COSER: Coordinating LLM-Based Persona Simulation of Established Roles
角色扮演语言智能体已经被用于模拟各种类型的人设,包括人口统计学意义上的群体人物、虚构角色以及日常个体。这类技术也催生了许多应用,例如角色聊天机器人、电子游戏中的智能体,以及人类的数字分身等。本文研究的是面向既定角色的角色扮演语言智能体。相比于简单地描绘个体特征或刻板印象,这是一项更加重要且更具挑战性的任务。具体而言,角色扮演语言智能体需要忠实地对齐角色复杂的背景,并捕捉其细腻的人格特征。为了构建有
摘要
角色扮演语言智能体,即 RPLAs,已经成为大语言模型的一类有前景的应用。然而,对于 RPLA 来说,模拟已经存在的成熟角色仍然是一项具有挑战性的任务。这主要是因为缺乏真实可靠的角色数据集,以及缺乏能够利用这些数据进行细致评价的方法。
在本文中,作者提出了 COSER。COSER 是一个面向成熟角色扮演智能体的完整集合,包括:高质量数据集、开源模型和评价协议
论文介绍
角色扮演语言智能体已经被用于模拟各种类型的人设,包括人口统计学意义上的群体人物、虚构角色以及日常个体。这类技术也催生了许多应用,例如角色聊天机器人、电子游戏中的智能体,以及人类的数字分身等。
本文研究的是面向既定角色的角色扮演语言智能体。相比于简单地描绘个体特征或刻板印象,这是一项更加重要且更具挑战性的任务。具体而言,角色扮演语言智能体需要忠实地对齐角色复杂的背景,并捕捉其细腻的人格特征。
为了构建有效的角色扮演语言智能体,目前仍然存在两个主要挑战:
第一,数据问题。高质量数据集仍然不足。现有数据集通常局限于两个角色之间的对话,缺乏必要的对话上下文以及其他形式的知识。此外,许多数据集是由大语言模型合成的,这会削弱数据的真实性以及对原始角色的忠实程度。
第二,评估问题。现有方法难以评估大语言模型对复杂角色的刻画能力。它们通常关注基于预定义问题集的单轮交互,并依赖大语言模型裁判或多项选择题。前者缺乏细致的区分能力,并且存在偏见问题;后者则只能评估某些特定方面。总体而言,目前缺乏真实的角色数据,也缺乏基于这种真实数据的合适评估方法。
于是本文提出了COSER,包含:
- 真实的角色数据
- 开放的先进模型
- 基于这些数据构建的评估协议
COSER 与现有数据集存在两个根本区别:
- COSER 从经典文学作品中提取真实的多角色对话,而不是像以往工作那样使用大语言模型合成的问答对。因此,保持了较高的源文本忠实度,同时展现出更高的质量和复杂性。
- COSER 包含更加全面的数据类型。如图 1 所示,除了角色画像和对话之外,COSER 还包含情节摘要、角色经历和对话背景。这些数据可以支持多种用途,包括提示构造、检索、模型训练和评估。此外,COSER 中的对话不仅记录角色表层的语言,还捕捉角色的动作和内心想法,使角色扮演语言智能体能够模拟人类更复杂的认知和行为过程。例如:“[我很紧张,但我们必须这样做](深吸一口气)好吧,我们……” 这类表达能够同时体现角色的心理状态、动作和言语

Conversations:一组结构化对话列表。
场景:哈利、罗恩和赫敏决定独自去取回魔法石。
角色动机:我们必须阻止斯内普得到魔法石……
对话内容:[我很紧张,但我们必须这么做](深吸一口气)好吧,就是现在了。你们两个确定要一起去吗?这可能会很危险。
可以看到这里包含三种信息:[内心想法] + (动作) + 角色台词
环境:门打开了,三头犬路威已经睡着了,旁边有一架正在自动演奏的竖琴。
Summary:剧情概括
