Langfuse实战入门到精通:搭建Agent监控系统,收藏这篇就够了!
导语:你的AI Agent正在"黑盒"运行吗?
深夜11点,产品经理急匆匆地找到你:
“我们的智能客服机器人今天出问题了!用户反馈说回答完全不对,但我不知道哪里出了错。你能帮我看看吗?”
你打开日志,发现海量的LLM调用记录,但根本无从下手:
- • ❌ 不知道哪次对话出了问题
- • ❌ 看不清楚Agent的执行路径
- • ❌ 无法追踪Prompt的演变历史
- • ❌ Token消耗暴增却找不到原因
- • ❌ 用户投诉却无法复现问题
这,就是没有可观测性的AI Agent系统的真实写照。
今天,我将带你从零开始,使用Langfuse搭建一套企业级的AI Agent可观测系统,让你的LLM应用彻底告别"黑盒"时代!
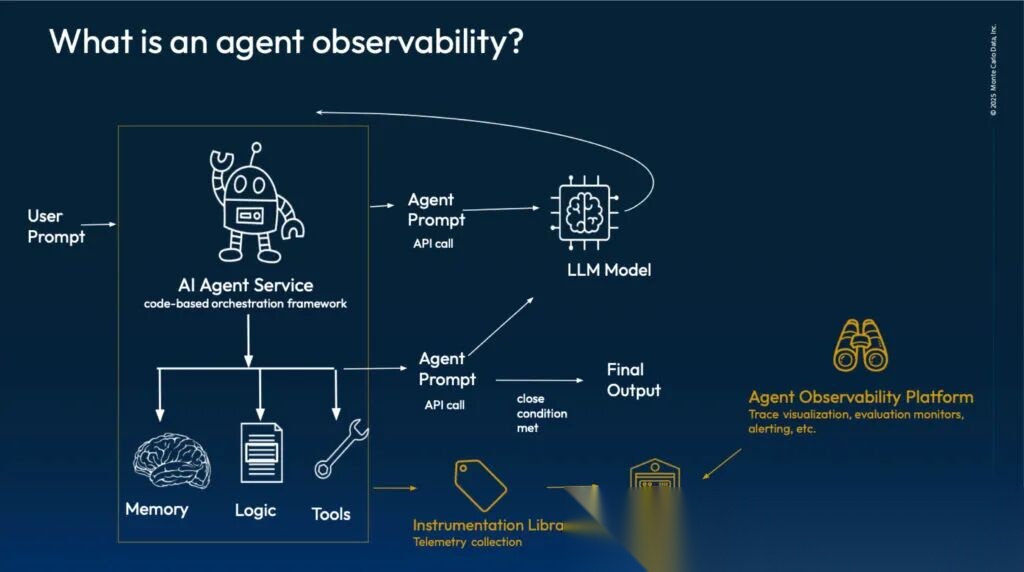
AI Agent可观测性架构
一、为什么AI Agent需要可观测性?
1.1 AI应用的独特挑战
与传统应用不同,AI Agent系统面临着独特的工程挑战:
🔍 不确定性问题
同样的输入,可能产生完全不同的输出。LLM的非确定性使得调试变得极其困难。
📊 多维度监控需求
Agentic AI可观测性是一个多维度的概念,它不仅包括传统应用监控中的指标,还需要特别关注AI特有的行为特征。你需要监控:
- • Token消耗与成本
- • 响应时间与延迟
- • Prompt质量与效果
- • 模型选择与切换
- • 工具调用成功率
- • 用户满意度评分
🔗 复杂的执行链路
在Agent系统中,我们需要监控从用户输入到最终输出的完整链路,包括:
- • RAG检索过程
- • 多轮对话历史
- • 工具调用链
- • 决策分支逻辑
💰 成本失控风险
没有合适的可观测性,调试AI工作流就像盲飞——只能看到结果,看不到过程。一个死循环的Agent可能在几小时内消耗掉你一个月的API预算!
1.2 真实案例:某电商公司的教训
让我分享一个真实案例:
某头部电商公司上线了智能客服Agent,首月表现良好。但第二个月突然出现:
- • API成本暴增300%
- • 用户满意度下降40%
- • 平均响应时间从2秒增加到8秒
由于缺乏可观测性,团队花了2周时间才定位到问题:
一个新上线的促销功能,导致Agent陷入了无限循环的工具调用。如果有Langfuse这样的追踪工具,能够在几分钟内发现问题所在。
二、Langfuse是什么?为什么选择它?
