机器学习-手写朴素贝叶斯分类器,附代码详细讲解(C++/Python实现)
目录
前言
本文实现环境的集成开发工具都是教育版、个人版
C++:VS2022
Python:Pycharm、anaconda环境下的包numpy
实现只讲核心代码,由于C++先讲,而且讲解不太涉及语法层面,Python的只讲不同之处,其他省略
实现项目交到github仓库管理
贝叶斯公式
公式说明
公式原理:通过先验概率计算后验概率
核心公式:
A是我们需要估计的事件发生概率,B是有别于A的事件
P(A|B):后验概率,在B发生的情况下,A发生的概率
P(A):先验概率,A事件发生的概率
P(B):B事件发生的概率
P(B|A):似然(度),A发生时,B发生的概率
解释部分词汇
先验概率:在没有任何新的信息时,根据原先的信息对事件发生概率进行初始估算;
后验概率:获取新的信息后,对初始估算的事件发生概率进行修正得到的概率。
可以这么理解,先验概率是我们对某件事总体发生的概率的预估,这个时候我们是不考虑其他因素的,等到我们需要考虑其他信息(这些考虑的信息在原来是没有的,所以是新添加的)时,我们将考虑这些信息与事件发生的关联,进一步对概率进行修正,就得到了后验概率。
就像有个人去打球,观察他一个月获取他的打球情况,发现他一天打球的概率是50%(这就是他的先验概率),但我们发现仅仅考虑他一天打球的概率,很容易出问题,如果下一周7天下5天雨,而他这一周在没下雨的时候都去打球,概率只有不到30%,所以我们需要考虑天气因素,将天气因素作为新的信息添加到原来的信息中,对原先的概率进行修正,得到在某种情况下发生的概率(后验概率),这个才是比较有用的数据。
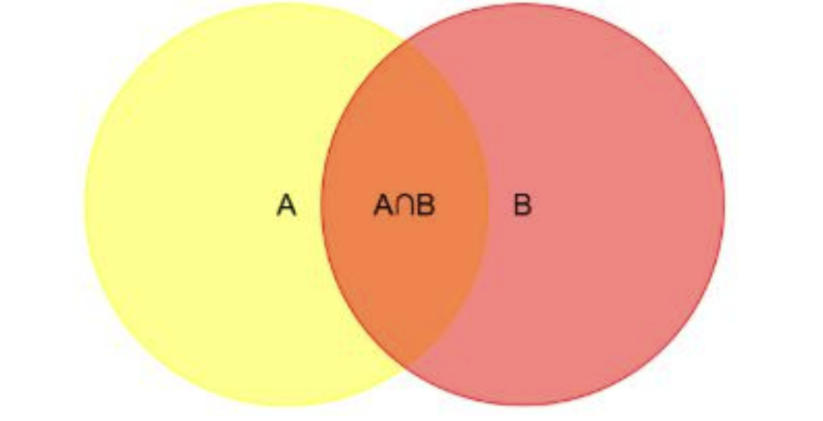
P(A,B)是A∩B的部分,A发生后,B就只能在A中发生,才能满足A、B同时发生的要求,P(B|A)是相对A而言的,所以P(A)*P(B|A)就是A∩B的概率,即P(A,B)的概率。
同理可得P(B)*P(A|B)=P(A,B)。
推导过程:
对上式的理解,为了达到避免只看新的信息,降低整体决策错误率的目的。
朴素贝叶斯分类器
原理
为什么在机器学习中要计算事件发生概率?
在描述一些事件时,我们通常都会使用概率来描述,得了某种病的存活率、明天是晴天的概率等等。前面讲的KNN ,就是一个和概率有关的算法,它根据一个点的周围对这个点直接预测,得到的是一个大概率的结果。同样,在朴素贝叶斯分类器中,我们需要概率来预测事件,以此达到分类的目的。
为什么朴素贝叶斯分类器有个“朴素”前缀?
