3090微调openvla微调复现踩坑(更新ing)
openvla微调复现踩坑
本文不涉及环境搭建相关内容,环境搭建可以参考官方仓库openvla,本文主要讲述openvla原理以及复现过程中遇到的各种问题及解决办法
基本信息
- 本人配置
- 仓库地址:https://github.com/machenxiang/openvla
注:因为原来的openvla需要多机多卡,所以改了一下finetune代码,封装了一下起训练的脚本
开始训练
- 代码下载
git clone https://github.com/machenxiang/openvla.git
- 根据openvla官方教程搭建环境,这里不在重复说明
- 运行训练脚本
python my_libero_train.py
和官方代码相比,本人主要做了一下修改
- 新增了tensorboard记录日志参数,原代码使用WandB需要注册及联网比较麻烦
- 原代码需要多机多卡,在单卡3090上跑报错,因此修改成了单卡模式
- 新增了训练和评测脚本,避免训练和评测参数太多
- 修改了lora权重和原权重结合的为重,新代码只在训练结束后,再结合一次
- 增加余弦退火学习率
微调实验
冻结策略:
if cfg.use_lora:
lora_config = LoraConfig(
r=cfg.lora_rank,
lora_alpha=min(cfg.lora_rank, 16),
lora_dropout=cfg.lora_dropout,
target_modules="all-linear",
init_lora_weights="gaussian",
)
vla = get_peft_model(vla, lora_config)
vla.print_trainable_parameters()
对应到具体的层
OpenVLA-7B (7B 参数基座)
├── Vision Encoder (SigLIP ViT)
│ ├── patch_embed ❄️ 冻结 (因为是 Conv2d)
│ └── blocks[0-26]
│ ├── attn.qkv 🔓 LoRA (r=32) ── 捕获!
│ ├── attn.proj 🔓 LoRA (r=32) ── 捕获!
│ ├── mlp.fc1 🔓 LoRA (r=32) ── 捕获!
│ ├── mlp.fc2 🔓 LoRA (r=32) ── 捕获!
│ └── norm ❄️ 冻结 (LayerNorm)
│
├── Projector (无缝连接件)
│ └── linear 🔓 LoRA (r=32) ── 捕获!(把视觉特征转成文本维度的多层感知机)
│
├── LLaMA Decoder (7B 大脑)
│ └── layers[0-31]
│ ├── q_proj 🔓 LoRA (r=32) ── 捕获!
│ ├── k_proj 🔓 LoRA (r=32) ── 捕获!
│ ├── v_proj 🔓 LoRA (r=32) ── 捕获!
│ ├── o_proj 🔓 LoRA (r=32) ── 捕获!
│ ├── gate_proj 🔓 LoRA (r=32) ── 捕获!
│ ├── up_proj 🔓 LoRA (r=32) ── 捕获!
│ ├── down_proj 🔓 LoRA (r=32) ── 捕获!
│ └── input_layernorm / post_attention_layernorm ❄️ 冻结
│
└── lm_head (输出预测头)
└── lm_head 🔓 LoRA (r=32) ── 捕获!(负责挑选最后256个动作Token)
rank选择:
Rank 适用场景 你的选择
r=4, r=8 轻量微调,数据少
r=16 通用推荐起点
r=32 平衡选择
r=64, r=128 数据丰富,需要大拟合能力
经验建议
数据集小 (< 10k):r=8 或 r=16
数据集中等 (10k-50k):r=16 或 r=32
数据集大 (> 50k):r=32 或 r=64
因为libero_spatial_no_noops 有 ~53k 样本,选 r=32 是合理的。
实验1
- 训练配置
cfg = FinetuneConfig(
vla_path="openvla/openvla-7b",
data_root_dir=Path("/home/vcar/LIBERO/modified_libero_rlds"),
dataset_name="libero_spatial_no_noops",
run_root_dir=Path("./runs"),
adapter_tmp_dir=Path("./adapter-tmp"),
batch_size=2,
max_steps=30000,
save_steps=3000,
learning_rate=2e-5,
grad_accumulation_steps=8,
image_aug=True,
shuffle_buffer_size=100_00,
save_latest_checkpoint_only=True,
use_lora=True,
lora_rank=32,
lora_dropout=0.0,
use_quantization=False,
wandb_project="openvla-libero",
wandb_entity="YOUR_ENTITY",
use_wandb=False,
run_id_note=None,
)
-
训练结果
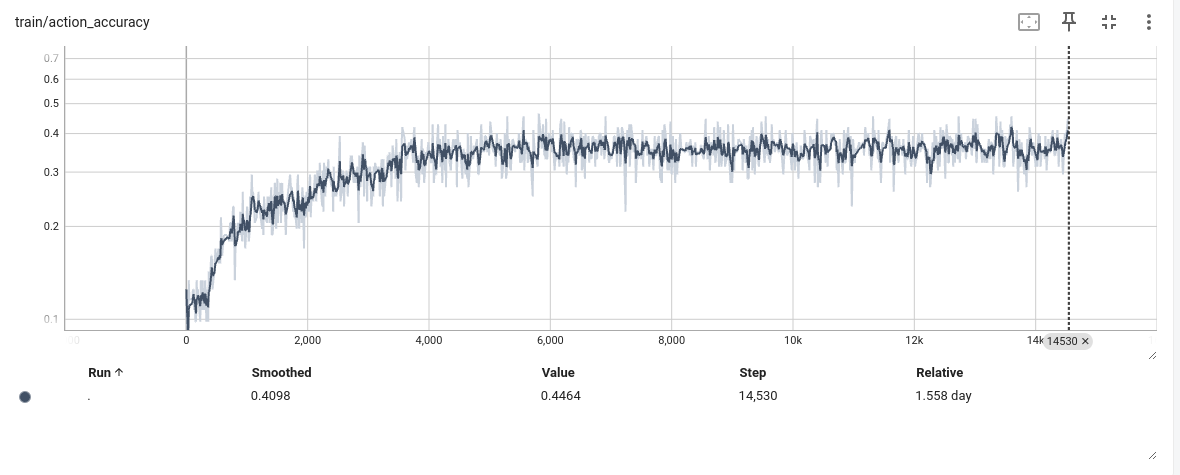
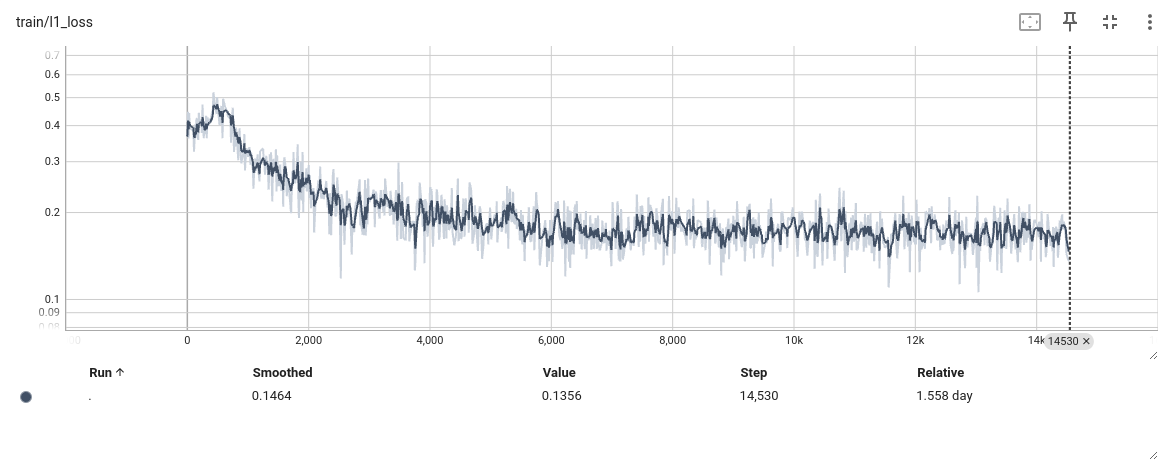
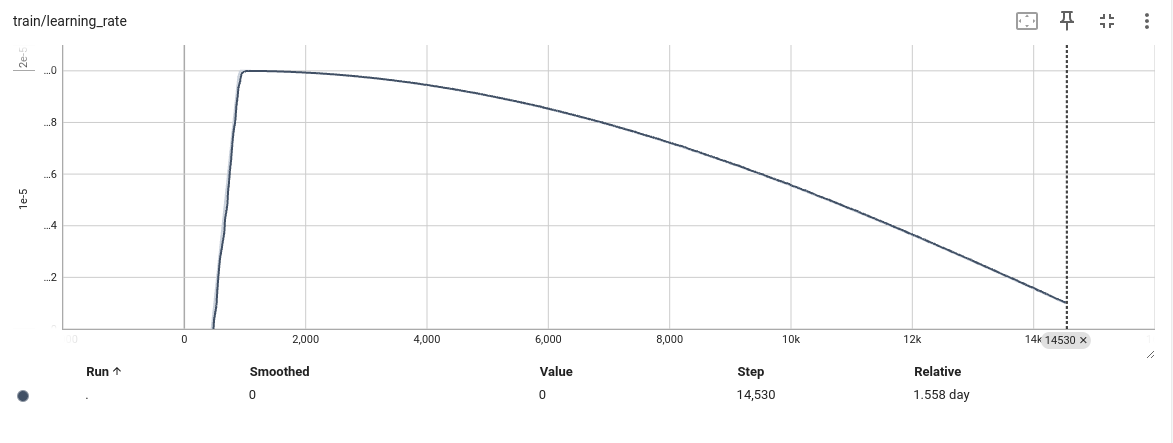
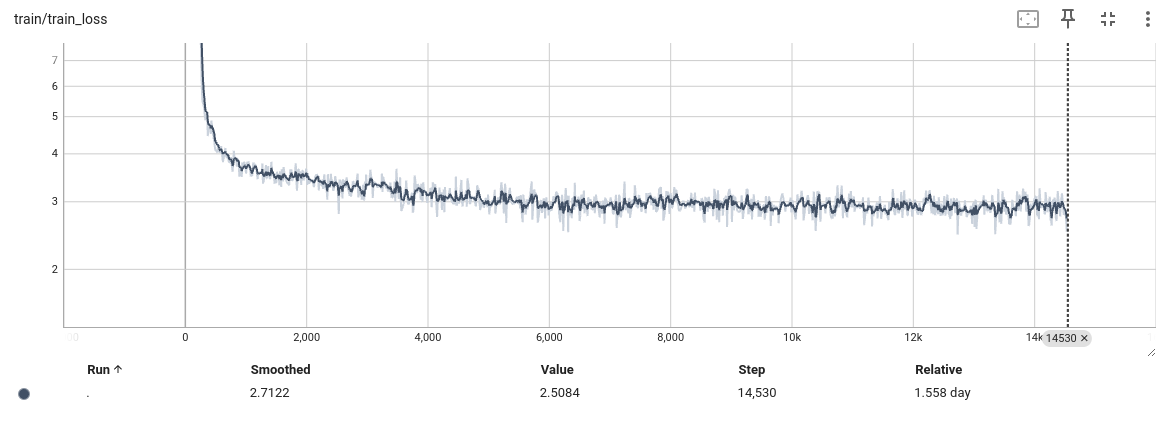
-
结论
发现模型训练到6000步左右,陷入瓶颈,loss,L1 loss 准确率都基本不在发生变化,怀疑是不是模型有问题 -
问题排查
- 过拟合实验
采用两个数据进行过拟合实验,使用仓库里finetune copy.py进行过拟合实验,下面是部分核心代码,反复训练第一个batch,看看loss和准确率
with tqdm.tqdm(total=cfg.max_steps, leave=False) as progress:
vla.train()
optimizer.zero_grad()
fixed_batch = None
for batch_idx, batch in enumerate(dataloader):
if fixed_batch is None:
fixed_batch = {k: v.to(device_id) if hasattr(v, "to") else v for k, v in batch.items()}
# 将当前的 batch 强行替换为固定 batch
batch = fixed_batch
with torch.autocast("cuda", dtype=torch.bfloat16):
output: CausalLMOutputWithPast = vla(
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"],
pixel_values=batch["pixel_values"].to(torch.bfloat16),
labels=batch["labels"],
)
loss = output.loss
.......
