面向可靠Sim-to-Real可预测性的MoE鲁棒四足运动控制——文献深度解读
本文提出了一种基于混合专家(MoE)的强化学习框架,用于提高四足机器人Sim-to-Real迁移的可靠性。针对仿真训练与真实部署间的性能差距问题,研究团队开发了创新的MoE学生编码器架构,通过并行专家子网络和动态门控机制增强本体感知表征能力。该方法在Unitree Go2机器人上验证,通过精心设计的奖励函数(包括创新的髋关节对称性奖励)和动态速度跟踪调节策略,实现了复杂地形下的鲁棒运动控制。实验表
面向可靠Sim-to-Real可预测性的MoE鲁棒四足运动控制——文献深度解读
一、文献基本信息
- 论文标题: Toward Reliable Sim-to-Real Predictability for MoE-based Robust Quadrupedal Locomotion
- 作者: Tianyang Wu, Hanwei Guo, Yuhang Wang, Junshu Yang, Xinyang Sui, Jiayi Xie, Xingyu Chen, Zeyang Liu, Xuguang Lan
- 机构: 西安交通大学,人机混合增强智能全国重点实验室,人工智能与机器人研究所
- 项目主页: https://robogauge.github.io/complete/
- 发表信息: arXiv:2602.00678v4 [cs.RO],2026年5月
二、核心科学问题与技术挑战
2.1 解决的核心科学问题
本论文聚焦于强化学习(Reinforcement Learning, RL)驱动的四足机器人运动控制中一个根本性瓶颈:Sim-to-Real迁移的不可靠性。
具体而言,该工作试图解决以下两个紧密关联的核心问题:
-
仿真-现实鸿沟(Sim-to-Real Gap)的不可预测性:四足机器人的RL训练通常在GPU加速的物理仿真器(如IsaacGym)中大规模并行进行。然而,仿真环境中的高训练奖励和高性能指标往往不能可靠地预示真实硬件上的表现。策略网络极易对仿真的特定动力学参数过拟合,导致其在真实世界中部署时性能急剧退化甚至完全失效。
-
缺少可靠的量化评估代理指标:在没有可靠的仿真评估手段的情况下,研究者不得不在物理机器人上进行直接的、反复的部署验证。这种"试错式"的验证范式不仅效率极为低下,而且面临严重的硬件损坏风险,尤其当策略在复杂地形(如楼梯、障碍物)或高速状态下运行时。传统的仿真训练指标(如训练奖励曲线、训练地形等级曲线)被证明与真实世界性能之间存在显著偏差。
2.2 技术挑战的深层分析
论文深入分析了造成上述问题的内在机制:
- 奖励过拟合(Reward Overfitting):在复杂地形上,策略可能学会利用仿真器特有的动力学"漏洞"来最大化奖励,而非学习真正鲁棒的运动技能。这些"漏洞"在真实物理世界中并不存在,导致策略迁移时崩溃。
- 本体感知的局限性:为增强在极端环境(浓烟、弱光、剧烈震动)下的可靠性,本工作仅依赖本体感知(proprioception,由IMU和关节编码器提供),不使用相机、LiDAR或足端接触传感器等外部感知传感器。这虽然提高了感知鲁棒性,但也使得策略必须从有限的高维隐式信息中推断地形和运动状态,对模型的表征学习能力提出了极高要求。
- 学生模型的容量瓶颈:在教师-学生(Teacher-Student)训练范式中,学生模型(部署于真实机器人)的表达能力通常远弱于教师模型(可访问特权状态信息),这种容量差距限制了性能上限。
三、研究方法与技术路线
本工作提出了一套统一的闭环训练与评估框架,将混合专家(Mixture-of-Experts, MoE)运动策略与RoboGauge预测评估套件紧密结合。整体框架架构如图1所示,涵盖三个阶段:训练(Train)、评估(Evaluate)、部署(Deploy),形成一个闭环迭代优化流程。
