HumanEgo:基于人类第一人称视角数分钟视频的零样本机器人学习
26年5月来自马里兰大学的论文“ HumanEgo: Zero-Shot Robot Learning from Minutes of Human Egocentric Videos”。
人类的第一人称视角(egocentric)视频无需任何机器人硬件即可捕捉丰富的操作演示,但由于人类与机器人在视觉外观和运动学特性上存在“具身差异”(embodiment gap),将这些技能迁移到机器人身上仍极具挑战。HumanEgo 框架,通过将人类演示转化为“手-物交互”的实体级表征来弥合具身差异,并利用密集的辅助目标训练一种流匹配(flow matching)策略,从而增强来自每条轨迹的监督信号。HumanEgo 具有无需机器人数据、不依赖特定硬件、数据高效以及支持零样本(zero-shot)人机技能迁移等特点。仅需针对每项任务使用 30 分钟的人类视频数据,HumanEgo 就能在四项现实世界任务中实现 92.5% 的平均成功率(仅需 15 分钟数据时成功率为 75%),其性能比同等时长的机器人遥操作高出 41%,并能稳健地实现跨新机器人、新相机视角及新环境的零样本迁移。
如图1 所示HumanEgo 从人类的第一人称视角视频中学习机器人策略。人类佩戴 Aria 眼镜采集演示数据(左);这些第一人称视角视频被转换为以交互为中心的表征,并用于训练流匹配(flow matching)策略(中);该策略可零样本(zero-shot)迁移至机器人,且不受环境、设置或具体形态的限制(右)。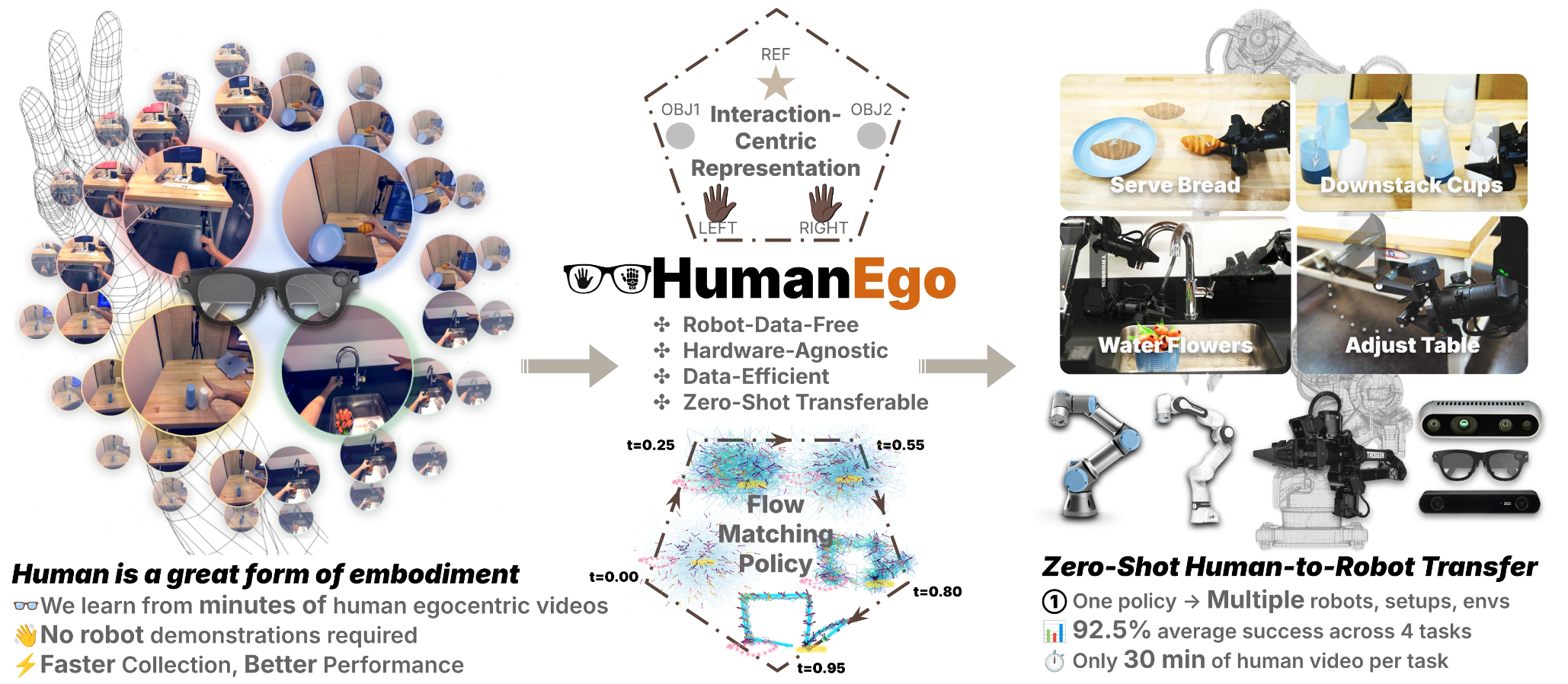
如图2所示HumanEgo 系统概览。HumanEgo 分四个阶段将人类以自我为中心的视频转化为可部署的双臂操作策略。演示者佩戴 Aria 眼镜记录任务过程;通过修复(inpainting)人类手臂图像并渲染虚拟夹爪来弥合具身差异,同时将每个实体相对于其他任务实体的位姿编码为“以交互为中心”的 Token。一种结合三个辅助目标的流匹配(flow matching)策略用于生成多模态双臂动作。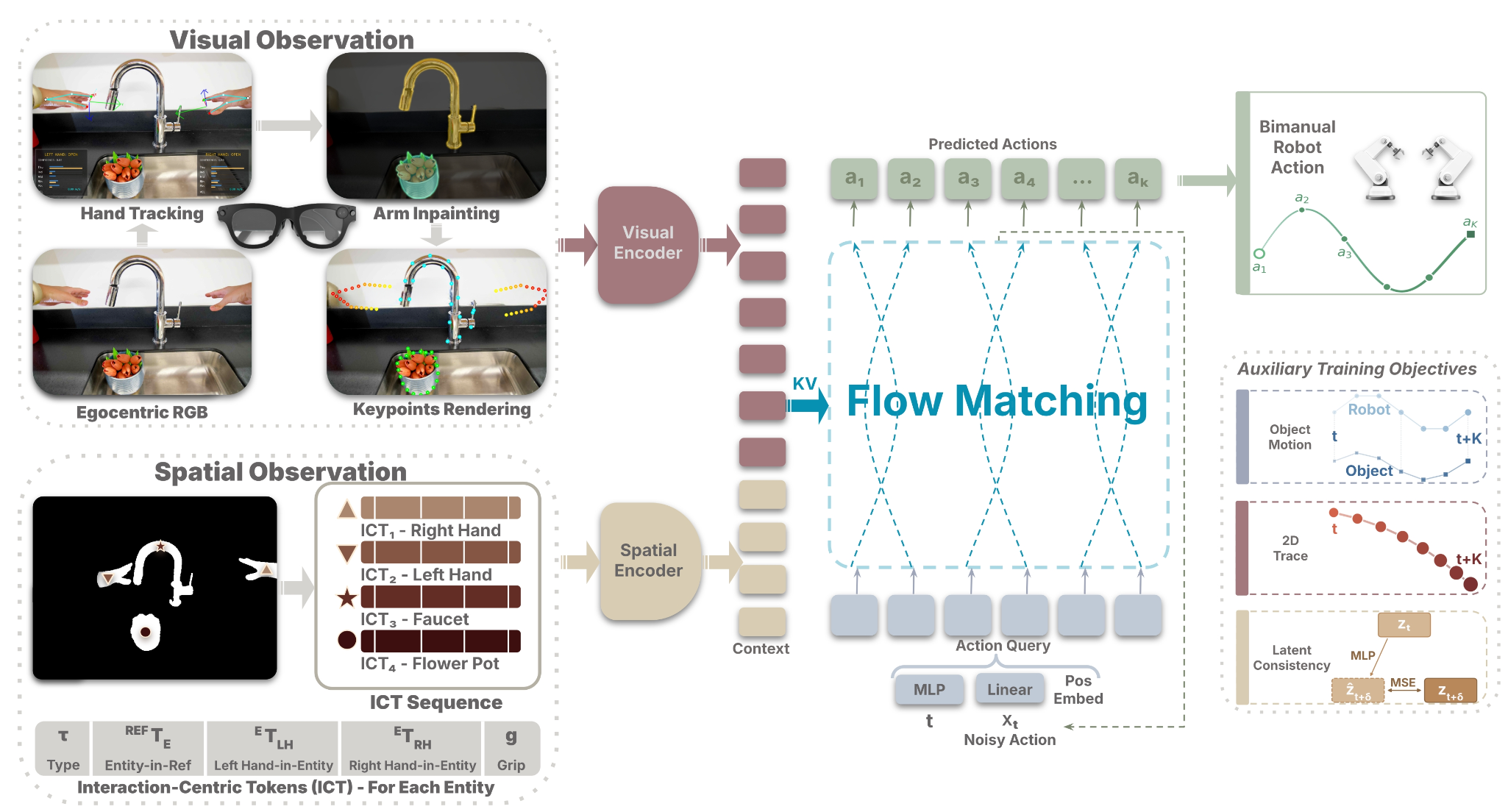
1 自我中心视角数据采集
演示者佩戴 Aria Gen1 眼镜 [7],在任意便利的环境下执行目标任务——无需考虑桌面高度、光照条件或背景,也无需专门的工作空间或校准步骤(如图 11所示)。每次演示仅需数秒;针对每项任务,以 30 Hz 的采样率采集约 30 分钟的人类演示数据。Aria 眼镜非常适合用于从人类视频中进行学习:其“机器感知服务”(MPS)能够提供高质量的 6-DoF SLAM 追踪、经过校准的 3D 手部姿态估计以及同步的自我中心视角 RGB 视频流——所有这些功能均集成于单一轻量级可穿戴设备之中。
三角测量
