顶会创新idea!少样本目标检测,准确率高达95%!
2张正常芯片图,精准定位0.1毫米微小划痕;4张病例影像,锁定罕见皮肤病灶。2025年CVPR、NeurIPS顶会的新成果,正让少样本目标检测彻底摆脱“数据饥荒”。放在以前,传统模型在小数据场景下根本撑不起场面,小众目标标注少,要么特征提不清晰,要么把相似物体搞混。工业质检里,漏检率常突破30%;医疗诊断中,结果更是不敢作为参考。现在,视觉提示+特征配准的新架构来了个大反转。IDEA研究院的Rex-Omni靠“下点预测”,零样本检测精度直接超过经典模型DINO;CAReg用跨类配准技术,工业缺陷检测AUC较传统方法提升11.3%,新类别还不用微调参数。具体来看,芯片质检仅需2张样本,准确率就达95%;罕见病诊断4张病例,识别精度能到91%。
论文er重点关注视觉提示、无监督配准、跨域泛化准没错。我整理了相关顶会/顶刊核心论文,部分还附带复现代码打包免费送,感兴趣的同学工种号 沃的顶会 扫码回复 “少样本目标” 领取。
Domain-RAG: Retrieval-Guided Compositional Image Generation for Cross-Domain Few-Shot Object Detection
文章解析
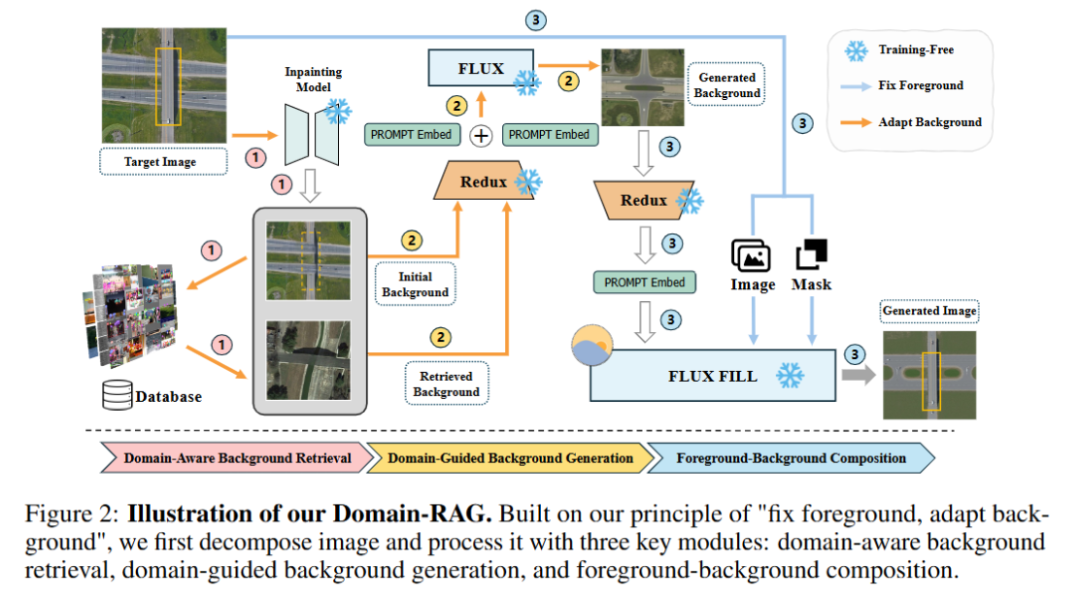
跨域少样本目标检测(CD-FSOD)旨在仅用极少量标注样本在未见域中检测新物体。现有数据增强方法如copy-paste或文本到图像生成难以同时保证视觉真实性和域一致性。本文提出Domain-RAG,一种无需训练的检索引导组合图像生成框架,通过分解图像为前景与背景、基于语义和风格检索相似背景、利用生成模型合成域对齐的新背景,并将原始前景无缝融合其中,从而生成高质量且域一致的训练样本。该方法无需额外监督或训练,适用于CD-FSOD、遥感及伪装场景下的少样本检测任务,实验表明其显著优于强基线并达到新的最先进性能。
创新点
提出首个专为跨域少样本目标检测设计的检索引导图像生成框架Domain-RAG。
采用‘固定前景、适配背景’策略,在保留原始对象的同时实现背景的域对齐生成。
结合检索增强生成(RAG)思想,利用真实图像作为视觉先验指导背景合成,提升语义与风格一致性。
整个框架无需训练,可即插即用于现有检测器,特别适合1-shot等极端低资源场景。
支持多类型下游任务,包括遥感和伪装环境下的少样本检测,展现广泛适用性。
研究方法
首先将输入图像分解为前景与背景,使用图像修复模型恢复掩码区域以获得干净背景。
从大规模图像库(如COCO)中检索语义和风格上与修复背景相似的候选背景图像。
利用Redux技术将检索到的视觉线索转换为文本提示,驱动文本到图像生成模型合成新背景。
通过mask引导的生成模型将原始前景与生成的域对齐背景进行融合,形成最终图像。
全过程无需微调或额外标注,完全基于预训练模型与外部数据库完成。