哈利、罗恩和赫敏穿过活板门去保护魔法石。他们面对了一系列魔法挑战,包括魔鬼网、巨型巫师棋……
Characters' Experiences:角色经历
带领保护魔法石的行动,并在整个过程中展现出勇气……
数据构建流程:
书籍 → 基于 LLM 的处理流程 → 抽取情节和对话数据
基于 COSER 数据集,作者提出了 given-circumstance acting(规定情境表演),给定一个包含消息集合 M、角色集合 C 和场景设定 S 的对话,GCA 要求一个演员大语言模型依次扮演每个角色 c ∈ C,从而重建该对话
在训练阶段,我们训练大语言模型去扮演每个角色 c,并学习该角色在真实对话中的话语 Mc ⊂ M。基于这一过程,我们开发了 COSER 8B 和 COSER 70B。它们构建于 LLaMA-3.1 模型之上,能够展现真实自然的角色刻画能力,并在多个角色扮演语言智能体基准测试中取得当前最先进的表现。
在评估阶段,GCA 包含两个步骤:多智能体模拟和基于惩罚机制的大语言模型评判。给定一个测试对话 M,我们首先创建一个多智能体系统来模拟一个对话 M̄,其中演员大语言模型在相同场景 S 下依次扮演每个角色 c ∈ C;然后,我们使用基于惩罚机制的大语言模型评论员对 M̄ 进行评估,并结合详细评分标准以及原始对话 M。
GCA 评估具有三个优势:
- 它通过多智能体模拟更全面地反映演员大语言模型的能力。
- 它基于真实场景和真实标准对话,而不是人工构造或模型合成的简单问题。
- 它提供了由专家设计的详细评价标准,用于指导大语言模型评论员进行更可靠的评估。
本文的贡献总结如下:
- 我们提出了用于角色扮演语言智能体研究和应用的 COSER 数据集和模型。该数据集包含来自 771 部著名书籍的 29,798 个真实对话以及多种类型的综合数据。基于该数据集,我们开发了 COSER 8B 和 COSER 70B,它们是当前先进的角色扮演语言智能体模型。
- 我们借鉴成熟的表演理论,提出了用于训练和评估角色扮演大语言模型的规定情境表演方法。我们的评估方法通过多角色模拟全面测试演员大语言模型,同时提供原始对话和详细评分标准,以增强基于大语言模型的评价。
- 大量实验结果证明了我们的数据集在角色扮演语言智能体训练、检索和评估中的显著价值。尤其是 COSER 模型在四个角色扮演基准和人工评价中均取得了当前最先进的表现。
相关工作
RPLA 的目标,是利用角色数据 Dc,让大语言模型生成一个能够模拟真实角色 c 的代理人格 πc。
已有 RPLA 数据集的问题:
- 许多数据集是通过大语言模型对通用指令集或特定角色问题的回答合成出来的,例如 RoleBench。然而,由大语言模型合成的数据会削弱数据的真实性,以及其对原始来源的忠实程度。
- 像 CharacterEval 和 CharacterDial 这样的人类标注数据集虽然质量更高,但成本昂贵,并且难以扩展到大规模。
- 也有一些工作从虚构作品中抽取真实对话,例如 ChatHaruhi 和 HPD。然而,这些方法依赖人工对单个来源进行处理,因此同样难以规模化。
- 现有数据集提供的表示和形式较为有限,主要由双角色对话或用户—角色问答对组成。这些数据集可以支持多种用途,包括提示构造、模型训练、检索增强以及 RPLA 评估。
RPLA 评估:
现有评估方法主要基于两类方式:大语言模型裁判,或者多项选择题。
基于大语言模型裁判的方法,通常通过预定义问题来激发模型的角色扮演表现,然后使用大语言模型裁判或奖励模型对其表现进行评分。这些方法评估多个维度,包括与具体角色无关的方面,例如拟人化程度和吸引力;也包括与具体角色相关的特征,例如语言风格、知识和人格。
