ABMamba:基于深度状态空间模型的高效视频字幕生成
视频字幕生成是视频理解领域的一项基础任务,其目标是给定一个视频输入,自动生成一段自然语言描述,准确概括视频中的视觉内容。这项任务具有广泛的实际应用价值,包括但不限于视频摘要、视障辅助、家庭服务机器人的场景理解以及视频内容检索等。从技术角度来看,视频字幕生成是一个典型的跨模态生成问题。模型需要同时处理两个异质的信息源:视觉模态(视频帧序列)和语言模态(文本描述)。这两个模态在数据结构上存在本质差异—
1 文献精读:《ABMamba:Aligned Hierarchical Bidirectional Scan Mamba for Video Captioning》
本文精读的文献来源为Yashima等人发表于arXiv预印本平台的工作“ABMamba: Aligned Hierarchical Bidirectional Scan Mamba for Video Captioning”(论文编号:2604.08050v1)。该工作聚焦于视频字幕生成任务,提出了一个基于深度状态空间模型的完全开源多模态大语言模型,通过引入对齐分层双向扫描模块,在保持与主流方法相当性能的同时实现了约三倍的推理吞吐量。
视频理解是人工智能领域最具挑战性的任务之一。与静态图像不同,视频数据具有天然的时空复杂性——不仅每一帧内部蕴含着丰富的空间语义信息,帧与帧之间还存在着复杂的时间依赖关系。这些时间依赖跨越不同的时间尺度:有些动作在几帧内即可完成(如眨眼),而有些事件则需要数十秒甚至更长时间才能完整展现(如烹饪过程)。如何高效地建模这种多尺度时间动态,同时保持计算上的可行性,是视频理解任务的核心挑战。
传统的视频字幕生成方法通常采用基于Transformer的架构。Transformer的自注意力机制虽然能够捕捉序列中任意两个位置之间的依赖关系,但其计算复杂度随序列长度呈二次增长。对于一个包含T帧的视频,如果每帧被划分为N个图像块,那么输入到语言模型的视觉令牌总数达到T×N。当视频较长时,这一数值迅速膨胀,导致计算资源消耗急剧增加。为了应对这一挑战,现有方法往往采取折中策略,例如下采样(丢弃部分帧)或学习投影(将多帧压缩为少量令牌),但这些操作不可避免地会丢失细粒度的时序信息。
正是在这一背景下,Yashima等人提出了ABMamba模型。该工作的核心洞察在于:视频的时序建模不一定需要Transformer的全局注意力机制。深度状态空间模型,特别是Mamba架构,通过线性的计算复杂度实现了高效的序列建模,为视频理解开辟了新的可能性。本文将对该论文进行系统性的解读,从理论基础到模型架构,从实验设计到结果分析,力求为读者呈现一份全面深入的技术文献精读。
2 研究背景与动机
2.1 视频字幕生成任务概述
视频字幕生成是视频理解领域的一项基础任务,其目标是给定一个视频输入,自动生成一段自然语言描述,准确概括视频中的视觉内容。这项任务具有广泛的实际应用价值,包括但不限于视频摘要、视障辅助、家庭服务机器人的场景理解以及视频内容检索等。
从技术角度来看,视频字幕生成是一个典型的跨模态生成问题。模型需要同时处理两个异质的信息源:视觉模态(视频帧序列)和语言模态(文本描述)。这两个模态在数据结构上存在本质差异——视觉信息是高维、连续、冗余的,而语言信息是离散、符号化、结构化的。因此,视频字幕生成的核心挑战在于如何有效地将视觉信息对齐到语言空间,并在生成过程中保持对视频内容的忠实表达。
2.2 现有方法的局限性与技术瓶颈
当前主流的视频多模态大语言模型主要基于Transformer架构。Transformer通过自注意力机制实现了序列中任意位置之间的直接信息交互,这一特性使其在捕捉长距离依赖方面具有天然优势。然而,这种能力是以高昂的计算代价换取的。
具体而言,对于长度为L的输入序列,自注意力机制需要计算一个L×L的注意力矩阵,其计算复杂度和内存复杂度均为O(L²)。当L较小时(如数百个令牌),这一开销尚可接受;但当L增长到数万甚至数十万时,O(L²)的复杂度变得难以承受。在视频理解任务中,视觉令牌的数量通常为T×N——假设一个10秒的视频每秒采样2帧(T=20),每帧被划分为196个图像块(N=196),那么视觉令牌总数就达到了3920个。这还仅仅是一个短视频的规模。对于长视频(如电影片段),令牌数量可能达到数万甚至更多。在这样的规模下,Transformer的自注意力计算会迅速耗尽GPU内存。
为了解决这一问题,现有方法采取了多种妥协策略。例如,Video-ChatGPT和Video-LLaVA通过简单的帧级视觉编码后直接输入语言模型,但这种方法缺乏对帧间时序依赖的显式建模,难以捕捉因果关系。Video-XL则引入了分块总结策略,使用潜在令牌进行高效的长视频处理,但这种方法以牺牲逐帧粒度和精细时序细节为代价。这些方法的共同问题在于:时序信息的压缩或丢弃不可避免地导致信息损失,从而影响字幕生成的准确性和完整性。
2.3 深度状态空间模型(Deep SSM)的兴起
面对Transformer的计算瓶颈,研究者开始探索替代性的序列建模范式。深度状态空间模型便是其中最具潜力的一支。
状态空间模型的理论渊源可以追溯到20世纪60年代的控制理论。经典的状态空间模型通过一个隐藏状态向量来描述动态系统的演化:给定当前输入,系统更新其内部状态并产生输出。在深度学习中,SSM被重新诠释为一种序列建模机制,其核心思想是将输入序列到输出序列的映射表示为一个状态演化过程。
Structured State Space Sequence Model的提出是SSM在深度学习领域的重要里程碑。S4通过精心设计的参数化方式,使得状态转移矩阵A具有特殊的结构,从而能够高效地进行计算。更重要的是,S4在训练阶段可以采用卷积形式进行并行计算,在推理阶段则切换为循环形式实现高效的逐令牌生成。这种“训练卷积、推理循环”的双重模式是SSM架构的核心优势。
