具身智能数据荒的技术拆解:三大路线与工程瓶颈
全球真机数据仅 50 万小时,缺口 99% — 数据基建正处于范式切换的前夜
1 数据荒的定量描述
Epoch AI 研究显示全球高质量文本训练数据约 1.67ZB,按当前消耗速度 2028 年前后将耗尽。但具身智能面临的数据荒更严峻:互联网上不存在可直接映射到机器人控制链路的"多模态指令-动作"数据,行业需从零建设物理世界数据管道。
据佐思汽研《2026 年具身智能数据报告》,全球高质量真机操作数据约 50 万小时,而训练通用具身模型需千万小时级,缺口超 99%。赛迪智库数据显示,单台遥操作设备产出 1 万小时真机数据需投入上百万元,单人日有效采集量仅 300-500 条。在头部 AI 公司训练总成本中,数据采集、清洗、标注环节已占 60% 以上,超越算力成为最贵的原材料。全球研发端数据需求约 120 万小时,但全行业月产能仅 25-30 万小时(科技日报 2026 年 5 月),供需结构性失衡持续加剧。

2 数据采集架构与技术路线对比
当前业内三条技术路线并行推进,在效率、成本与质量维度上各有取舍,共同构成"采集-预处理-融合-闭环"的工程架构:
数据采集架构流程:
真机遥操作 ──┐ ┌─ 混合训练池 ─┐
无本体采集 ──┼── 预处理层 ───────┤ ├── 模型迭代闭环
仿真生成 ──┘ 清洗·标注·格式转 └─ 训-评-测 ─┘ (反哺采集策略)
|
对比维度 |
真机遥操作 |
无本体采集(UMI) |
仿真生成 |
|
单小时成本 |
500-1000 元 |
100-200 元 |
约 50 元/万帧 |
|
人均日产出 |
300-500 条 |
800-1500 条 |
无限(算力受限) |
|
数据质量 |
高(精标注) |
中高(含失败轨迹) |
中(Sim-to-Real 偏差) |
|
跨本体复用 |
低(本体绑定) |
高(动作解耦) |
中(需域适配) |
|
场景覆盖 |
受限 |
灵活 |
极广 |
|
规模化瓶颈 |
本体产能+人力 |
标注自动化精度 |
Sim-to-Real Gap |
三条路线并非替代关系,而是互补拼图。真机数据提供最高质量的行为锚点,仿真数据负责穷举长尾场景,无本体采集则以较低成本填补跨本体的数据缺口——三者融合才能逼近数据完整性的上限。
3 关键瓶颈与破局变量
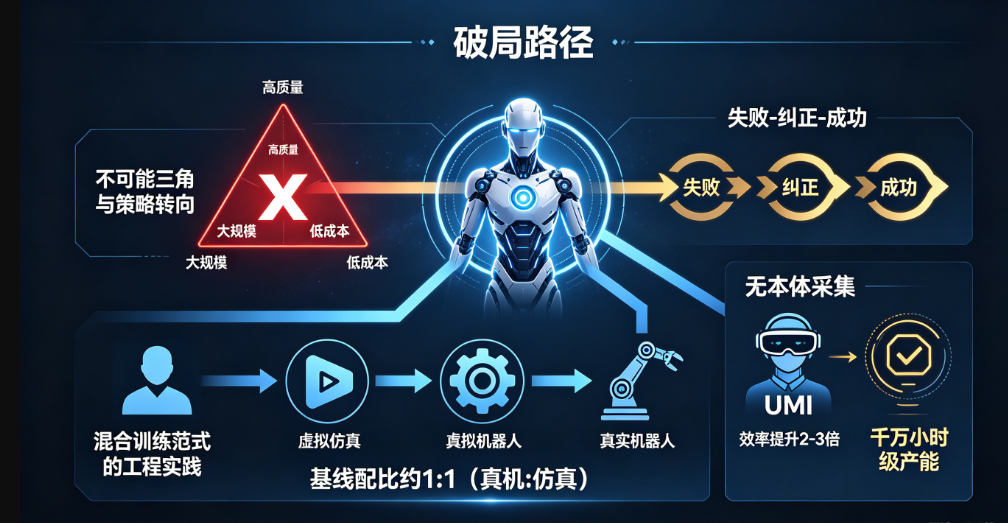
3.1 不可能三角与策略转向
北京人形机器人创新中心孔超指出,具身智能数据存在"高质量、大规模、低成本"不可能三角。一个关键认知转变正在发生:包含"失败-纠正-成功"阶段的非完美数据训练价值更高。标注策略应从追求"精确率"转向保留"多样性",尤其在高维动作空间中。
3.2 混合训练范式的工程实践
行业共识的混合策略:人类视频提供行为先验,仿真数据做规模化预训练和长尾覆盖,真机数据做最终场景对齐。据库帕思语料总监邓思文(财联社 2026 年 4 月),基线配比约 1:1(真机:仿真),具体比例需根据目标场景的 Sim-to-Real 难度动态调整。
3.3 无本体采集:最接近规模拐点的变量
UMI/ 范式的采集效率是真机遥操作的 2-3 倍,天然支持跨本体复用——意味着采集数据不再被单一硬件平台绑定。数创星光计划两年完成 1000 万小时视频数据采集;觅蜂科技 2026 年目标千万小时级产能,其中 60%-70% 来自无本体路线。如果标注自动化精度在年内达到实用水平,这条路线可能是最先突破数量级瓶颈的方向。
4 FAQ
Q: 仿真数据能完全替代真机数据吗?
不能。Sim-to-Real 迁移偏差是根本制约——物理引擎无法完全还原真实世界的摩擦力、形变与接触动力学。混合训练各司其职才是最优解。
Q: 数据荒何时出现实质性缓解?
短期不会。2026 年全球真机数据有望突破 200 万小时,距千万小时门槛仍有量级差距。拐点取决于无本体标注自动化精度和仿真迁移精度突破。
Q: 企业应对数据荒应优先布局什么?
短期接入成熟仿真平台降低初始门槛;中期自建无本体产线积累跨本体数据资产;长期构建"采-存-标-训-评-仿-测"全链路闭环。数据工程能力本身正成为核心壁垒。
数据来源
Epoch AI, "Will We Run Out of Data?", 2024
佐思汽研,《2026 年具身智能数据报告》
数智前线/CSDN, 2026.04
科技日报,《深瞳丨数据短缺...》, 2026.05
财联社,《人形机器人场外求解"数据之困"》, 2026.04
赛迪智库,《智能机器人数据产业报告》, 2026

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)