# Normalize loss to account for gradient accumulation
normalized_loss = loss / cfg.grad_accumulation_steps
# Backward pass
normalized_loss.backward()
.......
if gradient_step_idx >= 500:
print(f"Reached Debug Step 500. Forcing max_steps to trigger clean merge and save...")
cfg.max_steps = gradient_step_idx
.......
break
结果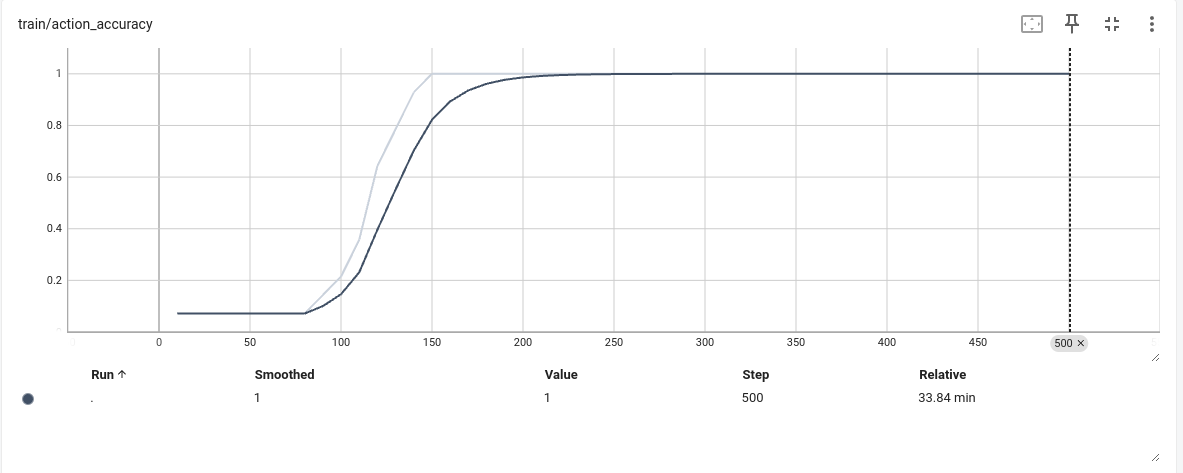
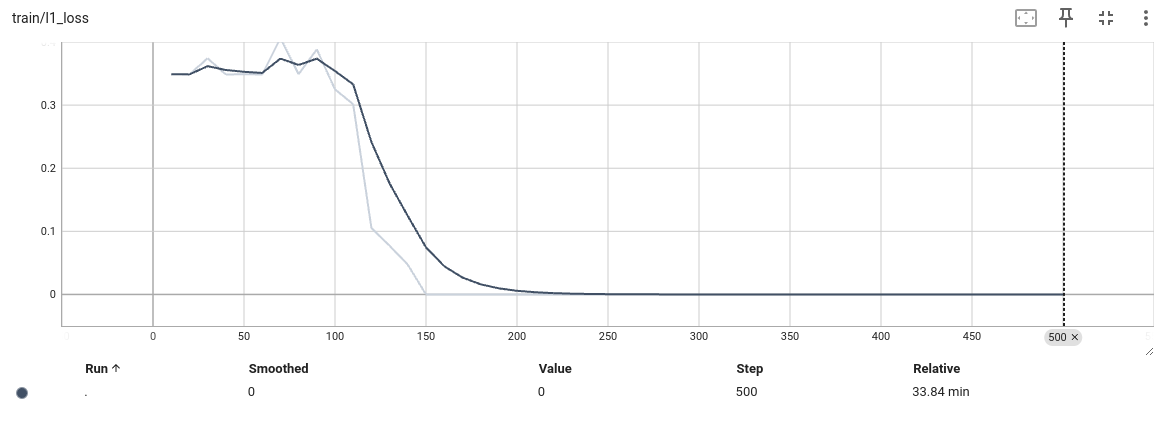
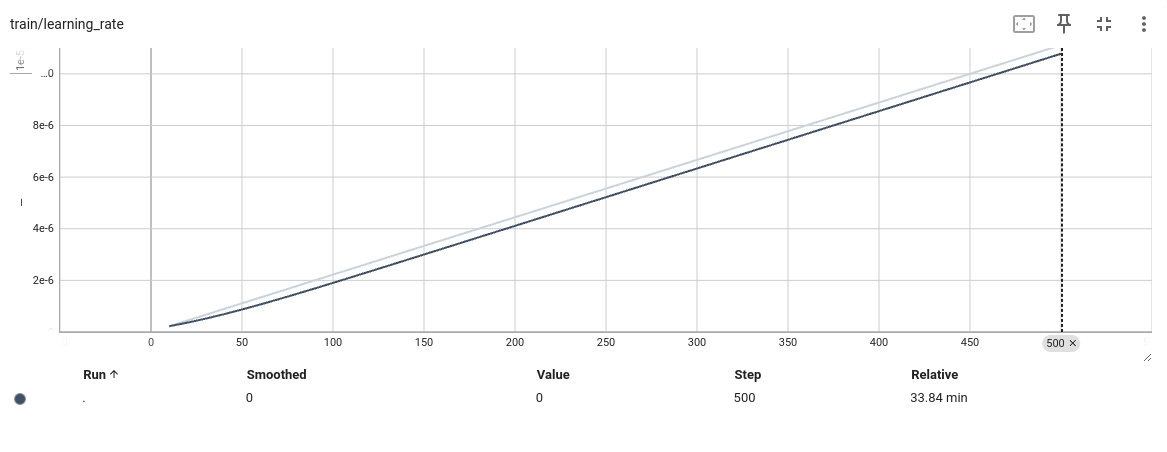
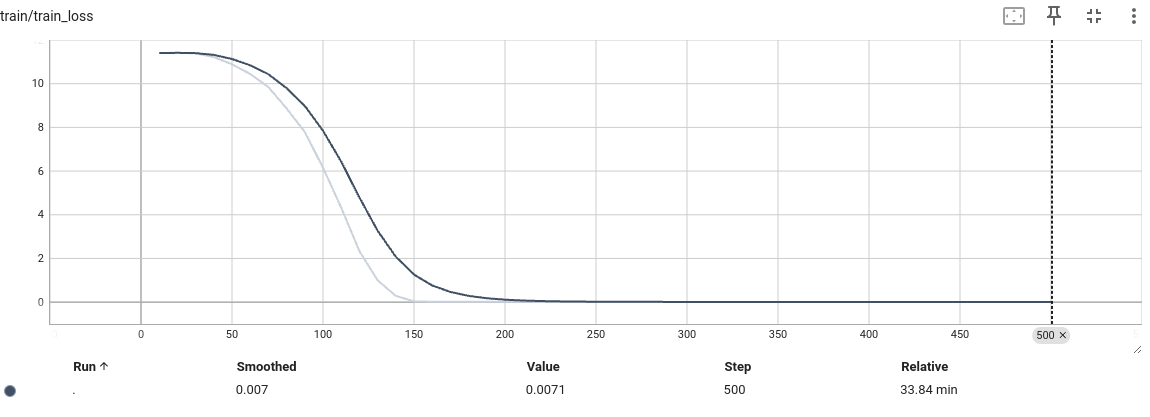
结论:
通过过拟合实验发现,模型的梯度,模型本身应该没有问题,那么问题在哪里还是不知道
- 数据检查
代码在scripts/visualize_libero.py
"""
visualize_libero.py
可视化 LIBERO 数据集中的训练样本。
显示图像、动作值、语言指令等信息。
Usage:
python scripts/visualize_libero.py --dataset libero_spatial_no_noops --num_samples 5
"""
import argparse
from pathlib import Path
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from PIL import Image
def load_tfrecord_dataset(data_root: Path, dataset_name: str, num_samples: int = 5):
"""加载 TFRecord 数据集"""
dataset_path = data_root / dataset_name / "1.0.0"
tfrecord_files = sorted(dataset_path.glob("libero_spatial-train.tfrecord-*"))
if not tfrecord_files:
raise FileNotFoundError(f"No tfrecord files found in {dataset_path}")
dataset = tf.data.TFRecordDataset(tfrecord_files)
# 解析 example - 扁平化结构
def parse_example(example):
return tf.io.parse_single_example(
example,
{
"steps/is_first": tf.io.VarLenFeature(tf.int64),
"steps/action": tf.io.VarLenFeature(tf.float32),
"steps/discount": tf.io.VarLenFeature(tf.float32),
"steps/is_last": tf.io.VarLenFeature(tf.int64),
"steps/language_instruction": tf.io.VarLenFeature(tf.string),
"steps/observation/wrist_image": tf.io.VarLenFeature(tf.string),
"steps/reward": tf.io.VarLenFeature(tf.float32),
"steps/is_terminal": tf.io.VarLenFeature(tf.int64),
"steps/observation/state": tf.io.VarLenFeature(tf.float32),
"steps/observation/joint_state": tf.io.VarLenFeature(tf.float32),
"steps/observation/image": tf.io.VarLenFeature(tf.string),
}
)
parsed_dataset = dataset.map(parse_example)
return parsed_dataset
def visualize_sample(sample, sample_idx=0):
"""可视化单个样本"""
print(f"\n=== Sample {sample_idx} ===")
# 获取基本数据
actions = tf.sparse.to_dense(sample["steps/action"]).numpy()
states = tf.sparse.to_dense(sample["steps/observation/state"]).numpy()
images = tf.sparse.to_dense(sample["steps/observation/image"]).numpy()
wrist_images = tf.sparse.to_dense(sample["steps/observation/wrist_image"]).numpy()
instructions = tf.sparse.to_dense(sample["steps/language_instruction"])
num_elements = actions.shape[0]
action_dim = 7
state_dim = 8
# 扁平化数据,需要重新计算步数
num_steps = num_elements // action_dim
actions = actions[:num_steps * action_dim].reshape(num_steps, action_dim)
states = states[:num_steps * state_dim].reshape(num_steps, state_dim)
# images 和 wrist_images 每个step一张,不需要reshape
num_images = images.shape[0]
wrist_images = wrist_images[:num_steps] # 截取到num_steps
images = images[:num_steps]
