1.55亿 vs 30亿:理想和小鹏,在车端模型这件事上背道而驰

「理想的减法与小鹏的加法」
目录
2026年6月,理想和小鹏同时在推进车端模型的部署。
理想把模型压到1.55亿、跑220帧做几何感知;小鹏把720亿蒸馏到30亿、塞进量产后推送给用户。
1.55亿和30亿,中间差了将近20倍。
车端算力到底应该“尽力用满”,还是“能省则省”?
智能驾驶的模型,应该往大了做、一统天下,还是往小了做、各司其职?
理想和小鹏,在这个月给出了截然不同的答案。
01 理想的答案
先看GeoX。这是理想6月初挂上arXiv的工作,读完的第一个感受是:它把事情做得很"窄",但正是在这种窄里体现出了技术判断。
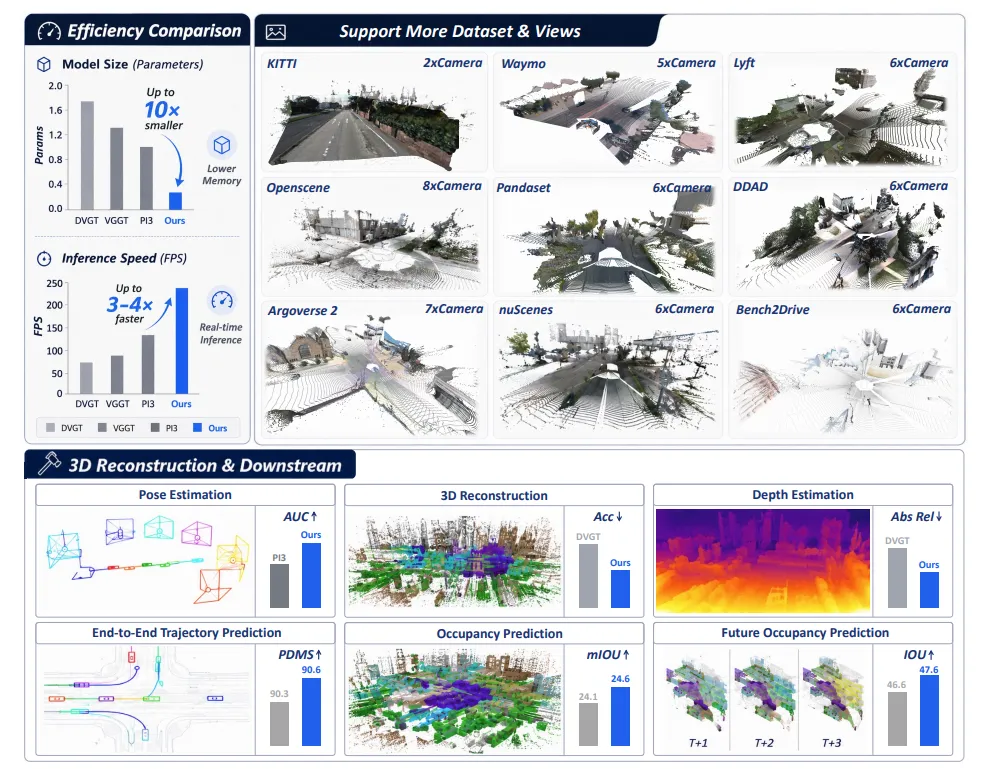
图| LiAuto-GeoX总览
GeoX是底层感知底座。它只做一件事:把稠密3D几何表征搬到车端,跑得够快、够准。
现有视觉几何大模型(VGGT、π3等)参数量动辄10亿级别,推理延迟破百毫秒,只能当离线重建工具。
GeoX的路线是“大模型蒸馏小模型”:先训一个高容量教师,再用两个蒸馏模块——掩码引导深度感知蒸馏(管局部精度)和相对位姿关系蒸馏(管跨视角一致性),把几何能力压缩到1.55亿参数的学生模型里。推理时蒸馏模块被丢弃,零额外开销。
效果上,1.55亿参数、1.75GB显存、KITTI 220 FPS,在DDAD上重建精度超越包括π3在内的所有对比方法。下游任务上:NAVSIM轨迹预测+0.3 PDMS,Occ3D占据预测+0.5% mIoU,增幅小但来源干净(骨干冻结,仅训练轻量规划解码器,增益纯来自几何表征本身质量)。

