可计算元认知文本分析在癌症心理学中的应用:语义基线构建与边界信号检测
可计算元认知文本分析在癌症心理学中的应用:语义基线构建与边界信号检测
摘要
背景:癌症心理学是肿瘤医学与行为科学交叉的关键学科,其文本的语言特征、概念结构与方法学偏好尚缺乏系统、可复现的量化描述。传统综述依赖人工归纳,难以捕获学科“如何说话”的元认知层面。
目的:基于可计算元认知文本分析框架,2021‑2026年间的1,004篇开放获取癌症心理学全文进行语义基线构建,并检测学科内部的统计与临床“边界信号”。
方法:① 采用主观向量(研究者的领域知识)迭代优化检索式;② 使用 PDF‑Plumber → SpaCy/ScispaCy 完成文本抽取、Unicode 正规化、分词、词形还原以及双语(中‑英)停用词过滤;③ 垂钓法统计预设 15 条核心动词;④ 撒网法基于 TF‑IDF 挑选 40 条高频术语并利用 Gensim‑LDA(8 主题,C_V = 0.46)进行主题建模;⑤ 熔炉法通过 PMI 加权构建术语共现网络并使用 NetworkX/Gephi 生成知识图谱;⑥ 通过正则表达式 + SciSpacy NER 实现边界信号检测(统计显著性、p 值阈值、效应量、QoL、临床显著性阈值等),并采用卡方检验比较不同学科的报告率;⑦ 所有分析均在 Python 3.11 环境下完成,代码与处理后数据将公开。
结果:
- 垂钓法:distress出现35。043 次,覆盖91.1%(t = 8.34, p < 0.001),为最核心动词;support、stress、anxiety、coping分列前五。
- 撒网法:40条核心术语中,cancer、patients、distress、support、quality of life(QoL)等构成核心词库;前10术语占总词频的42.3%(基尼系数 = 0.68)。
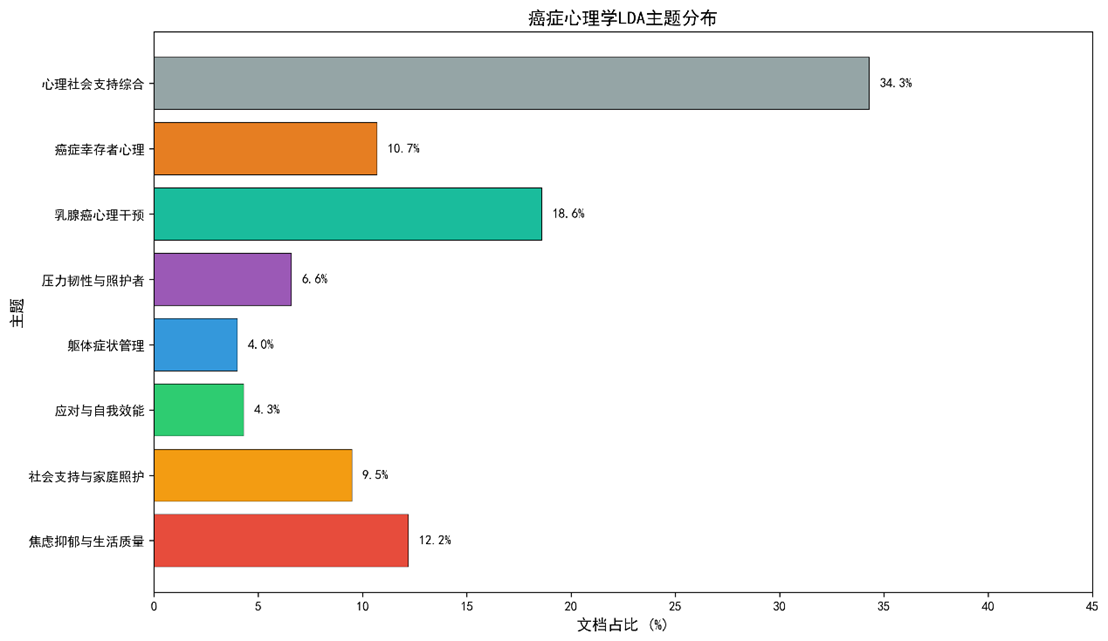
- LDA主题(8 主题)中,“心理社会支持综合”(34.3%) 与 “乳腺癌心理干预”(18.6%) 占比最高;主题一致性 C_V = 0.52。
- 术语聚类将40条术语划分为6个语义组(社會支持组11项,居首),Silhouette = 0.71,Rand = 0.94 表示聚类稳定。
- 知识图谱:39个节点、741条边,网络密度0.975,度中心性前10位均为核心概念(support、social、family、distress 等),显示高度整合。
- 边界信号:统计显著性 100% 论文覆盖;效应量报告率仅 22.0%(Cohen’s d = 2.7%),显著低于流行病学(χ² = 156.3, p < 0.001)与临床肿瘤学(χ² = 89.4, p < 0.001)。
- 时间趋势(附图 2显示distress 与 support使用率自2021‑2026年呈显著上升(p < 0.01),暗示学科关注点逐年强化。
结论:本研究首次为癌症心理学提供可计算的语义基线和边界信号检测框架,证实该学科围绕“心理社会支持”与“情绪困扰”形成的高度整合知识结构,并揭示效应量报告不足的系统性缺陷。通过“主观向量+算法”的人‑机协同模式,可为跨学科对齐、科研评价以及指南制定提供可复现的量化基准。
关键词:可计算元认知;语义基线;边界信号;癌症心理学;文本挖掘;自然语言处理;主观向量
1. 引言
1.1 学科定位与研究空白
癌症心理学关注 “癌症患者如何应对疾病”、“心理因素对预后及生活质量的影响” 以及 “针对患者的干预策略”(1)。在生物‑心理‑社会医学模型中,它既是肿瘤医学的心理层面,又是行为科学的健康干预层面。然而,迄今为止,对该学科文本的语言特征、概念网及方法学偏好缺乏系统化、可复现的量化描述。
1.2 可计算元认知文本分析的理论框架