print(f"Number of steps: {num_steps}")
print(f"Actions shape: {actions.shape}")
print(f"States shape: {states.shape}")
print(f"Number of images: {images.shape[0]}")
# 解析 language instruction
lang_instr = instructions[0].numpy().decode('utf-8') if len(instructions) > 0 else ""
print(f"Language instruction: {lang_instr}")
# 平均采样4个点
num_plot_points = 4
sample_indices = np.linspace(0, num_steps - 1, num_plot_points, dtype=int)
print(f"Sampled indices: {sample_indices}")
# 创建图像 + 动作图一起显示 (4行4列)
fig = plt.figure(figsize=(16, 12))
# 第一行:显示4张图像
for i, idx in enumerate(sample_indices):
ax_img = fig.add_subplot(4, 4, i + 1)
img = tf.io.decode_image(images[idx]).numpy()
ax_img.imshow(img)
ax_img.set_title(f"Image Step {idx}")
ax_img.axis('off')
# 第二行:手腕图像
ax_wrist = fig.add_subplot(4, 4, i + 5)
wrist = tf.io.decode_image(wrist_images[idx]).numpy()
ax_wrist.imshow(wrist)
ax_wrist.set_title(f"Wrist Step {idx}")
ax_wrist.axis('off')
# 第三行和第四行:动作曲线
action_names = ['base_x', 'base_y', 'base_z', 'base_rz', 'base_ry', 'base_rx', 'gripper']
for i in range(7):
ax = fig.add_subplot(4, 4, i + 9)
ax.plot(sample_indices, actions[sample_indices, i], 'o-', markersize=8)
ax.set_title(f"{action_names[i]}")
ax.set_xlabel("Step")
ax.set_ylabel("Value")
ax.set_xticks(sample_indices)
ax.set_xticklabels([str(idx) for idx in sample_indices])
ax.grid(True)
# 最后一个位置留空或显示额外信息
ax_info = fig.add_subplot(4, 4, 16)
ax_info.text(0.5, 0.5, f"Task: {lang_instr[:50]}...", ha='center', va='center', fontsize=10, wrap=True)
ax_info.axis('off')
plt.suptitle(f"Sample {sample_idx}", fontsize=14)
plt.tight_layout()
plt.savefig(f"sample_{sample_idx}_combined.png", dpi=100)
print(f"Saved sample_{sample_idx}_combined.png")
plt.close()
return {
"actions": actions,
"states": states,
"language_instruction": lang_instr,
}
def main():
parser = argparse.ArgumentParser(description="Visualize LIBERO dataset samples")
parser.add_argument("--data_root", type=str, default="/home/vcar/LIBERO/modified_libero_rlds")
parser.add_argument("--dataset", type=str, default="libero_spatial_no_noops",
choices=["libero_spatial_no_noops", "libero_object_no_noops",
"libero_goal_no_noops", "libero_10_no_noops"])
parser.add_argument("--num_samples", type=int, default=3, help="Number of samples to visualize")
parser.add_argument("--num_frames", type=int, default=5, help="Number of frames to show per sample")
args = parser.parse_args()
data_root = Path(args.data_root)
dataset = load_tfrecord_dataset(data_root, args.dataset, args.num_samples)
print(f"Loaded dataset: {args.dataset}")
print(f"Data root: {data_root}")
print(f"Number of samples to visualize: {args.num_samples}")
for i, sample in enumerate(dataset.take(args.num_samples)):
try:
data = visualize_sample(sample, i)
if data is not None:
print(f"\nActions shape: {data['actions'].shape}")
print(f"States shape: {data['states'].shape}")
except Exception as e:
print(f"Error processing sample {i}: {e}")
