OpenDriveVLA模型加载深度解析(推理阶段)
OpenDriveVLA 是慕尼黑工业大学等机构提出的端到端自动驾驶 VLA(Vision-Language-Action)模型,它基于 LLaVA-Qwen 多模态大模型构建,能够融合 3D 环境感知、自车状态与语言指令,直接生成驾驶轨迹,是当前自动驾驶大模型方向的代表性工作之一。由于该模型参数量级较大,原生加载会面临显存不足、推理延迟高的问题,因此项目采用了 DeepSpeed 框架来优化模型
前言
OpenDriveVLA 是慕尼黑工业大学等机构提出的端到端自动驾驶 VLA(Vision-Language-Action)模型,它基于 LLaVA-Qwen 多模态大模型构建,能够融合 3D 环境感知、自车状态与语言指令,直接生成驾驶轨迹,是当前自动驾驶大模型方向的代表性工作之一。
由于该模型参数量级较大,原生加载会面临显存不足、推理延迟高的问题,因此项目采用了 DeepSpeed 框架来优化模型加载与推理流程。
搭建环境和从 HuggingFace 上下载模型的方法,请参考笔者之前的博客:《OpenDriveVLA 环境部署与推理实践》
本文将以模型推理阶段为例,深入解析 OpenDriveVLA 的模型加载核心代码,带你从全局到细节,彻底搞懂大模型加载的完整流程。
一、模型加载流程概览
OpenDriveVLA 的模型加载入口是load_model_with_deepspeed函数,整个流程分为两大核心阶段:预训练模型加载与DeepSpeed 推理引擎初始化,完整流程如下图:
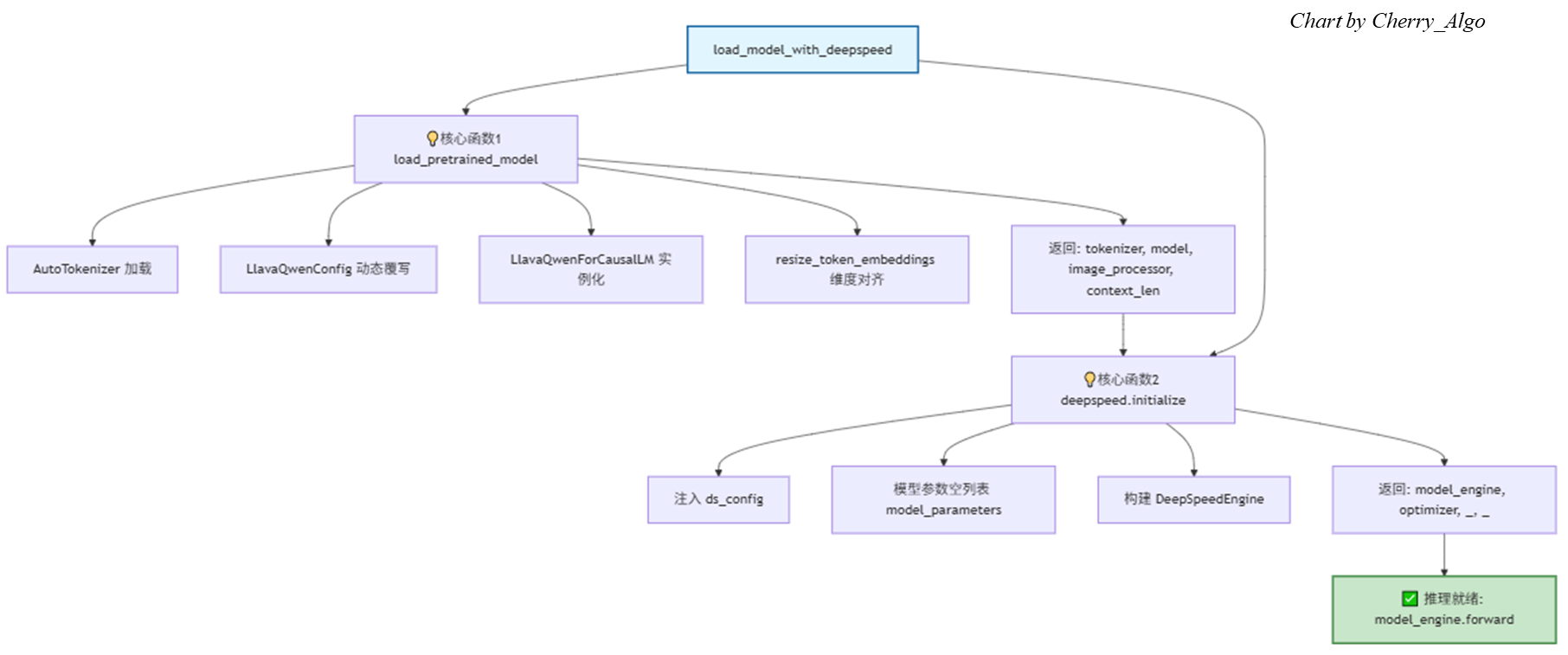
| 函数输出 | 作用 |
|---|---|
tokenizer |
分词器:把文本转换为模型能理解的数字格式 |
model_engine |
DeepSpeed 优化后的推理引擎,是最终用于预测的核心对象 |
image_processor |
图像处理器:将图片转换为模型可识别的特征向量(当前代码中未启用,为 None) |
context_len |
模型最大上下文长度,定义了模型能处理的输入长度上限 |
二、核心函数深度解析
2.1 预训练模型组件加载:load_pretrained_model
该子函数负责加载多模态模型的所有基础组件,包括 Tokenizer、模型配置、权重等,是整个加载流程的基础。
2.1.1 Tokenizer :多模态指令的“翻译官”
Tokenizer 是连接文本与模型输入的核心组件,OpenDriveVLA 中通过 Hugging Face开发的transformers库的AutoTokenizer完成加载:
tokenizer = AutoTokenizer.from_pretrained(model_path)
底层机制
AutoTokenizer 通过读取 tokenizer_config.json 自动路由至具体实现类(本项目中为:Qwen2TokenizerFast)。Fast 版本基于 Rust 的 tokenizers 库,推理吞吐量较 Python 原生版本提升显著。
核心配置文件说明
模型目录下存在两个 Tokenizer 相关的核心配置文件,二者分工明确,共同保证分词行为的一致性:
| 配置文件 | 核心作用 | 类比 |
|---|---|---|
tokenizer.json |