如果严格按照原来的贝叶斯公式计算,遇到事件不相互独立的情况时,我们需要计算很多个事件共同发生的概率和在我们要预测的事件的前提下共同发生的概率,计算量比较大,但是我们默认事件是相互独立的,计算量就小很多了。这个朴素就是假设事件相互独立,减小计算量。
公式说明
nb是naive bayes的缩写,就是朴素贝叶斯的意思;argmax是取最大值,从右边的一整串乘法式子中取出最大的后验概率;Π这种符号就是累乘的意思,从第一个特征累乘到d;P()就是概率;X表示x1,x2,...,xn,就是这些事件共同发生的概率。
我们最终认为,后验概率最大的事件就是会发生的事件,即A发生的概率为0.014,B发生的概率为0.025,我们认为B发生,A和B是待分类的两个类别。
MAP准则
MAP准则(Maximun A Posteriori),最大后验概率。朴素贝叶斯的公式想要达到分类出最接近标签的结果,需要降低误分类的期望,我们通过最大化后验概率来最小化误分类期望,这就是MAP准则的核心思想。具体做法就是,选择出最大的后验概率对应的类别(标签)作为预测的结果。
其他与贝叶斯公式不同的地方
相比贝叶斯公式,这个公式是没有除以P(x)的,原因是最终比较时,都是除以P(x)的,也就是有没有使用到这个数据处理,结果不会变,所以我们不需要特地在进行除法运算,减少计算量。
拉普拉斯修正
为什么需要这个修正?
朴素贝叶斯分类器计算后验概率时进行了累乘,如果里面出现了零,整个结果就会为零,其他因素就相当于是没有在考虑范围内。
这种情况是会出现的,当某个类别中的离散特征没有出现所有类别时,空缺的类别概率就会计算出0,当我们使用这个标记为0的特征对应的类别时,只有训练集上的样本能被正确分类,而训练集以外的样本在这一类别下计算出来的一定是0,和别的概率比较下来,一定不会被选中。
就好比当前所有男生都是短发,你也认为只有短发的是男生,突然来了个长发的男生,因为长发的不可能是男生,所以长发的男生就一定会被分错性别。我们不难发现,这种情况会导致过拟合。
公式说明
D就是数据集;c是类别(标签);Dc是有c类别的数据集;N是这个特征(标签)的所有类别;
Dc,xi是第i个特征的c类别的数据集;Ni是第i个特征的所有类别
拉普拉斯修正需要给每个概率都加上,没有为0的概率。
防溢出处理
在进行乘法运算时,难免会遇到数值很小的两个数相乘,无论是C++还是Python,当数据小于可以表示的精度时,数据将被设置为0。为了防止这种情况发生,我们使用对数运算来解决。
公式:
这个公式就比较常见了,不做解释了。由于ln可以把数据从比较小的映射到比较大的数据,防溢出使用比较合适。
概率的获取
离散特征
直接求出占比即可,例如,当前数据集,正的特征A有a(10个)、b(12个)两个类别,负的特征A有a(7个)、b(4个)两个类别,按顺序求得正Aa(10/22)、正Ab(12/22)、负Aa(7/11)、负Ab(4/11)
公式:
连续特征
使用概率密度公式,要对当前的数据集中连续特征的所有值求均值、方差和标准差
公式:
这里的sigma_c,i是标准差、mu_c,i是均值,整个就是一个正态分布公式;xi是测试集传入的连续特征对应的值
案例分析
预测西瓜是不是好瓜
训练集:
色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜
青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.460,是
乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.774,0.376,是
乌黑,蜷缩,浊响,清晰,凹陷,硬滑,0.634,0.264,是
青绿,蜷缩,沉闷,清晰,凹陷,硬滑,0.608,0.318,是
浅白,蜷缩,浊响,清晰,凹陷,硬滑,0.556,0.215,是
青绿,稍蜷,浊响,清晰,稍凹,软粘,0.403,0.237,是
乌黑,稍蜷,浊响,稍糊,稍凹,软粘,0.481,0.149,是
乌黑,稍蜷,浊响,清晰,稍凹,硬滑,0.437,0.211,是
乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,0.666,0.091,否
青绿,硬挺,清脆,清晰,平坦,软粘,0.243,0.267,否
浅白,硬挺,清脆,模糊,平坦,硬滑,0.245,0.057,否
浅白,蜷缩,浊响,模糊,平坦,软粘,0.343,0.099,否
青绿,稍蜷,浊响,稍糊,凹陷,硬滑,0.639,0.161,否
浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,0.657,0.198,否