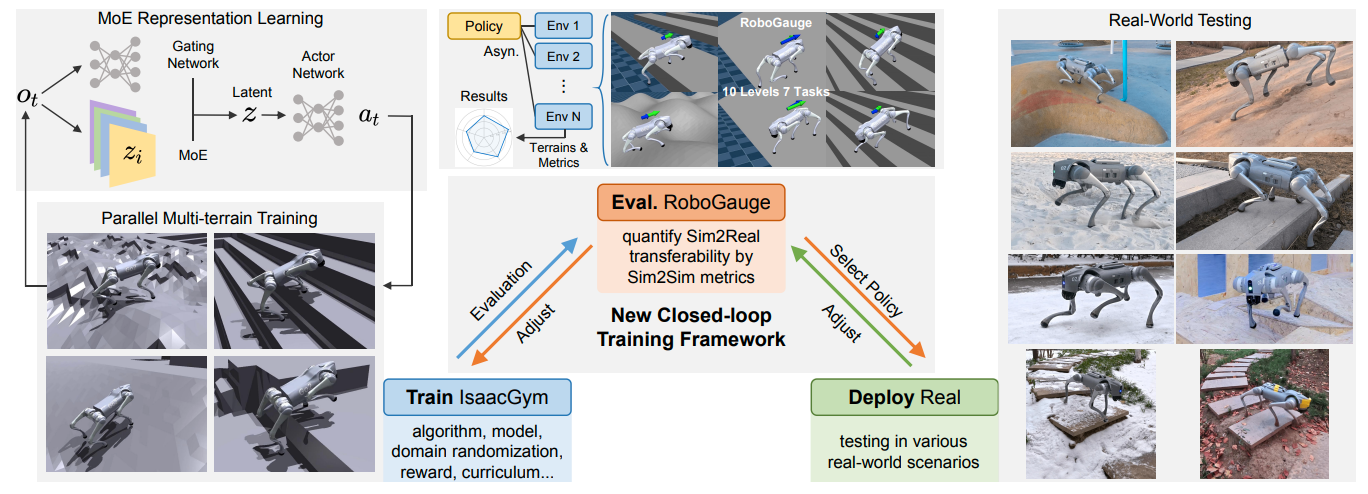
3.1 强化学习问题建模:部分可观测马尔可夫决策过程(POMDP)
论文将仅依赖本体感知的四足运动控制问题建模为无限时域部分可观测马尔可夫决策过程(POMDP),形式化定义为元组 (S, A, O, P, Ω, R, ρ₀):
- 状态空间 S ⊂ ℝⁿ:特权状态空间,包含机器人动力学信息及周围环境的全部信息,包括线速度
v_t、采样的地形高度h_t(在机器人基座周围 1m × 1.6m 矩形区域内以 0.1m 间隔采样)、环境隐变量µ_t(足端接触力、关节力矩、关节加速度等)。这些信息仅在训练时可用。 - 观测空间 O ⊂ ℝᵒ:部署时可用的本体感知观测,包含:IMU测量的角速度
ω、本体坐标系中投影重力矢量g_proj、关节位置q和关节速度q̇、纵向/横向线速度命令v_x^cmd和v_y^cmd、偏航角速度命令ω_z^cmd,以及前一时刻的动作a_{t-1}。 - 动作空间 A ⊂ ℝᵐ:关节位置偏移量(相对于默认关节位置)。通过比例-微分(PD)控制器将目标关节位置转换为关节力矩。
- 奖励函数 R:根据期望的运动行为设计的复合奖励。
- 优化目标:寻找最优策略 π*,最大化期望累积折扣奖励:
J(π) = E_{s₀∼ρ₀, τ∼π} [ Σ_{t=0}^{∞} γᵗ R(sₜ, aₜ, sₜ₊₁) ]
其中 γ ∈ (0, 1) 为折扣因子。
3.2 MoE混合专家表征编码器——核心算法创新
这是本文最核心的算法贡献。论文将混合专家(Mixture-of-Experts, MoE)架构创新性地嵌入到并发教师-学生(Concurrent Teacher-Student, CTS)框架的学生编码器中,大幅提升学生在仅使用本体感知条件下的多地形表征能力。
3.2.1 架构设计
MoE学生编码器的核心结构包含以下组件:
- K个并行的专家子网络 {Eₖ}ₖ₌₁ᴷ:每个专家子网络专精于处理特定指令类型或环境上下文下的观测数据。
- 门控网络(Gating Network)g:基于观测序列
o_{t-H:t} = [o_{t-H}, ..., o_t]ᵀ(H=5)动态分配各专家的权重ωₖ。 - 隐状态输出 zₛ:所有专家输出的加权和:
zₛ = Σ_{k=1}^{K} ωₖ Eₖ(o_{t-H:t})
ωₖ = softmax(g(o_{t-H:t}))ₖ
3.2.2 负载均衡损失(Load Balancing Loss)
为防止门控网络退化到只激活单一专家子网络(导致其余专家失效),引入辅助的负载均衡损失:
L_load_balance = Σ_{k=1}^{K} (ω̄ₖ - 1/K)²
ω̄ₖ = (1/B) Σ_{j=1}^{B} ωₖ^{(j)}
其中 B 为训练批次大小,ωₖ^{(j)} 为第 j 个样本分配给第 k 个专家的权重。该损失鼓励系统在所有专家之间均匀分配任务,确保表征多样性和整体表达能力。
3.2.3 与现有方案的对比与消融实验
论文设计了系统的消融研究验证MoE架构设计的有效性:
| 变体 | 描述 | RoboGauge得分 |
|---|---|---|
| MoE(本文方案) | MoE部署于学生编码器 | 0.6713 |
| AC-MoE | MoE应用于Actor-Critic网络(参考MoE-Loco[44]) | 0.6509 |
| MoE-NG | 门控网络输入排除指令信息 | 0.6519 |
| MCP | 乘法组合策略(Multiplicative Compositional Policies) | 0.6399 |
关键发现:
- 将MoE应用于编码器而非动作网络(AC-MoE)或使用乘法组合(MCP),能避免在动作空间的直接专家组合所导致的训练不稳定和损失发散问题。
- 指令信息对于门控网络至关重要——排除后性能下降,说明门控需要指令信息来正确路由至正确的专家。
