Milvus向量数据库学习笔记(4)
第二索引篇3
这是索引的第3篇了,其实写到上一篇的时候,我就有些后悔。整个学习笔记是一边读一边写。有点像Milvus官网的翻译加注解的意思。但是,产品官网的重点,在于产品功能的罗列。但是,从学习的角度上来,这样的行文结构,就不太合理。
向量数据库索引结构非常显著的分为索引、量化算法两大部分。而Milvus的索引实现,呈现出来是一个索引加一个量化的组合形态。前后有一些重复冗余的内容。如果索引归索引,量化归量化,拆分开来学习,其实结构更加清晰。
但是,既然已经写了一半了,我还是先把所有的索引都写完,等写完之后,我再尝试把索引所有的内容,重新整理结构再写一次。
HNSW算法
在索引这条线,除了IVF索引算法写完了。另一个重要算法就是HNSW算法。HNSW是一个基于图的索引算法。可以提高搜索高维浮点向量时的性能。它具有出色的搜索精度和低延迟。但需要较高的内存开销来维护其分层图结构。对于索引而言,我们的关注焦点,依然还是放在,索引是如何减少无关数据的读入。
HNSW算法构建一个多层图,底层包含所有数据点,而上层则由从底层采样的数据点子集组成。在这个层次结构中,每一层都包含代表数据点的节点,节点之间由表示其接近程度的边连接。上层提供远距离跳转,用来快速接近目标,下层进行细粒度搜索,获取准确的结果。这个表述还是有点抽象,可以想象我们在一个地图APP中,打算寻找上海中心塔。我们肯定是把地图缩放到很大,然后选中上海。然后把上海地区搓大之后,再点到陆家嘴附近。再搓大,然后精确的找到上海中心。那这个搜索行为,就有点像HNSW的搜索过程。
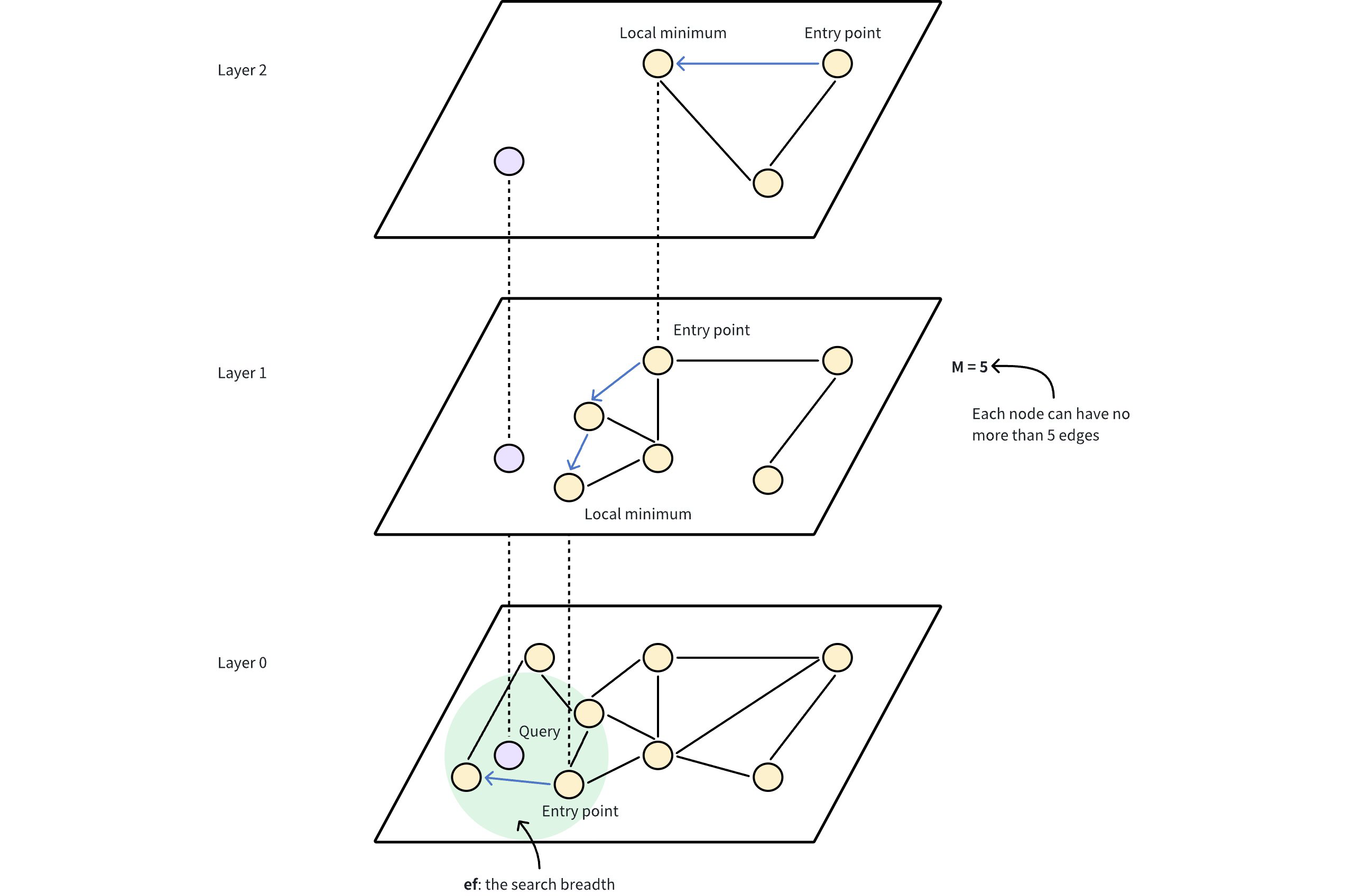
根据官网的工作原理表述,搜索流程如下:
1.入口点:搜索从顶层的一个固定入口点开始,该入口点是图中的一个预定节点。
2.贪婪搜索:算法贪婪地移动到当前层的近邻,直到无法再接近查询向量为止。上层起到导航作用,作为粗过滤器,为下层的精细搜索找到潜在的入口点。
3.层层下降:一旦当前层达到局部最小值,算法就会利用预先简历的连接跳转到下层,并重复贪婪搜索。
4.最后细化:这一过程一直持续到最底层,再最底层进行最后的细化步骤,找出最近的邻居。
HNSW的性能取决于控制图结构和几个关键参数:
M:图中每个节点在层次结构的每个层级所能拥有的最大边数或连接数。M越大,图密度越高,召回率和准确率越高,内存消耗越大。
efConstruction:索引构建过程中考虑的候选节点梳理,越高则图的质量越好,构建时间越长。
Ef:搜索过程中评估的邻居数量。增加ef可以提高找到最佳邻居的可能性,但会增加搜索时间。
PRQ残差量化算法