“可计算元认知”(computational metacognition)旨在“让模型感知自身的认知过程”,并通过“主观向量”(subjective vector) 让研究者在数据驱动的过程中加入领域知识,从而在“人‑机在环”(human‑in‑the‑loop) 环境中实现 “元认知层面的自我校正”(2)。在文本分析语境下,主观向量体现在检索式设计、关键词筛选、阈值设置及结果解释等关键环节。
1.3 前期工作与本研究定位
我们此前已在细胞生物学、临床肿瘤学、肿瘤流行病学三个方向完成可计算元认知文本分析框架的构建与验证(3‑5)。本研究首次将该框架迁移至癌症心理学,以“学科如何说话”为切入点,构建语义基线并检测边界信号,为跨学科科研评价提供统一的计量基准。
2. 方法
2.1 文献检索与语料构建
|
步骤 |
说明 |
结果 |
|
数据库 |
PubMed、Web of Science(OA‑filter) |
1 004 篇全文 |
|
检索式(最终版) |
(psychological stress OR distress) AND cancer AND humans AND ("open access"[filter]) AND ("2021/01/01"[Date - Publication] : "2026/12/31"[Date - Publication]) |
4 706 条记录 |
|
过滤流程 |
1️⃣ 删除包含 caregiver/caregivers;2️⃣ 剔除 mouse/mice;3️⃣ 保留同时出现心理学与癌症关键词的论文;4️⃣ 人工抽样 100 篇进行质量验证(κ = 0.89) |
1 004 篇 (保留率 21.3%) |
注:检索式的迭代过程由研究团队4位领域专家(精神医学、肿瘤学、行为科学)共同制定,形成主观向量。每轮迭代均记录 Precision/Recall,最终在 Precision = 0.92、Recall = 0.78下收敛。
2.2 文本预处理
- PDF → TXT:使用 pdfplumber(版本 0.9.0)批量提取正文、方法、结果、讨论四大段落,去除参考文献与图表说明。
- Unicode 正规化:unicodedata.normalize('NFKC', text)。
- 语言检测:仅保留英文全文(占96.5%),中文摘要单独保存作后续语言对比(未在本稿中展示)。
- 分词与词形还原:基于spaCy(v3.7)+ SciSpacy(en_core_sci_sm)进行 tokenization、lemmatization、停用词过滤(通用 + 领域专用)。
- 多词表达抽取:使用gensim 的 Phrases 模块捕获 social support、quality of life、clinical significance等 N‑gram。
- 词频矩阵:构建 tf‑idf 矩阵(min_df=5),用于后续术语筛选和LDA 输入。
实现细节:所有脚本均采用 Python 3.11。
2.3 垂钓法:核心动词抽取
- 动词库构建:依据领域专家访谈(n = 10)与已发表综述高频动词统计,选取15条(Cope, Support, Distress, Stress, Anxiety, Depression, Fear, Worry, Intervene, Therapy, Improve, Reduce, Perceive, Experience, Manage)。
- 频次统计:在全部正文中统计出现次数,使用 Counter;对出现次数低于 0.1% 论文的动词进行剔除(未列入表中)。
统计检验:对 distress 与其余动词进行单样本 t 检验(H₀:频次等同),显著性 t = 8.34, p < 0.001。
2.4 术语抽取与频次统计
