【python爬虫】懂车帝二手车数据爬取与解析:应对字体反爬与动态渲染的完整方案(含源代码)
大家好,我是@iFeng的小屋。
本次分享一个针对懂车帝二手车版块的Python爬虫项目。与常见的API接口爬取不同,该项目直接解析列表页HTML,完整应对了动态页面渲染、自定义字体反爬等核心挑战,并实现了多字段的结构化提取。本文将深入讲解技术细节、代码逻辑,并探讨数据的应用潜力。
一、研究背景与目的
1.1 研究背景
二手车市场信息繁杂,价格、车况、地域等因素交织,为消费者决策带来困难。懂车帝作为主流汽车信息平台,其二手车数据具有较高的市场参考价值。通过技术手段进行批量采集与分析,有助于揭示市场价格分布规律、车况与价格的关联性等,为市场研究、价值评估或购车决策提供数据支撑。
1.2 研究目的
本项目旨在:
-
技术实现:攻克目标网站的反爬机制(动态加载、字体加密),构建一个稳定的多页爬虫。
-
数据采集:完整爬取车辆关键字段,包括标题、价格、年限、里程、所在地、检测报告、过户次数、新车参考价及原始链接。
-
结构化存储:将非结构化的网页数据转化为可供分析的表格数据(Excel),并实现增量式追加存储。
-
为分析奠基:获取干净、结构化的数据,为后续的价格分布分析、保值率研究、车源画像等可视化与挖掘工作做准备。
二、技术方案与反爬应对策略
项目没有采用简单的requests库,而是用的DrissionPage来开发。
2.1 核心工具选型:DrissionPage vs Selenium
为了获取JavaScript渲染后的完整页面源码,本项目选择了DrissionPage库。
-
优势:
DrissionPage相比传统的Selenium,其内核驱动更高效,允许直接进行网络操作和页面操作,且API设计更简洁。它能够像真实浏览器一样加载页面、执行JS,并轻松获取最终渲染的HTML。 -
关键代码
from DrissionPage import ChromiumPage
page = ChromiumPage() # 启动无头浏览器
page.get(url) # 访问目标URL
page.scroll.to_bottom() # 滚动至底部,触发可能的懒加载
page_source = page.html # 获取渲染后的完整HTML2.2 核心挑战一:自定义字体反爬(Font Anti-Scraping)
这是本项目最大的技术难点。懂车帝对页面上的关键数字(价格、里程)使用了自定义字体进行渲染。
2.2.1 现象分析
在获取的HTML中,价格等数字并非明文显示,而是诸如 的Unicode占位符。浏览器通过加载一个专用的字体文件(.woff或.ttf),将这些符号映射为正确的数字图形显示。
2.2.2 破解方案:字符映射解密
我们通过分析字体文件,找到了Unicode码点与真实数字的对应关系,并实现了解密函数 change()。
def change(encoded_text):
"""
将字体加密的文本解码为正常数字。
原理:字体文件将特定Unicode字符(如\\ue149)渲染为数字形状。
我们需要建立这些字符编码与真实数字的映射关系。
"""
char_map = {
58425: '0', # Unicode码点十进制 58425 对应字符'',实际显示为'0'
58700: '1', # 以此类推...
58467: '2',
58525: '3',
