π∗0.6: a VLA That Learns From Experience
本文提出RECAP方法,通过优势条件策略实现视觉语言动作模型(VLA)的强化学习训练。该方法整合演示数据、自主收集数据和专家干预,首先通过离线RL预训练通用VLA模型π*0.6,再针对下游任务进行优化。核心创新在于:1)使用多任务价值函数Vπref评估状态价值;2)基于优势函数Aπ生成改进指标It指导策略优化。实验表明,该方法能显著提升任务成功率和执行效率。相比传统方法,RECAP通过价值函数引导
π*0.6:从经验中学习的 VLA
“我们提出了一种通用方法,即通过优势条件策略进行经验和修正的强化学习 (RECAP),它通过优势条件条件为 VLA 提供强化学习训练。我们的方法将异构数据纳入自我改进过程,包括演示、政策收集的数据以及自主执行期间提供的专家远程操作干预。 RECAP 首先使用离线 RL 预训练通用 VLA(我们称之为 π*0.6),然后可以通过机器人数据收集专门实现下游任务的高性能。”
本文细节非常非常丰富。咱们可以先看来自于实验对比baseline的下面这张差异表
|
模型 |
它代表什么 |
|
Pre-trained π₀.₅ |
老一代 VLA,不用 RECAP、不用 RL |
|
Pre-trained π₀.₆ |
更强的监督预训练 VLA,但没有 advantage indicator |
|
RL pre-trained π*₀.₆ |
已经做过 offline RL pretraining,有 advantage conditioning,但还没有目标任务上的完整 RECAP |
|
π*₀.₆ offline RL + SFT |
在 π*₀.₆ 上用目标任务 demo 做 SFT;demo 的 advantage indicator 固定为 True |
|
π*₀.₆ Ours |
完整 RECAP:目标任务 demo + 自主 运行 + 专家 修复 + value-function-based advantage conditioning |
|
AWR / PPO |
用相同机器人数据,但换成不同 policy特征提取 方法 |
即提出了RECAP的概念,能自主运行,在专家修复的背景下与外界交互进行强化学习,接着如何利用在修复阶段的数据集进行强化学习,就得要引出价值函数 + advantage indicator + value-function-based advantage conditioning。
RL WITH EXPERIENCE AND CORRECTIONS VIA ADVANTAGE-CONDITIONED POLICIES (RECAP)
通过优势条件政策获得经验和纠正的 RL(RECAP)
我们的方法由以下步骤组成,这些步骤可以重复一次或多次以改进基础 VLA 模型: 1)数据收集。我们在任务上运行 VLA,用任务结果标签(决定奖励)标记每个情节,并可选择提供人工干预,以提供早期迭代中错误的纠正示例。 2)价值功能训练。我们使用迄今为止收集的所有数据来训练一个大型的多任务价值函数,我们将其称为 V πref ,它可以检测故障并判断任务完成的预期时间。 3)优势条件训练。为了利用该价值函数改进 VLA 策略,我们包含一个基于由此得出的优势值的最优性指标。
这里进一步浓缩的创新点成2)和3)。
下述这张图片就总结了π*0.6的RECAP架构情况(红色圈起来)
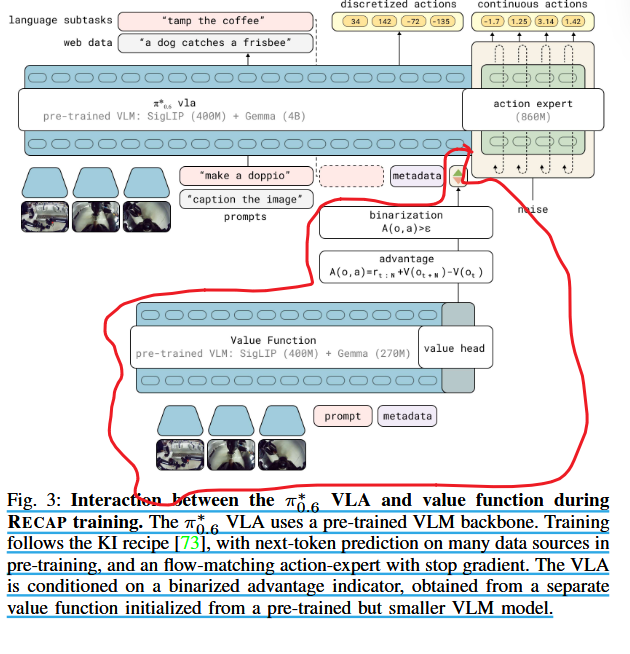
图 3:RECAP 训练期间 π0*.6 VLA 和值函数之间的相互作用。 π0*.6 VLA 使用预先训练的 VLM 主干。训练遵循 KI 配方 [73],在预训练中对许多数据源进行下一个标记预测,以及具有停止梯度的流匹配动作专家。 VLA 以二值化优势指标为条件,该指标是从预训练但较小的 VLM 模型初始化的单独值函数获得的。
先来讲价值函数:

“为了训练一个可以在训练前或训练后阶段充当任何任务的可靠批评者的价值函数,我们用多任务分布价值函数 pφ(V |ot, l) ε ΔB [72] 表示 V πref ,将观察值 ot 和语言命令 l 映射到 B 个离散值箱上的分布。在我们的实现中,该价值函数使用与 VLA 策略相同的架构,但具有较小的 VLM 主干。使用 Rt(τ ) = ΣT t′=t rt′ 表示从时间步 t 到结束的轨迹 τ 的经验回报,我们通过首先将经验回报值 Rt(τ ) 离散化为 B = 201 个 bin(使用 RtB 表示离散化回报)来训练 pφ(V |ot, l),然后最小化当前数据集 D 中轨迹上的交叉熵 H。”
解读:让 value 逼近 future return 的统计规律(期望/分布)。而不是轨迹完全一样,这个就是强化学习本质上的好处,相较于模仿学习。
然后接着

“这是数据集 D 表示的策略价值函数的蒙特卡洛估计器(即行为策略 πref)。我们可以使用 V πref (ot, l) = Σ b∈[0,B] pφ(V = b|ot)v(b) 从学习到的值分布中提取连续值函数(从而获得优势),其中 v(b) 表示对应于 bin b 的值。在预训练阶段,数据集 D 对应于人类演示,价值函数捕获我们所条件的任务和元数据的预期回报,而在后续迭代中,它偏向于演示回报和学习策略的加权组合。”
解读:这里就相当于把概率乘值然后便利每个值做这样相同的操作得到连续的值函数,即蒙特卡洛估计器。
怎么用这个V πref呢?这就得要跳到附页了:

“优势估计:在训练后,我们使用 Aπ(ot, at) = Σt+N−1 t′=t r′ t+ V π(ot+N ) − V π(ot) 来估计优势函数,其中 ot+N 是从同一轨迹向前 N 步采样的观测值。我们使用 N = 50 前瞻来计算这一优势。在预训练期间,我们将优势估计计算为 Aπ(ot, at) = ΣT t′=0 r′ t V π(ot),为每个情节设置 N = T,这是优势的更高方差估计。我们使用这种优势计算,因为它允许我们在预训练期间使用对值函数的单个推理调用即时计算优势值。我们根据经验发现,当策略在预训练期间对来自不同任务的大量数据进行训练时,这种优势估计效果很好。”
解读:利用价值函数得到优势函数Aπ(ot, at),其实我觉得这里应该有语言l的输入,跟下面改进指标 I 里的A应该是一回事。
然后接着用优势函数经过零一判断得到改进指标:

“因此,如果我们训练策略使其能够同时表示 πref(a|o, l) 和 πref(a|I, o, l),我们就可以表示 π^,而无需显式表示改进概率 p(I|Aπref (o, a))。这一原理类似于无分类器指导中的方法,其中训练扩散模型来对有或没有条件变量的数据进行建模[4]。我们假设改进指标 I 遵循 delta 分布”(这句话其实正文是在公式2之后作为补充的,看下图)
解读:它来自 advantage-conditioning / CFGRL 这条思路:先用 value function 算 advantage,再把动作是否优于参考策略压成一个二值标签,作为策略训练时的条件输入。这里的阈值在附页中有解释怎么设定
来自附录F“优势阈值:每个任务优势阈值εl设置如下。在预训练期间,我们为每个任务选择阈值,以便大约 30% 的演示数据具有积极优势(根据 10k 数据点的随机样本计算得出)。在微调过程中,我们通常设置阈值,使得每次迭代中大约 40% 的评估推出具有积极优势。对于 T 恤和短裤洗衣折叠任务(其中高质量演示数据的训练产生缓慢的策略,但成功率很高),我们提高了阈值,使得只有大约 10% 的数据具有正优势。”
然后用I放入下面这个(2)公式,真正用的时候β不是等于1,在附录E中说了设定在β ∈ [1.5, 2.5])

这里的πref初始的时候是Pre-trained π₀.
然后接着恩就是优化策略

“具有任务相关的改进阈值 εl。该阈值使我们能够控制最优性指标,并最大限度地减少寻找衰减因子 β 来锐化训练后改进条件分布的需要。2 然后,策略目标对应于最小化以下负对数似然:
优势值Aπref(ot,at,l)由上一节中的价值函数获得,α是一个权衡超参数。实际上,数据集 Dπref 包含迄今为止收集的所有数据,包括所有演示和自主任务尝试,因此参考策略 πref 是人类行为和先前行为混合体部署的政策(经过不断人工矫正扩充数据集)。为了包含人工更正,我们发现对于在自主推出期间作为人工更正提供的操作强制 It = True(即正)很有用。如果我们假设人类专家总是提供良好的纠正措施,那么这种选择是合理的。正如我们将在第五节中讨论的,实际上我们的 VLA 模型会产生离散和连续输出,连续分布通过流匹配表示。因此,真正的训练目标将离散值的可能性与连续值的流匹配目标相结合。在实践中,我们在整个预训练数据集上预训练一个模型来表示 πθ(at|It, ot, l),然后针对每项任务通过在策略部署(以及可选的专家纠正干预)来执行我们的方法的一次或多次迭代。”
算法的总结:

接着就是一些细节上的内容:
奖励的设定参考公式(5)
然后: “在预训练期间,我们首先在同一数据集上训练价值函数,预测成功完成每个任务的步骤数(负数)。然后我们估计每个任务的改进阈值 εl,用于确定基于优势的改进指标 It。我们将 εl 设置为任务 l 的价值函数预测值的 30% 百分位。然后,我们在 VLA 训练期间动态运行价值函数,以估计每个示例的 Aπref (ot, at, l),然后使用它根据 εl 计算 It。它作为 π* 0.6 的输入包含在内,如第 V-A 节所述。
由于我们使用相对较小的 VLM 主干 (670M) 作为价值函数,因此价值函数的即时推断在 VLA 训练期间产生的额外成本最小。预训练后,我们开始针对目标任务的策略改进循环。我们首先使用目标任务 l 的演示数据 Dl 微调 π* 0.6。我们在此阶段将指标 It 固定为 True,我们发现这会带来稍微更好的结果,因此该阶段对应于监督微调(SFT)。这会产生初始策略 πl0,然后用于收集添加到 Dl 的其他数据。虽然有些剧集是完全自主收集的,但有些剧集是由专家远程操作员监控的,他可以进行干预提供更正。这些更正可以向政策展示如何避免灾难性故障或如何从错误中恢复。但请注意,仅靠纠正不太可能解决所有问题:在自主执行期间进行干预是一种破坏性事件,即使是专家操作员也无法保证干预质量的一致性,也无法改善行为的微妙方面,例如整体速度。因此,与理论[7]相反,修正更多地用于修复大错误并克服探索中的挑战,并且其本身并不能提供最佳监督。回想一下第 IV-B 节,我们强制所有修正都为 It = True,
但除此之外,整个情节(自主部分和修正)都可以选择添加到数据集 D1 中,无论是否提供修正。数据收集后,我们对迄今为止为任务收集的所有数据微调价值函数,然后使用它通过更新的指标 It 来微调策略,使用与预训练相同的过程。价值函数和策略都是从预训练的检查点进行微调的,而不是上次迭代的策略和价值函数。我们发现这对于避免多次迭代中的漂移很有用,尽管通过对上一个模型进行持续微调也可能获得良好的结果。
我们可以根据需要重复此过程多次迭代,但在实践中我们发现即使一次迭代也常常会带来显着改善的结果。”
解读:在目标任务的第一轮适配时,作者暂时不做真正的 RL/advantage 筛选,而是把所有目标任务 demonstration 都当作“正向、值得模仿的动作”,用它们做一次普通监督微调,得到一个能跑起来的初始策略 π^0_ℓ。 原文说:预训练后进入 target task 的 policy improvement loop;先用目标任务 ℓ 的 demo 数据 D_ℓ 微调 π*₀.₆;在这个阶段固定 I_t=True,效果略好,因此这个阶段等价于 SFT;得到初始策略 π^0_ℓ,然后用它去收集更多数据。 收集完后,作者会在当前任务所有数据上微调 value function,再用更新后的 I_t 来微调策略。
|
阶段 |
数据 |
I_t 怎么来 |
目的 |
|
预训练 π*₀.₆ |
大规模多任务机器人数据 |
value function 估计 advantage,再二值化 |
让通用 VLA 学会 advantage conditioning |
|
目标任务初始微调 |
目标任务 demos D_ℓ |
全部固定 True |
得到能跑起来的初始策略 π^0_ℓ |
|
数据收集 |
用 π^0_ℓ 上机器人执行 |
暂时不训练,只收集成功、失败、纠正等轨迹 |
扩充目标任务经验 |
|
后续 RECAP 迭代 |
demo + autonomous rollout + corrections |
autonomous 部分用 value function 算 I_t;correction 强制 True |
真正利用成功/失败经验改进策略 |
实验这块的话两个指标:success rate 和 throughput
论文主要看两个指标:
Success rate 是 episode 成功比例,由人工标注得到。标注者会根据多个质量维度判断 episode,最后聚合成成功/失败标签。
Throughput 是每小时成功完成多少次任务。这个指标很有意思,因为它同时惩罚失败和慢动作:一个策略即使成功率高,但动作太慢,throughput 也会低。对真实机器人部署来说,throughput 往往比单纯 success rate 更实用。
经过算法1这样的无限循环,RECAP 不是一次性 SFT,而是可以靠经验继续变好。
局限性也很明显:
作者自己也承认系统还不是完全自主:reward feedback、human interventions、episode resets 仍然依赖人工。探索方式也比较朴素,主要依靠策略随机性和人工 intervention,而不是复杂探索算法。另外,RECAP 采用的是 batch/iterated offline update:收集一批数据、重新训练、再部署,而不是边收集边实时更新的 fully online RL。
所以,这篇论文的实验结论不是已经解决了机器人 RL,而是更准确地证明:
对于真实长时程机器人任务,大 VLA 可以通过部署经验、人工纠正和 value-function-based advantage conditioning 继续提升;而且这种提升体现在实际有意义的指标上:更高成功率、更高 throughput、更少特定失败模式

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)