import traceback
traceback.print_exc()
print("\n=== Visualization complete! ===")
print("Check current directory for saved PNG files.")
if __name__ == "__main__":
main()
结果如下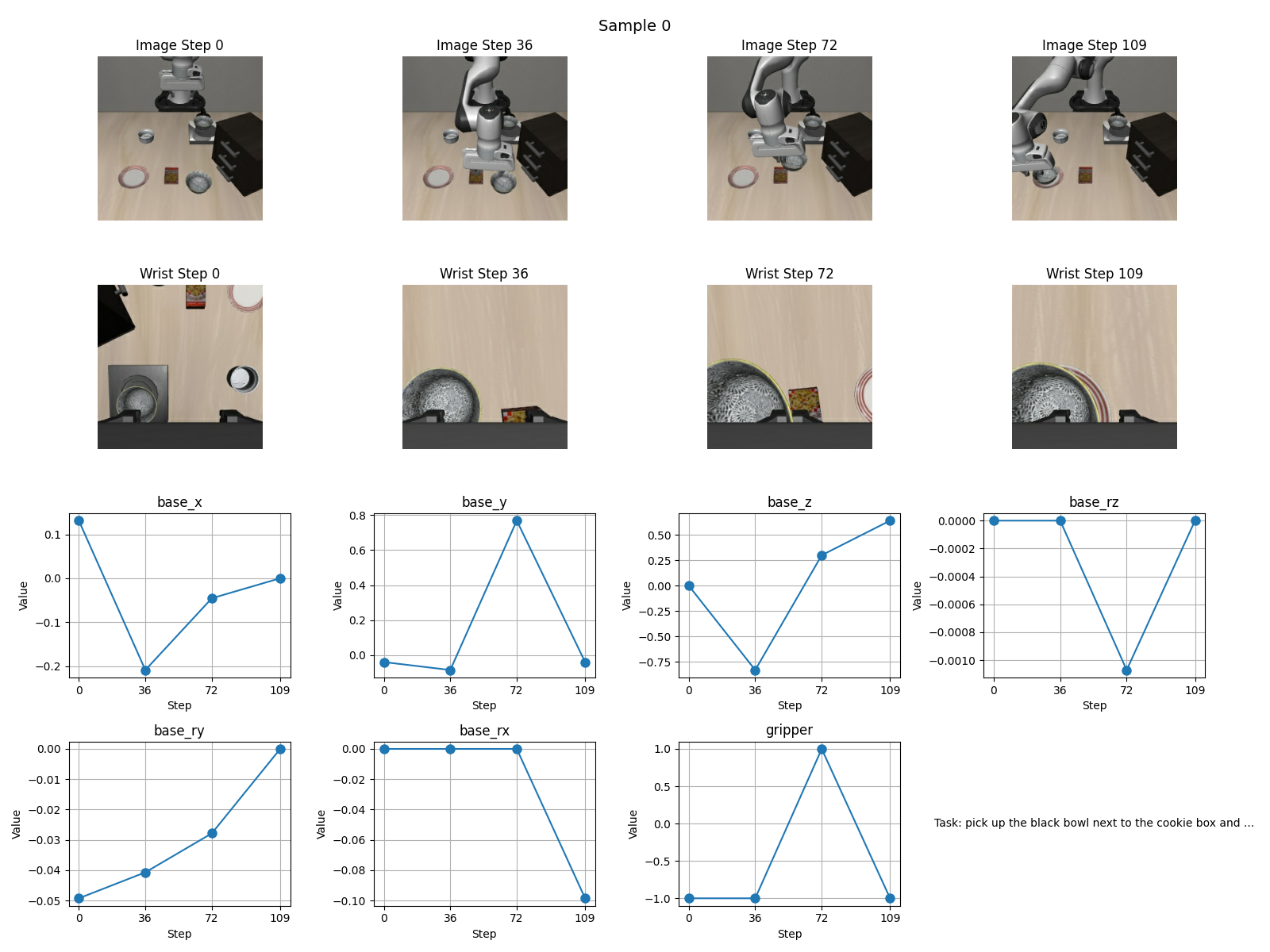
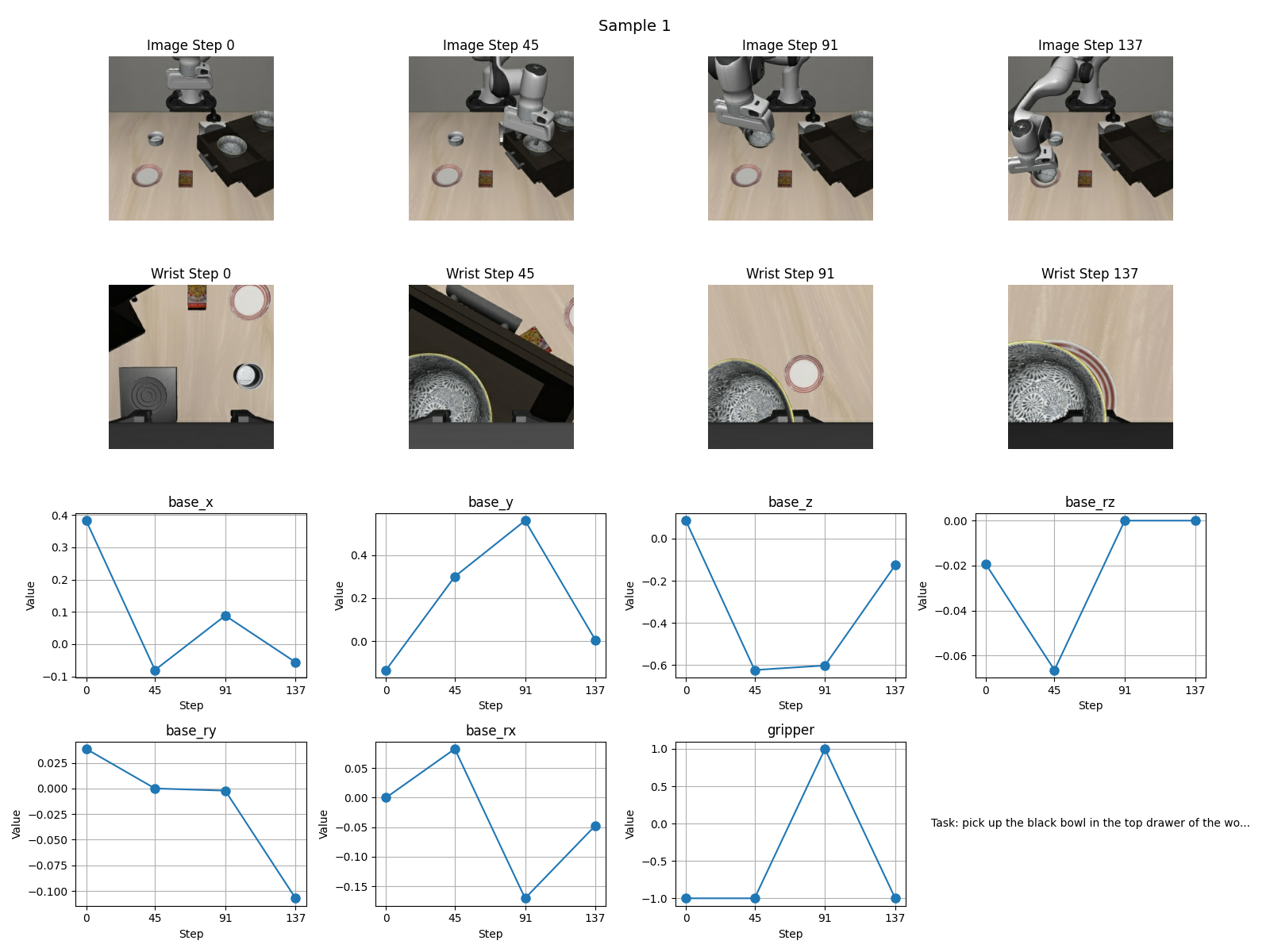
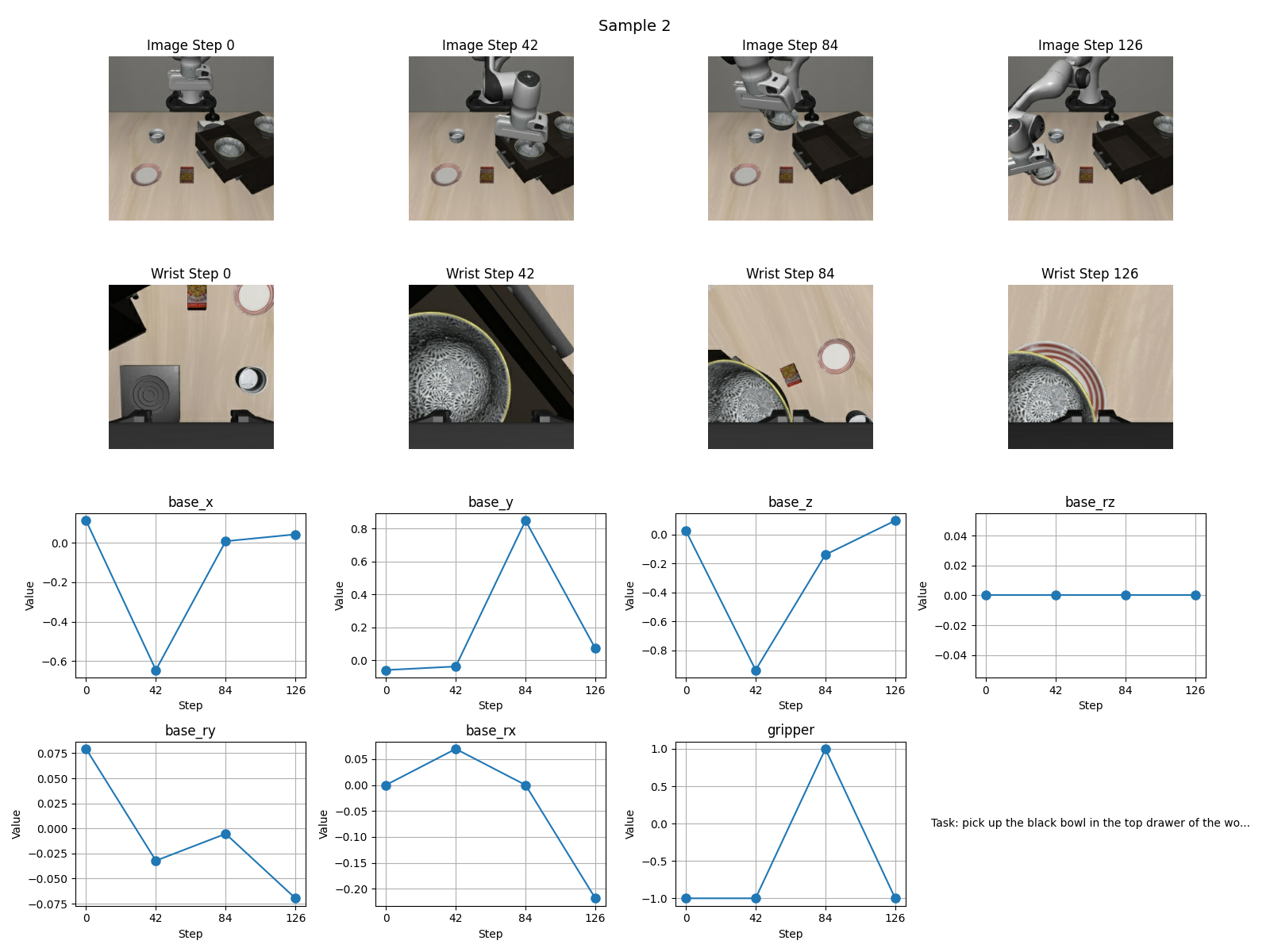
可视化数据来看应该没什么问题,通过看官方的github的md文档,发现我的学习率比官方小了一个数量级,因此开始实验2
实验2
cfg = FinetuneConfig(
vla_path="openvla/openvla-7b",
data_root_dir=Path("/home/vcar/LIBERO/modified_libero_rlds"),
dataset_name="libero_spatial_no_noops",
run_root_dir=Path("./runs"),
adapter_tmp_dir=Path("./adapter-tmp"),
batch_size=2,
max_steps=30000,
save_steps=3000,
learning_rate=5e-4,
grad_accumulation_steps=16,
image_aug=True,
shuffle_buffer_size=100_00,
save_latest_checkpoint_only=True,
use_lora=True,
lora_rank=32,
lora_dropout=0.0,
use_quantization=False,
wandb_project="openvla-libero",
wandb_entity="YOUR_ENTITY",
use_wandb=False,
run_id_note=None,
)
这样配置的原因,观察上面实验一发现在6000步左右,loss就不在下降,怀疑是学习率太小,同时增大grad_accumulation_steps,近似增大batch size到32,增加梯度下降的稳定性,增加了grad_accumulation_steps后发现,模型训练时间大幅提高,在3090上跑了快三天o(╥﹏╥)o,不过结果是好的
- 结果
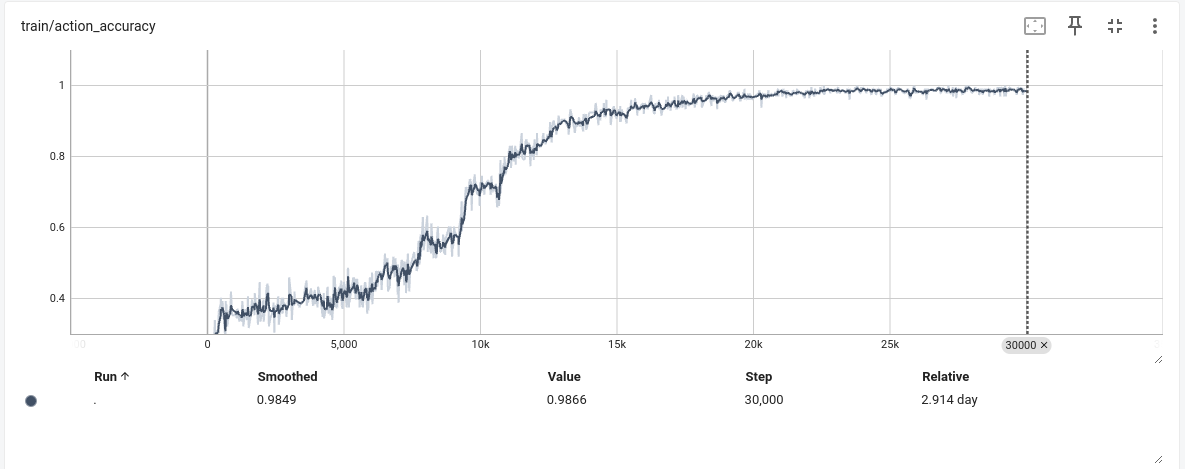
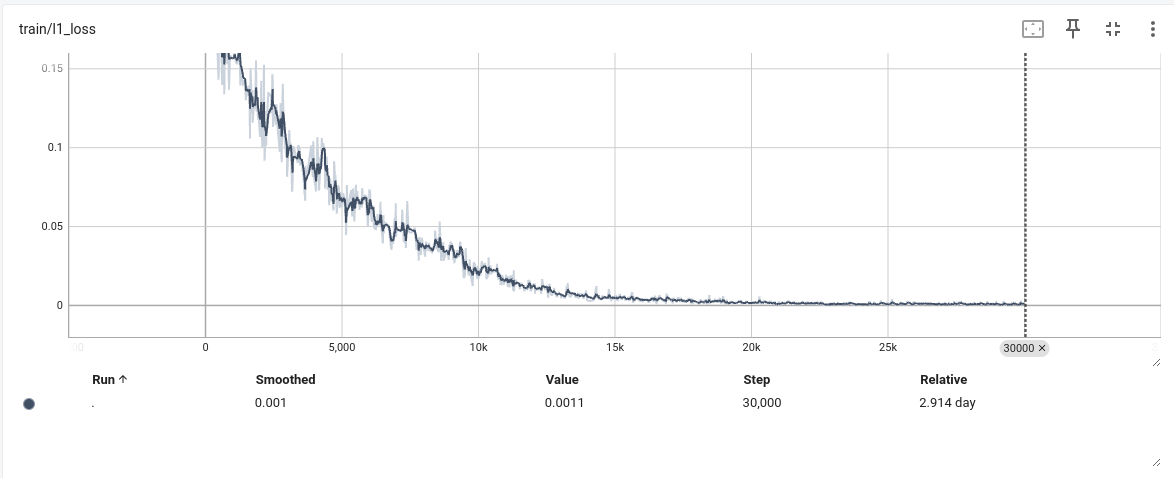
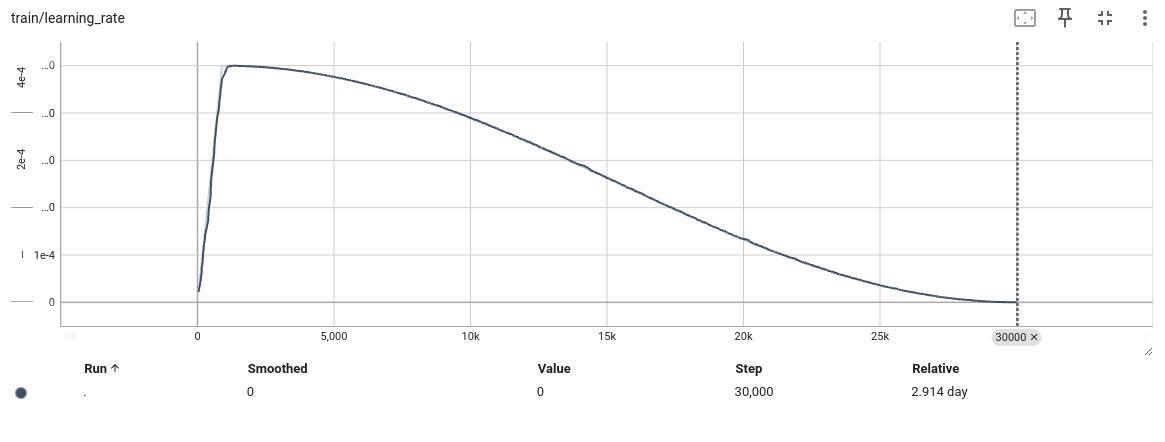
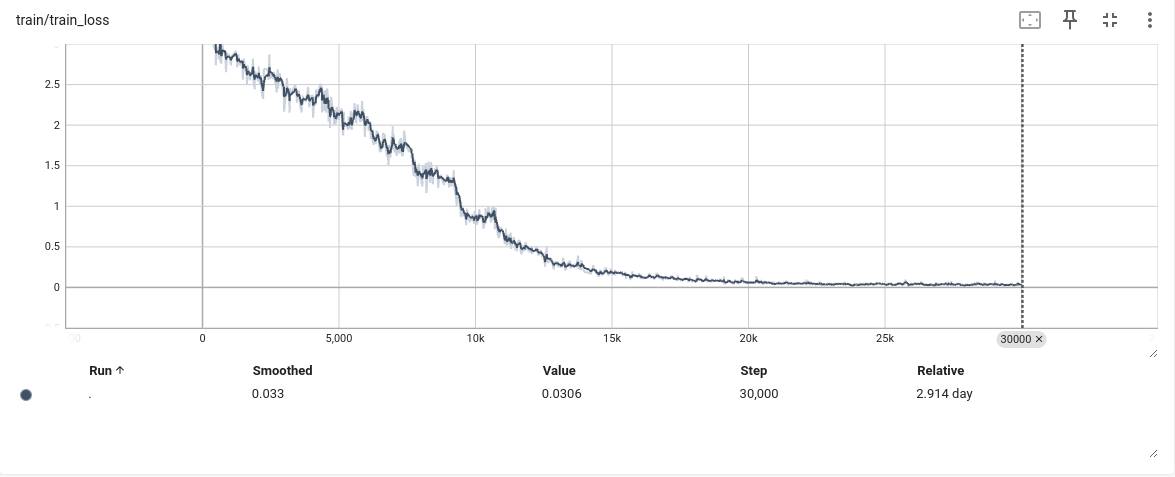
- 结论
发现训练指标在20k左右就基本不在变化了,因此感觉后期训练可以在相同配置下,将step步数减小,以加快训练速度
后续统计
通过统计发现总体成功率在81%左右,但是任务pick_up_the_black_bowl_on_the_ramekin_and_place_it任务成功率只有20%不知道为什么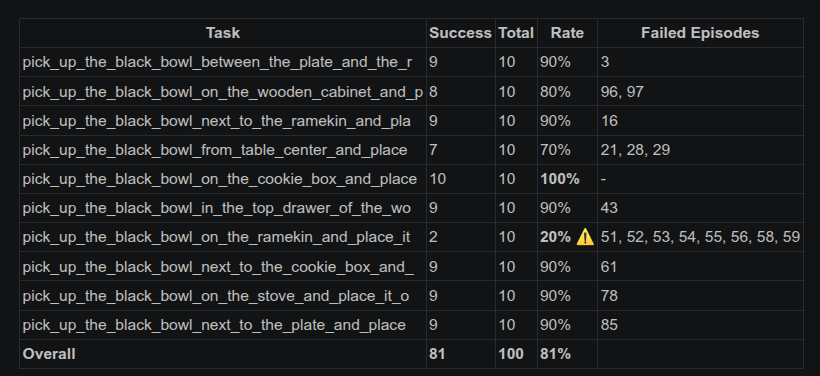
这里插入一失败个视频
2026_06_08-09_07_32
通过视频无法清楚看到夹爪到底是横向不到位还是纵向不到位,因此在官方的代码中新增了计算夹爪和目标之间距离的打印
"""
run_libero_eval.py
Runs a model in a LIBERO simulation environment.
Usage:
# OpenVLA:
# IMPORTANT: Set `center_crop=True` if model is fine-tuned with augmentations
python experiments/robot/libero/run_libero_eval.py \
--model_family openvla \
--pretrained_checkpoint <CHECKPOINT_PATH> \
--task_suite_name [ libero_spatial | libero_object | libero_goal | libero_10 | libero_90 ] \
--center_crop [ True | False ] \
--run_id_note <OPTIONAL TAG TO INSERT INTO RUN ID FOR LOGGING> \
--use_wandb [ True | False ] \
--wandb_project <PROJECT> \
--wandb_entity <ENTITY>
"""
import os
import sys
from dataclasses import dataclass
from pathlib import Path
from typing import Optional, Union
import draccus
import numpy as np
import tqdm
from libero.libero import benchmark
import wandb
# Append current directory so that interpreter can find experiments.robot
sys.path.append("../..")
from experiments.robot.libero.libero_utils import (
get_libero_dummy_action,
get_libero_env,
get_libero_image,
quat2axisangle,
save_rollout_video,
)
from experiments.robot.openvla_utils import get_processor
from experiments.robot.robot_utils import (
DATE_TIME,
get_action,
get_image_resize_size,
get_model,
invert_gripper_action,
normalize_gripper_action,
set_seed_everywhere,
)
@dataclass
class GenerateConfig:
# fmt: off
#################################################################################################################
# Model-specific parameters
#################################################################################################################
model_family: str = "openvla" # Model family
pretrained_checkpoint: Union[str, Path] = "" # Pretrained checkpoint path
load_in_8bit: bool = False # (For OpenVLA only) Load with 8-bit quantization
load_in_4bit: bool = False # (For OpenVLA only) Load with 4-bit quantization
center_crop: bool = True # Center crop? (if trained w/ random crop image aug)
#################################################################################################################
# LIBERO environment-specific parameters
#################################################################################################################
task_suite_name: str = "libero_spatial" # Task suite. Options: libero_spatial, libero_object, libero_goal, libero_10, libero_90
num_steps_wait: int = 10 # Number of steps to wait for objects to stabilize in sim
num_trials_per_task: int = 50 # Number of rollouts per task
#################################################################################################################
# Utils
#################################################################################################################
run_id_note: Optional[str] = None # Extra note to add in run ID for logging
local_log_dir: str = "./experiments/logs" # Local directory for eval logs
use_wandb: bool = False # Whether to also log results in Weights & Biases
wandb_project: str = "YOUR_WANDB_PROJECT" # Name of W&B project to log to (use default!)
wandb_entity: str = "YOUR_WANDB_ENTITY" # Name of entity to log under
seed: int = 7 # Random Seed (for reproducibility)
# fmt: on
@draccus.wrap()
def eval_libero(cfg: GenerateConfig) -> None:
assert cfg.pretrained_checkpoint is not None, "cfg.pretrained_checkpoint must not be None!"
if "image_aug" in cfg.pretrained_checkpoint:
assert cfg.center_crop, "Expecting `center_crop==True` because model was trained with image augmentations!"
assert not (cfg.load_in_8bit and cfg.load_in_4bit), "Cannot use both 8-bit and 4-bit quantization!"
# Set random seed
set_seed_everywhere(cfg.seed)
# [OpenVLA] Set action un-normalization key
cfg.unnorm_key = cfg.task_suite_name
# Load model
model = get_model(cfg)
# [OpenVLA] Check that the model contains the action un-normalization key
if cfg.model_family == "openvla":
# In some cases, the key must be manually modified (e.g. after training on a modified version of the dataset
# with the suffix "_no_noops" in the dataset name)
if cfg.unnorm_key not in model.norm_stats and f"{cfg.unnorm_key}_no_noops" in model.norm_stats:
cfg.unnorm_key = f"{cfg.unnorm_key}_no_noops"
assert cfg.unnorm_key in model.norm_stats, f"Action un-norm key {cfg.unnorm_key} not found in VLA `norm_stats`!"