58397: '4',
58385: '5',
58676: '6',
58347: '7',
58595: '8',
58461: '9',
}
decoded_str = ''
for char in encoded_text:
original_code = ord(char) # 获取字符的Unicode码点
# 如果该码点在映射字典中,则替换为数字,否则保留原字符(如汉字)
decoded_str += char_map.get(original_code, char)
return decoded_str
# 应用示例
raw_price = li.xpath('./a/dl/dd[3]/text()')[0] # 获取到类似“万”的文本
clean_price = change(raw_price) # 解密为“12.34万”
numeric_price = re.findall(r'\d+\.?\d*', clean_price)[0] # 提取“12.34”三、数据采集与处理流程
3.1 爬取过程主循环
代码通过一个 for 循环控制翻页,并实现了数据的实时保存与去重累加。
for page_num in range(START_PAGE, END_PAGE + 1):
# 1. 构建分页URL并访问
url = f'https://...110000-{page_num}-x-x-x-x-x'
page.get(url)
time.sleep(2) # 礼貌等待,控制请求频率
# 2. 解析当前页,得到当前页的数据列表`lst`
# ... (解析逻辑)
# 3. 增量保存至Excel
current_page_df = pd.DataFrame(lst)
if os.path.exists('懂车帝.xlsx'):
history_df = pd.read_excel('懂车帝.xlsx')
# 使用concat合并,ignore_index重置索引
combined_df = pd.concat([history_df, current_page_df], ignore_index=True)
else:
combined_df = current_page_df
# 写入Excel,每次循环后文件都包含所有已爬取页面的完整数据
combined_df.to_excel('懂车帝.xlsx', index=False)3.2 采集字段说明
最终生成的Excel表格将包含以下结构化字段:
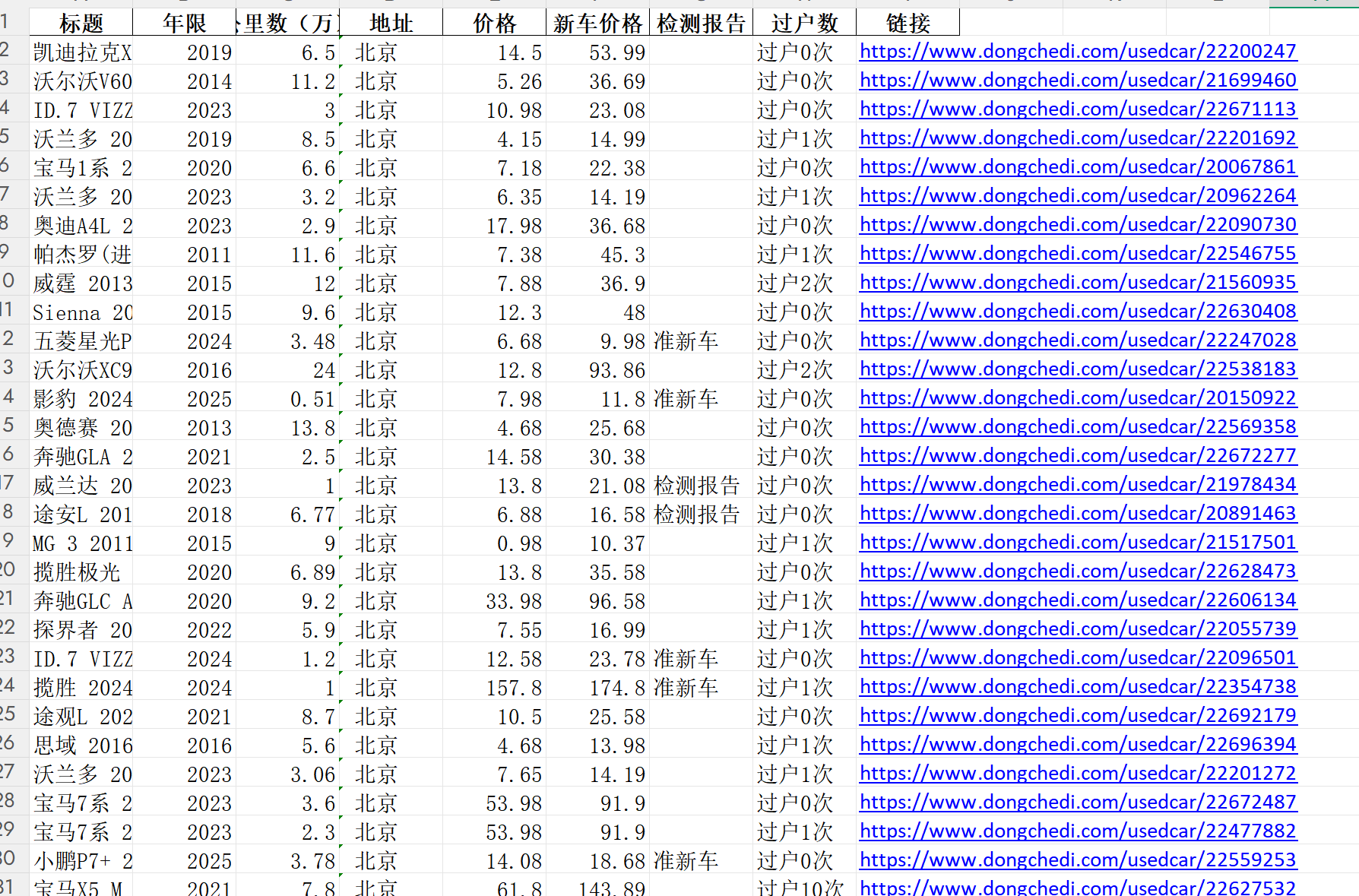
字段:标题,年限,公里数,地址,价格,新车价格,检测报告,过户数,链接。
后续拿到数据,可以再进一步进行数据可视化,数据分析。
四、总结与说明
本爬虫项目完整展示了从动态页面获取、字体反爬破解、到数据清洗存储的全流程。它不仅仅是一个脚本,更是一套解决特定复杂爬虫问题的技术方案。
温馨提示:爬虫技术应用于学习与研究。在实际使用时,请务必尊重网站的
robots.txt协议,合理控制请求频率,避免对目标网站造成过大压力。
希望这篇详细的技术解析能对你有所帮助。如果对字体反爬的深度破解、DrissionPage的高级应用,或基于此数据的分析案例感兴趣,欢迎关注我的同名此平台的公主号获取。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)