存储词汇表映射、BPE 合并规则、切分算法逻辑 | 📘 字典 + 语法书 |
tokenizer_config.json |
控制默认行为(max_length、add_bos/eos、特殊Token映射) | 📖 使用说明书 |
加载完成后,我们可以看到该 Tokenizer 的具体信息:
Qwen2TokenizerFast(
name_or_path='DriveVLA-Qwen2.5-0.5B-Instruct',
vocab_size=151643,
model_max_length=32768,
is_fast=True,
special_tokens={
'eos_token': '<|im_end|>',
'pad_token': '<|endoftext|>',
'additional_special_tokens': [
'<trajectory>', '<track_start>', '<track_end>',
'<scene_start>', '<scene_end>', '<map_start>', '<map_end>',
... 共17个自动驾驶场景特殊Token
]
}
)
- 模型匹配性:分词器必须与模型严格匹配,错误的分词器会导致输入分布偏移,严重影响模型效果。
- 特殊 Token 扩展:该模型在基础 Qwen 模型的基础上,额外扩展了 17 个自动驾驶场景的特殊 Token,用于分隔不同模态的输入,这些 Token 会在 Tokenizer 加载时自动识别。
2.1.2 模型配置动态覆盖:灵活调整超参数
OpenDriveVLA 支持在不修改原始配置文件的前提下,动态调整模型的超参数,这部分通过自定义的LlavaQwenConfig实现:
# 导入自定义多模态模型配置类
from llava.model.language_model.llava_qwen import LlavaQwenConfig
# 加载原始配置
llava_cfg = LlavaQwenConfig.from_pretrained(model_path)
# 动态覆盖配置
if overwrite_config is not None:
rank0_print(f"Overwriting config with {overwrite_config}")
for k, v in overwrite_config.items():
setattr(llava_cfg, k, v)
实现原理
代码利用 Python 的动态属性机制,在运行时修改配置对象的属性,然后将修改后的配置传入模型加载函数,实现超参数的动态调整。
配置参数示例
{
"_name_or_path": "output/0.5B/stage3_object_agent_trajectory_on_QA_...",
"architectures": ["LlavaQwenForCausalLM"],
// ================== 语言模型基座配置 (Qwen2.5-0.5B) ==================
"attention_dropout": 0.0,
"hidden_act": "silu",
"hidden_size": 896,
"num_hidden_layers": 24,
"vocab_size": 151682,
... ...
