机器学习算法(三):支持向量机(SVM)的sklearn调用
文章目录
前言
本节只会介绍SVM的一些sklearn的高级API调用接口,具体的理论推导这个模型的推导还是很复杂的,这里就不给出具体的理论了。具体理论还请读者自己想办法查阅资料吧。本来是有打算将理论也在这里附上,但很显然这个模型并不像线性回归和逻辑回归那样简单的几个公式就能够说明的,如果需要在这里讲述明白,需要大量的文字叙述,那么读者还不如去找一本详细介绍该模型的书看。
一 理论
【注】:该模型理论不是一句两句话可以阐述明白的,需要时哪出iPad上面笔记看一看 ---- 本注是写给作者本人看的。
但是sklearn中定义的核函数是什么样的还是需要在这里打一下公式才好在接口中选择参数
【注】:以后有时间了尽量会将理论也搬上来,支持向量机这个模型的确理解了理论和只会调用还是有一些区别的。
1 sklearn中的核函数形式

其中,linear:线性核函数;polynomial:多项式核函数;rbf:高斯核函数;主要是这三个了,具体的请参考官方文档,上面也简单介绍了点理论,不过很粗糙不容易看懂svm sklearn官方文档
二、sklearn调用
1 svm.SVC() 接口说明
sklearn.svm.SVC 是 scikit-learn 中用于分类任务的支持向量分类器类。它提供了丰富的参数来控制 SVM 模型的行为和性能。
以下是 SVC 中的几个重要参数及其详细解释(仅列出较为重要的参数):
(1). C (float, default=1.0)
惩罚参数 ( C ),也称为正则化参数。它控制误分类的惩罚力度。较小的 ( C ) 会允许更多的误分类点,从而获得更平滑的决策边界(防止过拟合)。较大的 ( C ) 会对误分类点施加更大的惩罚,尝试准确地划分所有训练数据(可能导致过拟合)。
svm.SVC(C=1.0)
(2). kernel (str, default=‘rbf’)
指定用于模型的核函数。支持的核函数有:
'linear':线性核函数'poly':多项式核函数'rbf':径向基函数核(默认)'sigmoid':S 型核函数- 自定义核函数:通过一个 callable 函数传递
svm.SVC(kernel='rbf')
(3). degree (int, default=3)
当使用多项式核函数时,指定多项式的阶数。这个参数在 kernel='poly' 时才有意义。
svm.SVC(kernel='poly', degree=3)
(4). gamma (str or float, default=‘scale’)
核函数系数,仅在 kernel='rbf', kernel='poly', 和 kernel='sigmoid' 时有效。它决定了单个训练样本的影响范围。
'scale':默认值。使用 ( 1 / (n_{\text{features}} \times X.var()) )'auto':使用 ( 1 / n_{\text{features}} )- 也可以直接指定一个浮点数
svm.SVC(kernel='rbf', gamma='scale')
(5). coef0 (float, default=0.0)
核函数的独立项。在多项式和 S 型核函数中有用。它是多项式核中常数项(bias term)以及 S 型核中线性部分的常数项。
svm.SVC(kernel='poly', coef0=0.0)
(6). tol (float, default=1e-3)
停止准则的容忍度。用于控制算法的收敛精度,较小的 tol 值会使得优化过程更精确,但计算时间可能更长。
svm.SVC(tol=1e-3)
(7). decision_function_shape (str, default=‘ovr’)
决策函数的形状。对于多分类任务,支持两种模式:
- `'ovr'` (one-vs-rest):一对多,默认值。适合大多数情况。
- `'ovo'` (one-vs-one):一对一,用于处理多类别分类问题。
```python
svm.SVC(decision_function_shape='ovr')
```
【注】:关于各类二分类器的一对一和一对多的策略实现多分类效果,后面会有一篇博客专门详细讲述究竟是什么个流程。
三 、具体示例
在本练习中,我们将使用支持向量机(SVM)来构建垃圾邮件分类器。 我们将从一些简单的2D数据集开始使用SVM来查看它们的工作原理。 然后,我们将对一组原始电子邮件进行一些预处理工作,并使用SVM在处理的电子邮件上构建分类器,以确定它们是否为垃圾邮件。
我们要做的第一件事是看一个简单的二维数据集,看看线性SVM如何对数据集进行不同的C值(类似于线性/逻辑回归中的正则化项)。
