NLP是什么?一文读懂自然语言处理(NLP)!_nlp领域是什么
自然语言处理(NaturalLanguage Processing,NLP)是人工智能的一大分支领域,其主要目的是让机器理解人类的语言文字,从而执行一系列任务。通常来说,语音识别、文本生成、情感分析、知识图谱、机器翻译、问答系统、聊天机器人等都是常见的自然语言处理任务。
自然语言处理(NaturalLanguage Processing,NLP)是人工智能的一大分支领域,其主要目的是让机器理解人类的语言文字,从而执行一系列任务。
通常来说,语音识别、文本生成、情感分析、知识图谱、机器翻译、问答系统、聊天机器人等都是常见的自然语言处理任务。
如果继续划分下去,自然语言处理还可被细分为自然语言理解(Natural Language Understanding,NLU)和自然语言生成(Natural Language Generation, NLG )
相比计算机视觉相关的任务,自然语言处理任务难度更高。与图片和视频相比,语言文字受到方言、表达方式、歧义等多种因素的影响,更不用说,很多文字并非字面意思,需要联系上下文来理解其更加深层次的含义。
举个自然语言处理领域的经典例子,“南京市长江大桥”这句话就可以有两种断句方式,一种是“南京市”和“长江大桥”;另一种则是“南京市长”和“江大桥"。
当模型没有联系上下文时,很难判断这句话的真实意图是什么。此外,像“C罗梅开二度”这句话,对模型来说,更是难上加难,因为它既不知道C罗是谁,更不知道“梅开二度”在足球中是什么含义。
在2019年之前,自然语言处理使用的技术主要是循环神经网络(Recurent Neural Network,RNN)和卷积神经网络(Convolutional Neural Network,CNN)等特征抽取器。
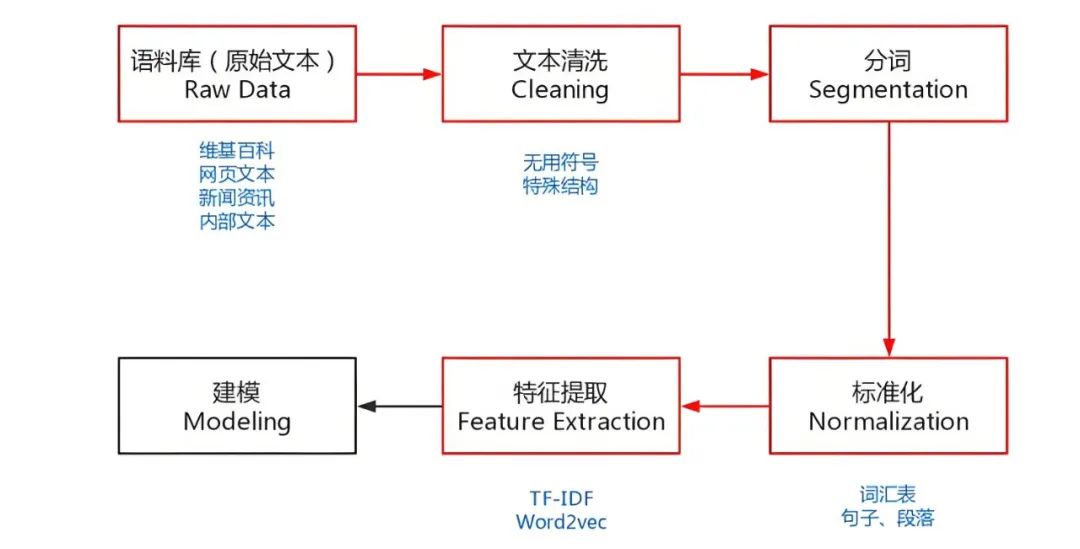
卷积神经网络主要由卷积层、池化层和全连接层组成。如图3-6所示:
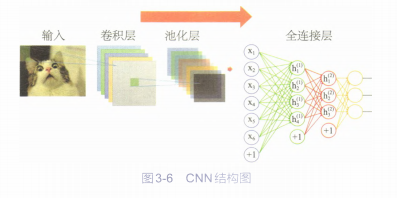
其中,卷积层用来提取图像中的特征,随着卷积层不断加深,提取的特征范围也在加大,相当于人眼从局部开始逐步看到整体:池化层则是用来降维,大幅度降低参数的量级。
从而简化网络:全连接层就是普通的神经网络层,池化层的输出就是全连接层的输入,全连接层的输出就是卷积神经网络整体的输出结果。
看到这里,你很可能会有疑问,卷积神经网络不是应用在图像领域吗?和自然语言处理有什么关系呢?