Aria Gen1 眼镜没有深度传感器,因此通过对跨帧追踪的二维关键点进行三角测量来恢复每个物体的三维位置。将移动的头戴式摄像机视为一个多视图系统,其外参由 6 自由度(6-DoF)Aria MPS SLAM 位姿 [7] 标定得出。这要求物体在观测窗口期间保持静止;一旦开始操作,物体便可自由移动。
片段开始前的场景扫描。多视图三角测量要求从差异足够大的视点观察同一个三维点,但在操作过程中,头戴式摄像机往往几乎静止,只有双手在移动,导致有效的摄像机基线(baseline)缩减。因此,在每次演示前都加上一个简短的场景扫描步骤:演示者保持场景静止,缓慢移动头部约 1–2 秒(约 30–60 帧)——采用水平从左向右平移或向物体前移的方式——然后再进行实际操作。
基于二维轨迹的多视图三角测量。对于每个物体,首先在扫描的第一帧中使用 Grounding DINO [59] 进行检测,利用 SAM2 [60] 进行分割,在生成的掩码(mask)上采样 N 个关键点,并使用 CoTracker3 [61] 在整个扫描过程的 F 帧中追踪这些点。
2 视觉观测预处理
将去畸变后的自我中心视角(egocentric)帧转换为与具体形态无关(embodiment-agnostic)的 RGB 观测,这一过程分为两步。首先,利用 SAM2 分割出人手和手臂,并通过 LaMa 图像修复技术 [58] 将其去除,从而消除视觉上的形态差异(embodiment gap)。其次,将虚拟夹爪和被追踪物体的关键点渲染到修复后的图像中——这两者均源自空间观测——以此将 6D 位姿信息隐式编码为视觉线索。这种轻量级处理流程弥合视觉形态差异,且无需昂贵的域适应或图像转换操作。
阶段检测
原始 Aria 录像交替包含主动操作片段和非操作片段——例如走向工作区、片段开始前的场景扫描以及任务结束后退。只有操作部分包含清晰的手部与物体交互动态,因此运行一个自动阶段检测步骤,将每段录像分割为不同的运动学模式,并仅保留操作帧用于训练。
阶段分类。每一帧被归类为以下五种模式之一:(0) MANIP(操作)——演示者站立不动并主动操作场景;(1) FORWARD(前进)——直线行走;(2) ROTATE(旋转)——原地头部/身体旋转(例如场景扫描);(3) TRANSITION(过渡)——相邻模式之间的短时缓冲;(4) FINISHED(结束)——录像末尾持续的静止保持状态。
分割信号与训练数据选择。动作阶段是基于两路数据流计算得出的:来自 Aria SLAM 的 6 自由度头部轨迹(对应身体运动)以及来自手部追踪器的 3D 手部轨迹(对应操作运动)。当头部线速度和角速度同时低于阈值(v_stop = 0.03 m/s,w_stop = 0.15 rad/s)并持续至少 15 帧时,当前帧被归入 MANIP(操作)阶段;ROTATE(旋转)阶段要求 ||ω_head|| > 0.10 rad/s 且 ||v_head|| < 0.08 m/s;FORWARD(前进)阶段包含剩余的线速度较高的帧;TRANSITION(过渡)阶段用于填充模式切换时的 10 帧缓冲区;当静止状态持续至少 30 帧时,判定为进入 FINISHED(结束)阶段。