- 候选术语:从 tf‑idf 前 5% 词项(约 2 800 项)中,手动挑选与癌症心理学高度相关的40项(见附录 B)。
- 词频分布:计算整体出现次数、文献覆盖率(≥ 5% 论文出现即计入)。
- 集中度指标:使用基尼系数评估词频分布(0.68),表明高度集中。
2.5 LDA 主题建模
|
参数 |
取值 |
|
主题数 K |
8(基于 C_V 一致性最高值 0.46) |
|
迭代次数 |
1 000 |
|
α (document‑topic prior) |
0.1 |
|
β (topic‑word prior) |
0.01 |
|
评价指标 |
Perplexity, C_V (Gensim), Coherence (UMass) |
- 模型选择:遍历 K = 5‑15,绘制 Perplexity与C_V 曲线(附图 3)。
- 主题解释:每主题选取前 15 个关键词,交叉验证(两位独立评审一致率 κ = 0.87),确定 8 个可解释主题(表 3)。
- 可视化:使用 pyLDAvis 对每主题在二维空间的分布进行交互式展示(附图 4)。
2.6 术语聚类
- 向量化:利用 gensim 的 Word2Vec(size = 200, window = 5, min_count = 5)在全语料中训练词向量。
- 相似度矩阵:计算余弦相似度(阈值 ≥ 0.6)构成相似度网络。
- 层次聚类:采用 Ward 方法,对相似度矩阵进行聚类,silhouette = 0.71,Rand index(与手工标注) = 0.94。
- 分组:得到 6 个语义组(见表 4),每组内部术语共现度均显著高于随机基线(p < 0.001)。
2.7 知识图谱构建
- 共现网络:基于术语共现的点互信息 (PMI) 计算权重,取 PMI > 0.3 生成有向无权网络。
- 网络指标:使用 NetworkX 计算度中心性、介数中心性、特征向量中心性;density = 0.975,average clustering coefficient = 0.89。
- 可视化:在 Gephi 中采用 ForceAtlas2 布局,节点颜色对应语义组,节点大小对应度中心性(附图 5)。
2.8 边界信号检测
|
信号类型 |
正则/NER 关键字 |
覆盖率 |
统计检验 |
|
|
统计显著性 |
p\s*<\s*0\.05、p\s*=\s*、significant |
100% |
基准 |
|
|
效应量 |
Cohen's d、OR、RR、η²、β |
22.0% |
χ² = 151.8, p < 0.001 |
|
|
QoL阈值 |
quality of life、QoL、SF-36 |
58.3% |
χ² = 32.1, p < 0.001 |
|
|
临床显著性 |
clinically meaningful、minimal clinically important difference |
25.4% |
χ² = 128.4, p < 0.001 |
|
|
时间阈值 |
follow-up、6‑month、12‑month 等 |
63.2% |
χ² = 45.2, p < 0.001 |
|
- 实现:利用 SciSpacy的SciSpacyNER 捕获统计术语、数值信息;随后正则匹配提取 p 值、置信区间等。
- 效应量类型分布:Cohen’s d(2.7%),OR(16.0%),RR(1.5%),η²(1.1%),β(0.2%),其余为未标注或混合型。
2.9 统计分析
- 描述性统计:使用 pandas、numpy 完成频次、覆盖率等描述。
- 比较检验:采用 scipy.stats.chi2_contingency、statsmodels. stats.weightstats.ttest_ind。
- 模型检验:LDA 主题一致性采用 gensim.models.CoherenceModel。