图| 各类自动驾驶数据集的比较
详细解读:理想最新的工作LiAuto-GeoX,端侧部署的稠密 3D 几何,终于跑起来了!
MindVLA-o1是上层决策大脑。3月GTC发布的原生多模态MoE Transformer架构,统一空间理解、思考推理、驾驶行为三个维度,同一套模型同时控制车辆和机器人。技术亮点包括前馈式3DGS场景表示(动静分离建模)、自监督未来状态预测、System-2显式推理机制、以及隐空间内的场景推演。
参数量至今未公开。理想在这件事上的态度是:上层模型不强调“大小”,强调推理能力和跨智能体复用。
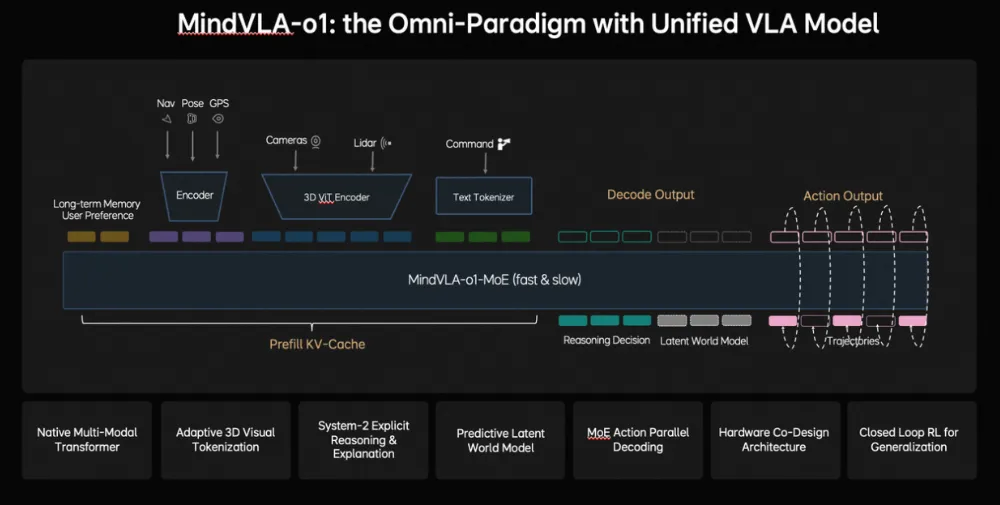
图| MindVLA-o1:具有统一VLA模型的范式
GeoX + MindVLA-o1,这对组合恰好构成了理想对"车端智能"的完整理解:
底层用极高效的小模型做几何感知(看得准),上层用强推理的大模型做决策(想得深)。不是在一个模型里解决所有问题,而是分两层、各有各的评价标准。
02 小鹏的答案
小鹏VLA 2.0走的路完全不同。它本质上是一个单体解决一切的策略:从视觉感知到语言推理到控制指令,全在一个模型框架内端到端完成。小鹏自己管它叫"原生多模态物理世界基座模型"。

云端基座720亿参数(基于阿里云3万卡集群,每5天全链路迭代),蒸馏到车端保留约30亿参数,能力保留率宣称超90%。硬件依赖自研图灵AI芯片,Ultra版三颗共2250 TOPS算力。
何小鹏在2025年科技日上说"搭载数十亿级参数规模的第二代VLA,而行业普遍车端模型参数量仅为千万级规模"。
小鹏的逻辑很清晰:一个模型做所有事,避免模块间的信息损失。30亿参数只是一个起点,芯片预留了足够的扩张空间。
而VLA 2.0不只是停留在论文里。
2026年3月发布后,5月31日起OTA 6.2.0分批推送,6月15日前完成全覆盖。新增“无导航NGP漫游”功能——车辆不需要导航目的地也能自主行驶,从公开道路扩展到园区和地库。推送首月数据显示,智驾里程占比首次突破50%。