此外,利用手部运动学数据对 MANIP 阶段进行细化:若在 5 帧窗口内手部平均速度超过 0.15 m/s,则将该候选帧降级为 TRANSITION 阶段,从而将伸展/回缩动作从核心操作阶段中剔除。随后,训练流程仅保留 MANIP (0) 和 FINISHED (4) 阶段,舍弃 FORWARD、ROTATE 和 TRANSITION 阶段,确保场景扫描、导航及模式切换期间的数据不被纳入训练信号。
3 空间观测预处理
构建显式的实体级空间观测:将每个物体及双手均视为一个实体,通过追踪双手和物体来获取各实体的 6 自由度(6-DoF)位姿,随后将其相对关系编码为“以交互为中心”的 Token(Interaction-Centric Tokens)。
手部追踪与运动优化。首先利用 Aria MPS [7] 获得三维手部关键点,通过 SLAM 将其转换至世界坐标系,并分别对位置和旋转数据进行平滑处理:位置采用 Savitzky–Golay 滤波,旋转采用指数移动平均(EMA)。随后,将拇指与食指视为一对虚拟平行钳爪(如图 12所示),从而提取出 SE(3) 末端执行器位姿 T_ee 以及标量抓取参数 g。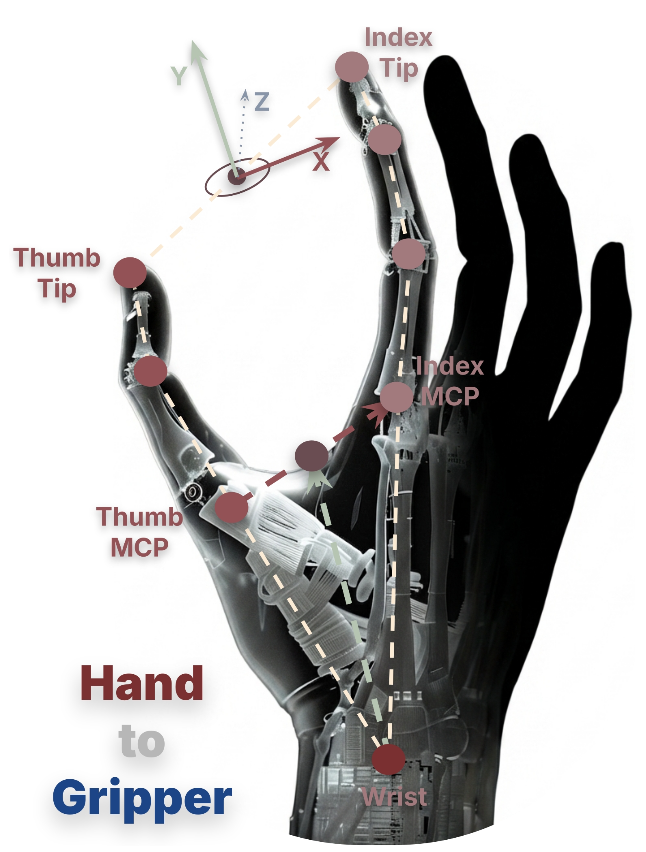
从手部到夹爪的动作迁移
若要将人类以自我为中心的视角(egocentric)视频视为机器人数据,演示中的每一帧都必须包含一个平行夹爪机器人实际可执行的末端执行器目标。然而,人手拥有 21 个有关节的关键点,其形态与双指夹爪截然不同,因此无法直接使用原始手部姿态。为此,通过一个简短的运动优化流程,利用几个解剖学上稳定的关键点,将手部动作重映射(retarget)为虚拟夹爪的参数——即 6 自由度 SE(3) 姿态加上 1 自由度的抓取标量值。
手部关键点提取。基于 Aria MPS [7] 生成的 21 关键点手部骨架进行处理;该系统融合立体 SLAM 相机与设备内置 IMU 的数据,以恢复每一帧中各关键点在 SLAM 世界坐标系下的 3D 位置。在重映射过程中,仅使用每只手上的五个关键点(如图 12所示):手腕、拇指掌指关节(MCP)、拇指指尖、食指掌指关节(MCP)以及食指指尖。