我们要做的第一件事是看一个简单的二维数据集,看看线性SVM如何对数据集进行不同的C值(类似于线性/逻辑回归中的正则化项)。
1、简单的线性SVM例子 — 不同C值的影响
C越大,对误分类的惩罚越大,决策边界越接近于正确分类的数据点,但是容易过拟合;C越小,对误分类的惩罚越小,决策边界越接近于所有数据的中心,容易欠拟合。
(1) 数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from scipy.io import loadmat
raw_data = loadmat('data/ex6data1.mat') #加载数据
raw_data #查看数据,数据中X为特征,y为标签,可以看到数据放在一个字典中
输出:

【注】:数据读入进来是放在字典里面的。
我们将其用散点图表示,其中类标签由符号表示(+表示正类,o表示负类)。
data = pd.DataFrame(raw_data['X'], columns=['X1', 'X2'])
data['y'] = raw_data['y']
positive = data[data['y']==1]
negative = data[data['y']==0]
fig, ax = plt.subplots(figsize=(4,3))
ax.scatter(positive['X1'], positive['X2'], s=50, marker='x', label='Positive')
ax.scatter(negative['X1'], negative['X2'], s=50, marker='o', label='Negative')
ax.legend()
ax.grid(True)
plt.show()
输出: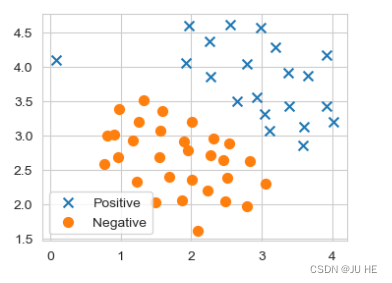
请注意,还有一个异常的正例在其他样本之外。
这些类仍然是线性分离的,但它非常紧凑。 我们要训练线性支持向量机来学习类边界。 在这个练习中,我们没有从头开始执行SVM的任务,所以我要用scikit-learn。
我们用线性的svc就可以分离这两类数据了,我们可以看看不同C值的影响。
X_train = data[['X1', 'X2']].values
y_train = data['y'].values
print(X_train)
print(y_train)
输出:
(2) svm sklearn调用
关于sklearn里面参数的获取:
model.coef_:获取模型的系数,即特征的权重。一般是是一个二维数组里面存放的是每个特征的权重。
model.intercept_:获取模型的截距。一般是一个一维数组,里面存放的是截距值。
w = model.coef_[0]
b = model.intercept_[0]
from sklearn import svm
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
C = [0.0001, 0.01, 0.1, 1, 10, 100] # 不同的C值
fig, ax = plt.subplots(1, len(C), figsize=(20, 4)) # 一行多列的画布
for i, c in enumerate(C):
model = svm.SVC(C=c, kernel='linear') # 线性核函数
model.fit(X_train, y_train) # 训练模型
# 在训练集上进行预测
y_pred = model.predict(X_train)
# 计算准确率
accuracy = accuracy_score(y_train, y_pred)
w = model.coef_[0]
w1, w2 = w[0], w[1]
b = model.intercept_[0]
ax[i].scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis') # 画真实数据散点图,cmap='viridis'选这色调搭配
# 计算决策边界,这种手动计算决策边界的方法很不方便,后面会介绍更简单的方法 --- 用等高线的画法来画决策边界(接下来的非线性SVM就会给出这种方法)
x_min, x_max = X_train[:, 0].min(), X_train[:, 0].max()
y_min = (-w1 * x_min - b) / w2
y_max = (-w1 * x_max - b) / w2