其实在大部分情况下,文本数据和图像数据一样,都会被处理后转化为矩阵的形式作为模型的输入,此时对于卷积神经网络,数据本身是图像、文字或语音,又有什么区别呢?
相比卷积神经网络来说,循环神经网络最大的特性就是对于序列数据的处理非常有效,能挖掘出数据中的时序信息及语义信息,天然适合处理文本和语音数据。
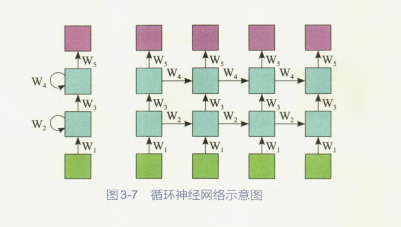
从图3-7所示的循环神经网络示意图中可以看到,输入数据(绿色部分)之间是有前后关联的,在处理数据的时候每一个隐藏层的神经元(蓝色部分)都会接收从上一个时刻传来的历史信息,这也就意味着循环神经网络拥有了像人类一样的记忆能力,这是一个重要的突破!
介绍完卷积神经网络和循环神经网络后,补充说明一下,上面之所以说“在2019年之前”,是因为在2018年尾BERT(其全称是Bidirectinal Encoder Representation fromTransformer,是一种用于语言表征的预训练模型)模型的横空出世,彻底改变了自然语言处理的范式。
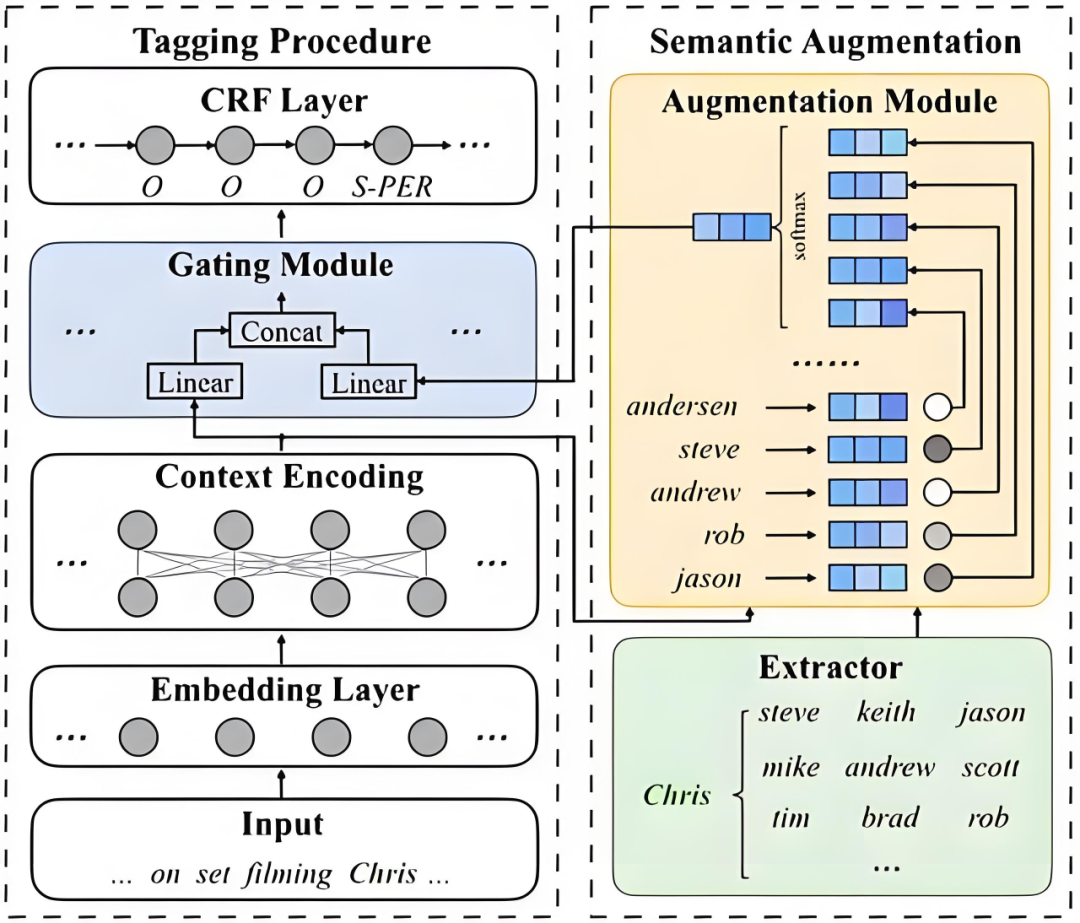
预训练模型其实很容易理解,记住“举一反三”这四个字就可以。当预训练模型训练好以后,仅需要对该模型最后几层的神经元权重进行微调(Fime Tuning),再利用一些新数据进行增量的训练,即可将模型的能力迁移到其他领域。
通俗地说,预训练模型就相当于“站在了巨人的肩膀上”,可以在开始就获得及格线以上的成绩,并在此基础上继续进步。
在预训练模型被大范围使用之前,使用传统的深度学习算法,想让模型得到更好的效果,就需要在数据量和神经网络的层数上做文章,通常需要数据在量级上的提升并不断叠加更深的神经网络。