运动优化。原始 MPS 关键点数据存在噪声且偶尔会出现丢帧现象,若直接用于构建 SE(3) 姿态,会导致轨迹抖动或发生翻转。因此,执行一个简短的优化流程:(1)置信度掩码(Confidence masking)——剔除 MPS 置信度低于 0.8 的关键点,并丢弃持续时间少于 30 帧的检测片段(视为可能的虚假检测);(2)间隙插值(Gap interpolation)——对于短时间的缺失间隔(≤10 帧),位置采用线性插值,方向采用球面线性插值(SLERP)进行填充,从而确保后续平滑处理接收到的是密集序列;(3)Savitzky–Golay 位置平滑——对五个重映射关键点应用窗口大小为 21、多项式阶数为 2 的 SG 滤波器,在去除高频抖动的同时保留与操作相关的加速度特征; (4) EMA(指数移动平均)姿态平滑——对夹爪坐标系的 X 轴和 Y 轴应用指数移动平均(参数设为 αx = αy = 0.15),在每次更新后利用 Gram-Schmidt 过程进行重新正交归一化,并强制相邻帧之间的符号一致性,以防止出现虚假的 180° 翻转。
末端执行器位置。将拇指指尖与食指指尖的中点作为夹爪位置,该位置自然对应于平行钳口抓取时的中心点。
末端执行器(夹爪)的朝向。在进行捏取(pinch grasp)动作时,选择一个既准确又稳定的朝向是动作重定向(retargeting)中的难点;两种看似自然的方案均不可行:(i) 原始手腕位姿:直接采用 MPS 系统的手腕朝向作为夹爪坐标系是不准确的,因为解剖学意义上的手腕坐标系与夹爪实际使用的“拇指-食指”动作轴并不重合。(ii) 手腕至指尖中点的连线:若将前向轴定义为从手腕指向拇指与食指指尖的中点,并将夹爪张合轴定义为从拇指指尖指向食指指尖,这种方法在手掌张开时有效,但在捏取瞬间会发生退化——此时两指尖几乎重合于同一点,导致夹爪张合轴退化为近乎零向量的向量,从而使坐标系定义失效。因此,改用掌指关节(MCP joints)来构建夹爪坐标系,因为这些关节在整个捏取过程中始终保持明显的间距。
夹具孔径。从拇指-食指指尖距离导出 1-DoF 夹具命令 g 。对归一化后的 g 信号进行中值滤波并执行简短的闪烁抑制处理,以生成清晰的“开启/关闭”指令流,并在部署阶段进行二值化处理。
目标跟踪与姿态估计。利用基于文本提示的 Grounding DINO [59] 检测每个目标,使用 SAM2 [60] 对其进行分割,并从掩码中采样轮廓关键点。
基于“以交互为中心”的Token(ICT)进行实体空间编码。将每个实体的6自由度(6-DoF)位姿编码为ICT,从而同时捕捉其在共享参考系中的位姿以及与双手的空间关系。
4 采用密集辅助目标的流匹配策略
其策略(如图 2 所示)接收场景状态 s_t(包含 ICT token 和 RGB 图像),并生成跨越 K 步时域的双手动作用轨迹 a;其中,轨迹的每个 D_a 维片段均由双手的 6 自由度(6-DoF)位姿与二值抓取状态拼接而成。
基于流匹配(Flow Matching)的动作生成。将动作生成建模为一个条件流匹配 [33, 64] 问题:利用以 s_t 为条件的 Transformer 解码器对速度场 v_theta 进行参数化,并对其进行训练,以实现从高斯先验样本到动作目标的传输。