然而,大语言模型裁判存在固有偏见,例如长度偏见和位置偏见,并且在面向特定角色进行评价时,可能缺乏必要的角色知识。
其他基准则通过多项选择题来评估角色扮演大语言模型,考察某些特定方面,例如知识、决策能力、人格忠实度和特定时间点的人物刻画能力。
COSER 数据集
覆盖了来自 771 部著名书籍的 17,966 个角色的真实数据。
它包含真实的、非合成的对话,这些对话具有现实世界中的复杂性;同时,它还提供了全面的数据表示形式,可以支持多种用途。
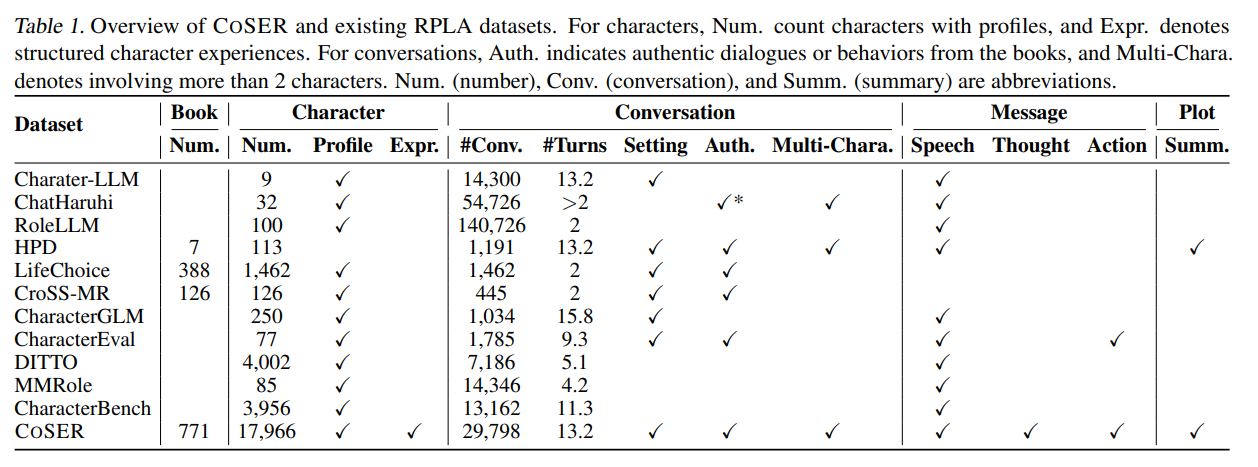
表1对比了COSER 与已有 RPLA 数据集,COSER 在数据规模、数据真实性、数据类型完整性、多角色对话、消息表达维度等方面,比已有角色扮演数据集更全面。
设计原则
COSER 与以往 RPLA 数据集的主要区别体现在三个方面:
- 丰富的数据类型;
- 消息中包含内心想法和身体动作;
- 将环境也视为一种角色。
丰富的数据类型
人格数据 Dc 可以通过多种形式表示虚构作品中的角色 c,例如叙事、角色画像、对话、经历等。以往研究主要关注角色画像和对话,这只能表示有限的知识。因此,我们提出了一组更加全面的数据类型。这些数据类型具有三个特点:
第一,全面性。它们覆盖书籍中关于角色和情节的大量知识。
第二,正交性。不同类型的数据携带不同且互补的信息,冗余较少。
第三,丰富上下文。这些数据提供足够的上下文,使模拟人格 πc 能够在给定场景中忠实再现角色 c 的行为和反应。
具体来说,我们通过三个相互关联的元素,以层级化方式组织书籍中的知识:
- 情节:每个情节包含原始文本;摘要;该情节中的对话;关键角色在该情节中的当前状态和经历。
- 对话:每个对话不仅包含对话文本,还包含丰富的上下文设定,例如:场景描述;角色动机。
- 角色:角色则与其参与的对话和情节相关联,作者基于这些信息构造角色画像。
消息中的内心想法与动作:
以往 RPLA 研究通常将角色扮演模型的输出空间限制在语言表达上,也就是只让模型生成角色说的话。这限制了模型完整表示人类互动的能力。
在本文中,作者将 RPLA 和角色数据集的消息空间扩展为三个不同维度:
语言 L:语言用于角色之间的口头交流。
动作 A:动作捕捉角色的身体行为、肢体语言、面部表情等。类似于智能体中的工具使用,动作可以被编程为触发多智能体系统中的后续事件。
思想 T:思想表示角色的内部思考过程,使 RPLA 能够模拟复杂的人类认知。
将环境视为角色
为了提升这种能力,作者将环境视为一个特殊角色 e。这个环境角色可以提供环境反馈,例如:
- 物理环境变化;
- 未指定角色的反应;
- 人群反应;
- 场景推进;
- 旁白叙述。
COSER 把环境视为特殊角色,可以让模型学习如何推动场景发展。
数据集构建
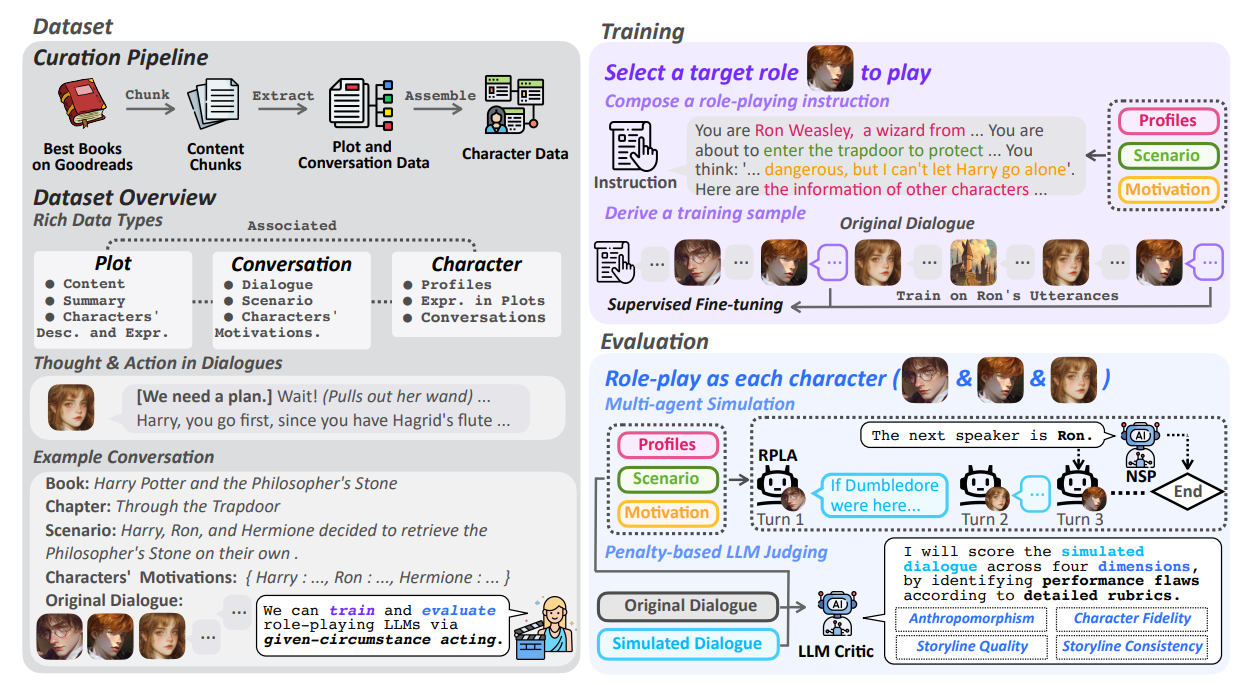
数据来源选择
从 Goodreads 的 “Best Books Ever” 榜单中选取排名前 1000 的书籍,并最终获取了其中 771 本书的内容。这些书籍涵盖了不同体裁、时代和文化背景,提供了具有文学意义和广泛知名度的角色与叙事内容。
Chunking:文本切块
将书籍内容切分成若干文本块,以适应大语言模型的上下文窗口限制。同时采用了两种切块策略:
1. 静态的、基于章节的切块策略
2. 动态的、基于情节的切块策略
首先,作者使用正则表达式识别章节标题,并将其作为自然的文本块边界。然后合并相邻的小文本块,并拆分过大的文本块,以确保每个文本块大小适中。
