【机器学习】线性回归:原理、求解与模型评估
线性回归是机器学习中最基础、最常用的算法之一,属于监督学习的回归任务范畴,也是入门机器学习的首选知识点。它原理简单、可解释性极强,广泛应用于数据分析、预测建模等场景,无论是初学者还是资深开发者,都需要熟练掌握其核心逻辑与实战技巧。本文将从线性回归简介、问题求解、模型评估三个维度,结合代码实战,帮你彻底吃透线性回归。
一、线性回归简介
1.1 线性回归的定义
线性回归(Linear Regression)本质上是一种预测性建模技术,它假设自变量(特征)与因变量(目标值)之间存在线性关系,通过构建线性方程来拟合数据分布,最终实现对未知数据的预测。
从数学角度来看,若存在n个自变量(特征)x1,x2...xn,1个因变量y,线性回归的数学表达式可表示为:
![]()
其中:
-
θ0是截距项(偏置),表示所有特征为0时,因变量的基准值;
-
θ1,θ2...θn 是特征系数(权重),表示每个自变量对因变量的影响程度(正系数表示正向影响,负系数表示负向影响);
-
ε是随机误差项,代表模型无法拟合的随机因素(如测量误差、未考虑到的微小特征等),通常假设其服从均值为0、方差为常数的正态分布。
线性回归的核心目标,就是找到一组最优的权重θ(包含θ0),使得模型预测值与真实值之间的误差最小。
1.2 线性回归的分类
根据自变量的数量和模型形式,线性回归主要分为两类,覆盖不同的应用场景:
(1)单变量线性回归(Simple Linear Regression)
又称一元线性回归,仅包含1个自变量和1个因变量,模型形式简化为:![]()
特点:原理最简单、可视化效果好(可通过二维平面拟合直线),适合分析两个变量之间的线性关联,比如“房屋面积与房价”“学习时长与考试分数”。
(2)多变量线性回归(Multiple Linear Regression)
包含2个及以上自变量,是实际应用中最常用的形式。比如预测房价时,除了房屋面积,还会考虑户型、楼层、地段、房龄等多个特征,此时就需要用到多变量线性回归。
补充:若自变量与因变量之间的关系是非线性的,但可通过变量转换转化为线性关系(如![]() ),又称为“广义线性回归”,本质上仍属于线性回归的范畴。
),又称为“广义线性回归”,本质上仍属于线性回归的范畴。
1.3 线性回归的应用场景
线性回归因可解释性强、计算高效,广泛应用于各行各业的预测任务,典型场景包括:
-
数据分析与趋势预测:如销售额预测、客流量预测、GDP增速预测,通过历史数据拟合线性模型,预测未来趋势;
-
量化分析:如股票价格预测(结合成交量、市盈率等特征)、基金收益率预测;
-
工程与科学计算:如传感器误差校正、实验数据拟合、物理量预测(如温度与压强的关系);
-
业务场景:如用户消费金额预测(结合用户年龄、消费频次、客单价等)、员工绩效预测(结合工作年限、学历、考勤等)。
注意:线性回归仅适用于“自变量与因变量存在线性关系”的场景,若两者为非线性关系(如二次曲线、指数关系),则需要使用多项式回归、决策树等其他算法。
二、线性回归问题的求解
线性回归的求解核心,是找到“最优权重θ,使得模型预测值与真实值的误差最小。这一过程分为三个关键步骤:调用线性回归API、定义损失函数(衡量误差)、使用优化算法求解最优权重。下面结合Python实战(sklearn库),逐一讲解。
2.1 线性回归API实战(Python sklearn)
在实际开发中,我们无需手动实现线性回归的求解过程,sklearn库提供了成熟的LinearRegression API,可快速完成模型的训练与预测。先看基础实战代码,后续结合原理拆解:
# 导入必要库
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 1. 构造模拟数据(单变量线性回归:x=房屋面积,y=房价)
x = np.array([[50], [60], [70], [80], [90], [100]]) # 自变量(二维数组,sklearn要求输入为2D)
y = np.array([150, 180, 210, 240, 270, 300]) # 因变量(房价,单位:万元)
# 2. 划分训练集与测试集(80%训练,20%测试)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 3. 初始化并训练线性回归模型
model = LinearRegression()
model.fit(x_train, y_train) # 训练模型,本质是求解最优权重theta
# 4. 查看模型参数(截距theta0和系数theta1)
print("截距 theta0:", model.intercept_)
print("系数 theta1:", model.coef_[0])
# 5. 模型预测
y_pred = model.predict(x_test)
print("测试集预测值:", y_pred)
