SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
SONIC提出了一种基于大规模运动跟踪的通用人形控制框架,通过扩大模型规模和数据量实现自然全身运动。其核心贡献包括:(1) 实时运动规划器连接运动跟踪与任务执行,实现交互式控制;(2) 统一token空间支持VR设备、视频、文本等多模态输入。系统采用密集运动捕捉监督训练PPO策略,通过专用编码器处理不同输入模态并量化为通用token,再由解码器生成动作。实验表明,该系统能实现高精度远程操作和复杂运
SONIC:用于自然人形全身控制的超大运动跟踪
“我们证明,扩大模型容量、数据和计算量可以产生一个通用的人形控制器,能够创建自然且强大的全身运动。具体来说,我们将运动跟踪视为人形控制的一项自然且可扩展的任务,利用来自不同运动捕捉数据的密集监督来获取人体运动先验,而无需手动奖励工程。”
解读:验证了scaling law在机器人小脑全身控制的有效性,效果不错。
论文的贡献点
“(1) 实时通用运动规划器,将运动跟踪与下游任务执行联系起来,实现自然和交互式控制;(2) 统一的令牌空间,支持各种运动输入接口,例如 VR 远程操作设备、人类视频和视觉语言动作 (VLA) 模型,所有这些都使用相同的策略。”
“在这项工作中,我们通过将运动跟踪确定为人形控制的可扩展基础任务。运动跟踪利用人体运动捕捉数据,提供密集的逐帧监督,无需奖励工程。”
“首先,我们开发通用运动生成系统用于交互式控制,通过运动空间中的运动规划来实现目标导向的任务,例如交互式运动和类似游戏的角色控制。其次,我们设计了一个支持多模式控制的通用令牌空间——通过统一的界面接受来自远程操作、人类视频、音乐、文本和视觉语言动作模型的输入(Kocabas 等人,2020;Li 等人,2021;Tevet 等人,2022;Zhang 等人,2023)。这个统一的框架允许我们的运动跟踪器直接与视觉语言动作(VLA)模型(Bjorck 等人,2025)和不同的控制方式交互。 我们提出了用于自然人形控制(SONIC)的超大运动跟踪,这是一个能够在广泛的应用程序中实现自然人形控制的框架。我们实现了高精度的远程操作和交互控制能力,包括跑步、跳跃、爬行等自然的类人运动。利用我们的通用令牌空间,我们的控制器可以支持跨实体运动跟踪,其中估计的人体全身运动可以直接映射到人形控制信号,从而绕过重新定位的需要。我们展示了与多模式人体运动生成模型的无缝集成,通过我们的通用令牌空间支持视频、文本和音乐控制。此外,我们还表明,通过我们的系统收集的远程操作数据可用于训练视觉-语言-动作基础模型,建立从大规模运动跟踪到基于基础模型的人形控制的完整管道。这些结果验证了大规模运动跟踪可以作为各种现实世界人形应用程序的实用且通用的行为基础模型。”
