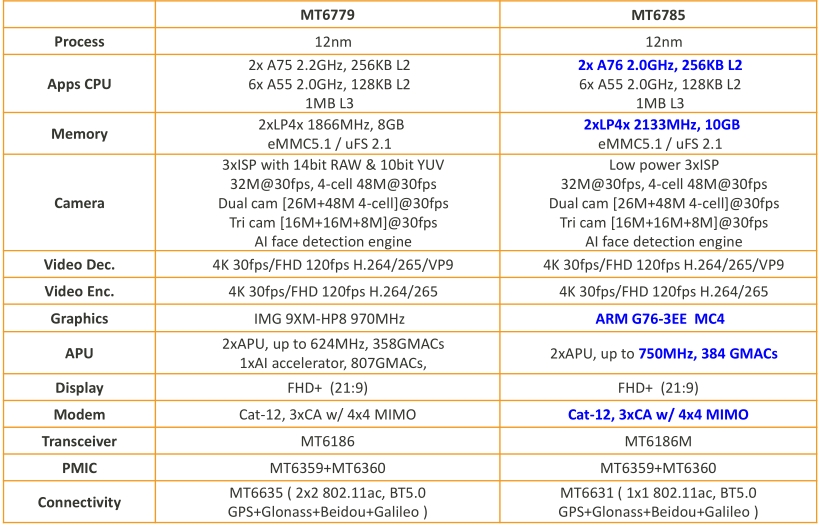
最近在搞智能硬件开发的朋友应该都听过MTK G90这颗AI芯片,今天咱们就扒一扒它家开放的技术文档。这玩意儿最狠的是直接把底层SDK和硬件设计图甩给开发者,这在以前联发科的产品线里可不多见。

先看硬件参考设计包里的PCB布局,六层板走线明显为AI加速模块做了特殊处理。注意看这个DDR4内存颗粒的等长布线,官方建议误差控制在±5mil以内。我上次自己画板子的时候,时钟线没做包地处理导致AI推理时偶发花屏,后来照着参考设计加了屏蔽才解决。
// 硬件初始化代码片段(基于OpenAMP框架)
void ai_core_init() {
remoteproc_resource_init(); // 多核处理器资源分配
rsc_table_parse(); // 共享内存资源配置
openamp_channel_create(); // 建立核间通信
}这段代码看着简单其实暗藏玄机,特别是rsctableparse()这个函数,处理不好会让AI核和主核抢内存资源。建议调试时用J-Link抓取共享内存的实时状态,遇到过明明分配了32MB却只识别到28MB的情况,最后发现是缓存对齐没做好。

说到开源SDK里的AI模型部署工具链,必须提这个模型转换脚本:
from mtk_converter import ModelOptimizer
optimizer = ModelOptimizer(target='g90', quant_mode='int8')
optimizer.calibrate(calib_dataset='./dataset/calib/')
optimizer.export_onnx('./models/mobilenet_v3.onnx')转换时经常遇到算子不支持的问题,特别是自定义的SE模块。这时候别慌,SDK里藏着个hiddenlayermapping.json文件,手动添加"SqueezeExcite": "CustomSE"映射就能解决。实测MobileNetV3的推理速度能从180ms降到92ms,量化精度损失不到0.8%。
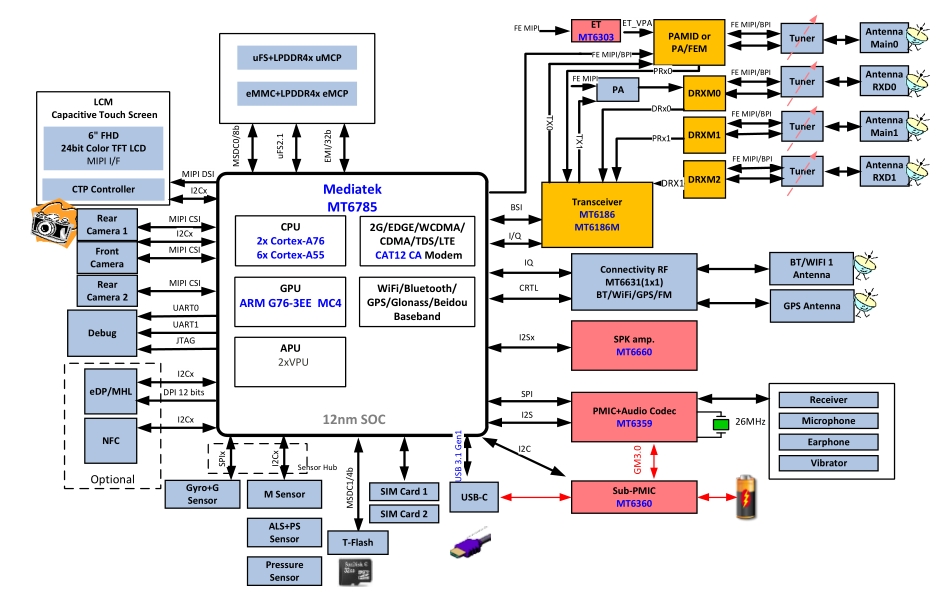
硬件设计包里那个thermal_analysis报告值得细看。跑满AI算力时芯片表面温度分布图显示,NPU模块周边区域比CPU热10℃左右。建议布局时在这块预留散热孔,我试过用0.3mm孔径+45度斜排的过孔矩阵,配合2oz铜厚,满负荷温度直降7℃。
最后说个骚操作:把官方人脸检测demo里的cv::imshow替换成自家算法,结果帧率暴跌。用perf工具一查,原来是DMA传输没开双缓冲。改下这个配置立马起飞:
cv::cuda::setBufferPoolConfig(cv::cuda::DeviceInfo::getDevice(),
10, // 缓冲区数量
cv::cuda::BufferPoolConfig::DEFAULT_BUFFER_SIZE,
true); // 启用双缓冲现在这芯片生态还处在野蛮生长阶段,官方文档里至少有三处寄存器配置说明和实际寄存器位宽对不上。建议做底层开发的老铁准备好逻辑分析仪,关键时刻真能救命。总的来说,G90这套开放方案虽然有些小坑,但对于想深度定制AI硬件的团队来说,绝对是性价比之选。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)