然而,静态切块会忽略故事情节本身,可能截断重要的情节或对话。为了解决这个问题,作者进一步实现了动态的基于情节的切块方法。也就是说在数据抽取过程中,还会提示大语言模型识别当前文本块中被截断的情节或尾部内容,并将其与后续文本块连接起来,以确保情节的完整性。
Data Extraction:数据抽取
使用大语言模型从书籍文本块中抽取情节和对话数据,包括:
1. 情节的原始内容、摘要和角色经历;
2. 对话内容和对话背景设定。
抽取出的数据表示形式如图 1 所示
在消息中,角色的语言 speech 始终从原始对话中抽取;而动作 actions 和内心想法 thoughts 既可以从文本中直接抽取,也可以由大语言模型根据上下文推断得到。
出于评估目的,作者保留每本书最后 10% 的情节数据作为测试数据,不参与训练。
Organizing Character Data:组织角色数据
基于抽取出的数据,我们通过三个步骤构建角色知识库。
- 统一角色称谓。使用大语言模型建立角色别名和标准名称之间的映射关系。例如,将 “Lord Snow” 映射到统一标识符 “Jon Snow”。
- 为每个角色聚合相关的情节和对话。
-
使用大语言模型基于抽取出的角色相关数据生成角色画像。这些角色画像从多个角度描述角色,包括背景;经历;外貌特征;性格特征;核心动机;人物关系;人物成长弧线等。
通过 GCA 进行训练和评估
规定情境表演
在康斯坦丁·斯坦尼斯拉夫斯基的表演方法论中,规定情境表演是一种基础方法。演员需要在特定条件下接受训练和评价,这些条件包括环境背景、历史事件以及个人状况等。
我们提出将这一表演方法改造成一个用于训练和评估大语言模型角色扮演能力的框架,并利用 COSER 中丰富的数据来实现它。
在这个框架中,给定一个对话,其中包括:
- 对话消息集合 M;
- 涉及的角色集合 C;
- 上下文场景设定 S;
一个演员大语言模型需要依次扮演每个角色 c ∈ C,从而模拟该对话。
GCA 训练与 COSER 模型
通过 GCA 来微调大语言模型的角色扮演能力。每个训练样本都来自 COSER 数据集中的一个对话,以及该对话中的某个角色 c。模型被训练去生成该角色的发言 Mc。
具体来说,作者首先构造一个角色扮演指令 ic。这个指令包含:
- 场景描述;
- 当前角色的画像 pc;
- 当前角色的动机;
- 其他参与角色的画像。
这些信息共同为角色扮演提供完整上下文。
原始对话消息记作:M = [m1, ..., mT]
其中 T 是对话轮数。
然后,一个训练样本可以表示为:[ic, m1, ..., mT]
也就是把角色指令和完整对话拼接起来。
在这个样本中,属于目标角色 c 的消息 Mc ⊂ M 被作为需要优化的输出;而其他部分则作为输入上下文。
作者基于 LLaMA-3.1 Instruct 模型训练了 COSER 8B 和 COSER 70B,使用了数据集中 90% 的书籍作为训练数据。
为了有效支持 RPLA 的多种真实应用场景,他们的训练样本覆盖了广泛设置:
第一,COSER 数据集包含大量来自不同书籍的角色和对话场景。作者会在每个对话中训练模型扮演所有角色,既包括拥有详细画像的主要角色,也包括只由上下文驱动的次要角色。
第二,为了模拟真实使用场景,作者通过不同格式的指令模板构造多样化的角色扮演指令。此外,作者还考虑了不同数据可用性的组合,例如是否包含其他角色画像、情节摘要和角色动机。
第三,作者分别训练了包含角色内心想法和不包含角色内心想法的模型,以研究 internal thoughts 对角色扮演训练的影响。