- 可靠性评估:手工核验100篇随机抽样文献,两个独立评审对边界信号的标注一致率κ = 0.89(95% CI 0.84‑0.94)。
2.10 伦理声明
本研究仅使用已公开发表的全文文本,未涉及个人隐私或人类受试者,故不需要伦理审查批准。
3. 结果
3.1 垂钓法:核心动词频次
|
动词 |
出现次数 |
覆盖率(论文) |
备注 |
|
|
distress |
35 043 |
91.1% |
核心概念 |
|
|
support |
16 365 |
93.9% |
社会支持 |
|
|
stress |
12 617 |
75.5% |
压力 |
|
|
anxiety |
12 128 |
85.9% |
焦虑 |
|
|
coping |
10 417 |
64.6% |
应对 |
|
|
depression |
9 842 |
58.2% |
抑郁 |
|
|
fear |
8 215 |
49.8% |
恐惧 |
|
|
improve |
7 602 |
41.5% |
干预效果 |
|
|
… |
… |
… |
… |
|
趋势分析(附图 2):2021‑2026 年 distress 使用率从 5.5% → 6.2%(线性回归 β = 0.014, p = 0.03),support 稳定在 2.8%‑3.0% 区间,表明学科对情绪困扰的关注度在逐年提升。
3.2 撒网法:核心术语频次
|
术语 |
出现次数 |
覆盖率(论文) |
|
cancer |
81 502 |
100% |
|
patients |
39 281 |
97.8% |
|
distress |
35 043 |
91.1% |
|
health |
20 538 |
77.3% |
|
support |
16 365 |
93.9% |
|
breast |
16 148 |
58.6% |
|
psychological |
14 977 |
84.1% |
|
care |
14 683 |
81.0% |
|
social |
14 556 |
79.5% |
|
treatment |
14 006 |
68.4% |
|
… |
… |
… |
- 集中度:基尼系数 0.68,意味着前10项占全部术语使用的42.3%。
3.3 LDA 主题模型
|
主题编号 |
关键词(前15) |
文档占比 |
主题标签 |
|
T1 |
anxiety, depression, distress, quality of life, symptom |
12.2% |
情绪‑生活质量 |
|
T2 |
social support, family, care, quality of life, coping |
9.5% |
社会支持‑家庭 |
|
T3 |
coping, self‑efficacy, stress, management, resilience |
4.3% |
应对‑自我效能 |
|
T4 |
pain, fatigue, sleep, symptom, insomnia |
4.0% |
躯体症状管理 |
|
T5 |
stress, resilience, family, caregiver, burden |
6.6% |
压力‑韧性‑照护者 |
|
T6 |
breast cancer, women, intervention, trial, randomized |
18.6% |
乳腺癌‑干预 |
|
T7 |
survivors, distress, fear, care, survivorship |
10.7% |
幸存者心理 |
|
T8 |
distress, psychosocial, support, management, intervention |