# [OpenVLA] Get Hugging Face processor
processor = None
if cfg.model_family == "openvla":
processor = get_processor(cfg)
# Initialize local logging
run_id = f"EVAL-{cfg.task_suite_name}-{cfg.model_family}-{DATE_TIME}"
if cfg.run_id_note is not None:
run_id += f"--{cfg.run_id_note}"
os.makedirs(cfg.local_log_dir, exist_ok=True)
local_log_filepath = os.path.join(cfg.local_log_dir, run_id + ".txt")
log_file = open(local_log_filepath, "w")
print(f"Logging to local log file: {local_log_filepath}")
# Initialize Weights & Biases logging as well
if cfg.use_wandb:
wandb.init(
entity=cfg.wandb_entity,
project=cfg.wandb_project,
name=run_id,
)
# Initialize LIBERO task suite
benchmark_dict = benchmark.get_benchmark_dict()
task_suite = benchmark_dict[cfg.task_suite_name]()
num_tasks_in_suite = task_suite.n_tasks
print(f"Task suite: {cfg.task_suite_name}")
log_file.write(f"Task suite: {cfg.task_suite_name}\n")
# Get expected image dimensions
resize_size = get_image_resize_size(cfg)
# Start evaluation
total_episodes, total_successes = 0, 0
for task_id in tqdm.tqdm(range(num_tasks_in_suite)):
# Get task
task = task_suite.get_task(task_id)
# Get default LIBERO initial states
initial_states = task_suite.get_task_init_states(task_id)
# Initialize LIBERO environment and task description
env, task_description = get_libero_env(task, cfg.model_family, resolution=256)
if task_description != "pick up the black bowl on the ramekin and place it on the plate":
continue
# else:
# task_description = "pick up the black bowl from the ramekin and place it on the plate"
# Start episodes
task_episodes, task_successes = 0, 0
for episode_idx in tqdm.tqdm(range(cfg.num_trials_per_task)):
print(f"\nTask: {task_description}")
log_file.write(f"\nTask: {task_description}\n")
# Reset environment
env.reset()
# Set initial states
obs = env.set_init_state(initial_states[episode_idx])
# Setup
t = 0
replay_images = []
if cfg.task_suite_name == "libero_spatial":
max_steps = 220 # longest training demo has 193 steps
elif cfg.task_suite_name == "libero_object":
max_steps = 280 # longest training demo has 254 steps
elif cfg.task_suite_name == "libero_goal":
max_steps = 300 # longest training demo has 270 steps
elif cfg.task_suite_name == "libero_10":
max_steps = 520 # longest training demo has 505 steps
elif cfg.task_suite_name == "libero_90":
max_steps = 400 # longest training demo has 373 steps
print(f"Starting episode {task_episodes+1}...")
log_file.write(f"Starting episode {task_episodes+1}...\n")
# 创建调试文件(每个视频一个txt)
debug_filename = f"rollouts/{run_id}/episode_{episode_idx+1}_debug.txt"
os.makedirs(os.path.dirname(debug_filename), exist_ok=True)
debug_file = open(debug_filename, "w")
debug_file.write(f"Episode {episode_idx+1} Debug Log\n")
debug_file.write(f"Task: {task_description}\n")
while t < max_steps + cfg.num_steps_wait:
try:
# IMPORTANT: Do nothing for the first few timesteps because the simulator drops objects
# and we need to wait for them to fall
if t < cfg.num_steps_wait:
obs, reward, done, info = env.step(get_libero_dummy_action(cfg.model_family))
t += 1
continue
# Get preprocessed image
img = get_libero_image(obs, resize_size)
# Save preprocessed image for replay video
replay_images.append(img)
# Prepare observations dict
# Note: OpenVLA does not take proprio state as input
observation = {
"full_image": img,
"state": np.concatenate(
(obs["robot0_eef_pos"], quat2axisangle(obs["robot0_eef_quat"]), obs["robot0_gripper_qpos"])
),
}
# Query model to get action
action = get_action(
cfg,
model,
observation,
task_description,
processor=processor,
)
# 伪代码示例:在 eval 循环中打印最后阶段的控制命令
# Normalize gripper action [0,1] -> [-1,+1] because the environment expects the latter
origin_grip_action = float(action[..., -1].copy())
action = normalize_gripper_action(action, binarize=True)
if t > 20: # 假设动作进行到中后期,机械臂已经靠近物体
# 获取机械臂夹爪位置
gripper_pos = obs["robot0_eef_pos"]
# 获取两个黑碗的位置
bowl1_pos = env.sim.data.get_body_xpos("akita_black_bowl_1_main")
bowl2_pos = env.sim.data.get_body_xpos("akita_black_bowl_2_main")
# 计算两个碗到机械臂的距离
dist1 = (
(gripper_pos[0] - bowl1_pos[0]) ** 2
+ (gripper_pos[1] - bowl1_pos[1]) ** 2
+ (gripper_pos[2] - bowl1_pos[2]) ** 2
) ** 0.5
dist2 = (
(gripper_pos[0] - bowl2_pos[0]) ** 2
+ (gripper_pos[1] - bowl2_pos[1]) ** 2
+ (gripper_pos[2] - bowl2_pos[2]) ** 2
) ** 0.5
dist1_cm = dist1 * 100
dist2_cm = dist2 * 100
debug_info = f"Step {t}: gripper=({gripper_pos[0]:.4f},{gripper_pos[1]:.4f},{gripper_pos[2]:.4f}) | bowl1=({bowl1_pos[0]:.4f},{bowl1_pos[1]:.4f},{bowl1_pos[2]:.4f}) dist1={dist1_cm:.2f}cm | bowl2=({bowl2_pos[0]:.4f},{bowl2_pos[1]:.4f},{bowl2_pos[2]:.4f}) dist2={dist2_cm:.2f}cm | gripper={action[-1]:.2f}| origin_gripper={origin_grip_action:.2f}"
print(debug_info)
debug_file.write(debug_info + "\n")
debug_file.flush()
# [OpenVLA] The dataloader flips the sign of the gripper action to align with other datasets
# (0 = close, 1 = open), so flip it back (-1 = open, +1 = close) before executing the action
if cfg.model_family == "openvla":
action = invert_gripper_action(action)
# Execute action in environment
obs, reward, done, info = env.step(action.tolist())
if done:
task_successes += 1
total_successes += 1
break
t += 1
except Exception as e:
print(f"Caught exception: {e}")
log_file.write(f"Caught exception: {e}\n")
debug_file.write(f"Exception: {e}\n")
debug_file.close()
break
task_episodes += 1
total_episodes += 1
# 关闭调试文件
debug_file.write(f"\nEpisode {episode_idx+1} finished. Success: {done}\n")
debug_file.close()
# Save a replay video of the episode
save_rollout_video(
replay_images, total_episodes, success=done, task_description=task_description, log_file=log_file
)