虽然这种“暴力解法”也可以使得模型效果更好,但总体来说,性价比不高。同时,哪怕卷积神经网络和循环神经网络等特征抽取器进行各种变形,但表达能力依旧受限,传统的深度学习算法仍旧无法学到数据里蕴含的更深刻的含义。
在这种情况下,BERT的出现让此前的循环神经网络和卷积神经网络等方法黯然失色,自此之后,自然语言处理领域几乎被 BERT实现了“大一统”,无论是在学术界还是工业界,自然语言处理研究和应用的突破几乎离不开BERT的变体。
BERT之所以能取得这么大的突破,和其将特征抽取器从循环神经网络和卷积神经网络统一成Transformer架构有很大的关系。那我们下期再来详细介绍一下Transformer是如何为AIGC奠基的。
如今传统技术岗位大批缩水!
85%企业计划2025年前 “淘汰纯业务型程序员”!
未来,传统技术岗将失去竞争力!
转型大模型方向,才是又一轮的时代红利!
那么作为技术人:
如何成功掌握大模型技术、拿到AI方向高薪岗?
如果你想通过学习大模型技术实现就业或转行!我可以把自己录制的199节
从零基础到精通的视频课程+配套学习资料无偿分享给您!
希望能帮你在AI这条路上走得更远。
2026最新AI大模型资料预览
一、199节视频教程
199集从入门到精通的全套视频教程(包含提示词工程、RAG、Agent等技术点)
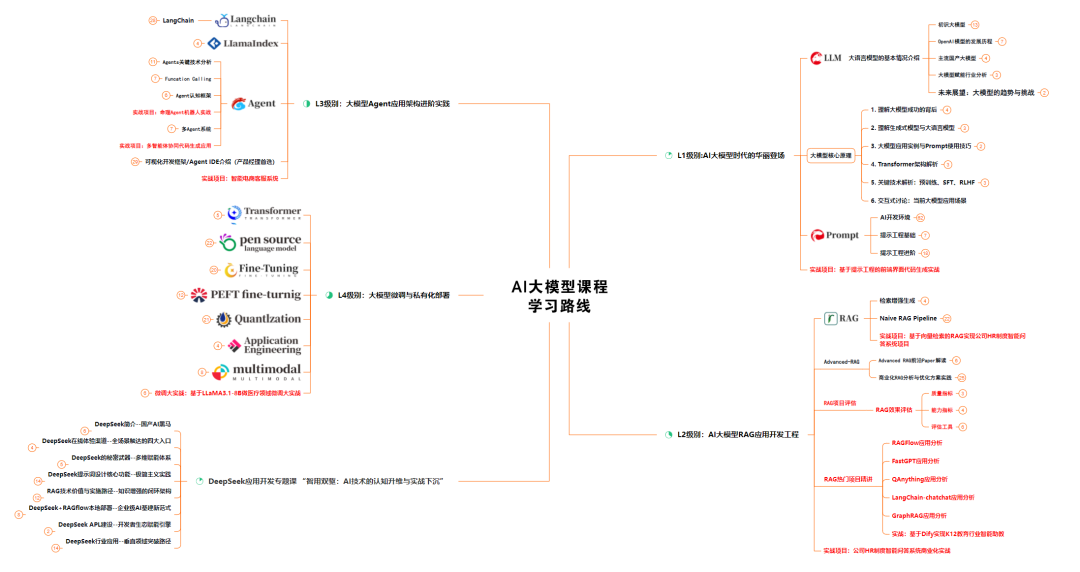
二、AI大模型学习路线图
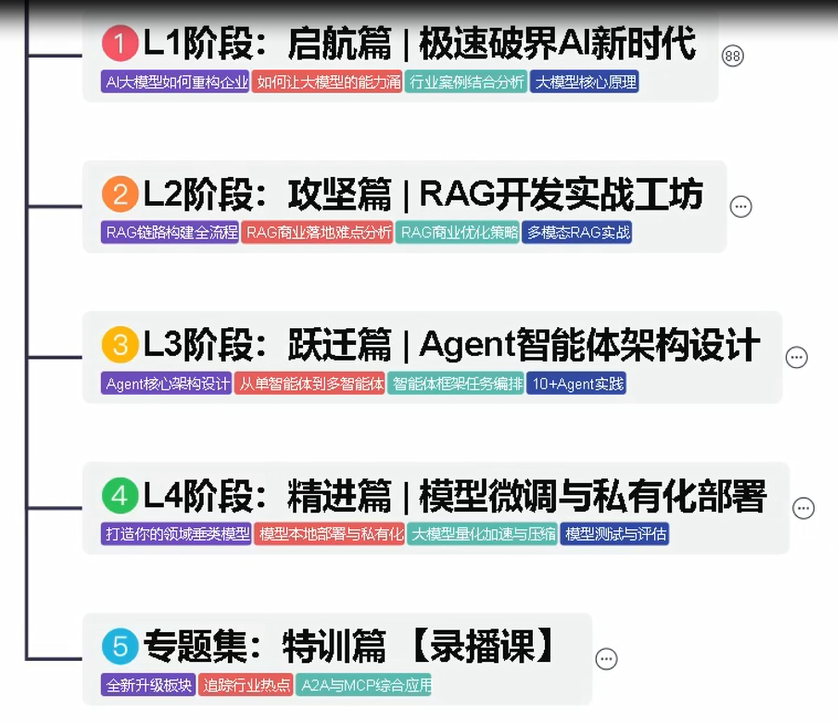
全过程AI大模型学习路线