乌黑,稍蜷,浊响,清晰,稍凹,软粘,0.360,0.370,否
浅白,蜷缩,浊响,模糊,平坦,硬滑,0.593,0.042,否
青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,0.719,0.103,否测试集:
色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜
青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.460,这些特征的类别都是字符串,我们需要对其进行编码,但是这个不是重点,小编生成了一份只有数字的训练集和测试集,如果需要在转化回原来的字符串,可以参考上面的数据自己写一份
训练集:
0,0,0,0,0,0,0.697,0.460,0
1,0,1,0,0,0,0.774,0.376,0
1,0,0,0,0,0,0.634,0.264,0
0,0,1,0,0,0,0.608,0.318,0
2,0,0,0,0,0,0.556,0.215,0
0,1,0,0,1,1,0.403,0.237,0
1,1,0,1,1,1,0.481,0.149,0
1,1,0,0,1,0,0.437,0.211,0
1,1,1,1,1,0,0.666,0.091,1
0,2,2,0,2,1,0.243,0.267,1
2,2,2,2,2,0,0.245,0.057,1
2,0,0,2,2,1,0.343,0.099,1
0,1,0,1,0,0,0.639,0.161,1
2,1,1,1,0,0,0.657,0.198,1
1,1,0,0,1,1,0.360,0.370,1
2,0,0,2,2,0,0.593,0.042,1
0,0,1,1,1,0,0.719,0.103,1
测试集:
0,0,0,0,0,0,0.697,0.460,
这个测试集是没有标签的、样本数量少,所以我们没办法评估模型,我也省去了,这里读者自行实现,也可参考前几篇博客的模型评估实现。
这里小编在文本结尾留了个逗号在测试集里面,如果想要实现难度下降,可以手动删除这个逗号。
我们只需要导入数据,把数据整理成一张概率表,如下图展示的:
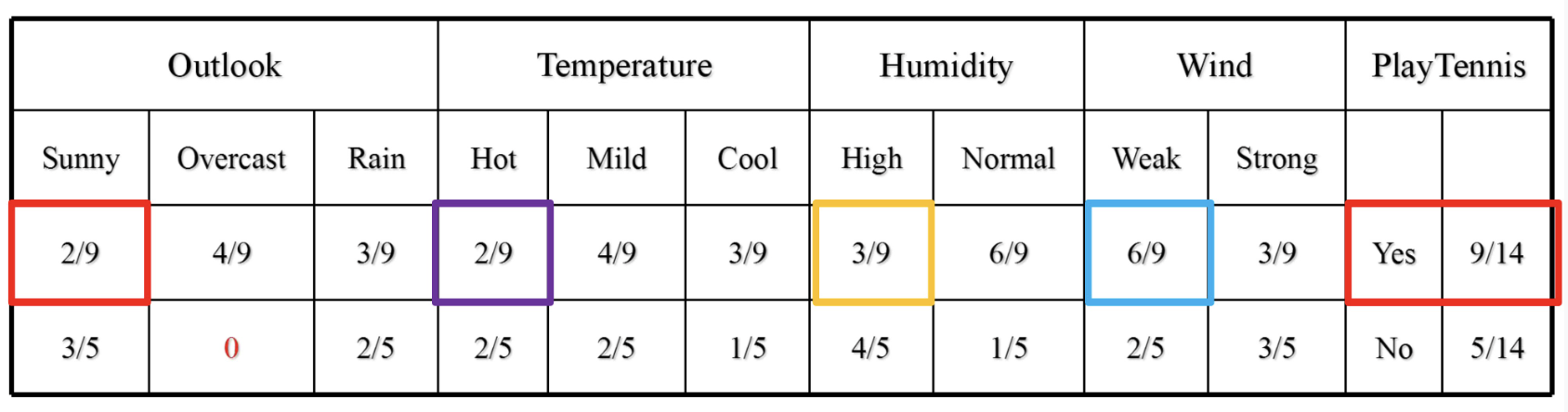
当然,是用特定的数据结构存(C++要自己建,Python使用numpy管理)
最后到对应的框中获取概率累乘就能算出多个标签的概率,根据MAP准则选择最大的,认为是这个样本的标签。
C++实现
结构体
// 存数据样本的
struct Data
{
vector<int> disperse;
vector<double> continuous;
int tag;
};
// 存连续特征的
struct ContinuousStats
{
double mean; // 平均值
double variance; // 方差
double deviation; // 标准差
};
统计连续特征的函数
ContinuousStats stats(std::vector<double>& values)
{
Assert(!values.empty(), "stats: values is empty!");
double avg = accumulate(values.begin(), values.end(), 0.0) / values.size();
double sum = 0.0;
for (double value : values)
{
double gap = value - avg;
sum += gap * gap;
}
double variance = sum / values.size();
double deviation = sqrt(variance);
return {avg, variance, deviation};
}这些实现没什么好讲的,遍历特征列,计算均值、方差和标准差。
生成概率表
pair<
unordered_map<int, double>,
pair<
vector<vector<unordered_map<int, double>>>,
vector<vector<ContinuousStats>>
>
> compressData(vector<Data>& data)
{
Assert(!data.empty(), "compressData: data is empty");
vector<vector<unordered_map<int, double>>> ds_list;