3.2.4 MoE隐空间表征可视化分析
通过**主成分分析(PCA)**将学生编码器的隐状态降维至二维进行可视化:
- 不同地形下的前向运动(Fig. 6):MoE架构的隐状态在不同地形(平坦、波浪、楼梯、障碍物)上形成明显分离的簇,而标准CTS的隐状态分布高度重叠——证明MoE实现了更优的地形特征辨别。
- 全部地形下的不同指令(Fig. 16):在前向、后退、侧移和转向指令下,MoE隐状态也表现出清晰的聚类分离,表明其对运动模式的精细编码能力。
3.3 奖励函数设计
论文采用一致的奖励函数结构用于多地形和高速运动模型,基于已有成熟方法[16, 22, 49],并引入了关键的自定义奖励项:
| 奖励项 | 公式/描述 | 权重(多地形/高速) |
|---|---|---|
| 线速度跟踪 | exp(-σ‖v_xy^cmd - v_xy‖₂²) |
1.0 / 2.0 |
| 角速度跟踪 | `exp(-σ | ω_z^cmd - ω_z |
| 垂直线速度 | v_z² |
-2.0 |
| 角速度(xy) | ‖ω_xy‖₂² |
-0.05 |
| 关节加速度 | q̈² |
-2.5×10⁻⁷ |
| 关节功率 | ` | τ |
| 关节力矩 | ‖τ‖₂² |
-1×10⁻⁴ |
| 基座高度 | (h_des - h)² |
-1.0 |
| 动作变化率 | ‖aₜ - aₜ₋₁‖₂² |
-0.01 |
| 动作平滑度 | ‖aₜ - 2aₜ₋₁ + aₜ₋₂‖₂² |
-0.01 |
| 碰撞惩罚 | n_collision |
-1.0 |
| 关节限位 | n_limitation |
-2.0 |
| 足端调节 | r_fr |
-0.05 |
| 髋关节调节 | ` | q_hip - q_hip_default |
髋关节对称性 r_hs |
见公式(4) | -1.0(仅高速模型) |
髋关节对称性奖励 r_hs 的创新设计
针对高速直线运动,论文创新性地引入了髋关节对称性奖励:
r_hs = |v_x^cmd| / ‖v_cmd‖₂ · (|q_hip_FL + q_hip_FR| + |q_hip_RL + q_hip_RR|)
该奖励项以指令方向分量为权重因子,确保机器人在执行纵向运动时保持对称姿态,抑制大腿外展,促进高速稳定窄幅步态的自发涌现。
动态速度跟踪精度调节策略
在复杂地形(波浪、楼梯、障碍物)上,固定不变的速度跟踪精度参数 σ 容易导致跟踪失败。论文提出了动态调节机制:
- 定义速度范围
[v_min, v_max]及各地形的最大跟踪系数σ_max^Ti。 - 中间系数
σ_vel在低/高速度区间分别采用σ或σ_max^Ti,在过渡区间采用线性插值。 - 最终自适应系数
σ_now将地形难度等级L纳入影响:
σ_now = σ + min(e^(L/10) - 1, 1)(σ_vel - σ)
这一设计使得训练能在复杂地形上适当放松跟踪约束,同时确保稳定性。
3.4 环境配置与域随机化策略
3.4.1 训练环境
| 参数 | 配置 |
|---|---|
| 仿真平台 | IsaacGym(基于GPU的大规模并行仿真) |
| 并行智能体数量 | 8192 |
| 机器人平台 | Unitree Go2(12自由度) |
| 控制频率 | 50 Hz |
| 仿真频率 | 200 Hz |
| PD控制增益 | kp = 20.0, kd = 0.5 |
| 观测序列长度 H | 5 |
3.4.2 地形课程设计
训练地形涵盖7种类型:平坦(Flat)、波浪(Wave)、坡道(Slope)、粗糙坡道(Rough Slope)、上楼梯(Stairs Up)、下楼梯(Stairs Down)、障碍物(Obstacle)。
关键地形参数:
- 坡道倾角:5.7° ~ 29.6°
- 粗糙坡道附加随机高度波动:5 cm
- 楼梯高度:5 cm ~ 25.7 cm,踏步宽度恒定 31 cm