想要学习AI大模型,作为新手一定要先按照路线图学习,方向不对,努力白费。对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线,大家跟着这个路线图学习准没错。
三、配套项目实战/源码
所有视频教程所涉及的实战项目和项目源码等
四、学习电子书籍
学习AI大模型必看的书籍和文章的Pdf
市面上的大模型书籍确实太多了,这些是我精选出来的

五、面试真题/经验
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

作者有话说
1、为什么我要分享这些资料?
只要你是真心想学习人工智能大模型技术,我愿意将这份精心整理的资料无偿分享给你。
我分享这些资料的初衷,就是希望可以帮助更多人快速入门、系统学习,真正掌握这项前沿技术。如果你在学习过程中遇到任何问题,我也非常乐意为你提供帮助,技术交流与共同进步,是我一直坚持的初心。
2、这些资料真的有用吗?
这份资料由我与鲁为民博士共同整理。鲁博士毕业于清华大学(学士)和美国加州理工学院(博士),在人工智能领域深耕多年,先后在包括 IEEE Transactions 在内的国际权威期刊和会议上发表论文 超过50篇,拥有 多项中美发明专利,并曾荣获 吴文俊人工智能科学技术奖。
目前,我正与鲁博士在人工智能领域展开深入合作。本次整理的资料内容系统全面,涵盖从零基础入门到实战进阶的199节视频教程,以及配套的学习资料与实战项目。无论你是完全零基础的小白,还是已有一定技术背景的学习者,都能从中获得切实提升,助力你转行大模型岗位、提升薪资待遇。


👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

{kind=link}
所有评论(0)