# 绘制决策边界
ax[i].plot([x_min, x_max], [y_min, y_max], color='blue')
ax[i].set_title(f"SVM with C={c}\nAccuracy: {accuracy:.2f}", fontsize=12) # 调整标题字体大小
ax[i].grid(True)
plt.tight_layout() # 自动调整子图布局,防止重叠
plt.show()
输出: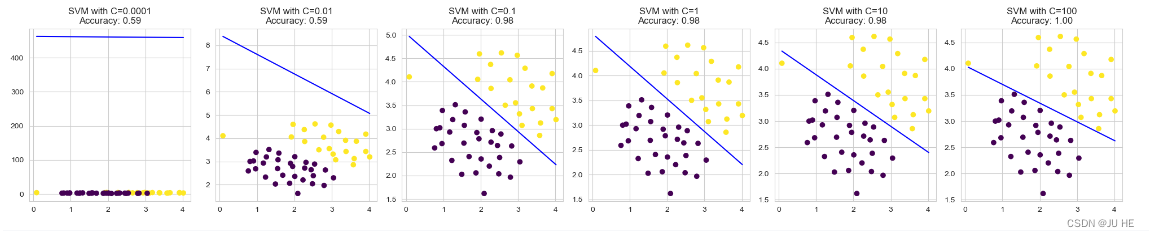
从上面的图中可以看出,C值越大,决策边界越接近于正确分类的数据点,但是容易过拟合,C=100时很显然有点过拟合的意思了;
C值越小,决策边界越接近于所有数据的中心,容易欠拟合,C<=0.01,时效果很差,因为对分错的惩罚很小就会导致主要最大化距离去了,所以就很离谱。
从这个例子中。我们可以看到C的取值对SVM的决策边界有很大的影响,需要慎重选择。
下面给出一个更复杂的例子,这个例子中,我们使用高斯核函数的SVM来对非线性数据进行分类,并用等高线的画法来画决策边界。
2、高斯核函数的SVM — 非线性分类
(1) 数据集
raw_data = loadmat('data/ex6data2.mat')
raw_data
输出:
【注】:数据读入进来是放在字典里面的。
data = pd.DataFrame(raw_data['X'], columns=['X1', 'X2'])
data['y'] = raw_data['y']
data
输出:
# 可视化数据集
positive = data[data['y'] == 1]
negative = data[data['y'] == 0]
fig, ax = plt.subplots(figsize=(6,4))
ax.scatter(positive['X1'], positive['X2'], s=30, marker='x', label='Positive')
ax.scatter(negative['X1'], negative['X2'], s=30, marker='o', label='Negative')
ax.legend()
plt.show()
输出: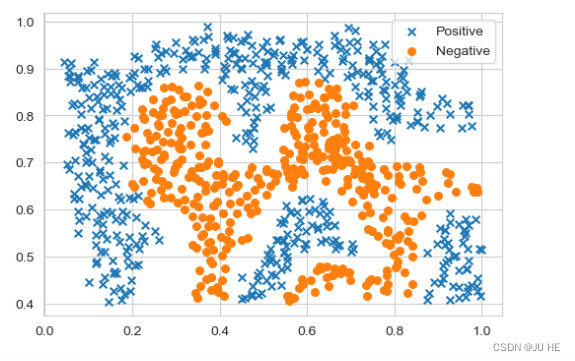
可以看到这个数据集是非线性的,我们不能用线性的SVM来分割这个数据集。我们可以使用高斯核函数的SVM来处理这个数据集。
X_train = data[['X1', 'X2']].values
y_train = data['y'].values
(2) 高斯核函数的SVM
高斯核函数的SVM可以很好地分割非线性数据集,我们可以看看不同gamma值的影响。
一般来说,gamma值越大,决策边界越不规则(容易过拟合),gamma值越小,决策边界越平滑(容易欠拟合)。
ga = [1, 10, 100] # 不同的gamma值
fig, ax = plt.subplots(1, len(ga), figsize=(20, 4))
for i, g in enumerate(ga):
model = svm.SVC(C=1, kernel='rbf', gamma=g) # 高斯核函数
model.fit(X_train, y_train) # 训练模型
# 在训练集上进行预测
y_pred = model.predict(X_train)
# 计算准确率
accuracy = accuracy_score(y_train, y_pred)
# 绘制原始数据散点图
ax[i].scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='viridis')
# 画决策边界
# 创建一个网格以便可视化决策边界
xx, yy = np.meshgrid(np.linspace(X_train[:, 0].min() , X_train[:, 0].max() , 500),
np.linspace(X_train[:, 1].min() , X_train[:, 1].max() , 500)) # 生成网格点坐标矩阵
# 预测网格上的每个点
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]) # ravel()将多维数组降为一维,np.c_按行连接两个矩阵
Z = Z.reshape(xx.shape)
# 绘制决策边界
ax[i].contourf(xx, yy, Z, alpha=0.3, cmap='viridis') # 绘制等高线图,利用等高线图不同颜色来形成一条决策边界