此外,COSER 的训练不仅限于角色扮演本身,还扩展到了两个互补能力:
- environment modeling:环境建模;
- next speaker prediction,NSP:下一说话人预测。
这些能力有助于实际 RPLA 应用。
为了保持模型的一般能力,作者还使用 Tulu-3 数据集 对训练数据进行了增强。
GCA Evaluation
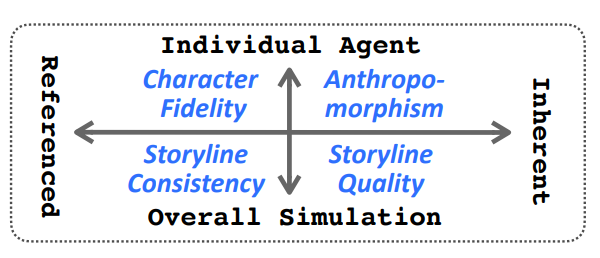
四个评价维度
横轴:Reference-based 参考原文评价 ↔ Inherent 不依赖原文,评价自身质量
纵轴:Individual Agent 单个角色表现 ↔ Overall Simulation 整体模拟质量
- 角色忠实度
- 拟人化程度
- 故事线一致性
- 故事线质量
评价角色扮演大语言模型仍然是一项重要挑战,主要体现在两个方面:
第一,如何提供合适的场景来激发模型的角色扮演表现;
第二,如何恰当地评估模型的表现。
针对这些挑战,作者提出了用于评价演员大语言模型角色扮演能力的 GCA evaluation。该方法包含两个阶段:
1. 多智能体模拟;
2. 基于扣分机制的大语言模型评判。
多智能体模拟
对于一个测试对话 M,作者构建一个多智能体系统,在与 M 相同的设定下模拟出一个新对话 M̄。
具体来说,对于每一个角色 c ∈ C,作者都使用 actor LLM 创建一个角色扮演智能体 πc。
这些 RPLA 会获得第 4.2 节中描述的完整数据,包括:
- 场景描述;
- 参与角色画像;
- 角色动机。
其中,场景描述和角色画像为角色扮演提供关键上下文,而角色动机可以增强角色的主动性,并促进更自然的对话流动。
按照第 3.1 节的设计,RPLA 被要求以:语言—动作—内心想法的格式输出
作者使用一个 NSP 模型从:C ∪ {e} 中选择每一轮的说话者。这里的 C 是角色集合,e 是环境角色。另外,作者还使用另一个大语言模型作为环境模型 πe,用于提供环境反馈。
模拟在两种情况下结束:
1. NSP 输出 <END> 信号;
2. 达到最多 20 轮。
通过这种方式,作者获得了一个多轮、多角色的模拟对话,用来全面反映 actor LLM 的角色扮演能力。
此外,作者还引入了一个 continue-from 参数 k。当 k > 0 时,模拟会从原始对话 M 的前 k 条消息开始。
这样做的好处是可以控制故事方向和语言风格,类似于 in-context learning。它能让评估更可控,并减少不同 LLM 语言风格差异对评估结果的影响。
基于扣分机制的大模型评价
在第二阶段,作者使用 LLM critics 来评价模拟对话 M̄。
与以往基于 LLM-as-a-judge 的角色扮演评估方法不同,COSER 的 LLM critics 有两个特点:
1. 使用基于扣分的评分方式;
2. 使用原始对话 M 作为参考。
具体来说,LLM critic 不会直接输出一个分数,而是先识别模拟对话 M̄ 中的问题实例 F。
这些问题实例对应具体的评分细则,例如:偏离原始对话、缺乏主动性和目标感
每一个问题实例 f 都会被分配一个严重程度 vf,范围是1 到 5
每个维度的初始分数计算为 s = 100 - 5 × Σ vf
也就是说,每发现一个问题,就根据严重程度扣分。
发现 1 个轻微问题,vf = 1
扣 5 分
发现 1 个严重问题,vf = 5
扣 25 分
四个评价维度的具体解释:
1. Anthropomorphism 拟人化程度:评价 RPLA 是否像人一样行动。
2. Character Fidelity 角色忠实度:评价 RPLA 是否忠实扮演指定角色。
3. Storyline Quality 故事线质量:评价模拟对话是否自然发展。
4. Storyline Consistency 故事线一致性:评价模拟对话 M̄ 和原始对话 M 是否对齐。
Length Correction:长度校正
模拟越长,越容易出现更多错误。如果直接按错误数量扣分,那么长对话会吃亏。
所以作者加入 length correction:s = 100 - 5 × Σ vf + λ|M̄|
也就是说,在扣分后,根据生成对话长度加回一部分分数,以减少长度偏差。
实验
实验设置
在 COSER Test 上通过 GCA 来评估大语言模型的角色扮演能力。COSER Test 是一个测试集,包含从每本书最后 10% 情节中保留下来的对话。
COSER Test 一共有 200 个对话,其中:
- 100 个来自 COSER 训练时使用过的书籍;
- 100 个来自训练时没有使用过的书籍。
使用 GPT-4o 作为 LLM critic 和环境模型,并使用 COSER 70B 进行 NSP,也就是下一说话人预测。在给 LLM critic 评价时,作者去掉了角色的内心想法,并将 continue-from 参数设置为 k = 0
Metrics:评价指标
作者报告了每个评价维度上的 LLM judge 分数,并将这些维度的平均值作为总分。
为了分析,我们还使用了两个传统的基于 N-gram 的指标:
- BLEU;
- ROUGE-L。
这两个指标用于比较模型生成对话和原始对话之间的文本相似度。
Models:比较模型
闭源模型,包括:
- Minimax Abab7-preview;
- Doubao-pro;
- Step-1-Flash;
- Step-2;
- GPT-3.5;
- GPT-4o;
- GPT-4o Mini;
- Gemini-1.5-Pro;
- Claude-3-Haiku;
- Claude-3.5-Sonnet。
开源模型,包括:
- COSER 8B;
- COSER 70B;
- LLaMA-3.1-Instruct 8B;
- LLaMA-3.1-Instruct 70B;
- Qwen-2-Instruct 7B;
- Qwen-2-Instruct 72B;
- Vicuna-13B-1.5;
- Mixtral-8x7B;
- DeepSeek-V3;
- Higgs-Llama-3-70B。
Other Benchmarks:其他基准测试
作者还在已有 RPLA benchmark 上评估 COSER 模型。这些 benchmark 不是用 LLM judge,而是基于多项选择题。
包括:
- InCharacter:用于人格测试;
- LifeChoice:用于决策能力测试;
- CroSS:用于动机识别。
对于 InCharacter,作者报告的是其在 Big Five Inventory,五大人格量表 BFI 上的准确率。
主要实验结果
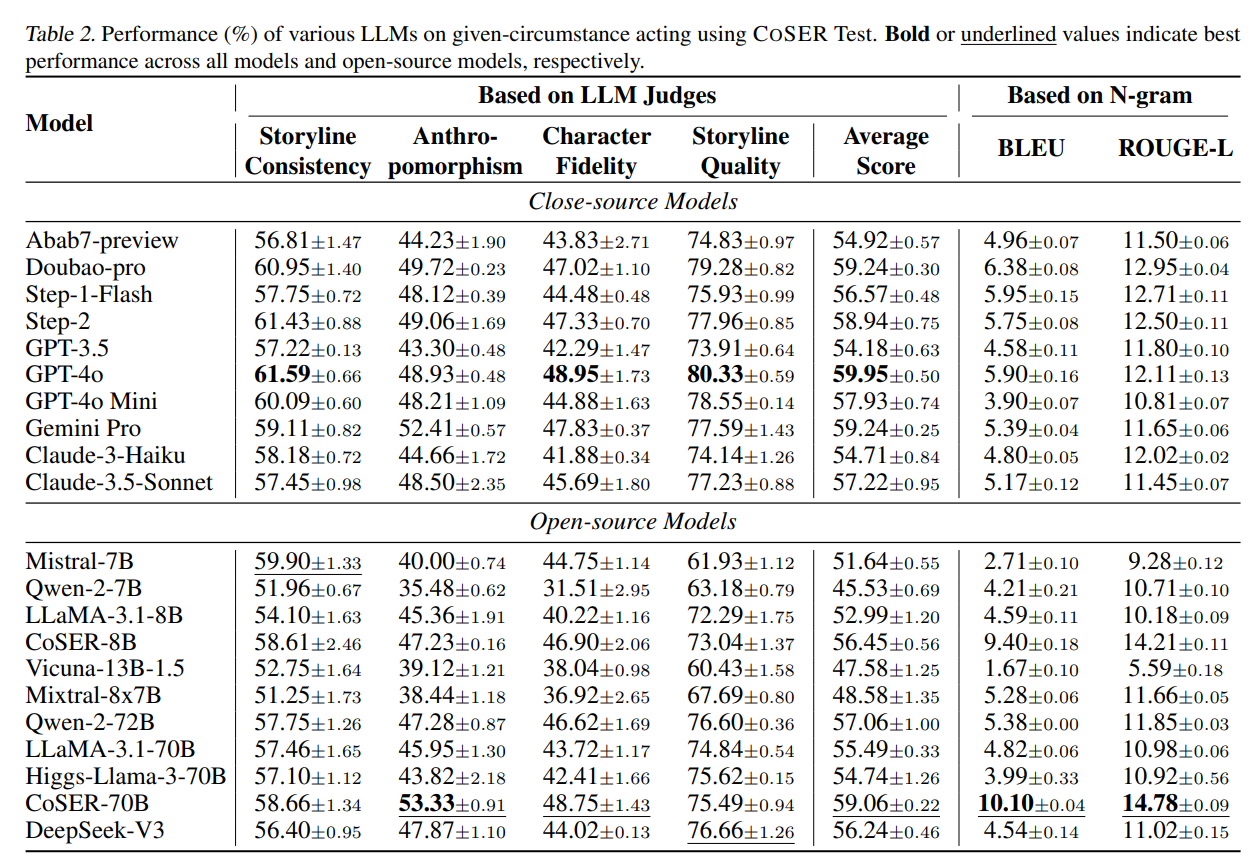
可以看到分为基于 LLM 裁判的评价和传统文本相似度指标
COSER-70B 在基于 LLM 裁判和基于 N-gram 的指标上都取得了当前最先进的表现。对于 LLM 裁判指标,COSER-70B 超过了所有开源模型,并且与 GPT-4o 表现接近。COSER-8B 同样超过了同等规模的模型。对于 N-gram 指标,COSER 模型相比现有模型有显著提升,在 BLEU 上超过第二名 58%。