- 障碍物:随机立方体结构,高度 5 cm ~ 27.5 cm,宽度 1 m ~ 2 m
3.4.3 域随机化参数
| 随机化项 | 范围 | 单位 |
|---|---|---|
| 摩擦系数 | [0.5, 1.5] | – |
| 负载质量 | [-1, 1] | kg |
| 连杆质量 | [0.9, 1.1] × 标称值 | kg |
| 基座质心位置 | [-3, 3] × [-3, 3] × [-3, 3] | cm |
| 恢复系数 | [0.0, 0.5] | – |
| 比例增益 kp | [0.9, 1.1] × 标称值 | Nm/rad |
| 微分增益 kd | [0.9, 1.1] × 标称值 | Nm·s/rad |
| 执行器强度 | [0.8, 1.2] × 标称值 | – |
| 执行器偏移 | [-0.035, 0.035] | rad |
| 控制延迟 | [0, 20] | ms |
3.4.4 指令设计策略——三项创新
- 指令课程(Command Curriculum):分三阶段逐步扩大指令范围,避免初始阶段的大范围指令导致不稳定步态。
| 阶段 | 训练步数 | vx [m/s] | vy [m/s] | ωz [rad/s] |
|---|---|---|---|---|
| 初始 | [0, 2×10⁴] | ± 0.5 | ± 0.5 | ± 1.0 |
| 中级 | [2×10⁴, 5×10⁴] | ± 1.0 | ± 1.0 | ± 1.5 |
| 高级 | [5×10⁴, ∞] | ± 2.0 | ± 1.0 | ± 2.0 |
-
极端指令采样(Extreme Command Sampling):修改均匀采样分布,以10%概率采样静止指令,20%概率采样三维最大化指令组合,20%概率在线速度为零时采样最大角速度(增强原地转向鲁棒性)。
-
动态指令采样(Dynamic Command Sampling):确保累积指令距离超过地形进阶所需的阈值(4m),防止因指令序列过短而阻碍难度等级提升。该策略加速收敛并使RoboGauge峰值得分提升11%。
3.5 RoboGauge预测评估框架——评估方法的核心创新
RoboGauge是本工作提出的一个系统化的预测性评估框架,其核心理念是:通过对仿真环境的精细化设计,建立一个能可靠预测真实世界性能的仿真评估体系(Sim-to-Sim评估),从而避免高风险的真实硬件验证。
3.5.1 设计哲学
RoboGauge的目的并非在仿真中复制真实世界,而是构建一套多维度的难度压力测试,使仿真评估的得分排序与真实世界性能排序高度一致。这种"排序一致性"比绝对的"数值一致性"更为现实和有用——只要能基于仿真分数选出最优策略模型即可。
3.5.2 三大层次化评估管道
RoboGauge构建于MuJoCo仿真引擎之上,组织为三个层次:
(A) 基础管道(BasePipeline):
- 原子级单环境评估单元
- 整合特定地形、域随机化配置
- 管理异常处理、观测噪声注入
(B) 多/等级管道(Multi/Level Pipeline):
- 并行化跨多随机种子的评估
- 通过二分搜索策略确定各地形-随机化组合下的最高可通行难度等级
- 判定标准:目标到达成功率 ≥ 80%(5个随机种子评估)
© 压力管道(Stress Pipeline):
- 综合所有地形、域随机化、难度的全面测试
- 合成统一的鲁棒性得分
3.5.3 八维度定量性能指标体系
论文基于四足运动控制的物理本质和真实部署中的常见失效模式,设计了六类共八项归一化指标:
| 指标类别 | 指标名称 | 评估目的 |
|---|---|---|
| 跟踪精度 | 线速度跟踪误差(ℓ₂) | 衡量对期望速度的跟踪保真度 |
| 角速度跟踪误差(ℓ₂) | 衡量对期望偏航速率的跟踪保真度 | |