# Log current results
print(f"Success: {done}")
print(f"# episodes completed so far: {total_episodes}")
print(f"# successes: {total_successes} ({total_successes / total_episodes * 100:.1f}%)")
log_file.write(f"Success: {done}\n")
log_file.write(f"# episodes completed so far: {total_episodes}\n")
log_file.write(f"# successes: {total_successes} ({total_successes / total_episodes * 100:.1f}%)\n")
log_file.flush()
# Log final results
print(f"Current task success rate: {float(task_successes) / float(task_episodes)}")
print(f"Current total success rate: {float(total_successes) / float(total_episodes)}")
log_file.write(f"Current task success rate: {float(task_successes) / float(task_episodes)}\n")
log_file.write(f"Current total success rate: {float(total_successes) / float(total_episodes)}\n")
log_file.flush()
if cfg.use_wandb:
wandb.log(
{
f"success_rate/{task_description}": float(task_successes) / float(task_episodes),
f"num_episodes/{task_description}": task_episodes,
}
)
# Save local log file
log_file.close()
# Push total metrics and local log file to wandb
if cfg.use_wandb:
wandb.log(
{
"success_rate/total": float(total_successes) / float(total_episodes),
"num_episodes/total": total_episodes,
}
)
wandb.save(local_log_filepath)
if __name__ == "__main__":
eval_libero()
其会在rollouts中生成对应的输出文档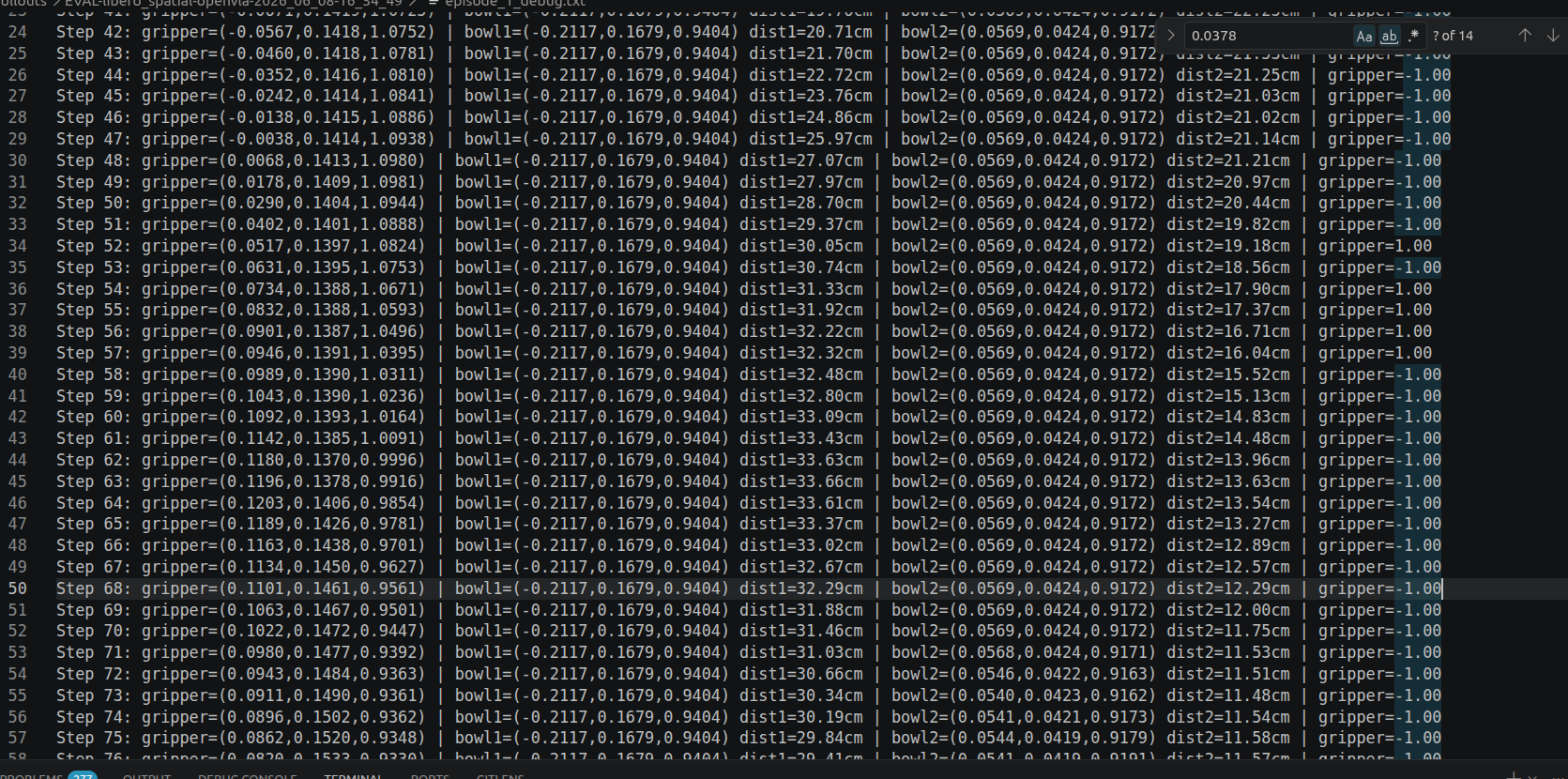
具体的统计结果如下在 LIBERO 中,gripper = 1.00 代表夹爪完全张开,gripper = -1.00 代表下达闭合命令。我们来看这 10 个文件里,模型第一次把夹爪抠下去(或者无限接近闭合)的那一帧: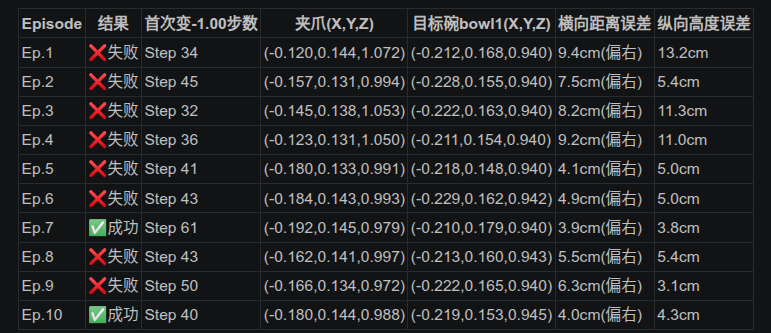
通过统计机械臂和bowl的位置发现,xy和z轴都没运动到位,夹爪就闭合了,但是夹爪知道往目标方向移动
:
"""加载 TFRecord 数据集"""
dataset_path = data_root / dataset_name / "1.0.0"
tfrecord_files = sorted(dataset_path.glob("libero_spatial-train.tfrecord-*"))
if not tfrecord_files:
raise FileNotFoundError(f"No tfrecord files found in {dataset_path}")
dataset = tf.data.TFRecordDataset(tfrecord_files)
# 解析 example - 扁平化结构
def parse_example(example):
return tf.io.parse_single_example(
example,
{
"steps/is_first": tf.io.VarLenFeature(tf.int64),
"steps/action": tf.io.VarLenFeature(tf.float32),
"steps/discount": tf.io.VarLenFeature(tf.float32),
"steps/is_last": tf.io.VarLenFeature(tf.int64),
"steps/language_instruction": tf.io.VarLenFeature(tf.string),
"steps/observation/wrist_image": tf.io.VarLenFeature(tf.string),
"steps/reward": tf.io.VarLenFeature(tf.float32),
"steps/is_terminal": tf.io.VarLenFeature(tf.int64),
"steps/observation/state": tf.io.VarLenFeature(tf.float32),
"steps/observation/joint_state": tf.io.VarLenFeature(tf.float32),
"steps/observation/image": tf.io.VarLenFeature(tf.string),
}
)
parsed_dataset = dataset.map(parse_example)
return parsed_dataset
def analyze_training_gripper(
dataset_name: str = "libero_spatial_no_noops",
data_root: str = "/home/vcar/LIBERO/modified_libero_rlds",
):
"""分析训练数据中夹爪关闭的时机"""
data_root = Path(data_root)
dataset = load_tfrecord_dataset(data_root, dataset_name)
print(f"Dataset: {dataset_name}")
print(f"Data root: {data_root}")
gripper_close_steps = [] # 每个trajectory第一次关闭夹爪的step
trajectory_lengths = [] # 每个trajectory的长度
total_trajectories = 0
print("Processing trajectories...")
for i, sample in enumerate(dataset):
# 获取动作数据
actions = tf.sparse.to_dense(sample["steps/action"]).numpy()
instructions = tf.sparse.to_dense(sample["steps/language_instruction"])
num_elements = actions.shape[0]
action_dim = 7
num_steps = num_elements // action_dim
# Reshape actions: [num_steps, 7]
actions = actions[:num_steps * action_dim].reshape(num_steps, action_dim)
# Gripper action is the last dimension (index 6)
# In RLDS format: -1 = close, 1 = open
gripper_actions = actions[:, 6]
# 找到第一个从张开变成闭合的step
# gripper从1(张开)变成-1(闭合)
first_close_step = None
prev_gripper = gripper_actions[0]
for step_idx in range(1, len(gripper_actions)):
curr_gripper = gripper_actions[step_idx]
# 之前是张开(1),现在变成闭合(-1)
print(prev_gripper)
print(curr_gripper)
if prev_gripper > 0 and curr_gripper < 0:
first_close_step = step_idx
break
prev_gripper = curr_gripper
if first_close_step is not None:
gripper_close_steps.append(first_close_step)
trajectory_lengths.append(num_steps)
# 打印一些样本
if first_close_step is not None and first_close_step < 20:
lang_instr = instructions[0].numpy().decode('utf-8')
print(f"Trajectory {i}: steps={num_steps}, "
f"first_close=Step {first_close_step}, "
f"lang={lang_instr[:50]}...")
total_trajectories += 1
if total_trajectories % 500 == 0:
print(f"Processed {total_trajectories} trajectories...")
# Statistics
print("\n" + "=" * 80)
print("统计结果")
print("=" * 80)
if gripper_close_steps:
gripper_close_steps = np.array(gripper_close_steps)
trajectory_lengths = np.array(trajectory_lengths)
print(f"\n总轨迹数: {total_trajectories}")
print(f"有夹爪关闭动作的轨迹数: {len(gripper_close_steps)}")
print(f"\n第一次关闭夹爪的step统计:")
print(f" 平均值: {np.mean(gripper_close_steps):.1f}")
print(f" 中位数: {np.median(gripper_close_steps):.1f}")
print(f" 标准差: {np.std(gripper_close_steps):.1f}")
print(f" 最小值: {np.min(gripper_close_steps)}")
print(f" 最大值: {np.max(gripper_close_steps)}")
print(f"\n分位数:")
for p in [10, 25, 50, 75, 90]:
val = np.percentile(gripper_close_steps, p)
print(f" {p}%: Step {val:.0f}")
# Distribution
print(f"\n分布:")
bins = [0, 20, 40, 60, 80, 100, 150, 200, 300, 1000]
for i in range(len(bins) - 1):
if bins[i + 1] == 1000:
label = f"{bins[i]}+"
else:
label = f"{bins[i]}-{bins[i + 1] - 1}"
count = np.sum(
(gripper_close_steps >= bins[i]) &
(gripper_close_steps < bins[i + 1])
)
pct = count / len(gripper_close_steps) * 100
bar = "#" * int(pct / 2)
print(f" Step {label:>8}: {count:5d} ({pct:5.1f}%) {bar}")
print(f"\n轨迹长度统计:")
print(f" 平均长度: {np.mean(trajectory_lengths):.1f}")
print(f" 中位数长度: {np.median(trajectory_lengths):.1f}")
else:
print("没有找到夹爪关闭动作的数据!")