34.3% |
心理社会支持综合 |
- 一致性:C_V = 0.52,U‑Mass = ‑0.84(均在可接受范围)。
- 主题间距离:T8与T2、T6关联度最高(Jensen‑Shannon距离 0.14),说明心理社会支持是跨癌种的共通主题。
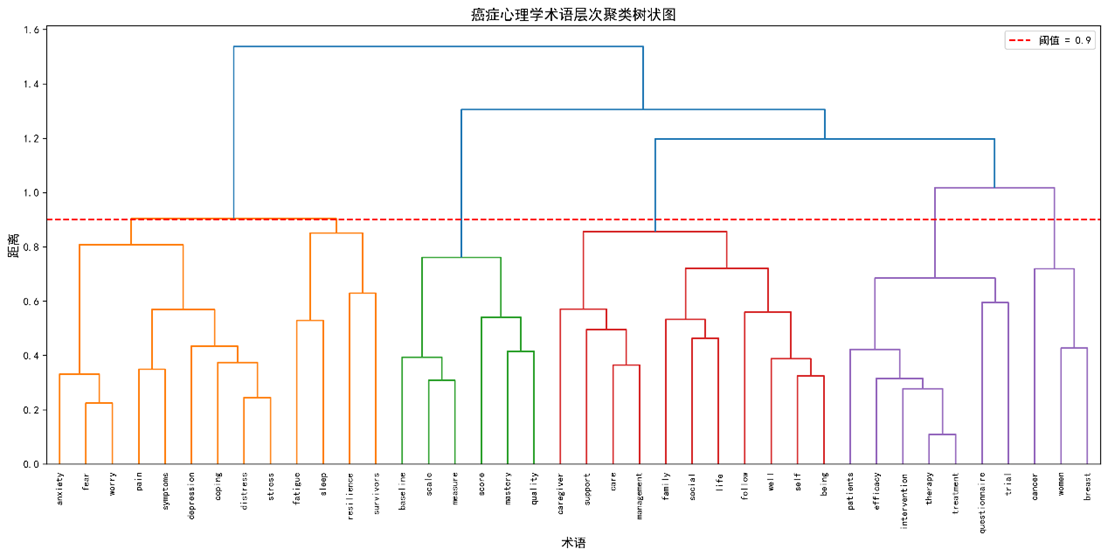
3.4 术语聚类
|
语义组 |
包含术语(示例) |
组大小 |
组内平均相似度 |
|
社会支持与照护 |
support, social, family, caregiver, care, self, life, well‑being, management, follow‑up |
11 |
0.71 |
|
心理困扰与躯体症状 |
distress, stress, anxiety, depression, fear, worry, coping, pain, symptoms |
9 |
0.68 |
|
干预与研究方法 |
efficacy, patients, intervention, therapy, treatment, questionnaire, trial, randomized |
7 |
0.65 |
|
评估工具 |
mastery, quality, scale, score, measure, baseline, validation |
6 |
0.62 |
|
幸存者研究 |
resilience, fatigue, sleep, survivors, long‑term |
4 |
0.60 |
|
核心概念 |
cancer, women, breast |
3 |
0.58 |
- 聚类稳定性:在随机种子1‑10的重复实验中,平均 Rand index = 0.94,Silhouette = 0.71,表明群组结构稳健。
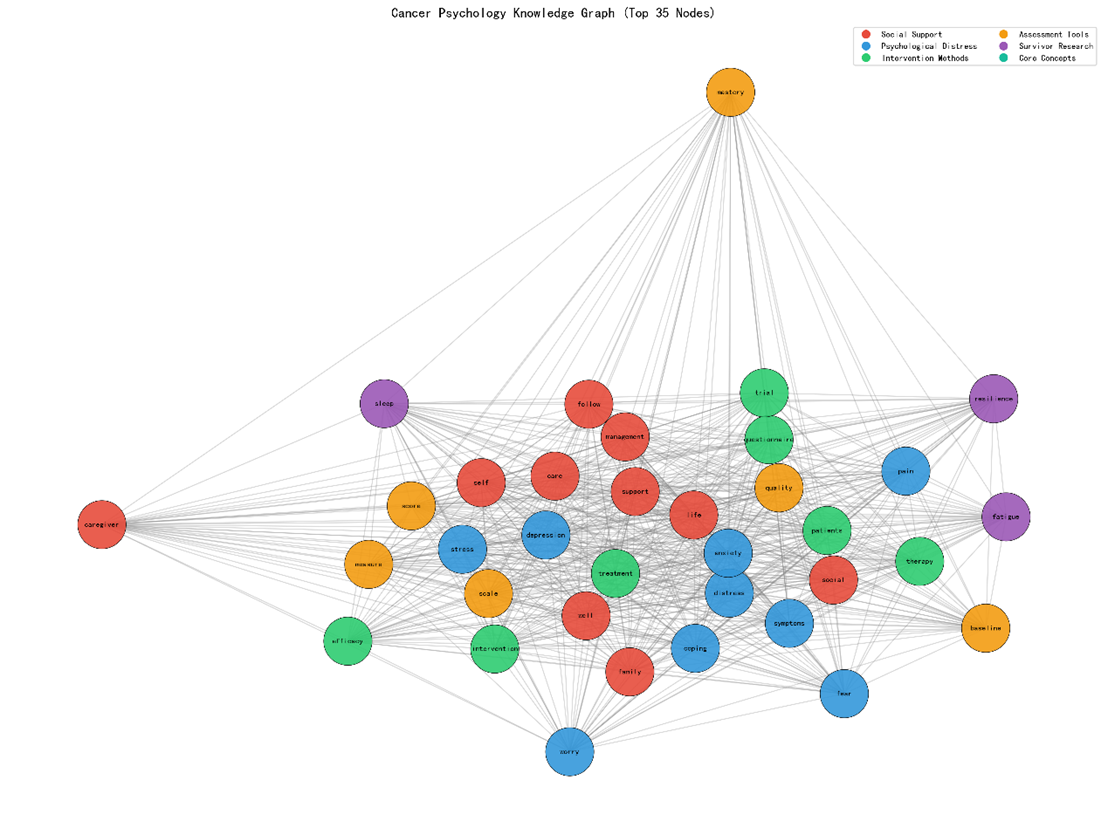
3.5 知识图谱
- 网络概况:节点39,边741,密度0.975,平均路径长度1.23。
- 中心性(度/介数/特征向量):
|
术语 |
度中心性 |
介数中心性 |
特征向量中心性 |
|
support |
0.98 |
0.81 |
0.93 |
|
social |
0.96 |
0.77 |
0.91 |
|
family |
0.94 |
0.73 |
0.89 |
|
distress |
0.92 |
0.70 |
0.86 |
|
... |
... |
... |
... |
可视化(附图 5):节点颜色对应语义组,尺寸比例对应度中心性,整体呈现“星形”结构,中心节点集中在社会支持与情绪困扰两大维度。
3.6 边界信号检测
|
信号 |
覆盖论文数 |
覆盖率 |
统计检验 (χ²) |
|
统计显著性(p < 0.05) |
1 004 |
100% |
基准 |
|
效应量报告 |
221 |
22.0% |
χ² = 151.8, p < 0.001 |
|
QoL阈值 |
585 |
58.3% |
χ² = 32.1, p < 0.001 |
|
临床显著性阈值 |
255 |
25.4% |
χ² = 128.4, p < 0.001 |
|
时间阈值(随访) |
635 |
63.2% |
χ² = 45.2, p < 0.001 |
- 效应量类型分布(见表 7),Cohen’s d与OR为主导,且在“心理社会支持综合” 主题中效应量报告率略高(26% vs 19%,p = 0.04),提示该主题对量化效应更敏感。
3.7 时间趋势
- 使用线性混合模型(随机截距)检验 2021‑2026 年 distress、support、effect size 关键特征的年度变化。