密集辅助目标。为了从每一次演示中提取丰富的监督信号,引入三个与流匹配(flow matching)头共享上下文编码器的辅助目标:(1) 物体运动(L_OM):预测受控物体的未来 6-DoF 轨迹,从而迫使编码器对受手部动作影响的物体动力学进行建模;(2) 2D 轨迹(L_2D):回归实体轨迹的未来 2D 投影,将表征与视觉观测建立联系;(3) 潜在一致性(L_LC):预测 K 步之后的 ICT 状态,促使编码器捕捉场景动态。最后将这些目标与流匹配损失结合,构成一个统一的优化目标。
所有辅助目标均由感知流水线自动生成,因此每一次演示都能提供密集的、多任务的信号。这三个目标分别在互补的空间(3D 物理空间、2D 视觉空间及潜在空间)中预测场景演变,赋予共享编码器一个关于手-物交互的轻量级世界模型。此外,利用该共享编码器作为多任务正则化器来抑制过拟合,这种方法在低数据量场景下带来的性能提升尤为显著。
流匹配(Flow Matching)策略
速度场与损失函数。训练一种条件流匹配(conditional flow matching)[33] 策略,该策略将高斯先验 x_0 ∼ N (0, I ) 映射到真实的双臂动作片段 x_1,路径为线性路径 x_t = (1-t)x_0 + tx_1,其中流时间 t ∼ U (0, 1)。目标速度为恒定位移 v_target = x_1 - x_0;流匹配损失是对预测速度计算的均方误差(MSE),并按维度进行加权:位置权重 w_p=5,6D 旋转权重 w_r=1,抓取 Logit 权重 w_g=10。还支持一种最优传输-匹配变型(OT-CFM),它在计算损失前先在每个小批量(mini-batch)内求解噪声样本与动作样本之间的匈牙利指派问题,从而生成更平直的目标流;由于在任务中未发现其具有持续优势,因此默认关闭该选项。
网络架构。速度场 v_theta 是一个 6 层、8 头(8-head)的 Transformer 解码器,嵌入维度为 384,Dropout 率为 0.05。每个动作片段 Token 既通过自注意(self-attention)关注片段内的其他 Token,也通过交叉注意(cross-attention)关注条件上下文(conditioning context)。上下文由两路信息构成:(i) RGB 帧,通过对 240 X 320 的输入应用 16 X 16 的 Patch 嵌入,并融合经由小型 MLP 处理的正弦时间嵌入(sinusoidal time embedding)来构建;(ii) 状态 Token,即针对每个实体的 ICT Token,经线性投影至 384 通道。