“2.4.3.基础模型驱动的移动双手操作
为了通过相同的通用令牌接口演示自主控制,我们将 VLA 基础模型连接到用于远程操作的管道。使用通过 3 点远程操作接口收集的 300 个轨迹,我们对 GR00T N1.5 模型进行了微调(Bjorck 等人,2025 年),并在上述从苹果到盘子的移动拾放任务中对其进行了评估(图 6)。 VLA 输出相同的远程操作格式控制信号:三个上身姿势(头部和双手腕)、基础(腰部)高度和导航命令(根线速度和角速度),然后将其输入运动规划器和混合编码器,然后通过通用控制策略执行。在这项概念验证任务中,系统经过 20 次试验取得了 95% 的成功率,表明通用运动跟踪器可作为强大的系统 1 控制器(快速、反应性全身技能),补充 VLA 的系统 2 功能(较慢、深思熟虑的推理)(Kahneman,2011)。该实验的目的只是为了建立基础模型规划和我们的运动跟踪控制器之间的兼容性,而不是要求广泛的概括;扩展到更丰富的任务分布留待未来的工作。展望未来,VLA 与通用token空间的接口提供了一条通往高级全身推理的道路,该推理位于通用跟踪器的响应性、鲁棒性和人体运动感应偏差之上,能够以更高的控制率运行。大规模探索这种整合是未来工作的重要方向。”
解读:这里展示了VLA接口与sonic接口的对齐方案。这块是来自于实验结果的解读。(论文把实验结果放在第二部分,第三部分才开始正式讲原理结构)
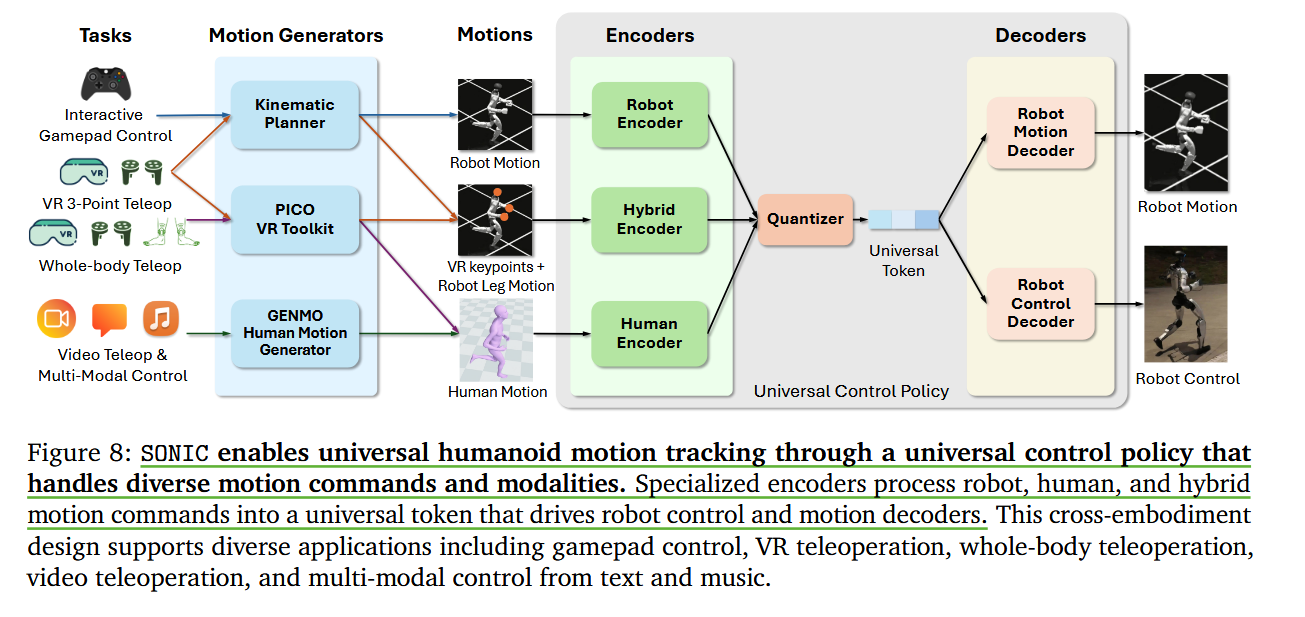
SONIC 通过处理不同运动命令和模式的通用控制策略实现通用人形运动跟踪。专用编码器将机器人、人类和混合运动命令处理为驱动机器人控制和运动解码器的通用令牌。
先来讲基础的运动追踪:
“运动追踪方式。我们将人形运动跟踪制定为马尔可夫决策过程 M = ⟨S, A, T , R, γ⟩,包括状态空间、动作空间、转换函数、奖励函数和折扣因子 γ。我们使用近端策略优化(PPO)(Schulman et al., 2017)来训练策略,以最大化预期累积贴现收益 E [︁ Σ︀T t=1 γt−1rt ]︁ 。
状态。状态表示 st 包括两个部分:本体感觉 sp t 和运动命令 sgt 。本体感觉信息 sp t ≜ (qt, q ̇t, ωt, ψt, at−1) 包括关节姿态 qt、关节速度 q ̇t、根角速度 ωt、根坐标系中的重力向量 gt 以及之前的动作 at−1。运动命令 sg t 有三种类型:机器人运动 gr、人类运动 gh 或混合运动 gm(将上半身关键点与下半身机器人运动相结合),为了简洁起见,我们省略了下标 t。所有状态量都在机器人的局部航向坐标系中表示,以确保旋转不变性。”