研究结论
Domain-RAG能有效生成视觉逼真且域一致的训练样本,显著提升CD-FSOD性能。
相比copy-paste和纯文本引导生成方法,本方法在保持类别准确性和上下文连贯性方面更具优势。
在多个跨域少样本检测基准(包括自然图像、遥感、伪装场景)上均取得当前最优结果。
无需训练的设计使其具备高实用性与部署便捷性,尤其适用于标注稀缺的真实应用场景。
未来工作可扩展至更多模态或动态场景下的少样本检测任务。
Temporal Object-Aware Vision Transformer for Few-Shot Video Object Detection
文章解析
本文提出了一种新的少样本视频目标检测(FSVOD)方法,通过引入目标感知的时序建模机制,解决视频中因遮挡、外观变化和有限标注样本带来的检测难题。该方法利用视觉-语言预训练的Transformer模型(如OWL-ViT),通过筛选机制跨帧传播高置信度目标特征,实现高效特征演化并减少噪声积累。与依赖复杂区域提议的传统方法不同,本方法无需显式生成目标管(object tube),在多个基准上显著提升了检测精度。
创新点
提出一种新颖的目标感知时序建模方法,选择性地跨帧传播高置信度目标特征。
首次将大规模视觉-语言预训练模型(如OWL-ViT)适配用于少样本视频目标检测任务。
设计无需区域提议的端到端学习框架,直接基于少样本训练的检测头进行条件化检测。
通过融合历史检测特征增强时序一致性,提升对遮挡和外观变化的鲁棒性。
在多个FSVOD基准上实现显著性能提升,验证了方法在不同shot设置下的泛化能力。
研究方法
采用视觉-语言预训练的Vision Transformer作为骨干网络,提取具有强语义的图像特征。
构建支持集与查询视频之间的视觉提示匹配机制,实现少样本条件下的目标识别。
设计过滤机制,仅传播高置信度的目标特征至后续帧,避免低质量特征的噪声累积。
在解码器中融合当前帧与历史帧的目标表示,增强跨时间的目标一致性。
使用对比学习优化视觉编码器,提高对相似类别和部分可见目标的区分能力。
研究结论
所提方法在5-shot设置下于FSVOD-500、FSYTV-40、VidOR和VidVRD数据集上分别提升AP达3.7%、5.3%、4.3%和4.5%。
在1-shot、3-shot和10-shot配置下均表现出一致的性能增益,证明其良好的泛化性。
无需依赖复杂的区域或管提议网络即可实现强时序一致性,简化了检测流程。
结合视觉-语言先验知识显著增强了对新类别对象的检测能力。
代码已开源,为未来少样本视频理解研究提供了可复现的基础。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 10
10 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)