vector<vector<ContinuousStats>> ct_list;
auto transformation = transform(data);
vector<vector<int>> ds_tf(transformation.first.begin(), transformation.first.end() - 1);
vector<int> tag_tf(*(transformation.first.end() - 1));
vector<vector<double>> ct_tf = transformation.second;
double total = data.size();
int ds_num = data[0].disperse.size();
int ct_num = data[0].continuous.size();
unordered_map<int, int> group_data;
for (int tag : tag_tf)
group_data[tag]++;
ds_list.resize(group_data.size());
ct_list.resize(group_data.size());
vector<int> ds_vocab;
ds_vocab.reserve(ds_num);
for (auto& ds : ds_tf)
ds_vocab.push_back(unique(ds).size());
unordered_map<int, double> prior_prob;
prior_prob.reserve(group_data.size());
int tag_pos = 0;
for (const auto& d : group_data)
{
// 计算先验概率
#ifndef RAW
prior_prob[d.first] = log(d.second / total);
#else
prior_prob[d.first] = d.second / total;
#endif
// 计算离散特征的概率
cout << "离散特征:" << endl;
vector<unordered_map<int, double>> ds_prob;
ds_prob.reserve(ds_num);
for (int i = 0; i < ds_num; ++i)
{
auto ds = ds_tf[i];
int vocab = ds_vocab[i];
unordered_map<int, double> feature_prob;
for (int j = 0; j < total; ++j)
{
if(d.first == tag_tf[j])
feature_prob[ds[j]]++;
}
for (auto& port : feature_prob)
{
port.second = (port.second + 1) / (d.second + vocab);
#ifndef RAW
port.second = log(port.second);
#endif
cout << port.second << " ";
}
cout << endl;
ds_prob.push_back(feature_prob);
}
ds_list[tag_pos] = move(ds_prob);
// 计算连续特征的概率密度
cout << "连续特征:" << endl;
vector<ContinuousStats> feature_density;
feature_density.reserve(ct_num);
for (auto& ct : ct_tf)
{
vector<double> sub;
for (int j = 0; j < total; ++j)
{
if (d.first == tag_tf[j])
sub.push_back(ct[j]);
}
feature_density.push_back(stats(sub));
}
for (auto& feature : feature_density)
cout << feature.mean << " " << feature.variance << " " << feature.deviation << endl;
ct_list[tag_pos] = move(feature_density);
tag_pos++;
}
return make_pair(prior_prob, make_pair(ds_list, ct_list));