Mamba则是S4的史诗级升级。Mamba的核心创新在于引入了选择性机制——传统的SSM是线性时不变系统,其参数(A, B, C, Δ)与输入无关,是静态的;而Mamba让这些参数成为输入的函数,实现了数据依赖的状态转移。这一看似简单的改动带来了质的飞跃:模型能够根据当前输入动态地决定“记住什么”和“遗忘什么”,从而在保持线性计算复杂度的同时,具备了与Transformer相当甚至更优的表达能力。
从计算复杂度的角度比较:Transformer的复杂度为O(L²),而Mamba的复杂度为O(L)。对于长度为10万的序列,这意味着计算量相差数个数量级。此外,Mamba的常数因子也远小于Transformer,因为其核心运算(矩阵-向量乘法)在现代GPU上具有极高的计算效率。
2.4 ABMamba的核心创新点
在上述背景下,ABMamba提出了三个核心创新点,直击现有视频理解方法的技术痛点。
创新点一:首个基于深度SSM的完全开源视频MLLM。 ABMamba选择Mamba作为语言骨干网络,替代了传统的Transformer注意力机制,从而实现了序列长度上的次二次计算复杂度。这一架构选择使得ABMamba能够处理更长的视频输入,而不受计算资源的严重限制。
创新点二:对齐分层双向扫描模块。 这是ABMamba最具原创性的贡献。AHBS模块通过多个并行的时序处理通路,在不同时间分辨率上对视频进行扫描,同时捕捉细粒度的局部动作和粗粒度的全局事件。该模块采用双向扫描策略——既沿正向时序进行信息传播,也沿反向时序进行回溯——从而有效克服了单向SSM在处理非因果视觉数据时的局限性。
创新点三:卓越的效率表现。 在保持与基线方法相当性能的前提下,ABMamba实现了约三倍的推理吞吐量。这一效率优势使其特别适合需要实时响应的应用场景,如机器人视觉导航、自动驾驶感知等。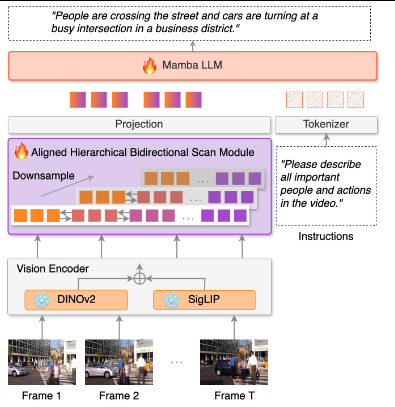
表1总结了Transformer与SSM/Mamba在核心特性上的对比:
| 特性 | Transformer | SSM / Mamba |
|---|---|---|
| 计算复杂度 | O(L²) | O(L) |
| 内存复杂度 | O(L²) | O(L) |
| 长序列处理 | 受限于二次复杂度 | 线性扩展 |
| 训练并行性 | 完全并行 | 卷积形式并行 |
| 推理效率 | 需缓存所有历史键值 | 固定大小的状态向量 |
| 选择性机制 | 隐式(通过注意力权重) | 显式(Mamba的选择性SSM) |
| 核心运算 | 矩阵乘法 + Softmax | 矩阵-向量乘法 |
2.5 “完全开源”的内涵与意义
ABMamba特别强调了其“完全开源”(fully open)的属性。在论文中,“完全开源”指的是以下三个层面的资源均可公开获取:开源数据集、开源代码以及训练好的模型权重。
这一承诺具有重要的学术意义和实际价值。首先,开源促进了研究的可复现性——其他研究者可以基于相同的代码和数据进行实验验证,或在此基础上进行改进。其次,开源降低了视频多模态大语言模型的研究门槛——并非所有研究机构都具备从头训练大模型的计算资源,但可以基于开源权重进行微调或应用。最后,开源推动了整个社区的协同发展——当核心算法被广泛使用和测试时,其潜在的局限性和改进空间也会更快地被识别和解决。
3 状态空间模型的理论基础
3.1 连续状态空间模型的基本原理
状态空间模型起源于控制理论中对动态系统的数学描述。对于一个连续时间系统,其行为可以用一对微分方程来刻画:
状态方程:
dh(t)dt=Ah(t)+Bx(t)\frac{d\mathbf{h}(t)}{dt} = \mathbf{A}\mathbf{h}(t) + \mathbf{B}\mathbf{x}(t)dtdh(t)=Ah(t)+Bx(t)
输出方程:
y(t)=Ch(t)+Dx(t)\mathbf{y}(t) = \mathbf{C}\mathbf{h}(t) + \mathbf{D}\mathbf{x}(t)y(t)=Ch(t)+Dx(t)
其中,x(t)∈R\mathbf{x}(t) \in \mathbb{R}x(t)∈R 是时刻 ttt 的输入(标量),h(t)∈RQ\mathbf{h}(t) \in \mathbb{R}^{Q}h(t)∈RQ 是 QQQ 维的隐藏状态向量,y(t)∈R\mathbf{y}(t) \in \mathbb{R}y(t)∈R 是输出。A∈RQ×Q\mathbf{A} \in \mathbb{R}^{Q \times Q}A∈RQ×Q 是状态转移矩阵,描述了隐藏状态如何随时间演化;B∈RQ×1\mathbf{B} \in \mathbb{R}^{Q \times 1}B∈RQ×1 是输入投影矩阵;C∈R1×Q\mathbf{C} \in \mathbb{R}^{1 \times Q}C∈R1×Q 是输出投影矩阵;D∈R1×1\mathbf{D} \in \mathbb{R}^{1 \times 1}D∈R1×1 是直连项。
从直观上理解,这个模型描述了一个"记忆系统":系统通过隐藏状态 h(t)\mathbf{h}(t)h(t) "记住"了历史输入的部分信息。当前时刻的输入 x(t)\mathbf{x}(t)x(t) 会通过 B\mathbf{B}B 矩阵影响隐藏状态的变化,而输出 y(t)\mathbf{y}(t)y(t) 则是当前隐藏状态和输入的线性组合。
在经典的SSM中,矩阵A、B、C、D是固定的常数矩阵,与输入无关。这意味着系统对输入的处理方式是线性和时不变的——无论输入什么内容,系统的“记忆”机制都是一样的。这种设计虽然在数学上简洁,但在处理复杂的自然语言或视觉序列时存在表达能力的局限。
3.2 从连续到离散:零阶保持离散化
在实际的深度学习应用中,我们处理的是离散的序列数据(如单词索引、图像块特征),而非连续的时间信号。因此,需要将连续SSM转换为离散形式。
离散化过程引入了一个时间尺度参数Δ∈R+\Delta \in \mathbb{R}_{+}Δ∈R+,它决定了连续时间中采样的间隔。采用零阶保持方法,可以得到离散化的状态空间方程:
hk=A~hk−1+B~xk \mathbf{h}_k = \tilde{\mathbf{A}}\mathbf{h}_{k-1} + \tilde{\mathbf{B}}\mathbf{x}_k hk=A~hk−1+B~xk