在所有模型中,GPT-4o、Gemini Pro、Claude-3.5-Sonnet、Doubao-pro、Step-2、Qwen-2-72B 和 COSER-70B 表现较好,它们的平均分都超过了 57%。
高质量小说中的真实对话提升了 LLM 的角色扮演能力
根据表 2,COSER 模型相比它们的 LLaMA-3.1 基线有显著提升。
这说明在 COSER 数据上训练之后,模型角色扮演能力变强了。
Higgs-LLaMA-3-70B 是在合成对话上微调的,但它的表现低于 LLaMA-3.1-70B。
Conversation Continuation 可以让评估更可控
作者还测试了另一种设置:k = 3
也就是给模型原始对话的前 3 句,让模型从第 4 句开始继续模拟。
结果发现:
- 模型分数普遍更高;
- 不同模型之间差距变小;
- BLEU 和 ROUGE-L 提升明显。
因为原始对话前 3 句给了模型故事方向和语言风格提示。
这对小模型尤其有帮助,因为小模型本来更难理解复杂角色扮演指令。有了前几句原文作为引导,它们更容易继续生成合理内容。
说明给前文提示后,小模型也能更好地跟上剧情。
其他 Benchmark 结果
作者还在已有 RPLA benchmark 上评估 COSER 模型,包括:
- InCharacter:人格测试;
- LifeChoice:角色决策测试;
- CroSS:角色动机识别。
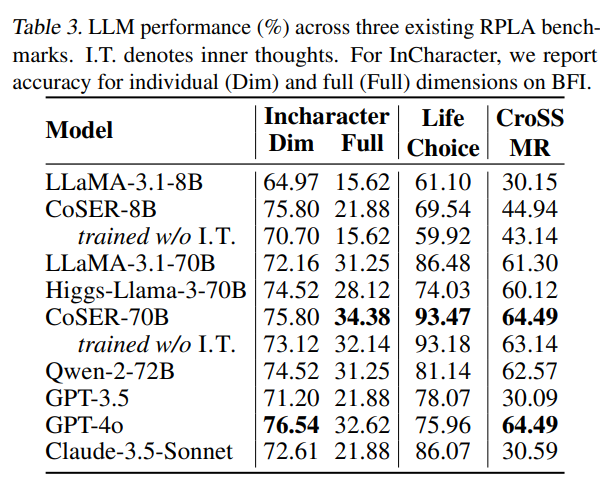
表 3 显示,COSER-70B 在这些 benchmark 上也取得了当前最好的结果。
这说明 COSER 模型不仅在 COSER 自己的测试集上表现好,在已有角色扮演基准上也很强。
人工评估
人工标注
从 COSER Test 中随机选择了 60 个样本,并基于这些样本的多智能体模拟结果,对 7 个代表性 LLM 进行评价。
三名标注者分别独立地对模型进行评分。每位标注者评价 20 个样本。评分采用 1 到 10 分制。在评分时,标注者会看到背景上下文和原始对话。
在这个过程中,标注者指出了两点:
第一,与以往的单轮角色扮演 benchmark 相比,GCA 多智能体模拟能够更深入地反映 LLM 的角色扮演能力。
第二,人工评价非常困难且耗时。它要求标注者仔细理解复杂背景和大量对话。平均来说,评价一个样本中的 7 个模型需要 15 分钟。
作者报告了各模型的平均得分,以及它们相对于其他模型的胜率。
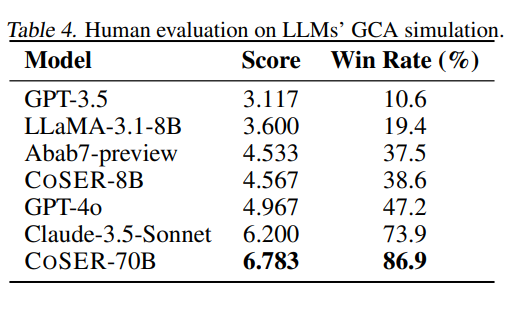
根据表 4,作者发现:
第一,人工评价结果总体上与 GCA 自动评价结果一致。这验证了作者提出的基于 LLM 的评价协议具有一定可靠性。
第二,COSER-70B 仍然保持最优表现,获得了最高的人工评分 6.783 和最高胜率 86.9%。
第三,与 GPT-4o 作为 LLM judge 的评价结果相比,人类评价者对 GPT 系列模型的偏好较低。这可能是因为 LLM judge 存在 self-preference bias,自我偏好偏差。也就是说,GPT-4o 作为裁判时,可能更偏好 GPT 系列模型生成的风格。
LLM 评价与人类评价的一致性
作者进一步研究了 LLM judge 和人类 judge 之间的一致性。
他们评估了三个 judge 模型:GPT-4o、DeepSeek-V3、DeepSeek-R1