根据官网的说明,这个索引除了标准的HNSW算法(这里应该就是平铺量化)。还搭配的量化算法有SQ(标准量化),这种用于减少内存使用,简化HNSW图的大小,可选SQ6,SQ8,BF16,FP16。默认为SQ8,前2者是偏考虑内存,后2者偏考虑精度。PQ(乘积量化)也和之前类似。
除此之外,PRQ(残差产品量化)算法,是HNSW索引新出现的。按官网说法,PRO算法超越了传统的PQ,引入了残差量化来捕捉更多信息。可以实现更高的精度或更紧凑的索引。不过额外的步骤,需要索引构建和搜索过程的计算开销增加。它大致工作原理有。
1.乘积量化(PQ),和之前一样,把原始向量划分为子向量,用码本上子向量替换。
2.残差量化(RQ),在PQ阶段之后,RQ使用额外的编码本量化残差,也就是原始向量与其基础PQ的近似值之间的差值。因为残差通常要小很多,因此可以在不增加大量存储空间的情况下,对其进行更精确的编码。参数nrq决定了残差被迭代量化的次数,让你可以微调压缩效率和精确度之间的平衡。这里我理解就是残差再残差,不断循环。
3.最终压缩表示。RQ完成对残差的量化后,PQ和RQ的整数代码将合并为一个压缩索引。通过捕捉PQ可能忽略的精细细节,RQ在不显著增加存储空间的情况下提高了精确度。PQ和RQ协作定义为PRQ。
DISKANN算法
至此,IVF和HNSW两大内存索引的内容完结。那在大规模场景中,数据集过大时,内存限制就非常明显。所以接下来就是DISKANN算法。这是一种基于磁盘的方法,在数据量大于RAM时,保持较高的搜索精度和速度。
DISKANN算法由Vamana图索引算法和PQ量化算法构成。
Vamana图形-一种基于磁盘的图形索引,可将数据点(或向量)连接起来。以便在搜索过程中高效导航。
乘积量化(PQ)
Vamana图的构建过程
1.初始随机连接:每个数据点(向量)在图中表示为一个节点。这些节点最初时随机连接的,形成一个密集的网络。通常情况下,一个节点开始时会有大约500条边(或连接),以实现广泛的连接。
2.细化以提高效率:初始随机图需要经过优化过程,以提高搜索效率。这包括两个关键步骤:
(1)修剪多余的边:算法根据节点之间的距离丢弃不必要的连接。这一步优先处理质量较高的边。max_degree参数限制了每个节点的最大变数。max_degree越高,图的密度越大,有可能找到更多相关的相邻节点(召回率更高),但也会增加内存使用量和搜索时间。
(2)添加战略捷径:Vamana引入了长距离边,将向量空间中相距甚远的数据点连接起来。这些捷径允许搜索在图中快速跳转,绕过中间节点,大大加快了导航速度。search_list_size参数决定了图细化过程的广度。较高的search_list_size可以在构建过程中扩展对邻接节点的搜索,从而提高最终准确性,但会增加索引构建时间。