yk=Chk+Dxk \mathbf{y}_k = \mathbf{C}\mathbf{h}_k + \mathbf{D}\mathbf{x}_k yk=Chk+Dxk
其中:
A~=exp(ΔA) \tilde{\mathbf{A}} = \exp(\Delta \mathbf{A}) A~=exp(ΔA)
B~=(ΔA)−1(exp(ΔA)−I)⋅ΔB \tilde{\mathbf{B}} = (\Delta \mathbf{A})^{-1}(\exp(\Delta \mathbf{A}) - \mathbf{I}) \cdot \Delta \mathbf{B} B~=(ΔA)−1(exp(ΔA)−I)⋅ΔB
这组递推关系揭示了SSM与循环神经网络之间的深刻联系。实际上,离散化后的SSM正是一个线性RNN——当前隐藏状态hk\mathbf{h}_khk是前一个隐藏状态hk−1\mathbf{h}_{k-1}hk−1和当前输入xk\mathbf{x}_kxk的线性组合。
然而,这种循环形式在训练时存在效率问题:每个时间步的计算依赖于前一步的结果,无法并行化。为了解决这一问题,S4提出了卷积形式的等价表示。
3.3 卷积形式与训练-推理的双模式
通过展开递推关系,我们可以将SSM的输出表示为输入与一个"核"的卷积:
y=K~∗x\mathbf{y} = \tilde{\mathbf{K}} \ast \mathbf{x}y=K~∗x
其中卷积核 K~\tilde{\mathbf{K}}K~ 定义为:
K~=(CB~+D, CA~B~+D, CA~2B~+D, …, CA~L−1B~+D)\tilde{\mathbf{K}} = (\mathbf{C}\tilde{\mathbf{B}} + \mathbf{D},\ \mathbf{C}\tilde{\mathbf{A}}\tilde{\mathbf{B}} + \mathbf{D},\ \mathbf{C}\tilde{\mathbf{A}}^{2}\tilde{\mathbf{B}} + \mathbf{D},\ \dots,\ \mathbf{C}\tilde{\mathbf{A}}^{L-1}\tilde{\mathbf{B}} + \mathbf{D})K~=(CB~+D, CA~B~+D, CA~2B~+D, …, CA~L−1B~+D)
这里 LLL 是序列长度。这个卷积核只依赖于模型参数,与输入无关。
这一转换的意义在于:在训练阶段,我们可以将输入序列与预先计算好的卷积核进行卷积运算,利用快速傅里叶变换实现高效的并行计算。在推理阶段(自回归生成),我们则切换回循环形式,每个时间步只需更新隐藏状态并计算输出,无需重新处理整个序列。
这种“训练卷积、推理循环”的双模式设计是SSM架构区别于RNN和Transformer的关键特性。RNN在训练时受限于串行计算,Transformer在推理时需要缓存所有历史键值,而SSM兼取二者之长。
3.4 Mamba的选择性机制
Mamba对传统SSM的核心升级在于引入了选择性机制。在S4中,参数 Δ,A,B,C\Delta, \mathbf{A}, \mathbf{B}, \mathbf{C}Δ,A,B,C 是输入无关的常数——这是一个线性时不变系统。Mamba打破了这一约束,让这些参数成为输入的函数:
B=sB(x),C=sC(x),Δ=sΔ(x)\mathbf{B} = s_B(\mathbf{x}), \quad \mathbf{C} = s_C(\mathbf{x}), \quad \Delta = s_\Delta(\mathbf{x})B=sB(x),C=sC(x),Δ=sΔ(x)
其中 sBs_BsB、sCs_CsC、sΔs_\DeltasΔ 是可学习的线性投影加上适当的激活函数。
选择性机制使得模型能够根据输入内容动态调整信息处理的方式。具体而言,当 Δ\DeltaΔ 较大时,模型会更重视当前输入,对隐藏状态进行大幅度更新;当 Δ\DeltaΔ 较小时,当前输入的影响被削弱,模型更依赖于历史信息。这种数据依赖的适应性是Mamba表达能力超越传统SSM的关键。
从信息论的角度看,选择性机制赋予了模型"注意力"的能力——模型可以选择性地"关注"哪些输入,"忽略"哪些输入。但与传统注意力机制不同的是,这种选择性是通过状态更新实现的,而非通过计算全局相似度矩阵,因此保持了 O(L)O(L)O(L) 的计算复杂度。
3.5 SSM在视觉领域的适配
将SSM从一维序列建模扩展到二维视觉理解并非易事。视觉数据具有与文本不同的特性:图像是空间结构化的,信息以二维网格形式组织,不存在天然的“序列”顺序。如何将二维图像映射为一维序列,同时保持空间邻近性,是一个需要仔细设计的问题。
早期的视觉SSM方法探索了多种扫描策略。S4ND通过垂直和水平两个方向分别扫描图像,将得到的向量外积作为卷积核。2D-SSM则引入了明确区分垂直和水平状态转移的矩阵。Vim针对视觉数据特点,提出了基于Mamba的双向扫描方法。随后,研究者开发了多种扫描策略,包括之字形扫描、希尔伯特扫描和交叉扫描,以更好地捕捉视觉数据的非因果结构。
然而,这些方法主要针对静态图像。视频数据带来了额外的挑战:除了空间维度,还需要处理时间维度。时间维度具有天然的因果顺序(过去的帧影响未来的理解),但又不同于文本的严格因果性(视频中有时需要回顾前面的内容来理解当前的事件)。ABMamba的AHBS模块正是在这一背景下提出的创新解决方案。
表2总结了从S4到Mamba再到ABMamba的技术演进:
| 模型 | 核心创新 | 计算复杂度 | 适用领域 | 局限性 |
|---|---|---|---|---|
| S4 | 结构化状态空间、卷积训练+循环推理 | O(L) | 一维序列(音频、文本) | 参数静态、表达能力有限 |
| Mamba | 选择性机制、数据依赖参数 | O(L) | 一维序列(语言建模) | 单向处理、不适合视觉 |