// ================== 视觉编码器与多模态对齐 ==================
"mm_vision_tower": "uniad_track_map", // 定制化视觉塔(目标/轨迹/地图)
"mm_projector_type": "mlp2x_gelu", // 双层MLP视觉投影层
... ...
// ================== 训练策略与精度 ==================
"mm_tunable_parts": "mm_vision_tower,mm_mlp_adapter,mm_language_model",
"torch_dtype": "float16"
}
overwrite_config的作用是,在不修改原始模型文件的前提下:
- 快速测试不同的超参数(如attention_dropout等);
- 动态修改参数(mm_tunable_parts),可快速切换 “全参数微调” 与 “仅训练适配器 / 投影层” 模式;
⚠️ 关键风险提示
重点注意:配置与权重的结构一致性
如果你修改的配置参数改变了模型的架构形状(如hidden_size、num_hidden_layers、vocab_size),会导致预训练权重的形状与新模型结构不匹配,引发size mismatch错误,甚至导致模型性能完全丧失。
这种覆盖方式仅适用于修改不改变权重大小的参数,如激活函数类型、标志位、推理相关参数等。
2.1.3 模型权重加载:初始化多模态模型结构
完成配置调整后,代码加载模型的预训练权重,构建完整的多模态模型:
model = LlavaQwenForCausalLM.from_pretrained(
model_path,
low_cpu_mem_usage=True,
attn_implementation=attn_implementation,
config=llava_cfg,
**kwargs
)
具体流程如下:
- 先根据 config 初始化模型结构(搭骨架)
from_pretrained 的第一步是读取配置llava_cfg,然后根据配置中的 architectures 字段(如 LlavaQwenForCausalLM)实例化一个空的、参数随机初始化的模型结构; - 再加载预训练权重(填血肉)
模型结构初始化完成后,函数会从 model_path 读取权重文件model.safetensors,将预训练参数加载到刚才创建的结构中,覆盖随机初始化的参数。
补充知识点1:safetensors 模型权重格式
在 Hugging Face 生态中,.safetensors 正逐渐取代 .pth/.bin 成为主流权重格式,其优势如下:
- 安全性
传统 .pth 基于 Pickle 序列化,当调用 torch.load(‘model.pth’) 加载模型时时,会执行 Python 代码,存在恶意代码注入的风险;而 .safetensors 仅存储纯张量数据,它也只能读取数据,因此非常安全。 - 高性能加载
直接映射文件到内存,避免了在内存中进行频繁的数据拷贝;且支持按需加载部分张量(如多 GPU 训练或推理时,每个 GPU 只加载自己需要的权重),而不需要把整个大文件读入内存。
核心参数解析
-
low_cpu_mem_usage=True:开启 CPU 内存优化,加载模型时最大限度降低 CPU 内存占用,将权重直接映射到目标设备,避免加载过程中的内存峰值,这对于大模型加载至关重要。 -
attn_implementation='sdpa':指定使用 SDPA(Scaled Dot Product Attention)注意力实现。
SDPA 是 PyTorch 2.0+ 引入的高度优化的注意力算子torch.nn.functional.scaled_dot_product_attention,该算子会根据当前硬件(如 NVIDIA Ampere/Hopper 架构)与输入形状,自动择优调用 FlashAttention-2、Memory Efficient Attention 或标准矩阵乘法。相比传统 eager 模式,显存占用下降 30%~50%,推理延迟降低 20% 以上,是自动驾驶低延迟推理的关键优化点。
2.1.4 词嵌入层适配:匹配扩展后的词汇表
