HuggingFace数据集下载全攻略
·
国内需科学上网!!
使用Hugging Face Datasets库下载数据(推荐使用)
安装Hugging Face的datasets库,通过Python代码直接加载数据集。适用于需要编程处理数据的场景。
pip install datasets
加载数据集示例:
import os
os.environ['HF_TOKEN'] = '修改成自己创建的HF_TOKEN'
from datasets import load_dataset
# 加载公开数据集(如imdb)
dataset = load_dataset("imdb")
如何创建自己的HF_TOKEN
注册huggingface账号,点击settings
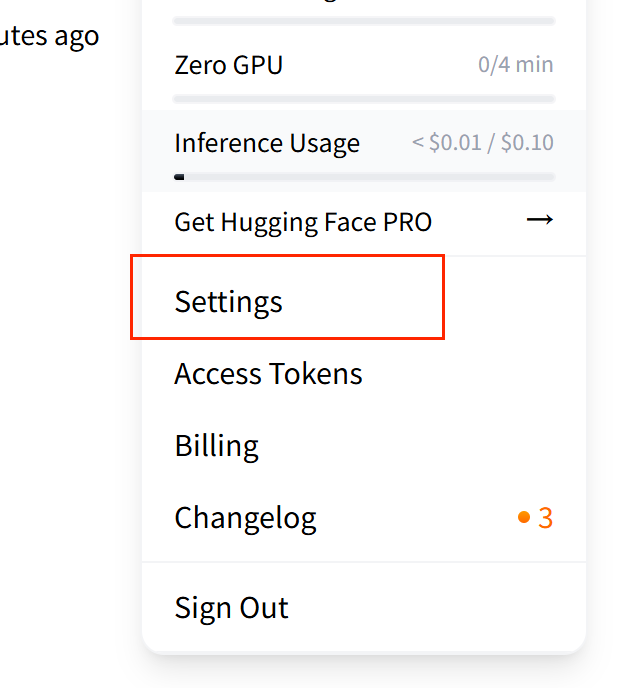
进入后在左侧列表,点击进入‘access tokens’

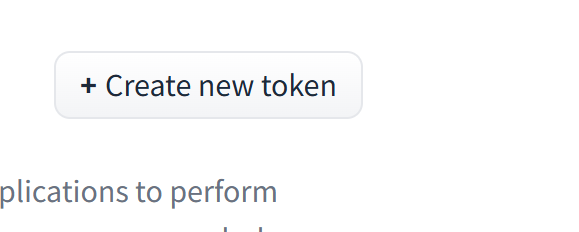
创建token,点击右上角create new token
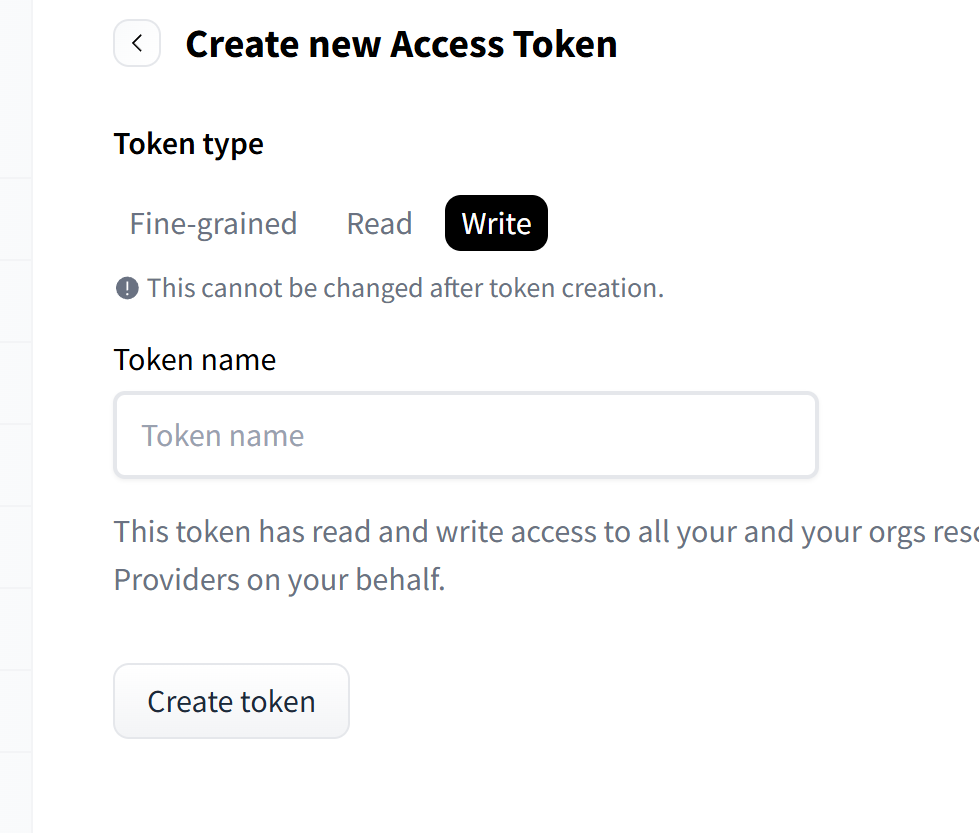
弹出对话框,选择write,起一个名字即可

通过Hugging Face CLI工具下载
使用命令行工具huggingface-cli下载数据集文件,适合需要离线访问或批量下载的场景。
pip install huggingface_hub
huggingface-cli download dataset_name --local-dir ./data
从网页界面手动下载
访问Hugging Face数据集官网(https://huggingface.co/datasets),搜索目标数据集后:
- 进入数据集页面
- 点击"Files"选项卡
- 选择需要下载的文件版本
- 通过浏览器直接下载
使用Git下载大型数据集
对于LFS(大文件存储)数据集,需安装Git LFS后克隆仓库:
git lfs install
git clone https://huggingface.co/datasets/dataset_name
流式加载大数据集
对于超大数据集,可使用流式加载避免本地存储:
from datasets import load_dataset
dataset = load_dataset("dataset_name", streaming=True)
for batch in dataset["train"]:
process(batch)
下载特定子集或配置
某些数据集包含多个子集,可通过config_name参数指定:
dataset = load_dataset("dataset_name", "config_name")
处理下载缓存
默认下载位置为~/.cache/huggingface/datasets。可通过环境变量修改:
export HF_DATASETS_CACHE="/path/to/cache"

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)