| VideoMamba | 视频专用双向SSM、时空扫描 | O(L) | 视频识别 | 不与语言集成 |
| ABMamba | AHBS、多分辨率双向扫描、完全开源 | O(L) | 视频字幕生成 | — |
4 ABMamba模型架构解析
4.1 整体架构概览
ABMamba的总体架构如图2所示。模型由三个核心模块构成:视觉编码器、对齐分层双向扫描模块和基于Mamba的大语言模型。
输入数据包含两个部分:视觉输入 xvision=(xvision(1),xvision(2),…,xvision(T))\mathbf{x}_{\mathrm{vision}} = (\mathbf{x}_{\mathrm{vision}}^{(1)}, \mathbf{x}_{\mathrm{vision}}^{(2)}, \dots, \mathbf{x}_{\mathrm{vision}}^{(T)})xvision=(xvision(1),xvision(2),…,xvision(T)) 表示视频的 TTT 个帧,每个帧的尺寸为 H×WH \times WH×W;文本输入 xtext\mathbf{x}_{\mathrm{text}}xtext 是经过词元化的自然语言提示。
整个处理流程可以概括为:视觉编码器独立处理每一帧,提取空间特征;AHBS模块在这些帧特征上进行多分辨率、双向的时序建模,将视觉信息整合为语言模型可理解的形式;Mamba-LLM接收融合后的视觉-语言序列,以自回归方式生成字幕。
这一架构设计的核心理念是“分而治之”——空间理解由视觉编码器负责,时序建模由AHBS模块负责,语言生成由Mamba-LLM负责。各模块职责清晰,且AHBS模块的设计具有模块化特性,理论上可以移植到其他多模态架构中。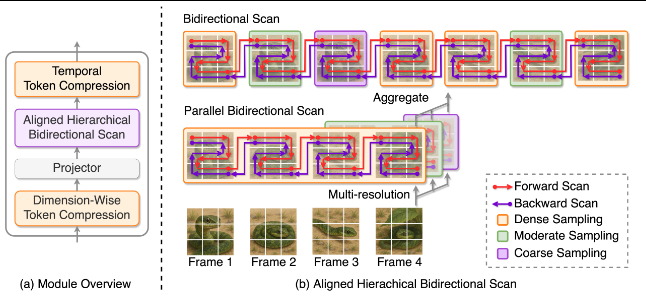
4.2 视觉编码器设计
ABMamba的视觉编码器采用了双编码器策略,同时使用SigLIP和DINOv2作为视觉特征提取器。
SigLIP基于图像-文本对比学习框架训练,其优势在于提供鲁棒的语义对齐能力。通过对齐图像和文本的嵌入空间,SigLIP能够提取与语言语义高度相关的视觉特征,这对于视频字幕生成任务尤为重要——模型需要将视觉内容“翻译”为语言描述,语义对齐的质量直接影响翻译的准确性。
DINOv2则采用自监督学习方法训练,不依赖任何人工标注。其优势在于能够捕捉细粒度的视觉特征,包括纹理、边缘、局部模式等细节信息。这些细节在字幕生成中往往至关重要——例如,描述“一个男人用玻璃刮清洁窗户”时,需要识别出“玻璃刮”这一具体工具,而非笼统地说“清洁工具”。
对于视频中的每一帧 xvision(t)\mathbf{x}_{\mathrm{vision}}^{(t)}xvision(t),首先将其划分为 NpN_pNp 个不重叠的图像块,每个块的大小为 p×pp \times pp×p。划分后的图像块分别输入SigLIP和DINOv2编码器,得到两个特征张量:
VSigLIP(t)∈RNp×ds,VDINOv2(t)∈RNp×dd\mathbf{V}_{\mathrm{SigLIP}}^{(t)} \in \mathbb{R}^{N_p \times d_s},\quad \mathbf{V}_{\mathrm{DINOv2}}^{(t)} \in \mathbb{R}^{N_p \times d_d}VSigLIP(t)∈RNp×ds,VDINOv2(t)∈RNp×dd
其中 dsd_sds 和 ddd_ddd 分别是两个编码器的输出维度。随后,这两个特征沿特征维度拼接,形成统一的视觉表示:
V(t)=[VSigLIP(t),VDINOv2(t)]∈RNp×dv\mathbf{V}^{(t)} = [\mathbf{V}_{\mathrm{SigLIP}}^{(t)}, \mathbf{V}_{\mathrm{DINOv2}}^{(t)}] \in \mathbb{R}^{N_p \times d_v}V(t)=[VSigLIP(t),VDINOv2(t)]∈RNp×dv
其中 dv=ds+ddd_v = d_s + d_ddv=ds+dd。
这种双编码器设计被近期多项多模态大语言模型工作所采用,研究表明其能够显著提升视觉理解能力。SigLIP提供语义层面的“大局观”,DINOv2提供细节层面的“微观视角”,二者互补协同,共同构成丰富的视觉特征。
4.3 AHBS模块:对齐分层双向扫描
AHBS模块是ABMamba的核心创新,也是模型能够高效处理视频时序信息的关键。该模块的设计理念是:视频中的时序动态发生在多个时间尺度上,单一分辨率的处理难以兼顾局部动作的精细捕捉和全局事件的高层抽象。
模块的输入是V(1),V(2),…,V(T)∈RT×Np×dv\mathbf{V}^{(1)}, \mathbf{V}^{(2)}, \dots, \mathbf{V}^{(T)} \in \mathbb{R}^{T \times N_p \times d_v}V(1),V(2),…,V(T)∈RT×Np×dv,即T帧的视觉特征,每帧有NpN_pNp个空间块。在进入多分辨率处理之前,首先通过空间下采样层降低空间维度,得到Vd∈RT×Nd×dv\mathbf{V}_{\mathrm{d}} \in \mathbb{R}^{T \times N_{\mathrm{d}} \times d_v}Vd∈RT×Nd×dv。这一步骤的主要目的是降低计算复杂度,将模型的计算资源聚焦于时序建模而非空间细节。
随后,Vd\mathbf{V}_{\mathrm{d}}Vd被输入到M条并行的时序处理通路中,每条通路对应不同的时间分辨率。对于第m条通路,通过时间下采样得到Vm∈RTm×Nd×dv\mathbf{V}_m \in \mathbb{R}^{T_m \times N_{\mathrm{d}} \times d_v}Vm∈RTm×Nd×dv,其中时间长度$T_m = \lfloor T / 2^{m-1} \rfloor。这意味着:
- 通路1:T1=TT_1 = TT1=T(原始分辨率)