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Analyze gripper closing timing in training data"
)
parser.add_argument(
"--data_root",
type=str,
default="/home/vcar/LIBERO/modified_libero_rlds",
)
parser.add_argument(
"--dataset",
type=str,
default="libero_spatial_no_noops",
choices=[
"libero_spatial_no_noops",
"libero_object_no_noops",
"libero_goal_no_noops",
"libero_10_no_noops",
],
)
args = parser.parse_args()
analyze_training_gripper(dataset_name=args.dataset, data_root=args.data_root)
结果如下
================================================================================
统计结果
================================================================================
总轨迹数: 432
有夹爪关闭动作的轨迹数: 428
第一次关闭夹爪的step统计:
平均值: 108.3
中位数: 109.0
标准差: 20.3
最小值: 47
最大值: 169
分位数:
10%: Step 82
25%: Step 94
50%: Step 109
75%: Step 123
90%: Step 132
分布:
Step 0-19: 0 ( 0.0%)
Step 20-39: 0 ( 0.0%)
Step 40-59: 6 ( 1.4%)
Step 60-79: 27 ( 6.3%) ###
Step 80-99: 114 ( 26.6%) #############
Step 100-149: 270 ( 63.1%) ###############################
Step 150-199: 11 ( 2.6%) #
Step 200-299: 0 ( 0.0%)
Step 300+: 0 ( 0.0%)
轨迹长度统计:
平均长度: 122.7
中位数长度: 123.0
因此数据问题应该是被排除了
- 为了进一步排查问题
我在推理的时候将
"pick up the black bowl on the ramekin and place it on the plate"
替换成了
"grab up the black bowl on the ramekin and place it on the plate"
"pick up the black bowl near the ramekin and place it on the plate"
"pick up the black bowl that on the ramekin and place it on the plate"
发现成功率依然很低然后我将机械臂的xyz和第一次闭爪的实际画了出来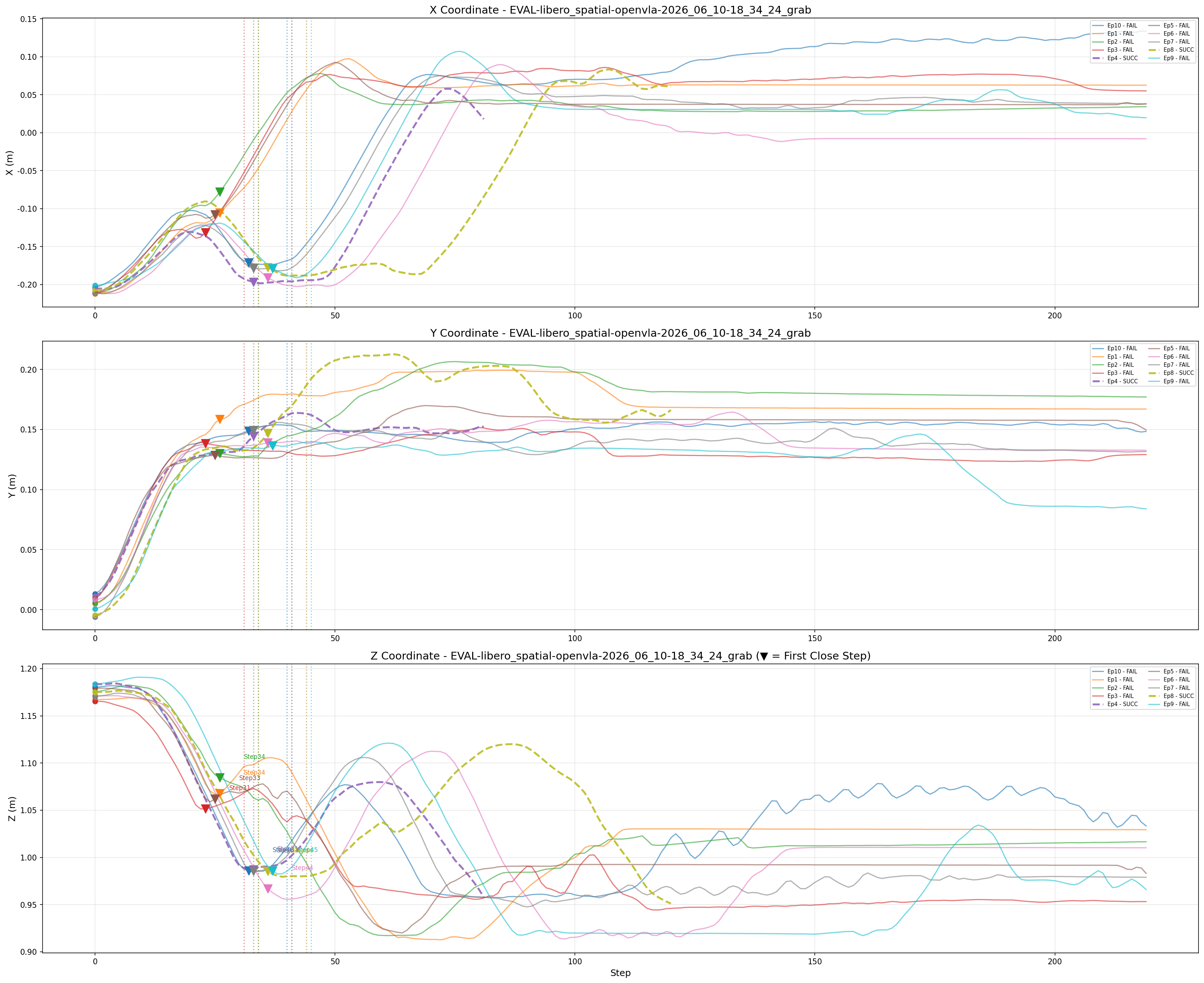
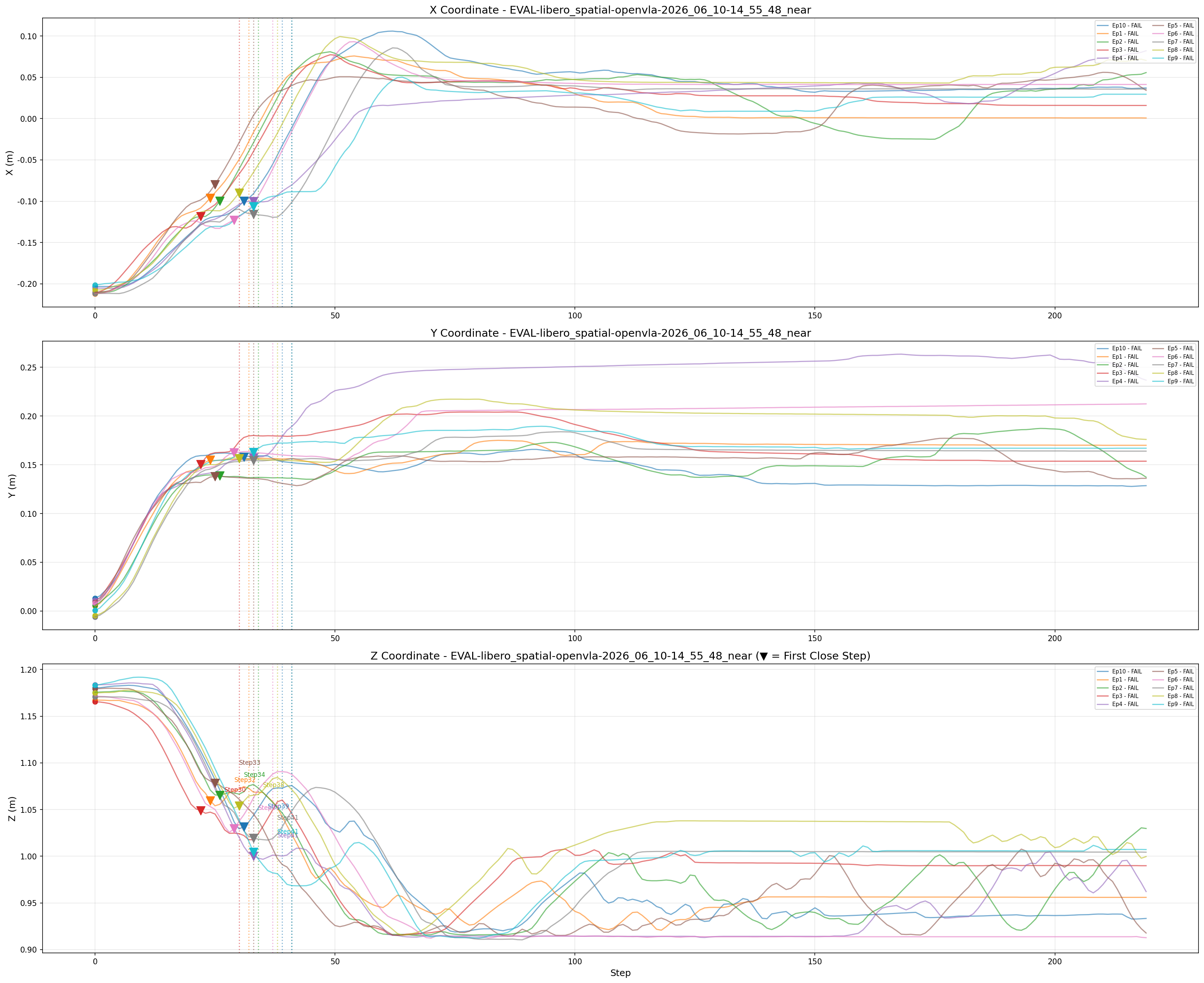
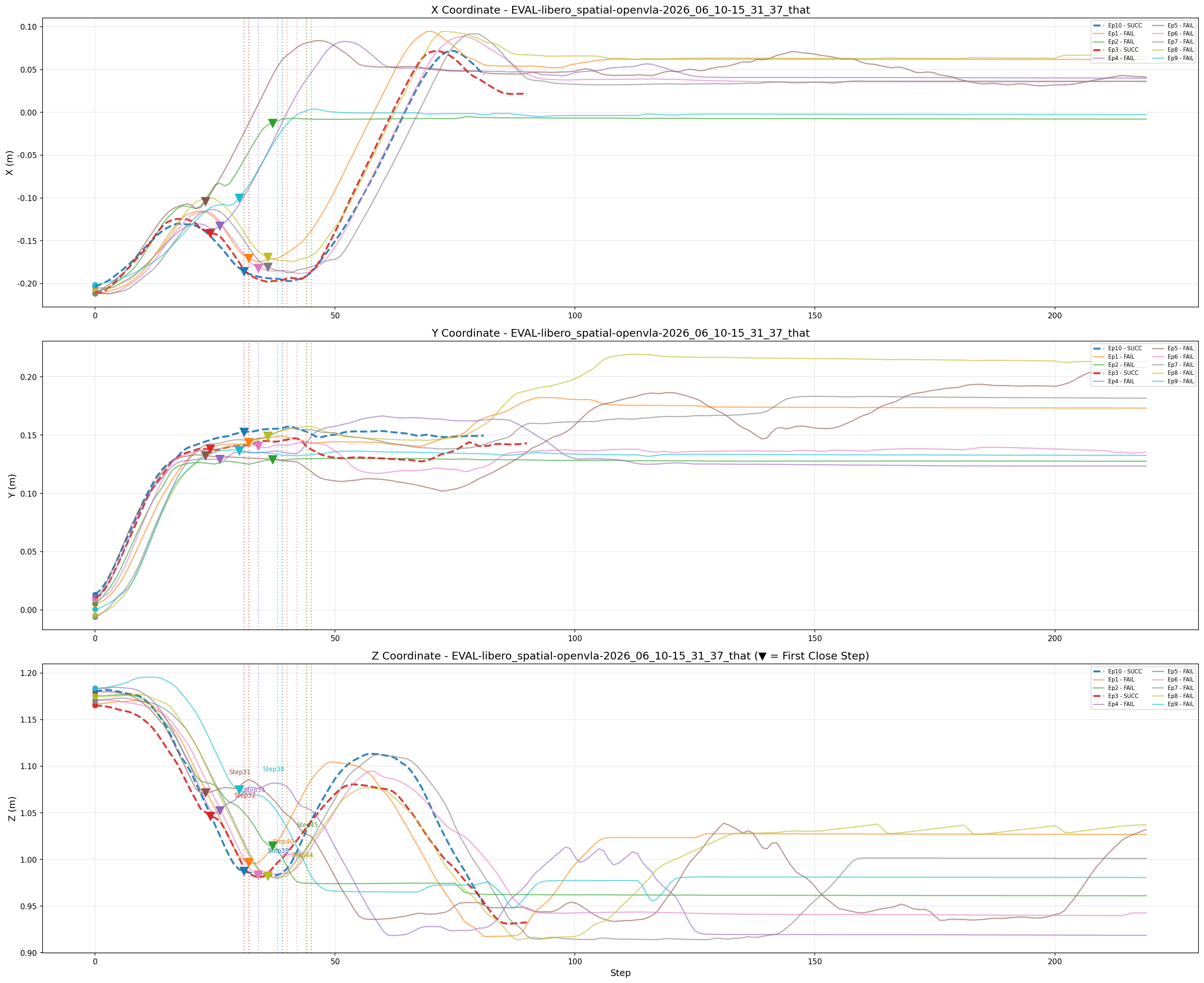
最后发现推理结果发现near全部失败,that和grab都成功两个但是成功具体例子不一样,通过上图可以很明显发现模型无法准确的找到在ramekin上的bowl的位置

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)