VLA 2.0已经开始在真实用户端跑了,而不只是Demo。
而理想这边,GeoX是6月刚挂上arXiv的学术工作,从论文到芯片部署再到OTA推送还有距离。MindVLA-o1在3月GTC发布后,OTA 8.5在5月上线,但核心更新是手机遥控泊车等功能增强,而非MindVLA-o1的架构级上车。
理想现有的量产系统还在端到端+VLM双系统的框架下运行,下一代架构的落地时间尚未公布。
03 两种工程选择的真实差异
把两家的方案放在一起看,本质差异在于对三个问题的不同回答:
第一,车端智能应该分层还是统一?
理想选择分层:感知底座一个模型,决策推理另一个模型。好处是每个模块可以独立优化,GeoX追求极致的效率,MindVLA-o1追求推理深度。代价是需要两套系统协同,级联误差和接口开销不可避免。
小鹏选择统一:一个模型端到端输出。好处是避免了模块间的信息损失,代价是30亿参数的实时推理延迟(小鹏称80ms)和自研芯片的高度绑定。
第二,几何感知要不要单列?
GeoX的做法是把几何感知做成一个独立的、通用的底座,可供轨迹预测、占据预测、未来帧预测等多类下游任务调用。这个思路和CV领域"预训练基础模型+下游微调"的逻辑是一致的。
小鹏VLA 2.0没有单独剥离几何感知模块,而是在端到端框架内隐式地处理所有表征,包括几何理解。
哪种做法更好,目前没有结论。GeoX的下游任务增益确实存在,但+0.3/+0.5%的幅度也让这种"底座可迁移"的叙事显得有些谨慎。
第三,大应该大在云端还是车端?
两家都用了蒸馏,但方向相反。
理想GeoX是从10B级教师蒸馏到155M学生。蒸馏的目的在于压缩,用最小的参数保留最高的几何精度。
小鹏VLA是从720B教师蒸馏到30B学生——蒸馏的目的在于保留(能力保留率90%),让车端小模型尽可能接近云端大模型的上限。
这里需要澄清一个容易混淆的点:小鹏的30亿和理想的参数并不是同一个统计口径。
小鹏30亿是一个统一模型的全部参数;理想的端到端+VLM双系统架构中,VLM部分(约22亿参数)和端到端快系统是分开的,两者并不对应同一个统计维度。
04 芯片决定路线的天花板
两条路线背后还有一场看不见的竞赛:芯片。
小鹏图灵芯片已累计出货超20万片,2026年目标出货量接近100万片。单颗可支持300亿参数大模型本地运行——30亿不是天花板,芯片预留了扩张空间。
理想马赫M100芯片采用5nm车规级工艺,单芯算力1280 TOPS,实际运行效率超82%。搭载双马赫M100的理想L9 Livis整机总算力达2560 TOPS。理想强调的不是“算力大”,而是“同样算力下跑得更高效”——数据流架构让利用率从行业平均的50-60%拉到82%。但具体能跑多大模型,尚未公开。

芯片差异直接影响模型架构选择。小鹏选择往大了做,因为芯片预留了足够的算力空间;理想选择分层做、精度高的部分尽量压缩,可能是基于对车端电力、散热、成本更保守的判断。
一旦芯片能力拉开,模型路线的优劣可能瞬间逆转。
05 路线没有标准答案
“谁更靠谱”不是好的提问方式。
两条路线各有各的假设和成本约束,适用场景不同,判断标准也不同。
理想的减法,赌的是“车端算力永远不够用”:能省则省,把最必要的事情用最小的代价做好。
小鹏的加法,赌的是“算力会越来越便宜”:尽力用满,用一个统一的模型覆盖所有事情。

也有可能,两条路最终会交汇:理想把GeoX的蒸馏方法论用到了MindVLA-o1的压缩上,小鹏在VLA 3.0里开始引入分层架构。
在那一天到来之前,这两家之间没有标准答案,只有不同的赌注。
本期就聊到这里,我们将持续跟踪两家在后续OTA更新、芯片进展、以及实际路测中的对比数据,带来更直观的对比与深度解读。
Ref
- LiAuto-GeoX: Efficient Grounded Driving Transformer. arXiv:2606.05774, 2026.
- 理想汽车MindVLA-o1官方发布,NVIDIA GTC 2026.
- 小鹏汽车OTA 6.2.0升级说明,2026年6月.
- 何小鹏2025小鹏科技日演讲,2025年11月.
- Xiaopeng: https://www.xiaopeng.com/news/company_news/5539.html
- GeoX Project: https://ljwwwiop.github.io/GeoX/

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 2
2 0
0- 0



 已为社区贡献94条内容
已为社区贡献94条内容

所有评论(0)