- 通路2:T2≈T/2T_2 \approx T/2T2≈T/2(2倍下采样)
- 通路3:T3≈T/4T_3 \approx T/4T3≈T/4(4倍下采样)
- 依此类推
这种金字塔式的多分辨率结构使得模型能够同时捕捉不同时间尺度上的动态模式。细粒度的通路(小下采样倍数)捕捉局部、快速变化的动作;粗粒度的通路(大下采样倍数)捕捉全局、缓慢演变的场景。
在每个通路上,对Vm\mathbf{V}_mVm应用双向扫描模块。双向扫描的核心思想是同时沿正向和反向两个方向处理时序序列:
Hv=Aggregatem(SSM(Vm)+SSM(frev(Vm))) \mathbf{H}_{\mathrm{v}} = \underset{m}{\mathrm{Aggregate}}\left( \mathrm{SSM}(\mathbf{V}_m) + \mathrm{SSM}(f_{\mathrm{rev}}(\mathbf{V}_m)) \right) Hv=mAggregate(SSM(Vm)+SSM(frev(Vm)))
其中SSM(⋅)\mathrm{SSM}(\cdot)SSM(⋅)表示Mamba操作,frev(⋅)f_{\mathrm{rev}}(\cdot)frev(⋅)是将序列反转的函数,Aggregate(⋅)\mathrm{Aggregate}(\cdot)Aggregate(⋅)是聚合函数(论文中使用加法作为聚合方式)。
正向扫描捕捉从过去到未来的因果依赖,符合人类观看视频的自然顺序;反向扫描捕捉从未来到过去的“回溯”依赖,使模型能够利用后续帧的信息来理解当前帧——例如,只有看到有人摔倒,才能理解前面那一步踩空的意义。双向扫描的结合使得模型能够更全面地理解视频中的时序结构。
最后,所有通路的输出通过聚合函数融合,得到最终的视觉特征表示Hv∈RT×Nd×dv\mathbf{H}_{\mathrm{v}} \in \mathbb{R}^{T \times N_{\mathrm{d}} \times d_v}Hv∈RT×Nd×dv。这一表示既保留了不同时间尺度的信息,又通过双向扫描增强了对时序依赖的捕捉能力。
4.4 Mamba语言骨干网络
ABMamba采用Mamba作为大语言模型的骨干架构。选择Mamba而非Transformer的核心原因在于其线性的计算复杂度,这对于处理视觉-语言融合后的长序列尤为重要。
Mamba-LLM的输入是视觉特征Hvision\mathbf{H}_{\mathrm{vision}}Hvision与文本嵌入的拼接序列。视觉特征已经过AHBS模块的处理,以适合语言模型的形式呈现。
Mamba骨干网络由多个相同的基本块堆叠而成,每个基本块包含:
- 一维卷积层:对输入序列进行局部特征提取
- Mamba块:核心的选择性SSM操作
- 残差连接:将输入与输出相加,缓解梯度消失问题
- 层归一化:稳定训练过程
Mamba块的核心是选择性SSM操作,其计算流程可以概括为:
- 输入x\mathbf{x}x通过线性投影得到扩展表示
- 基于输入计算选择性参数Δ\DeltaΔ、B\mathbf{B}B、C\mathbf{C}C
- 根据Δ\DeltaΔ离散化得到A~\tilde{\mathbf{A}}A~和B~\tilde{\mathbf{B}}B~
- 执行SSM递推,更新隐藏状态并产生输出
- 通过SiLU激活函数和门控机制增强非线性
这种设计使得Mamba在保持线性复杂度的同时,具备了处理复杂序列依赖的能力。
在推理阶段,Mamba-LLM以自回归方式生成字幕。设当前已生成的令牌序列为y^<i\hat{\mathbf{y}}_{<i}y^<i,模型预测下一个令牌y^i\hat{y}_iy^i的概率分布:
y^i=argmaxy^∈Vpθ(y^∣xvision,xtext,y^<i) \hat{y}_i = \arg\max_{\hat{y} \in \mathcal{V}} p_{\theta}(\hat{y} \mid \mathbf{x}_{\mathrm{vision}}, \mathbf{x}_{\mathrm{text}}, \hat{\mathbf{y}}_{<i}) y^i=argy^∈Vmaxpθ(y^∣xvision,xtext,y^<i)
其中V\mathcal{V}V是词汇表。模型使用交叉熵损失作为训练目标,最大化正确字幕序列的生成概率。
4.5 训练策略与优化
ABMamba的训练过程采用了简化的策略。与LLaVA风格范式中常见的“预对齐阶段+微调阶段”两阶段训练不同,ABMamba直接对视觉-语言投影器和完整的LLM骨干网络进行联合微调。
训练数据来自两个主要来源:首先是LLaVA 1.5引入的665K图像-文本指令数据集,该数据集涵盖了COCO、Visual Genome、GQA等多个来源的监督信号,提供了丰富的视觉-语言对齐样本。其次是Video-ChatGPT引入的100K视频-文本指令样本,这些样本通过人工辅助和半自动标注相结合的方式生成,专门用于视频理解任务的训练。
训练配置方面,模型在16块NVIDIA H200 SXM GPU上进行训练,每块GPU显存为141GB,总训练时间约8小时。评估则使用单块NVIDIA A100 GPU(40GB显存)。
这一训练策略的选择体现了“少即是多”的设计理念。作者发现,省略预对齐阶段并未导致性能下降,反而通过简化流程降低了训练开销。这表明视觉-语言投影器与Mamba-LLM可以在端到端微调过程中自然地对齐,无需额外的前期对齐步骤。
5 实验设计与结果分析
5.1 实验设置
评估ABMamba性能的实验在标准视频字幕基准测试MSR-VTT和VATEX上进行。
MSR-VTT是视频字幕领域的经典数据集,包含10,000个视频片段,总时长约41.2小时。每个视频片段标注约20个英文字幕,平均时长为15秒。数据集的训练集包含6,153个片段,验证集497个片段,测试集2,090个片段。视频内容覆盖20个类别,包括音乐、体育、游戏、新闻等,具有较好的多样性。