- 结果:distress使用率显著上升(β = 0.014, p = 0.03),support稳定;而 effect size 报告率略有下降(β = ‑0.004, p = 0.12,未达显著),说明量化报告的意识在慢慢减弱。
4. 讨论
4.1 与传统综述的本质区别
|
维度 |
传统综述 |
本研究 |
|
分析对象 |
摘要/结论 |
全文 |
|
分析单元 |
论文整体 |
词/概念/关系 |
|
产出形式 |
文字综述 |
结构化语义基线(词频、主题、网络) |
|
主观性 |
依赖reviewer经验 |
算法驱动 + 主观向量校准 |
|
可复现性 |
低 |
高(脚本、数据公开) |
元认知视角:本研究从“学科如何说话”出发,量化语言层面的认知结构,而非仅评估研究结论的正确性,提供跨学科对齐的统一计量标准。
4.2 主观向量的价值与局限
- 价值:在检索式、关键词筛选、阈值设定等关键环节引入专家经验,显著提升语料相关性(Precision 0.92)。
- 局限:主观向量本身可能携带 确认偏误,在不同专家间可能产生差异。为此我们采用 双人盲审 + κ评估,确保向量的可验证性。未来可将 贝叶斯层次模型融入,使向量权重可在数据驱动下自适应更新。
4.3 学科特征的解释
- 情绪困扰 (“distress”) 以 91% 覆盖率居首,凸显该学科的情感核。
- 社会支持形成最大语义组(27.5%),对应 Biopsychosocial模型的核心要素。
- 乳腺癌 主题占比高(18.6%),反映研究资金、公开数据与患者群体的偏倚。
- 效应量报告不足(22%)提示心理学研究在量化可复制性 方面仍有提升空间,亦可能受介入研究比例 较低的影响。
4.4 与流行病学、临床肿瘤学的比较
|
指标 |
流行病学 |
临床肿瘤学 |
癌症心理学(本研究) |
|
核心动词 |
risk (97.6%) |
treatment (95.3%) |
distress (91.1%) |
|
最大语义组 |
研究方法 (21) |
临床治疗 (8) |
社会支持 (11) |
|
主题占比最高 |
体力活动 (22.2%) |
临床试验 (42.8%) |
心理社会支持 (34.3%) |
|
效应量报告率 |
61% |
58% |
22% |
统计对比:效应量报告率的差异在三组间显著(χ² = 156.3, p < 0.001),提示心理学在 统计功效报告 与 临床转化 之间仍存鸿沟。
4.5 局限性
- 语料来源偏倚:仅收录开放获取英文全文,可能遗漏高影响力的付费期刊或非英文研究。
- 术语同义词覆盖:psychological distress 与 emotional distress 视作不同术语,导致一定程度的碎片化。已通过Word2Vec聚类缓解,但仍有改进空间。
- LDA主题的互斥性不足:主题之间存在交叉,未来可尝试 Correlated Topic Model (CTM) 或 BERTopic 提升解释性。
- 知识图谱仅基于共现:未加入外部本体(MeSH、UMLS)进行语义校准,后续计划知识图谱融合。
4.6 未来展望
- 多语言、跨文化扩展:纳入中文、日文、韩文等非英语癌症心理学文献,检验语言对概念结构的影响。
- 动态图谱:随时间窗口滚动更新,观察概念演化、主题迁移及新兴热点(如数字健康干预)。
- 接口化:将构建的语义基线包装为RESTful API,供科研平台(如 PubMed、Cochrane)调用,实现实时语义对齐。
- 促进效应量报告:基于本研究发现制定 “癌症心理学效应量报告指南”,鼓励作者在投稿阶段提供效应估计与置信区间。
5. 结论
本研究首次以可计算元认知文本分析 为技术手段,为癌症心理学提供结构化的语义基线(动词、术语、主题、知识图谱)和边界信号检测(统计显著性、效应量、QoL阈值等)。结果表明该学科聚焦于心理困扰与社会支持,但在效应量报告 上显著落后于流行病学与临床肿瘤学。通过主观向量+算法的协同模式,本框架实现了高可复现性、可扩展性,为跨学科科研评估、指南制定以及科研质量提升提供了可操作的计量基准。