ax[i].set_title(f"SVM with C={g}\nAccuracy: {accuracy:.2f}")
ax[i].set_xlabel("Feature 1")
ax[i].set_ylabel("Feature 2")
plt.show()
输出: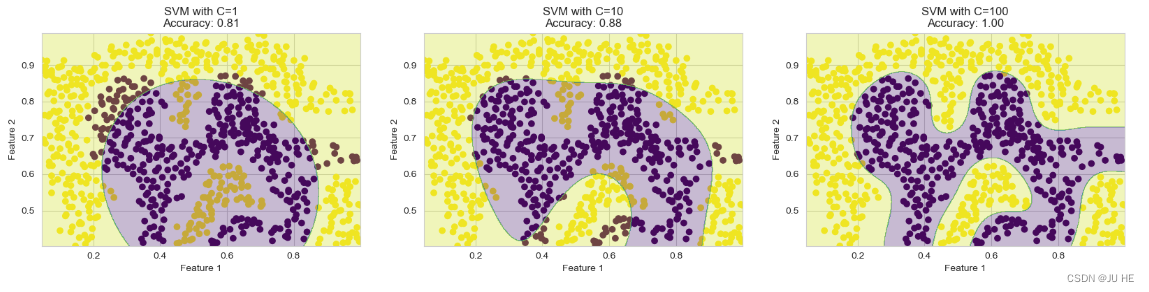
从上图中可以看到,高斯核函数的SVM可以很好地分割这个非线性数据集。gamma值越大,决策边界越不规则,gamma值越小,决策边界越平滑。
很明显,gamma=100时,决策边界过于不规则,可能有点过拟合的意思了,最好交叉验证一下,看看效果如何;
gamma=1时,决策边界比较平滑,但有点欠拟合的意思了。
可以看到,SVM是一个非常强大的算法,可以用于线性或非线性分类,也可以用于回归(SVM回归暂时还没学)。
但有个麻烦带你,参数怎么选,for循环一个一个试太麻烦了,sklearn提供了一种自动调参的方法,叫做网格搜索(Grid Search)。各种模型都有这个功能,
下面我们就来学习一下这个强大又实用的功能。还是选择上面的非线性数据集,我们来用网格搜索来选择最优的C和gamma值,以及不同的核函数。
3、sklearn调参技术–网格搜索 — 选择最优的C和gamma值、核函数等参数
在实际应用中,选择和调优这些参数通常需要一些实验和交叉验证,以找到最佳的组合。常用的方法包括网格搜索 (GridSearchCV) 和随机搜索 (RandomizedSearchCV),它们可以系统地搜索参数空间,以找到最优的参数组合。
之前不是学过一个交叉验证集的方法选择合适的参数吗,这里就可以很容易的实现了。不用我们一个一个去试,太麻烦了。
下面有一个参数就是交叉验证的:
cv=5 表示交叉验证的折数,即将数据分成多少个子集来进行交叉验证。在这里,cv=5 意味着数据集会被分成 5 份,每一份都会轮流作为验证集,其余的作为训练集。因此,整个过程会执行 5 次,每次选取不同的验证集来评估模型的性能。
有了这个功能以后我们就可以先用这个功能来选择最优的参数,然后再用最优的参数来训练模型。再对选择出来的最优模型进行具体的绘图等分析在确定是否是最优的。不是我们就继续调参。
print(X_train)
print(y_train)
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, classification_report
# 定义参数网格
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': ['scale', 0.01, 0.1, 1, 10],
'kernel': ['linear', 'poly', 'rbf', 'sigmoid']
}
# 创建 SVM 模型
svc = svm.SVC()
# 使用网格搜索进行参数调优
grid_search = GridSearchCV(svc, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 打印最佳参数
print("Best Parameters:", grid_search.best_params_)
# 使用最佳参数进行预测
best_model = grid_search.best_estimator_
y_best_pred = best_model.predict(X_train)
# 评估模型
print("Accuracy with Best Parameters:", accuracy_score(y_train, y_best_pred))
print("Classification Report with Best Parameters:")
print(classification_report(y_train, y_best_pred))
输出: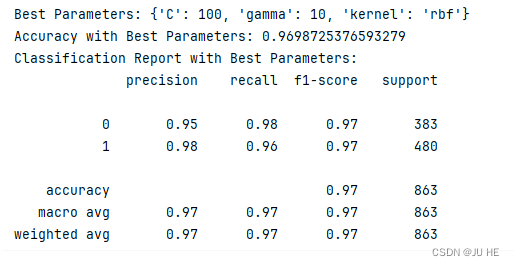
下面在用最优的参数来画图看看效果如何
自己试试看看效果如何,看看最优的参数是不是真的最优。
这里就不演示了,和前面的过程一样,只是参数不一样而已。
总结
最后面的sklearn网格搜索最优参数的技术很有用,要记得用哟,这个技术是通用适合sklearn里面各种模型的。
附录
关于数据集,你应该能csdn上搜到ex6data1.mat与ex6data2.mat
实在找不到评论我@我看到会回复。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)