VATEX是一个更大规模的多语言视频描述数据集,包含41,250个视频片段和825,000条中英文字幕。与MSR-VTT相比,VATEX在人类活动的多样性和描述的语言复杂性方面更具挑战性。每个视频片段有10条英文字幕和10条中文字幕,分别来自不同的人类标注者。
数据预处理方面,所有视频被均匀采样T帧(论文中T=16),并将每帧尺寸调整为384×384。评估指标采用视频字幕领域的标准度量:BLEU(双语评估替补)、ROUGE-L(面向召回的摘要评估)、METEOR(显式排序翻译评估度量)、CIDEr(共识图像描述评估)以及PAC-S。
基线方法涵盖了多个代表性模型,包括:完全开源视频MLLM(Video-ChatGPT、Video-LLaVA、LLaVA-OneVision)和小型视频MLLM(InternVL2.5、VideoLLaMA3)。为了进行公平比较,作者将参数量控制在4B以下。
5.2 定量结果分析
表1展示了ABMamba与基线方法在VATEX和MSR-VTT测试集上的定量比较结果。以下从多个维度进行分析。
字幕质量。 在VATEX基准上,ABMamba取得了28.6的BLEU4分数,比第二好的模型高出4.1个百分点。在MSR-VTT基准上,ABMamba取得了23.6的BLEU4分数,同样优于所有基线方法。CIDEr分数方面,ABMamba在VATEX上达到44.4,在MSR-VTT上达到27.4,均处于领先位置。
需要特别指出的是,ABMamba的参数量仅为3.6B,而大多数基线方法的参数量在7B左右(如Video-LLaVA和LLaVA-OneVision)。在更小的参数量下取得相当甚至更好的性能,充分证明了ABMamba架构的高效性——模型的容量被更有效地利用。
推理效率。 这是ABMamba最突出的优势。在MSR-VTT基准上,ABMamba的平均解码速度达到95.4 tokens/s,而最快的基线方法Video-ChatGPT仅为38.1 tokens/s。这意味着ABMamba的推理吞吐量约为基线的三倍。
这一效率优势源于Mamba架构的线性计算复杂度。在解码阶段,Transformer需要缓存所有历史位置的键值向量,每次生成新令牌时都要重新计算与所有历史令牌的注意力,复杂度随序列长度线性增长。相比之下,Mamba只需维护一个固定大小的隐藏状态向量,每个新令牌的计算只依赖于当前状态和输入,复杂度恒定。对于长序列生成任务,这种差异会被显著放大。
与闭源模型的对比。 论文还报告了闭源商业模型Gemini-1.5-Pro在相同任务上的性能作为参考。需要指出的是,闭源模型通常在远超开源模型的参数量和数据规模上训练,因此直接比较性能并不公平。然而,ABMamba在某些指标上(如VATEX上的BLEU4)已经超越了Gemini-1.5-Pro,这进一步证明了ABMamba架构的有效性。
5.3 定性结果与案例研究
图4展示了ABMamba与基线方法的定性比较结果。以下对两个典型案例进行深入分析。
案例一:窗户清洁场景。 视频展示了一个男人用玻璃刮清洁窗户的画面。ABMamba生成的描述为“一个男人正在用玻璃刮清洁窗户”,准确地识别出了动作(清洁)、工具(玻璃刮)和对象(窗户)。相比之下,InternVL2.5错误地生成了“男人用喷雾瓶喷洒窗户”——这一描述与画面内容完全不符,属于典型的幻觉错误。LLaVA-OneVision则生成了“一个男人正在清洁一面大玻璃窗,专注于下部区域”——虽然大致正确,但“专注于下部区域”这一细节是模型自行编造的,因为画面中男人正在清洁整个窗户。这一案例展示了ABMamba在减少幻觉方面的优势。
案例二:掷斧头场景。 视频展示了一群人在场地上向目标投掷斧头。ABMamba生成的描述为“一群人正站在场地上向目标投掷斧头”,准确地捕捉了多个演员、核心动作和交互对象。InternVL2.5生成了“穿蓝衬衫的男人正瞄准板子”,只关注了单个演员,且将“投掷”弱化为“瞄准”,未能准确描述动作的核心性质。LLaVA-OneVision则生成了“一个男人站在碎石路上竖起大拇指,周围是穿着各种服饰的人”,完全偏离了视频的主要内容,聚焦于一个可能出现在序列末尾的孤立帧。这一案例展示了ABMamba在捕捉全局事件而非局部细节方面的能力。
从定性结果可以看出,ABMamba的性能优势体现在三个层面:动作识别的准确性、幻觉现象的抑制、以及对整体事件而非局部细节的把握。这些优势可归功于AHBS模块的多分辨率双向扫描设计,使模型能够同时关注局部动作和全局场景。
5.4 消融实验:AHBS模块设计验证
论文对AHBS模块的关键设计进行了系统的消融研究,为设计选择的合理性提供了实证支撑。
扫描方向的消融。 表2比较了不同扫描配置对性能的影响。变体(a)不使用任何扫描(相当于仅通过空间下采样后直接输入语言模型),变体(b)仅使用正向扫描(不包含反向扫描),变体©不使用多分辨率下采样(仅单分辨率),变体(d)是完整的ABMamba模型。
结果表明,完整模型(d)在所有指标上显著优于其他变体。在MSR-VTT上,变体(a)的CIDEr分数为10.8,比完整模型的27.4低了16.6个百分点——这清晰地表明,没有时序扫描的视频理解接近于随机猜测。变体(b)(无反向扫描)的表现也明显差于完整模型,证实了双向扫描对于捕捉视频中的非因果依赖关系至关重要。变体©(无多分辨率)同样表现不佳,说明单一分辨率的时序建模无法有效捕捉视频中不同时间尺度上的动态模式。
分支数量和步长的消融。 表3考察了AHBS模块中多分辨率结构的设计参数对性能的影响。其中M表示并行通路的数量(即时间分辨率层数),stride表示下采样的步长。
结果显示,当M从1增加到3时,BLEU4分数从21.9提升到28.6,CIDEr分数从41.7提升到44.4。这表明更多的分辨率层次有助于模型更全面地捕捉时序动态。然而,当步长从2增加到4时,性能出现明显下降(BLEU4从28.6降至24.7,CIDEr从44.4降至38.8)。这说明过度的时序下采样会导致关键运动信息的丢失——当步长过大时,一些持续时间较短的动作可能完全消失在下采样后的序列中。
5.5 内存效率分析