解读:SONIC 的“密集监督”指的是 动作捕捉提供了逐帧参考信号;“PPO”指的是用这些逐帧参考信号构造 dense reward,然后通过强化学习训练物理控制策略。PPO 是训练方法,dense supervision 是奖励/目标信号来源,两者不冲突。
具体的奖励参数在文章中表1有详细列出。
“编码器。三个专用编码器处理不同的运动命令类型:(1)机器人运动编码器 Er 以帧间隔 Δtr 对 Fr 未来帧上的机器人关节位置和速度进行编码,(2)人体运动编码器 Eh 以帧间隔 Δth 对 Fh 未来帧上的 3D 人体关节位置(来自于VR眼镜)(Loper 等,2015)进行编码,(3)混合运动编码器 Em 对当前帧的稀疏上身关键点(头和手)进行编码(用于实时上半身跟踪),结合 Fm 未来帧上的下半身机器人运动,帧间隔为 Δtm。多帧输入可实现预期行为并提高策略的稳健性。所有编码器均实现为多层感知器(MLP;表 3 中的架构详细信息),将命令 gr、gh、gm 映射到共享潜在空间,从而实现跨实施例表示对齐。
量化器。使用矢量量化器将编码的潜在表示量化为通用标记 z。具体来说,我们使用 FSQ (Mentzer et al., 2023) 作为我们的矢量量化器。通用标记是 Dz 维向量,每维具有 Lz 量化级别。
解码器。通用令牌 z 通过两个单独的解码器进行解码。首先,机器人控制解码器 Dc 将通用令牌转换为控制机器人关节的电机命令。其次,机器人运动解码器 Dr 重建机器人运动命令,提供辅助监督以改善潜在空间并增强特征学习。两个解码器均以 MLP 的形式实现(表 3)。
”
解读:读到这里,我就有一个疑问了,解码器到底有没有当前的观测/状态的输入?我全文找了一圈,没有仔细说解码器的输入情况。翻阅代码发现是有的。
构造 decoder 输入
decode_input_dict = {
"token": all_tokens,
"token_flattened": all_tokens.view(..., -1),
"proprioception": proprioception_input,
}
decode_input_dict.update(tokenizer_obs)
所以 decoder 既能拿 token,也能拿 flatten token、proprioception(观测),以及原始 tokenizer obs。