}这里的RAW的预处理语句是为了查看防溢处效果的,定义RAW是不防溢出,不定义是放溢出。
转置方便计算,小编认为
先分标签的类别,最终存到要返回的数据中使用unordered_map区分,可以保证正确取到我们需要的标签类别。遍历每个特征(分离散和连续两个部分),因为数据集的样本数量就是计算概率的被除数,所以我们直接用d.second。
在离散特征计算中,需要提前统计特征类别数量,参与拉普拉斯计算
在连续特征计算中,需要获取一整列的数据,传入stats中统计,生成ContinuousStats变量。
预测函数
int bayes(unordered_map<int, double> prior_prob,
vector<vector<unordered_map<int, double>>> ds_list,
vector<vector<ContinuousStats>> ct_list, Data test)
{
double max = -1e18;
int label = -1;
for (const auto& port : prior_prob)
{
double val = port.second;
#ifndef RAW
for (int i = 0; i < test.disperse.size(); ++i)
val += ds_list[port.first][i][test.disperse[i]];
for (int i = 0; i < test.continuous.size(); ++i)
val += prob_density(ct_list[port.first][i], test.continuous[i]);
#else
for (int i = 0; i < test.disperse.size(); ++i)
val *= ds_list[port.first][i][test.disperse[i]];
for (int i = 0; i < test.continuous.size(); ++i)
val *= prob_density(ct_list[port.first][i], test.continuous[i]);
#endif
cout << val << endl;
if (max < val)
{
max = val;
label = port.first;
}
}
return label;
}遍历概率表,获取对应的特征类别的概率,或者当场计算,如果使用了防溢出处理,累加这些概率,否则需要累乘。然后通过一个简单的打擂台,选出最合适的标签。
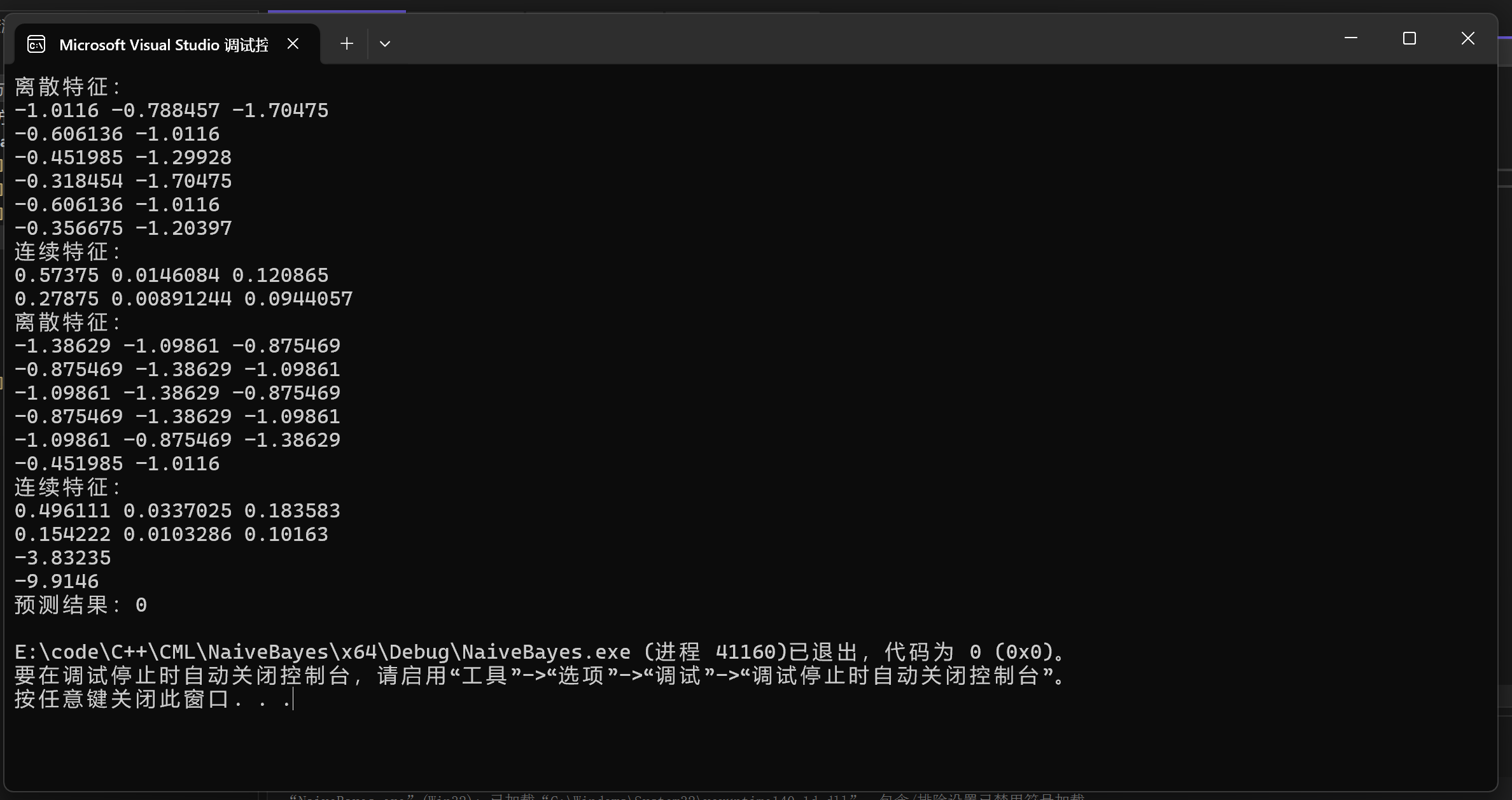
结果展示
只展示防溢出处理的
Python实现
类
class ContinuousStats:
def __init__(self, mean = 0.0, variance = 0.0, deviation = 0.0):
self.mean = mean
self.variance = variance
self.deviation = deviation统计连续特征的函数
def stats(values: list) -> ContinuousStats | None:
if values is None:
return None
avg = float(np.mean(values))
cnt = 0.0
for val in values:
gap = val-avg
cnt += gap*gap
variance = cnt / len(values)
deviation = variance**0.5
return ContinuousStats(avg, variance, deviation)生成概率表
def get_prob_cnt(data: np.ndarray, preserve: bool = False) -> (dict, dict, dict):
ds_list = {}
ct_list = {}
# 分离离散特征和连续特征
transform_data = data.T
disperse = []
continuous = []
tag_t = transform_data[-1]
for feature in transform_data[:-1]:
flag = 0
for f in feature:
if f != int(f):
flag = 1
break
if flag:
continuous.append(feature)
else:
disperse.append(feature)
# 计算拉普拉斯修正需要的同一特征的所有类型
ds_vocab = []
for ds_feature in disperse:
vocab = len(np.unique(ds_feature))
ds_vocab.append(vocab)
# 计算先验概率
total = float(len(data))
tag_list, tag_num = np.unique(data[:,-1], return_counts=True)
tag_num = tag_num.astype(float)
prior_prob = {}
for tag, num in zip(tag_list, tag_num):
prior_prob[tag] = num / total if not preserve else np.log(num / total)
for (tag, num) in zip(tag_list, tag_num):
# 计算离散特征概率
ds_prob = []
for i in range(len(disperse)):
ds_feature = disperse[i]
vocab = np.unique(ds_feature)
feature_cnt = {x:1.0 for x in vocab}
for j in range(len(tag_t)):
if tag_t[j] == tag:
feature_cnt[ds_feature[j]] += 1.0
for (key, value) in feature_cnt.items():
prob = value/(num+ds_vocab[i])
feature_cnt[key] = prob if not preserve else np.log(prob)
ds_prob.append(feature_cnt)
ds_list[tag] = ds_prob
# 计算连续特征概率密度
ct_prob_dense = []
for ct_feature in continuous:
mask = (tag == tag_t)
sub_ct = ct_feature[mask]
ct_prob_dense.append(stats(sub_ct))
ct_list[tag] = ct_prob_dense
return prior_prob, ds_list, ct_list思路和C++实现差不多,这里不讲了,讲一下第一个双重for循环,
这是因为可能存在离散特征和连续特征分布比较分散,我们需要划分开来,才方便后续处理
预测函数
def bayes_classifier(prior_prob: dict, ds_list: dict, ct_list: dict, test: np.ndarray, preserve: bool = False) -> int:
disperse = []
continuous = []
for t in test:
if t != int(t):
continuous.append(t)
else:
disperse.append(t)
max_label = -1
max_value = -1e18
for tag, prob in prior_prob.items():
val = prob
if preserve:
for i in range(len(disperse)):
val += ds_list[tag][i][disperse[i]]
for i in range(len(continuous)):
val += prob_density(ct_list[tag][i], continuous[i], preserve)
else:
for i in range(len(disperse)):
val *= ds_list[tag][i][disperse[i]]
for i in range(len(continuous)):
val *= prob_density(ct_list[tag][i], continuous[i], preserve)
print(f"类别{tag:.0f}的概率:{val}")
if max_value < val:
max_value = val
max_label = tag
return max_label
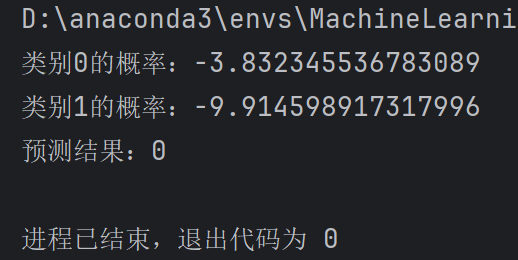
测试结果

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)