表6比较了推理时的内存使用情况。在MSR-VTT基准上,ABMamba的额外内存开销仅为482MB,比内存效率最高的Transformer基线(Video-ChatGPT,2066MB)降低了约77%。这一内存效率优势在资源受限的环境中尤为重要,如边缘设备部署或大规模并发推理场景。
这一优势的根源在于Mamba的固定大小隐藏状态。Transformer需要在解码时缓存所有历史令牌的键值向量,这些缓存的大小随序列长度线性增长。在生成长字幕时,这一缓存可能占用大量显存。而Mamba的隐藏状态大小是固定的,与序列长度无关,因此内存占用保持恒定。
表3总结了AHBS模块消融实验的核心结果,直观展示了各设计要素的重要性:
| 变体 | 描述 | MSR-VTT BLEU4 | MSR-VTT CIDEr | VATEX BLEU4 | VATEX CIDEr |
|---|---|---|---|---|---|
| (a) | 无扫描 | 13.9 | 10.8 | 17.9 | 24.6 |
| (b) | 无反向扫描 | 16.5 | 16.2 | 21.1 | 33.4 |
| © | 无多分辨率 | 17.9 | 19.7 | 21.9 | 41.7 |
| (d) | ABMamba(完整) | 23.6 | 27.4 | 28.6 | 44.4 |
6 局限性与错误分析
6.1 失败模式分类
任何模型都有其局限性。论文对ABMamba的失败案例进行了系统性的错误分析,将失败模式归纳为五类。
物体幻觉。 这是最主要的错误来源,占失败案例的68%。物体幻觉指的是模型生成了视频中不存在的物体。一个典型例子是:模型生成“一个男人拿着一个白色袋子”,而画面中男人实际上拿着一个枕头。这类错误的根源可能在于视觉特征与语言特征之间的对齐不足——模型学习了错误的物体-视觉关联。
动作幻觉。 占失败案例的44%,指模型描述了视频中不存在的动作。例如,模型生成“一个人在跑步”,但视频中人物只是站在原地做手势。这类错误反映了模型对动作识别的不准确性。
描述不充分。 占27%,指生成的描述遗漏了视频中的关键物体、动作或指代表达。例如,场景显示一个男孩完成了一次精彩的篮球投篮并庆祝,模型却只生成了“男孩在玩球”——遗漏了“投篮成功”和“庆祝”这两个关键信息。这类错误表明模型在某些情况下未能识别出所有重要的视觉元素。
场景遗漏。 占24%,指模型将视频中的局部上下文孤立处理,导致整体场景连贯性的丧失。例如,在描绘跑酷的视频中,模型生成了“一个人正在跳跃”或“一个人正在爬墙”等描述,仅捕捉了局部动作,未能反映跑酷的整体行为。这类错误表明模型在构建全局叙事方面存在不足。
词汇不匹配。 占9%,指模型的描述内容正确但因与参考字幕的词汇差异而得到较低的评估分数。例如,模型生成“一个男人在小吃摊做饭”,而参考字幕使用“市场”而非“小吃摊”。这类错误并非模型的问题,而是评估指标的局限——词义相近但用词不同的表述应被视为正确。
6.2 错误根源的理论分析
从上述错误分析中,可以识别出ABMamba的若干根本性局限。
首先,物体幻觉的高发率(68%)表明视觉-语言特征融合的深度可能不足。在当前的ABMamba设计中,视觉特征与语言特征的交互发生在AHBS模块之后、Mamba-LLM的输入端。这种“晚期融合”策略可能导致视觉细节在进入语言模型之前就已经被压缩或丢失。一种可能的改进方向是让AHBS模块同时处理视觉和语言特征,实现更深层次的跨模态融合。
其次,动作幻觉和描述不充分的问题反映了模型在动态时序理解上的局限。尽管AHBS模块已经实现了多分辨率双向扫描,但对于持续时间极短的动作(如眨眼、手势变换)或持续时间极长的场景变化(如天色渐暗),模型仍可能存在感知盲区。未来的改进方向包括引入更精细的时间分辨率分层,或结合显式的动作检测模块。
最后,场景遗漏问题揭示了模型在处理场景切换和叙事结构方面的不足。视频通常包含多个场景的切换,而模型倾向于将各场景孤立处理,难以构建统一的全局叙事。这一问题的解决可能需要引入场景检测机制或记忆增强模块,使模型能够“记住”之前场景的内容。
7 扩展讨论:视频理解基准与相关模型
7.1 主流视频理解基准数据集
视频字幕生成领域经过多年发展,已经积累了多个高质量的基准数据集,各具特色。
MSVD是最早的视频描述数据集之一,包含1,970个视频片段,每个片段有约40条字幕。虽然规模较小,但其高质量的人工标注使其成为早期研究的首选基准。
MSR-VTT是目前最广泛使用的通用视频字幕数据集,其10,000个视频片段的规模和20类的内容覆盖使其成为领域标准。每个视频有20条人工标注字幕,保证了标注的一致性和多样性。
VATEX是当前规模最大的多语言视频描述数据集,其41,250个视频片段和825,000条中英双语字幕为跨语言视频理解研究提供了宝贵资源。VATEX的视频内容覆盖了更广泛的人类活动,描述的语言复杂度也更高。
ActivityNet Captions和YouCook2专注于长视频的密集字幕标注。与短时视频不同,这些数据集中的视频持续时间可达数分钟,需要模型能够生成多句描述,对时序建模能力提出了更高要求。
7.2 SSM在视频理解领域的最新进展
ABMamba并非首个将SSM应用于视频理解的尝试。VideoMamba是这一方向的开创性工作之一,它创新性地将纯Mamba架构适配于视频识别任务。VideoMamba利用Mamba的线性复杂度和选择性机制,实现了高效的视频处理。但其设计主要针对视频识别(分类),并未与语言模型集成,因此不适用于视频字幕生成等跨模态任务。
随后出现的VideoMamba++在VideoMamba基础上引入了双注意力机制,通过门控块卷积和残差注意力Mamba块来增强空间关系捕捉。其在Kinetics-400和Something-Something V2等基准上取得了显著的精度提升,Top-1准确率分别提高了3.6%和3.2%。
与这些工作相比,ABMamba的独特贡献在于两点:一是将SSM应用于视频字幕生成这一跨模态生成任务,而非仅限于识别;二是引入了AHBS模块这一专门针对视频时序建模的多分辨率双向扫描设计。