接着来到3.3.生成运动学运动规划器 3.2 解决的是:给我一段明确的目标运动,我怎么稳定跟踪它并输出机器人动作。 3.3 解决的是:用户只给我很稀疏、很抽象的意图时,我怎么先生成一段合理的目标运动。(比如像向前走1m,这些通用语言指令) 高层命令 ↓ 3.3 运动生成器 / kinematic motion planner ↓ 机器人运动参考 / robot motion command ↓ 3.2 universal motion tracking policy ↓ 真实机器人动作
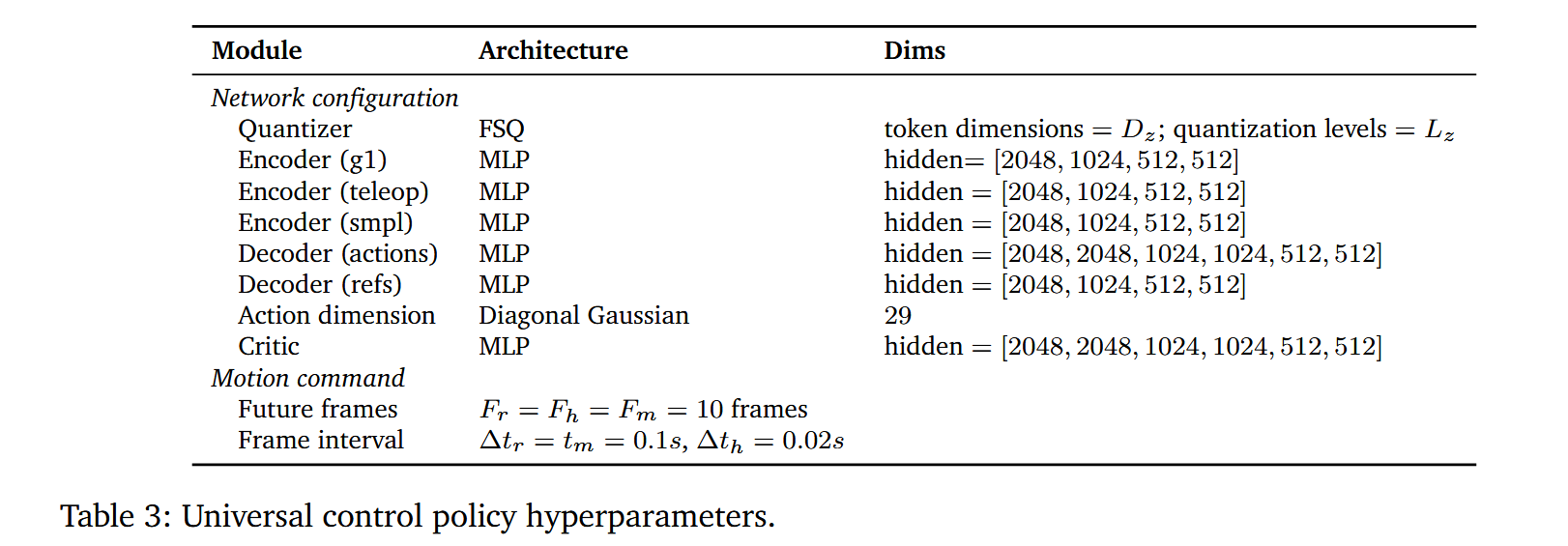
表三模型结构解读:
这里的 Dims 不是“输入维度”的意思,而是这个模块的隐藏层宽度配置。例如:
Decoder (actions) MLP hidden = [2048, 2048, 1024, 1024, 512, 512]
意思是 action decoder 是一个 6 层隐藏层的 MLP,大致结构是:
input → 2048 → 2048 → 1024 → 1024 → 512 → 512 → output
最后的 output 不在这个列表里。真正的动作输出维度由表里的 Action dimension = Diagonal Gaussian 29 决定,也就是输出一个 29 维的对角高斯动作分布。
|
模块 |
表里的 dims |
作用 |
|
Encoder (g_r / g1) |
[2048, 1024, 512, 512] |
把机器人自身 reference motion 编成 latent |
|
Encoder (teleop) |
[2048, 1024, 512, 512] |
把遥操作/稀疏上身 keypoint + 下身 motion 编成 latent |
|
Encoder (smpl) |
[2048, 1024, 512, 512] |
把 SMPL / human pose motion 编成 latent |
|
Quantizer |
D_z, L_z |
把连续 latent 变成 FSQ universal token |
|
Decoder (actions) |
[2048, 2048, 1024, 1024, 512, 512] |
从 token/状态特征生成机器人动作分布 |
|
Decoder (refs) |
[2048, 1024, 512, 512] |
辅助重建 robot reference motion |
|
Critic |
[2048, 2048, 1024, 1024, 512, 512] |
PPO 的 value function 网络 |

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)