| 硬件安全 | 自由度功率 | 防止执行器过热/热失效 |
| 自由度限位违反 | 防止关节超出软限位导致损坏 | |
| 运动稳定性 | 姿态稳定度(横向重力投影) | 抑制侧倾、确保姿态鲁棒控制 |
| 力矩平滑度(时序平滑性) | 抑制结构振动 | |
| 物理准则 | ZMP裕度 | 基于牛顿-欧拉方程的零力矩点偏离评估 |
| 库伦摩擦裕度 | 法向力加权的接触力锥边界松弛量 |
ZMP裕度的数学推导:
对所有N个刚体进行动力学聚合,计算总力和总力矩:
F_total = Σ_{i=1}^{N} m_i(g - p̈_i)
M_total = Σ_{i=1}^{N} [(p_i × m_i(g - p̈_i)) - (I_i ω̇_i + ω_i × (I_i ω_i))]
将ZMP投影至虚拟水平面(z_zmp = 0),解得精确坐标 (x_zmp, y_zmp),定义归一化裕度:
m_zmp_margin = max(0, 1 - ‖(x_zmp, y_zmp)‖₂ / D_norm)
其中 D_norm 为默认姿态下的对角线支撑跨度。
库伦摩擦裕度:
m_friction_margin = Σ_{i=1}^{Nc} w_i · max(0, 1 - ‖f_i^tangent‖ / (µ · f_i^normal))
w_i = f_i^normal / Σ_{j=1}^{Nc} f_j^normal
该指标以法向力加权,使承受更大垂向载荷的接触点获得更高权重。
3.5.4 评估矩阵
RoboGauge构建了一个系统化的评估矩阵:
| 维度 | 具体配置 |
|---|---|
| 运动目标 | 最大速度指令、紧急急停、对角速度阶跃、目标位置到达任务 |
| 地形类型 | 平坦、波浪、坡道(上/下)、楼梯(上/下)、障碍物 → 共7种独立评估环境 |
| 难度等级 | 除平坦外,每种地形10个离散等级(1~10) |
| 域随机化 | 9种不同组合,摩擦系数 0.2~1.0(步长0.1) |
| 评估种子 | 每种配置3个随机种子 |
3.5.5 层次化综合评分方法
(1) 执行质量评分:
采用加权几何平均对8项归一化指标进行聚合:
Q_{i,j}(L) = (Π_{k=1}^{K} m_k^{w_k})^{1 / Σ w_k}
使用几何平均而非算术平均的关键原因:惩罚不平衡性能——如果任何一个关键维度(如安全性)表现极差,几何平均会将其拉至接近零,避免"一白遮百丑"。
(2) 最差情况均值聚合:
对于每个运动目标内的多次试验,不取平均,而取最差50%的均值:
Score = Mean(lowest 50% of scores)
这种策略刻意“忽视”简单指令的高分,将评估集中在最具挑战性的机动(障碍物穿越、步态切换等),真实反映了机器人在困难场景下的表现。
(3) 重叠评分函数:
S_{i,j} = α(L*_{i,j} - 1) + β·Q_{i,j}(L*_{i,j})
其中 α = 0.09, β = 0.19,满足 β > α。这种设计使难度等级和完成质量相权衡:高质量的较低等级表现可近似较低质量的较高等级表现,确保评分区间 [0, 1] 内的平滑过渡。
(4) 最终得分聚合:
S̄_i = (1/M) Σ_{j=1}^{M} S_{i,j} # 地形平均鲁棒得分
S̄ = (1/N) Σ_{i=1}^{N} S̄_i # 最终框架得分
四、实验设计与结果分析
4.1 实验平台与硬件配置
- 机器人平台: Unitree Go2 四足机器人
- 运动捕捉: NOKOV Mars18H(12摄像头,90Hz)
- 测试环境: 室内有限跑道(8 m);多种户外真实地形
4.2 实验1:RoboGauge指标可靠性验证(Q1)
为验证RoboGauge的预测可靠性,将**训练环境(IsaacGym)和RoboGauge(MuJoCo)的指标预测值与真机实测(动捕捉地面真值)**进行对比:
| 评估来源 | 指令跟踪误差 ↓ | 安全性误差 ↓ | 质量误差 ↓ |
|---|---|---|---|
| RoboGauge(MuJoCo) | 0.0558 | 0.0117 | 0.0120 |
| IsaacGym(训练环境) | 0.0883 | 0.0333 | 0.0380 |
结论:RoboGauge所有维度上的误差均显著低于训练环境的指标误差,验证了其作为可靠模型选择依据的有效性。即使对于在训练中表现良好但在真实世界严重退化的模型,RoboGauge也能精确反映其真实水平。
4.3 实验2:基线方法对比(Q2)
在RoboGauge框架下对比了三种领先的仅本体感知一阶段训练方法:
| 方法 | RoboGauge得分 | 跟踪 | 安全 | 质量 | 等级 |
|---|---|---|---|---|---|
| Ours(MoE) | 0.6713 | 0.6669 | 0.7857 | 0.7392 | 7.85 |
| CTS [49] | 0.5786 | 0.5755 | 0.7066 | 0.6624 | 6.83 |
| HIM [25] | 0.5379 | 0.5453 | 0.6476 | 0.6050 | 6.19 |
| DreamWaQ [24] | 0.5054 | 0.5105 | 0.6149 | 0.5730 | 5.74 |
关键分析:
- 训练曲线与真机性能的不一致性(Fig. 4):本方法在训练阶段的平均地形等级并非最高,但RoboGauge评分却持续领先——再次证明传统训练指标不可靠,RoboGauge能更准确地反映真实性能。
- 不同摩擦系数下的鲁棒性(Fig. 5, Fig. 14):本方法在全部摩擦系数区间和全部地形类型上均表现最优,尤其在高难度地形(障碍物、楼梯)上的优势更为显著。
4.4 实验3:MoE隐表征分析(Q3)
通过在PCA降维的二维空间中对比CTS(不含MoE)与CTS w/ MoE的隐状态分布,MoE架构展现出显著的地形感知表征增强能力——不同地形和指令的隐状态呈现清晰聚类分离,体现MoE的多专家专业化分工确实在起作用。
4.5 实验4:真机部署对比(Q4)
三种挑战场景下的生存率测试:
| 方法 | 侧向拉力 80-100N | 瓷砖楼梯 15.5cm (μ=0.38) | 障碍物 30cm (μ=0.85) |
|---|---|---|---|
| Ours(MoE) | 18/20 | 85/85 | 17/20 |
| 内置RL控制器 | 5/20 | 85/85 | 0/20 |
| CTS | 11/20 | 18/85 | 0/20 |
| HIM | 8/20 | 24/85 | 0/20 |
| DreamWaQ | 7/20 | 12/85 | 0/20 |
压倒性优势:仅本方法成功跨越了30 cm障碍物,且在楼梯上完成85步比内置控制器快17秒。
4.6 实验5:速度跟踪精度(Q5)
| 场景 | 平均速度 | 跟踪误差 |
|---|---|---|
| 木制楼梯(10cm上升/15cm下降) | 1.31 m/s | 0.15 m/s |
| 30° 木制坡道 | 1.53 m/s | – |
| 室内跑道高速运动 | 峰值 4.01 m/s,2.16 s内达到 | 0.20 m/s |
4 m/s高速运动的关键发现:即便没有显式的运动约束,模型自发涌现出稳定的窄幅步态(narrow-width gait),这种步态通过减小横向质心振荡有效提升了高速机动时的稳定性。图9捕捉到了瞬时的腾空飞行阶段。
4.7 实验6:泛化性与鲁棒性(Q6)
- 扰动恢复:承受2540N的连续侧向拉力时保持稳定;承受85100N的瞬时脉冲几乎无影响;从60 cm高度跌落成功恢复。
- 跌落恢复:从前端突然失去支撑时,机器人迅速重构步态防止前倾翻倒。