print("测试集真实值:", y_test)运行上述代码,会得到模型的截距和系数,这两个参数就是我们要求解的最优权重。接下来,我们将讲解“模型如何求解这两个参数”——核心是先定义“误差衡量标准(损失函数)”,再通过优化算法最小化损失函数。
2.2 损失函数:衡量模型误差的标准
损失函数(Loss Function)是用来衡量“模型预测值与真实值之间差异”的函数,线性回归中最常用的是平方损失函数(Sum of Squared Errors, SSE),也称为残差平方和。
假设我们有m个样本,第i个样本的自变量为xi,真实值为yi,模型预测值为![]() (单变量场景),则平方损失函数定义为:
(单变量场景),则平方损失函数定义为:
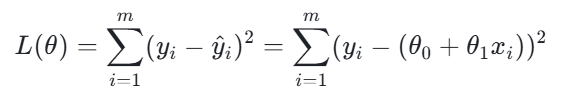
补充:在实际应用中,为了方便后续求导(优化算法),会将损失函数除以2m,得到均方误差损失(MSE)的一半,即:
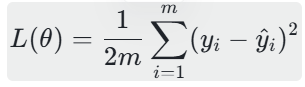
损失函数的核心意义:损失函数的值越小,说明模型拟合效果越好。因此,线性回归的求解问题,本质上就是“寻找一组权重θ,使得损失函数L(θ)取得最小值”。
2.3 最优权重的求解方法
求解“最小化损失函数的最优权重θ,主要有两种方法:正规方程法(解析解)和梯度下降算法(数值解)。两种方法各有优劣,适用于不同的场景。
(1)正规方程法(Normal Equation)
正规方程法是通过数学解析的方式,直接求解损失函数最小值对应的权重θ,无需迭代,一步到位。其核心思路是:对损失函数L(θ)求关于θ偏导数,令偏导数等于0,解出θ的解析表达式。
为了方便计算,我们将样本数据用矩阵形式表示(多变量场景通用):
-
样本矩阵X:m行(n+1)列,其中第一列全为1(对应截距θ0的系数),即X =

-
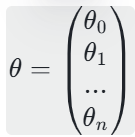
权重矩阵θ:(n+1)行1列,θ =
-
-
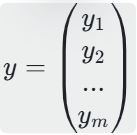
真实值矩阵y:m行1列,y =
-
此时,模型预测值y=xθ ,损失函数的矩阵形式为: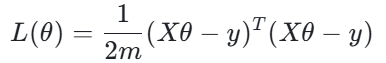
对求偏导数并令其等于0,可解得最优权重
的解析表达式:
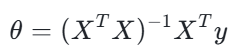
具体推导如下

优缺点分析:
-
优点:无需迭代,直接得到最优解;计算过程简单(矩阵运算),适合小规模数据(样本量m小、特征数n小)。
-
缺点:需要计算(X^TX)的逆矩阵,当特征数n较大(如n>10000)时,矩阵逆运算的时间复杂度极高(O(n^3)),计算效率极低;且当(X^TX)不可逆时(如特征之间存在多重共线性),无法求解。
注意:sklearn中的LinearRegression API,底层默认使用正规方程法求解(当特征数较小时),当特征数较大时,会自动切换为梯度下降算法。
(2)梯度下降算法(Gradient Descent)
梯度下降算法是一种迭代优化算法,核心思路是:沿着损失函数的“梯度负方向”(即损失函数下降最快的方向),逐步迭代更新权重θ,直到损失函数收敛到最小值(或接近最小值)。
举例:坡度最陡下山法
-
输入:初始化位置S;每步距离为a 。输出:从位置S到达山底
-
步骤1:令初始化位置为山的任意位置S
-
步骤2:在当前位置环顾四周,如果四周都比S高返回S;否则执行步骤3
-
步骤3: 在当前位置环顾四周,寻找坡度最陡的方向,令其为x方向
-
步骤4:沿着x方向往下走,长度为a,到达新的位置S‘
-
步骤5:在S‘位置环顾四周,如果四周都比S‘高,则返回S‘。否则转到步骤3
小结:通过循环迭代的方法不断更新位置S (相当于不断更新权重参数w)

梯度下降的核心步骤(以单变量线性回归为例):
-
初始化权重θ0和θ1(通常为随机值或0);
-
计算损失函数关于θ0和θ1的偏导数(梯度):
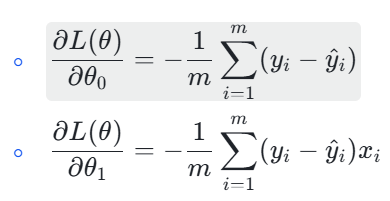
-
根据梯度更新权重(学习率
控制迭代步长):
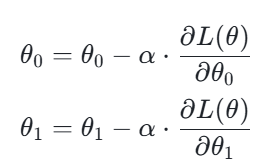
-
重复步骤2和步骤3,直到损失函数的值收敛(变化量小于预设阈值)或达到最大迭代次数。
关键参数说明:
-
学习率
-
迭代次数:预设的最大迭代次数,防止模型陷入无限迭代(即使未收敛,也会停止训练)。
优缺点分析:
-
优点:无需计算矩阵逆,时间复杂度低(O(mn)),适合大规模数据(样本量m大、特征数n大);适用性广,可用于其他复杂模型(如逻辑回归、神经网络)的优化。
-
缺点:需要手动调参(学习率、迭代次数);需要迭代多次才能收敛,训练时间可能较长;对特征缩放敏感(如不同特征的量级差异大,会影响收敛速度),通常需要先对特征进行标准化/归一化处理。
三、模型评估指标:MAE、MSE、RMSE