辅助头(Auxiliary heads)。三个稠密辅助任务与速度场共享上下文编码器。物体动力学头(object-dynamics head)预测被操作物体未来的 9 维位姿轨迹,并使用权重为 0.5(w_p, w_r) 的 MSE 进行训练;2D 视觉预测头(2D visual-foresight head)通过浅层反卷积堆叠输出三个锚点关键点的 K X 3 X 2 归一化图像坐标,损失权重 w_f=20;此外,时间一致性(temporal-consistency)预测头利用由 w_c [0.1, 1.0] 加权的掩码均方误差(masked MSE),预测未来 K 步的手部 Token。这三个目标均由感知流水线自动生成,因此每段演示都能提供密集的、无需额外标注的多任务信号。
其他技巧。两项轻量级训练技巧进一步稳定基于数分钟数据的学习过程。区域注意(region attention)机制引导图像交叉注意(image cross-attention)聚焦于当前活跃的操作锚点(manipulation anchor):具体而言,利用锚点在图像上的二维投影坐标 (u_0, v_0),将注意 Logits 与高斯spotlight相乘。在训练过程中,通过注入状态噪声来扰动每一个手部 Token(即 s ̃_t = s_t + epsilon,其中 epsilon ∼ N(0, Σ_s),并针对位置、6D 旋转及抓取通道分别设定标准差;这种做法增强了策略的鲁棒性,使其能够应对部署阶段可能出现的微小感知噪声。
优化方案。用 AdamW 优化器进行训练,基础学习率设为 10-4,采用余弦衰减策略(包含 200 步预热期),最小学习率比率为 0.05,批次大小(batch size)为 32,训练轮数(epochs)为 400。训练中将梯度范数裁剪阈值设为 1.0,使用 bfloat16 混合精度,并维护权重的指数移动平均(衰减率为 0.999)以供评估与部署使用。
数据增强。为了将有效的训练分布从每个任务仅约40分钟的人类视频数据进行扩展,在数据加载器中实时应用了一系列组合增强方法,这些方法归纳为三类。
(i) 针对RGB流的图像增强。光度抖动(概率p=0.8)会随机扰动亮度(±0.20)、对比度(±0.20)和伽马值(±0.15),添加高斯像素噪声(σ=0.02),以一定概率(p=0.1)将帧转换为灰度图,并对HSV色彩空间中的色调(hue)进行±10的抖动,对饱和度(saturation)进行[0.6, 1.4]范围内的抖动。随机缩放裁剪(p=0.5)操作会选取一个尺度在[0.7, 1.0]、长宽比在[0.9, 1.1]之间的子窗口,随后将其调整回网络输入尺寸。此外,还会以p=0.15的概率应用3×3核的高斯模糊,并使用随机擦除(p=0.5)覆盖3到8个黑色遮挡块,每个遮挡块覆盖帧面积的5%到20%。
(ii) 动作-目标增强。在计算流匹配(flow-matching)损失之前,向动作片段中的每个目标姿态添加高斯噪声进行扰动——平移噪声σ_pos = 1 mm,旋转噪声σ_rot = 0.5°——这有助于对速度场进行正则化,从而增强其对标签中微小跟踪噪声的鲁棒性。