由于 OpenDriveVLA 在基础 Qwen 模型的基础上,添加了大量自动驾驶场景的特殊 Token,导致词汇表大小超过了原始模型的嵌入层大小,因此需要调整嵌入层:
model.resize_token_embeddings(len(tokenizer))
训练阶段
通常情况下,resize_token_embeddings 主要是在训练阶段使用的。如2.1.2节提到的 OpenDriveVLA 添加自动驾驶特殊 tokens 后,需要调整嵌入层大小并训练新 tokens 的嵌入。训练完成后保存的模型权重中,嵌入层维度已经是调整后的大小了。
推理阶段
确保模型的嵌入层维度与当前 Tokenizer 的词汇表大小严格对齐,避免因维度不匹配导致的推理错误。
2.2 DeepSpeed 推理引擎初始化:deepspeed.initialize
完成原始模型的加载后,代码通过 DeepSpeed 初始化推理加速引擎,解决大模型的显存与延迟问题:
# 为推理阶段初始化deepspeed engine
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model, # 已经加载的模型预训练权重
config=ds_config, # DeepSpeed的配置字典
model_parameters=[] # 推理阶段无需优化器,为空列表
)
核心作用
deepspeed.initialize是 DeepSpeed 的核心入口,它会:
- 包装预先加载的模型,根据
ds_config中的配置,应用显存优化、算子融合、量化等加速技术。 - 支持分布式推理,将模型拆分到多个 GPU 上,解决单卡显存不足的问题。
DeepSpeed 推理配置
OpenDriveVLA 项目中,推理阶段的ds_config配置示例如下,该配置能够降低显存占用,提升推理速度:
ds_config =
{'bf16': {'enabled': True},
'fp16': {'enabled': False},
'inference_mode': True,
'train_micro_batch_size_per_gpu': 1,
... ...
}
补充知识点2:bf16 (BFloat16) 精度格式
计算机中浮点数由 符号位、指数位、尾数位三部分组成,三种主流精度的位宽如下:
- FP32(标准单精度):1 位符号 + 8 位指数 + 23 位尾数(共 32 位)
- FP16(半精度):1 位符号 + 5 位指数 + 10 位尾数(共 16 位)
- BF16(脑浮点):1 位符号 + 8 位指数 + 7 位尾数(共 16 位)
ds_config中的设置:
- FP16(置为False):为 “极致节省空间” 设计,同时砍掉了 FP32 的指数位(8→5)和尾数位(23→10),虽压缩了体积,但数值范围大幅缩小。
- BF16(置为True):为 “兼容 FP32 且易用” 设计,完整保留了 FP32 的 8 位指数位,仅大幅精简尾数位(23→7),因此数值动态范围与 FP32 一致,不容易溢出。本项目使用了
bf16作为推理时的计算精度,中间计算结果都会自动以 BF16 格式进行,从而在保证效果的同时降低显存占用、提升推理速度。
为什么model_parameters是空的?
- 在训练阶段,需要传入模型参数来初始化优化器,用于更新权重。
- 而在推理阶段,无需反向传播与梯度更新,传空列表可跳过 Optimizer 显存分配,节省大量 GPU 内存。
三、总结
OpenDriveVLA 的模型加载流程是一个典型的多模态大模型推理部署流程,它结合了 Hugging Face 生态的便捷性与 DeepSpeed 的推理优化能力,通过动态调整配置、预训练模型加载、推理引擎初始化等流程,实现了大模型的高效加载与低延迟推理。
理解这个流程,不仅能够帮助我们更好地部署OpenDriveVLA 模型,也能为其他多模态大模型的推理部署提供参考。
标签: OpenDriveVLA 大模型推理 DeepSpeed 自动驾驶 多模态模型
本文基于 OpenDriveVLA 推理部署源码梳理,笔者的环境依赖版本基于deepspeed=0.14.4与transformers=4.37.0。如有工程落地问题,欢迎在评论区交流探讨。
(本文为CSDN原创,转载请注明出处。)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)