- 野外测试:在沙地、冰面、坡道、不平坦地形等训练中未直接遇到的环境下,100%成功率,零次意外终止。
五、主要创新点与学术贡献
5.1 创新点一:RoboGauge——系统化的Sim-to-Real可转移性量化评估框架
这是本工作最具方法论价值的贡献。在机器人操作(manipulation)领域已有Sim-to-Real排名一致性评估的初步探索[45, 46],但四足运动控制领域长期缺乏此类系统化评估工具。RoboGauge的独到之处在于:
- 多维覆盖:6类指标 × 7种地形 × 10难度等级 × 9种域随机化 × 3类运动目标 × 多随机种子——构建了指数级丰富的评估空间。
- 层次化评分体系:几何平均聚合 → 最差情况均值 → 重叠评分 → 鲁棒得分——每一层都有明确的设计意图和物理/数学依据。
- 实用主义哲学:不追求"完美模拟真实世界",而是追求"排序一致性",这使得框架具有实时性和可扩展性。
- 闭环训练范式:RoboGauge的输出直接反馈到训练过程,指导策略选择和参数调整,构成训练-评估-部署的闭环。
5.2 创新点二:MoE架构在CTS框架中的创新性嵌入
虽然MoE在大语言模型领域已广泛应用,但将其应用于四足机器人运动控制策略的编码器层(而非动作层)是一个独特且经过验证有效的设计选择:
- 正确的架构位置选择:通过消融实验严格论证了MoE应部署于编码器而非Actor-Critic网络或动作空间,后者会导致训练不稳定和损失发散。
- 负载均衡的独特价值:在多地形运动任务中,负载均衡损失不仅防止专家退化,还促进了真正的地形专业化——PCA可视化直观证实了这一点。
- 指令信息对门控的关键作用:消融实验证明指令信息对门控路由至关重要,揭示了"上下文感知路由"在多地形运动中的关键性。
5.3 创新点三:4 m/s高速窄幅步态的自发涌现
这是一个令人瞩目的涌现行为(Emergent Behavior):在没有显式约束横向振荡的情况下,策略自发学会了窄幅步态。
- 物理直觉的验证:这种步态通过自然减小的横向质心振荡来增强高速稳定性,印证了生物力学直觉。
- 髋关节对称性奖励的设计洞见:作为促进该行为的关键因素之一,展示了如何通过精心设计的奖励函数引导有价值涌现行为的产生。
5.4 创新点四:系统的训练策略优化
三项指令设计创新(指令课程、极端指令采样、动态指令采样)和动态速度跟踪精度调节,共同解决了传统训练框架中的一系列工程难题,使RoboGauge得分峰值提升11%,且这些改进都具有通用性和可迁移性。
六、局限性与未来展望
6.1 当前局限
- 感知模态的单一依赖性:仅依赖本体感知虽然在极端条件下鲁棒,但在需要远端感知的任务(如复杂结构障碍物的预先规划)中仍有不足。
- 平台特定性:实验仅在Unitree Go2上完成,对其他形态四足机器人的泛化性有待验证。
6.2 未来方向
论文明确规划了两条扩展路线:
- 扩展至更广泛的机器人形态:将RoboGauge框架适配至人形机器人等更复杂的形态。
- 融合外部感知:将外感知(exteroception,如视觉)与MoE表征相结合,进一步提升对复杂结构障碍物的穿越能力。
七、总结
本文提出了一套面向四足机器人敏捷运动的闭环训练评估框架,核心由两大组件构成:
- MoE运动策略:通过混合专家架构增强仅本体感知条件下的多地形表征能力,实现鲁棒部署。
- RoboGauge评估套件:通过系统化的Sim-to-Sim评估量化Sim-to-Real可转移性,实现可靠的策略选择。
在Unitree Go2上的实验表明,该方法成功克服了30 cm障碍物和100N脉冲干扰,高速运动达4.01 m/s,野外测试成功率100%。这一工作为弥合仿真训练与真机部署之间的鸿沟提供了一条可靠、高效且可预测的技术路径,弥合了长期以来困扰四足机器人RL运动控制的Sim-to-Real评估缺失问题。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)