机器学习学习笔记1:k-近邻算法实现鸢尾花分类
(一)实验目的与背景
基于python的sklearn库与pandas库,通过k-近邻算法(KNN)实现鸢尾花三分类模型的构建。
scikit-learn是Python中一个强大的机器学习库,提供了各种监督学习和无监督学习算法。
鸢尾花数据集为机器学习中经典的数据集,包含150个样本,其中每个样本包含4个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度)和1个类别标签(Setosa、Versicolour、Virginica)。
K近邻是一种基于实例的学习算法,通过计算待分类样本与训练样本的距离,选取距离最近的K个样本,根据这K个样本的类别投票决定待分类样本的类别。
(二)实验过程
数据导入与探索:导入必要的库:numpy、pandas、matplotlib、seaborn、sklearn等,并加载鸢尾花数据集并进行初步探索。
数据预处理:将数据集分为特征(X)和目标变量(y),使用StandardScaler对特征进行标准化处理,将数据集划分为训练集和测试集(75%训练,25%测试)。
模型训练:初始化K近邻分类器(K=3)并在训练集上拟合模型。
模型评估:在测试集上进行预测,并计算准确度、混淆矩阵和分类报告。
(三)代码实现
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
#(1)读取数据
data = pd.read_csv('iris.csv', header=None)# 数据集来自本地下载
data.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
#(2)数据探索
X = data.iloc[0:150,[0,2]].values # 取前150行,前第0列和第2列的数据,即花瓣宽度和萼片长度
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.scatter(X[0:50,0],X[:50,1],color = 'blue',marker='x',label=('山鸢尾花 setosa'))
plt.scatter(X[50:100,0],X[50:100,1],color='red',marker='o',label=('变色鸢尾花 versicolor'))
plt.scatter(X[100:150,0],X[100:150,1],color='green',marker='*',label=('维吉尼鸢尾花 virginica'))
plt.xlabel('瓣宽 petal width')
plt.ylabel('萼长 sepal length')
plt.legend(loc='upper left')
plt.show()
#(3)数据预处理
# 定义特征和标签
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=7)
# 特征标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
#(4)KNN模型构建
# 创建KNN分类器
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 预测
y_pred = knn.predict(X_test)
# 评估模型
print("准确度:", accuracy_score(y_test, y_pred))
print("混淆矩阵:\n", confusion_matrix(y_test, y_pred))
print("分类报告:\n", classification_report(y_test, y_pred))(四)实验结果
1.以花瓣宽度与萼片长度为标准的类别分布(数据探索):
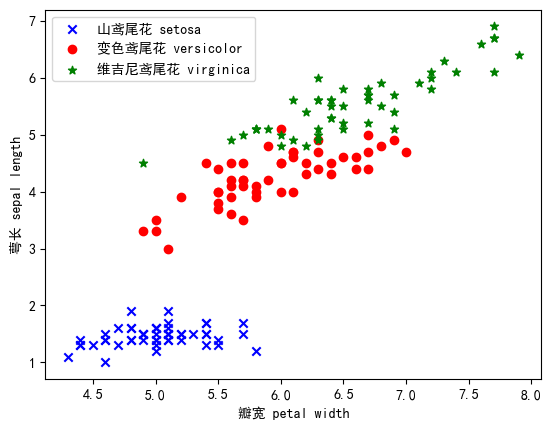
可以看出以以花瓣宽度与萼片长度为标准的情况下,山鸢尾花的区别十分明显,变色鸢尾花与维吉尼鸢尾花的区别较为明显,但仍有相似的样本。
2.模型评估结果:
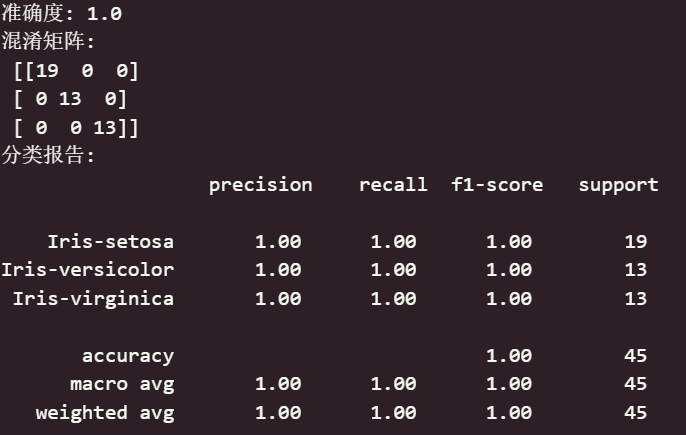
可以看出三个指标均为最佳,模型在测试集上完美分类了所有样本。
(五)总结
本实验成功实现了使用K近邻算法对鸢尾花数据集进行三分类的任务,并取得了完美的分类效果(因为鸢尾花数据集本身特征区分度较高),同时了解了机器学习分类任务的基本流程,为后续更复杂的机器学习项目打下了基础。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)