而PQ量化在此处有几个重要的参数。pq_code_budget_gb_ratio参数用于管理存储这些PQ代码的内存暂用。它表示向量的总大小与分配用于存储PQ代码的空间之间的比率。计算公式如下:
PQ Code Buget(GB)= vec_field_size_gb*pq_code_budget_gb_ratio
vec_field_size_gb是向量的总大小
pq_code_budget_gb_ratio是用户定义的比率。表示PQ代码保留总数据大小的一部分,该参数允许在搜索精度和内存资源之间进行权衡。
DISKANN的建立索引后,将执行ANN搜索,具体过程如下:
1.入口点:提供一个查询向量以定位其最近的邻居。DISKANN从Vamana图中选定的入口点开始,通常时数据集全局中心点附近的一个节点。全局中心点代表所有向量的平均值,这有助于最小化图中的遍历距离,从而找到所需的邻居。
2.邻居搜索:该算法从当前节点的边缘收集潜在的候选邻居。利用内存中的PQ码来估算这些候选邻节点与查询向量之间的距离。这些潜在的候选邻节点是通过Vamana图中的边直接连接到所选入口点的节点。
3.选择节点进行精确距离计算:在近似结果中,选择最优希望的邻节点子集,使用他们未经压缩的原始向量进行精确的距离评估。这需要从磁盘中读取数据,非常耗时。DISKANN使用两个参数来控制精度和速度之间的微妙平衡:
(1)bream_width_ratio:一个控制搜索广度的比率,它决定了有多少候选邻节点会被冰箱选择以探索其邻节点。bream_width_ratio越大,搜索范围越广,可能带来更高的精度,但也会增加计算成本和磁盘I/O。公式如下:
Beam width = Number of CPU cores * bread_width_ratio
(2)search_cache_budget_gb_ratio:为缓存频繁访问的磁盘数据而分配的内存比例。这种缓存有助于最大限度地减少磁盘I/O,使重复搜索更快,因为数据已经在内存中。
4.迭代探索:搜索会迭代完善候选集,反复执行近似评估,然后进行精确检查,指导找到足够数量的邻节点。
默认的设定
默认情况下,Milvus 会禁用DISKANN,以优先提高内存中索引的速度在Milvus里。
这个默认,感觉有一些倾向性,表名产品,不倾向于,在查询的时候,去进行磁盘IO行为。看起来并不稀奇,但是这个倾向性不是说,要利用好索引,减少查询中的IO行为。而是,最好在查询里面,不要有IO行为。感觉,好像在表达某种意思,就是海量数据下的相似性搜索是不靠谱的。是不是有这个感觉。当然,不是所有向量数据库产品都是如此,也还是有的产品把DISKANN当最主要的索引了的。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)