7.3 Mamba与Transformer的权衡:何时选择SSM?
Mamba与Transformer之间的选择并非简单的“谁更好”的问题,而是取决于具体任务的特性。
序列长度。 对于短序列(如长度<512),Transformer的二次复杂度尚可接受,且其成熟的优化(如FlashAttention)可能使其实际速度不输Mamba。但随着序列长度的增加,Mamba的线性复杂度优势会越来越明显。对于视频理解这种令牌数可达数万的任务,Mamba是更优选择。
任务特性。 Transformer的全局注意力机制使其天然适合需要跨序列任意位置信息交互的任务,如机器翻译中的长距离词汇对齐。Mamba虽然通过选择性机制增强了表达能力,但其信息流动仍受限于状态演化的递推结构。对于需要显式全局比较的任务,Transformer可能仍占优势。
部署约束。 在资源受限的环境(如移动设备、边缘计算)中,Mamba的内存效率和推理速度优势使其更具吸引力。苹果团队的最新研究也证实,在需要动态决策与迭代优化的Agent式任务中,基于SSM的模型在效率与泛化能力上展现出超越Transformer的潜力。
8 总结与展望
8.1 核心贡献回顾
本文对Yashima等人提出的ABMamba模型进行了系统性的技术解读。该工作的核心贡献可以概括为以下几点:
第一,ABMamba是首个基于深度SSM的完全开源视频多模态大语言模型。通过在语言骨干网络中采用Mamba替代Transformer,模型实现了序列长度上的次二次计算复杂度,为高效视频理解开辟了新路径。
第二,AHBS模块的设计是ABMamba最具原创性的技术贡献。该模块通过多分辨率并行通路和双向扫描机制,使模型能够同时捕捉视频中不同时间尺度上的动态模式,克服了单一分辨率时序建模的局限性。
第三,广泛的实验验证表明,ABMamba在保持与基线方法相当性能的同时,实现了约三倍的推理吞吐量和77%的内存节省。这些效率优势使其特别适合需要实时响应的实际应用场景。
8.2 理论启示
从更宏观的角度来看,ABMamba的成功提供了几个重要的理论启示。
注意力不是唯一的选择。 Transformer自2017年问世以来,已成为序列建模的事实标准。ABMamba的研究表明,在视频理解这类高维、长序列任务中,线性复杂度的SSM架构不仅可行,而且可以在效率维度上显著超越Transformer。这提示研究者不应被“注意力万能论”束缚,应积极探索更多样的架构范式。
架构设计需要与任务特性对齐。 ABMamba没有简单地将Mamba“粘贴”到视频上,而是针对视频的时空特性设计了专门的AHBS模块。多分辨率扫描和双向扫描的设计直接回应了视频数据的内在结构——不同时间尺度的动态和非因果的时空关系。这提醒我们,在将基础架构适配到特定任务时,需要深入理解任务的数据特性,进行有针对性的设计。
开源推动技术进步。 ABMamba强调的“完全开源”属性并非口号。当代码、数据和模型权重均可公开获取时,整个社区可以基于此进行验证、改进和二次开发,形成正向的技术演进循环。这对于人工智能这一快速发展领域尤为重要。
8.3 未来研究方向
ABMamba的论文为未来的研究指出了若干有价值的方向。
向更通用的视频理解扩展。 当前ABMamba主要聚焦于视频字幕生成任务。将其扩展到更广泛的视频理解场景——如时序定位、多轮对话、指令理解等——是自然而然的下一步。这些任务对时序建模提出了更高要求,也是对AHBS模块设计的有力检验。
减少幻觉的算法改进。 错误分析显示物体幻觉是ABMamba最主要的失败模式。未来的研究可以探索更深层次的视觉-语言特征融合方法,例如让AHBS模块同时处理两种模态的信息,实现更紧密的跨模态对齐。
与长视频理解的结合。 随着Mamba的线性复杂度,ABMamba天然适合处理长视频。但目前实验主要集中在短视频(15秒左右)上。将ABMamba应用于长视频理解——如电影摘要、讲座字幕生成等——是检验其扩展性的重要方向。
轻量化与边缘部署。 ABMamba的高效特性使其适合在资源受限的环境中部署。进一步压缩模型规模(如知识蒸馏、量化)并针对边缘设备进行优化,将使其在实际应用中发挥更大价值。
参考文献
[1] Yashima, D., et al. (2026). ABMamba: Aligned Hierarchical Bidirectional Scan Mamba for Video Captioning. arXiv preprint arXiv:2604.08050.
[2] Gu, A., Dao, T. (2024). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. Proceedings of Machine Learning Research (CoLM).
[3] Gu, A., Goel, K., Ré, C. (2022). Efficiently Modeling Long Sequences with Structured State Spaces. International Conference on Learning Representations (ICLR).
[4] Li, B., Zhang, Y., Guo, D., et al. (2024). LLaVA-OneVision: Easy Visual Task Transfer. arXiv preprint arXiv:2408.03326.
[5] Lin, B., Ye, Y., Zhu, B., et al. (2024). Video-LLaVA: Learning United Visual Representation by Alignment Before Projection. Empirical Methods in Natural Language Processing (EMNLP), 5971-5984.
[6] Li, K., Li, X., Wang, Y., et al. (2024). VideoMamba: State Space Model for Efficient Video Understanding. European Conference on Computer Vision (ECCV).
[7] Zhu, L., Liao, B., Zhang, Q., et al. (2024). Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model. International Conference on Machine Learning (ICML).
[8] Xu, J., Mei, T., Yao, T., et al. (2016). MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5288-5296.
[9] Wang, X., Wu, J., Chen, J., et al. (2019). VaTeX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research. International Conference on Computer Vision (ICCV), 4581-4591.
[10] Maaz, M., Rasheed, H., et al. (2024). Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. Association for Computational Linguistics (ACL), 12585-12602.
[11] Zhao, H., Zhang, M., Zhao, W., et al. (2025). Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference. AAAI Conference on Artificial Intelligence, 10421-10429.
[12] Qiao, Y., Yu, Z., Guo, L., et al. (2024). VL-Mamba: Exploring State Space Models for Multimodal Learning. arXiv preprint arXiv:2403.13600.
[13] Somvanshi, S., et al. (2025). From S4 to Mamba: A Comprehensive Survey on Structured State Space Models. arXiv preprint arXiv:2503.18970.
[14] Liu, H., Li, C., Li, Y., et al. (2024). Improved Baselines with Visual Instruction Tuning. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 26296-26306.
[15] Patro, B., Agneeswaran, V. (2024). Mamba-360: Survey of State Space Models as Transformer Alternative for Long Sequence Modelling: Methods, Applications, and Challenges. arXiv preprint arXiv:2404.16112.

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)