(iii) 时间维度增强。以p=0.5的概率应用子步插值(sub-step interpolation):即根据随机选取的α值(α ∈ [0, 1]),对相邻的状态/动作帧进行线性混合,从而在不增加额外数据采集成本的情况下,有效地提高了时间网格的密度。
在四项涵盖“抓取与放置”(pick-and-place)、多步双臂协同、富含接触交互的推理以及持续旋转控制的真实世界操作任务上对 HumanEgo 进行了评估(如图 3 所示)。针对每项任务,分别描述场景设置、单次试验(trial)的随机化方式、目标行为,以及用于评估主文中每种条件下 40 次试验结果的成功与失败判定标准。
1 机器人推理设置
除了零样本泛化研究外,主论文中的所有真实世界实验均采用图13所示的单一推理设置:两台 Trossen WidowX AI 机械臂并排安装在同一个工作台上,构成一个双臂操作平台,无需在任务间更换硬件即可执行单臂和双臂任务。每台 WidowX AI 机械臂均为 6 自由度(DoF)平行夹爪机械臂,在最大伸展范围下的有效载荷约为 1.5 kg,末端执行器重复定位精度为 ±1 mm。视觉输入方面,用安装在工作区上方的单个 Intel RealSense D405 相机;其 RGB 视频流是 HumanEgo 接收的唯一观测数据。虽然每台 WidowX AI 机械臂都配备了内置腕部相机,但特意未将其用于 HumanEgo;相比之下,机器人遥操作 ACT 基线方法 [28] 则将腕部相机作为其标准观测接口的一部分进行使用。
2 Flow Matching 推演与控制
ODE 推演。在测试阶段,利用固定步长的欧拉(Euler)求解器对学习到的速度场进行积分,共执行 20 个推理步骤:从策略加载时采样的一次噪声样本 x_0 ∼ N(0,I) 出发,以 Delta t = 1/20 迭代更新 x_t+Delta t ← x_t + v_theta(x_t, t, s_t) Delta t,从而在每次重规划的前向传播中生成包含 K=50 个步骤的双臂动作序列(action chunk)。预测结果按维度解包为每只手的位置、6D 旋转表示及抓取 Logit 值;其中位置数据利用数据集的均值/标准差进行反归一化,旋转数据通过对 6D 表示进行归一化及施密特正交化(Gram–Schmidt)处理投影回 SO(3) 空间,抓取数据则通过 Sigmoid 函数处理。
动作序列分块与控制。控制器在每个周期(10 Hz)进行重规划,在历史记录中最多保留一个预测结果,并在每个周期执行一个动作。采用步长为 2 的采样间隔对数据块进行降采样,使实际执行频率达到 5 Hz;同时,利用 25 步的前瞻偏移量(look-ahead offset),控制器可在当前执行索引之前预先查询数据块,从而掩盖规划延迟。对于抓取动作,采用“视界内任意时刻”(any-over-horizon)规则:只要当前数据块中任一步预测的抓取概率超过 0.6,机械爪即刻闭合;此外还提供可选的“抓取锁定”(grasp-latch)模式,在首次触发抓取后保持机械爪闭合状态,以防止任务执行中途发生意外松脱。