作者比较了标准 GCA 评价方法,以及若干消融版本。这些消融版本分别去掉:
1. 原始对话 reference
2. 评分 rubrics
3. 长度校正
4. 维度分离
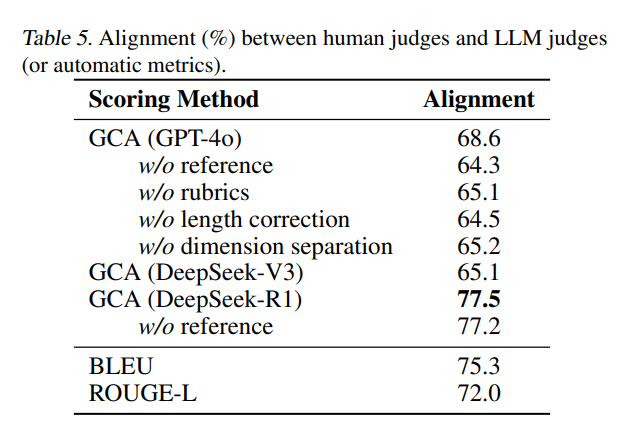
表 5 的结果显示:
第一,GCA 评价中的所有组件都有助于提高 LLM judge 与人类评价的一致性。
第二,推理模型更适合作为裁判。其中,DeepSeek-R1 达到了最高的一致性。
第三,BLEU 和 ROUGE-L 仍然是角色扮演评价中的有效指标。
消融实验
测试阶段:内心想法和角色动机能够增强 RPLA 表现
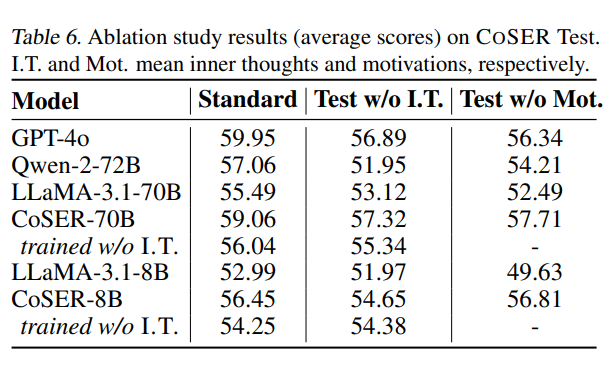
表 6 比较了在 COSER Test 上,模型在是否包含 inner thoughts 和 motivations 的情况下的 overall score。
结果显示,当输入中包含内心想法和角色动机时,所有模型都获得了一致的性能提升。
训练阶段:内心想法有助于角色扮演训练
作者还训练了不包含 inner thoughts 的 COSER 模型变体,并在多个 benchmark 上进行评估。
表 3 和表 6 的结果显示,没有使用 inner thoughts 训练的模型表现始终低于正常的 COSER 模型。这说明 inner thoughts 对角色扮演训练具有价值。
COSER 数据集用于检索增强
作者想证明:COSER 数据集不仅能用于训练和评估,还能作为 检索增强 RAG 的知识库使用。
评估了 COSER 中丰富数据类型在 COSER Test 上用于检索增强的价值。
对于某个特定角色,作者探索了三种检索来源:
- 相关对话中的 dialogue,也就是 Conv.;
- 角色在相关情节中的经历,也就是 Expr.;
- 相关情节中的原始文本,也就是 raw text。
检索系统基于 FAISS 构建,并使用 BGE-M3 生成文本向量表示。
如表 16 所示,我们观察到:
第一,模型能够稳定地从检索到的角色经历和相关对话中受益,尤其是 COSER-70B 的提升更明显。
第二,然而,直接检索原始文本几乎不能提升大语言模型的表现。
结论
为了构建面向既有角色的有效角色扮演语言智能体,本文提出了 COSER。COSER 包含一个基于真实数据构建的数据集,以及基于这些数据训练得到的模型和评价协议。
COSER 数据集从 771 本著名书籍 中提供了高质量数据,并包含多种全面的数据类型,例如:真实对话、情节摘要、角色经历、内心想法
随后,本文提出了 given-circumstance acting,GCA,给定情境表演,用于训练和评估角色扮演大语言模型。在 GCA 中,LLM 会在真实书籍场景中依次扮演多个角色。
基于该数据集,作者将 GCA 训练应用到 LLaMA-3.1 模型上,开发出了 COSER 8B 和 COSER 70B,它们是先进的开源角色扮演大语言模型。
在评价方面,GCA 结合了:多智能体模拟+基于扣分机制的 LLM critic
大量实验表明,COSER 数据集在 RPLA 的训练、评价和检索增强方面都有价值。
此外,COSER 模型不仅在作者提出的评估方法上取得了当前最优表现,也在三个已有的 RPLA benchmark 上达到了 state-of-the-art 性能。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)