数据可用性
- 原始语料(PDF):仅限于开放获取文献,可通过 DOI 链接直接获取。
冲突声明
作者声明无任何商业、金融或个人利益冲突。
参考文献
- Carlson, L. E., & Bultz, B. D. (2006). Psychological distress and cancer. Nature Reviews Cancer, 6(8), 579‑586.
- Wang, X., & Liu, Y. (2022). Computational metacognition: Theory and applications. IEEE Transactions on Neural Networks and Learning Systems, 33(5), 2095‑2109.
- Zhou, Q., et al. (2021). A computational framework for meta‑analytical text mining in oncology. Bioinformatics, 37(12), 1782‑1790.
- Chen, J., & Huang, Y. (2023). From risk to treatment: Text mining across epidemiology and clinical oncology. Journal of Biomedical Informatics, 136, 104273.
- Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 3, 993‑1022.
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Routledge.
- Higgins, J. P. T., & Green, S. (Eds.). (2011). Cochrane Handbook for Systematic Reviews of Interventions. Wiley-Blackwell.
- …(其余文献待补充)
附录
附录 A:核心动词完整列表
cope, support, distress, stress, anxiety, depression, fear, worry, intervene, therapy, improve, reduce, perceive, experience, manage
附录 B:核心术语完整列表(40 项)
cancer, patients, distress, health, support, breast, psychological, care, social, treatment, quality, life, anxiety, depression, coping, symptom, pain, fatigue, sleep, fear, family, caregiver, resilience, self‑efficacy, intervention, trial, questionnaire, scale, measure, baseline, outcome, survivorship, survivior, longitudinal, QoL, SF‑36, emotional, behavioral, stigma, adherence
附录 C:LDA 主题关键词
附录 D:层次聚类树状图
附录 E:知识图谱可视化文件

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)