平滑处理与安全机制。为消除预测出的 SE(3) 轨迹流中的微小噪声,在向机械臂发送目标指令前,对位置数据应用指数移动平均(EMA,α=0.5),对旋转数据应用四元数球面线性插值(SLERP);同时采用轨迹重叠混合技术(平滑参数为 12),以避免连续数据块切换时出现突兀的启停动作。最后,设置安全限制机制(safety cage),将每个周期内的目标位移限制在位置 ≤0.08 m 和旋转 ≤0.02 rad 以内,从而防范突发异常值;在实验的正常运行过程中,未观察到触发该安全限制的情况。
实验设置。ICT 接收 3D 手部关键点作为输入,因此上游手部追踪器的质量直接影响策略的学习效果。为了探究这种依赖关系,在“Serve Bread”任务上保持其他所有条件不变——即使用相同的 45 次演示(总计 30 分钟)、相同的 HumanEgo 架构和相同的训练方案——仅改变生成动作标签的手部追踪模块。比较四种涵盖文献中主流设计方案的追踪器(见图 15所示):(1) Aria-MPS [7](默认方案),它通过 Meta 的 MPS 流程融合两个大视场(wide-FoV)单色 SLAM 摄像头与设备内置 IMU 数据,从而恢复度量级 3D 关键点(注意:中央 RGB 摄像头仅用于视频记录,不参与手部追踪);(2) WiLoR [65],一种基于 Transformer 的模型,通过每帧的单张 RGB 裁剪图像回归 MANO 参数;(3) HaMeR [66],一种强大的单目 RGB 估计器,同样预测 MANO 参数但逐帧独立处理(该类方法后续已出现针对时间序列和世界坐标系的扩展版本 [67, 68]);以及 (4) MediaPipe [69],一种轻量级单目 RGB 流程,其 3D 输出基于根节点(root-relative),需结合相机深度信息进行坐标提升(lifting)。除了这些纯视觉追踪器外,还有一些基于传感设备的替代方案,利用多模态传感手套 [70] 或 6 轴 IMU 系统 [71] 恢复手部姿态;但这些方案要求演示者佩戴专用硬件,不符合“零设备(zero-instrumentation)”的数据采集设定。针对每种追踪器,重新进行数据预处理,从零开始训练 HumanEgo 模型,并在“Serve Bread”任务上进行 40 次真实环境测试评估(图 15所示)。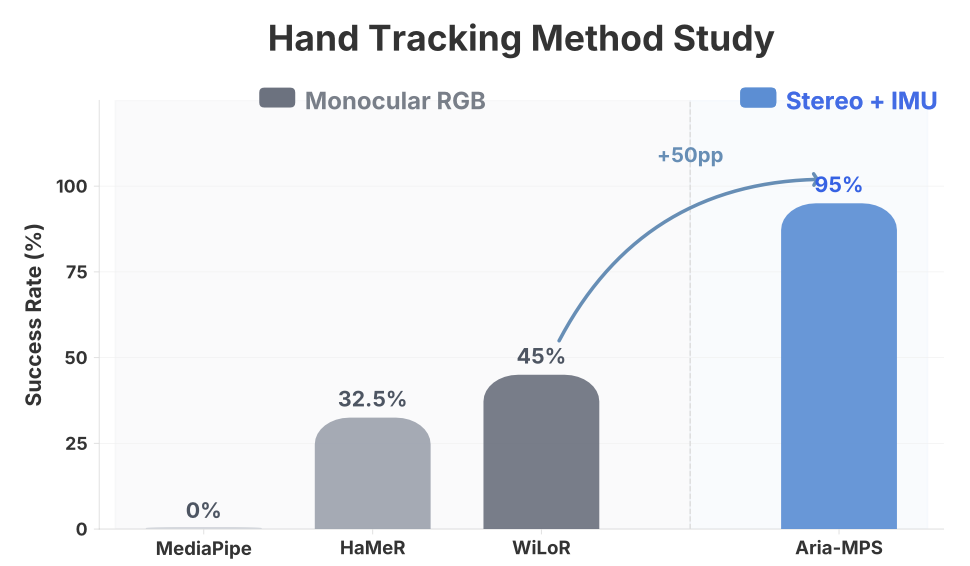

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 5
5 0
0- 0



 已为社区贡献212条内容
已为社区贡献212条内容

所有评论(0)