训练完线性回归模型后,我们需要通过评估指标来判断模型的拟合效果——评估指标本质是“更规范的误差衡量标准”,比单纯的损失函数更适合用于模型对比和效果判断。常用的评估指标有三个:MAE(平均绝对误差)、MSE(均方误差)、RMSE(均方根误差),下面逐一讲解其定义、计算方式和含义。
3.1 MAE(Mean Absolute Error,平均绝对误差)
(1)定义与计算公式
MAE是所有样本“预测值与真实值的绝对误差”的平均值,计算公式为:
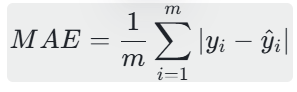
其中,m为样本数量,yi为第i个样本的真实值,![]() 为第i个样本的预测值。
为第i个样本的预测值。
(2)核心含义与特点
-
含义:MAE越小,说明模型的预测值与真实值的平均偏差越小,模型拟合效果越好。
-
特点:
-
对异常值不敏感(因为使用绝对误差,不会放大异常值的影响);
-
计算简单、直观,单位与因变量一致(如预测房价时,MAE的单位是“万元”);
-
缺点:绝对函数在
 处不可导,无法用于梯度下降等需要求导的优化算法(因此仅用于评估,不用于训练)。
处不可导,无法用于梯度下降等需要求导的优化算法(因此仅用于评估,不用于训练)。
-
3.2 MSE(Mean Squared Error,均方误差)
(1)定义与计算公式
MSE是所有样本“预测值与真实值的平方误差”的平均值,也是线性回归训练时最常用的损失函数(缩放后),计算公式为:
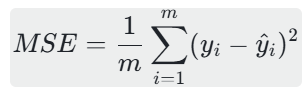
(2)核心含义与特点
-
含义:MSE越小,模型拟合效果越好,其值反映了预测值与真实值的平均平方偏差。
-
特点:
-
对异常值敏感(平方项会放大异常值的误差,比如一个偏差较大的样本,会显著拉高MSE的值);
-
可导,适合用于梯度下降等优化算法(因此既用于训练,也用于评估);
-
缺点:单位是因变量单位的平方(如预测房价时,MSE的单位是“万元²”),不够直观。
-
3.3 RMSE(Root Mean Squared Error,均方根误差)
(1)定义与计算公式
RMSE是MSE的平方根,本质是对MSE的“单位修正”,计算公式为:
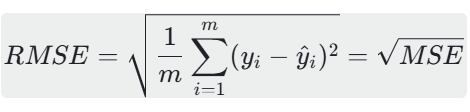
(2)核心含义与特点
-
含义:RMSE越小,模型拟合效果越好,其值反映了预测值与真实值的平均偏差,与MAE类似,但对异常值更敏感。
-
特点:
-
对异常值敏感(继承了MSE的特点);
-
单位与因变量一致(修正了MSE的缺点),直观易懂(如预测房价时,RMSE的单位是“万元”,可直接理解为“平均预测偏差多少万元”);
-
是实际应用中最常用的线性回归评估指标(兼顾了可导性和直观性)。
-
3.4 三个指标的对比与实战应用
为了方便大家快速区分和使用,整理了三个指标的核心对比表格:
|
评估指标 |
计算公式 |
对异常值敏感性 |
单位 |
适用场景 |
|---|---|---|---|---|
|
MAE |
|
不敏感 |
与因变量一致 |
数据存在异常值,需直观反映平均偏差 |
|
MSE |
|
敏感 |
因变量单位的平方 |
模型训练(梯度下降),侧重惩罚异常值 |
|
RMSE |
|
敏感 |
与因变量一致 |
模型评估(首选),兼顾直观性和异常值惩罚 |
实战代码(计算三个评估指标):
from sklearn.metrics import mean_absolute_error, mean_squared_error
# 沿用上面的训练数据和预测结果(y_test为真实值,y_pred为预测值)
# 计算MAE
mae = mean_absolute_error(y_test, y_pred)
# 计算MSE
mse = mean_squared_error(y_test, y_pred)
# 计算RMSE
rmse = np.sqrt(mse)
print("MAE(平均绝对误差):", mae)
print("MSE(均方误差):", mse)
print("RMSE(均方根误差):", rmse)四、总结与拓展
本文从线性回归的基础概念出发,详细讲解了线性回归的定义、分类、应用场景,深入剖析了模型求解的核心(损失函数、正规方程法、梯度下降算法),并介绍了常用的模型评估指标(MAE、MSE、RMSE),结合Python sklearn实战代码,帮助大家快速掌握线性回归的核心知识点。
拓展说明:
-
线性回归的前提假设:自变量与因变量存在线性关系、误差项服从正态分布、误差项方差恒定( homoscedasticity )、特征之间无多重共线性;
-
若特征之间存在多重共线性,可使用岭回归(Ridge Regression)、Lasso回归等正则化方法解决;
-
若自变量与因变量为非线性关系,可使用多项式回归(将特征转换为二次、三次项),本质上仍属于线性回归的拓展。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 25
25 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)