2.1 Langfuse的核心定位
Langfuse是一个专为LLM应用设计的可观测性与评估平台,也是当前最成熟的开源LLMOps解决方案之一。
它将以下能力整合在一个统一平台中:
- • ✅ 可观测性(Observability):完整的Trace追踪
- • ✅ 提示词管理(Prompt Management):版本控制与A/B测试
- • ✅ 效果评估(Evaluation):自动化评分与人工标注
- • ✅ 数据集管理(Datasets):回归测试与基准测试
- • ✅ 成本分析(Cost Analytics):细粒度的成本追踪
2.2 为什么选择Langfuse?
🏆 开源优先
Langfuse采用开源模式,你可以:
- • 完全自托管,数据完全掌控
- • 使用云服务,快速上手
- • 无供应商锁定风险
🔧 开箱即用的集成
支持主流LLM框架:
- • LangChain / LangGraph
- • LlamaIndex
- • OpenAI SDK
- • Anthropic SDK
- • 自定义集成
📈 企业级功能
- • 团队协作与权限管理
- • 多项目支持
- • API访问与数据导出
- • 自定义指标与Dashboard
🌍 中文支持完善
Langfuse提供完整的中文文档和界面支持,对中文团队极其友好。
2.3 Langfuse vs 其他方案
| 特性 | Langfuse | Arize Phoenix | Helicone |
|---|---|---|---|
| 开源 | ✅ 完全开源 | ✅ 开源 | ❌ 闭源 |
| 自托管 | ✅ 支持 | ✅ 支持 | ❌ 不支持 |
| 评估功能 | ✅ 强大 | ⚠️ 基础 | ⚠️ 基础 |
| Prompt管理 | ✅ 完整 | ❌ 无 | ⚠️ 有限 |
| 中文文档 | ✅ 完善 | ⚠️ 一般 | ❌ 无 |
三、快速部署:5分钟搭建Langfuse环境
3.1 环境准备
确保你的系统满足以下要求:
- • Docker 20.10+
- • Docker Compose 2.0+
- • 4GB+ 内存
- • 10GB+ 磁盘空间
3.2 方案一:Docker Compose快速部署(推荐开发环境)
步骤1:创建项目目录
mkdir langfuse-democd langfuse-demo
步骤2:创建docker-compose.yml
version: '3.8'services: langfuse: image: langfuse/langfuse:latest ports: - "3000:3000" environment: - DATABASE_URL=postgresql://postgres:postgres@postgres:5432/postgres - NEXTAUTH_SECRET=my-secret-key-change-in-production - SALT=mysalt - NEXTAUTH_URL=http://localhost:3000 - TELEMETRY_ENABLED=false depends_on: postgres: condition: service_healthy postgres: image: postgres:15-alpine environment: - POSTGRES_USER=postgres - POSTGRES_PASSWORD=postgres - POSTGRES_DB=postgres volumes: - postgres_data:/var/lib/postgresql/data healthcheck: test: ["CMD-SHELL", "pg_isready -U postgres"] interval: 5s timeout: 5s retries: 5volumes: postgres_data:
步骤3:启动服务
docker-compose up -d
步骤4:访问界面
打开浏览器访问:http://localhost:3000
首次访问会提示你创建管理员账号。
Langfuse部署界面
3.3 方案二:Langfuse Cloud(推荐生产环境)
如果你不想自己维护基础设施,可以使用Langfuse Cloud:
步骤1:注册账号
访问 langfuse.com 注册免费账号
步骤2:创建项目
登录后创建新项目,获取API密钥:
- •
LANGFUSE_PUBLIC_KEY - •
LANGFUSE_SECRET_KEY - •
LANGFUSE_HOST(云服务为 https://cloud.langfuse.com)
步骤3:配置环境变量
export LANGFUSE_PUBLIC_KEY=pk-lf-xxxxxxxxxxxxxexport LANGFUSE_SECRET_KEY=sk-lf-xxxxxxxxxxxxxexport LANGFUSE_HOST=https://cloud.langfuse.com
3.4 方案三:Kubernetes部署(企业级)
对于大规模生产环境,推荐使用Helm部署:
# 添加Helm仓库helm repo add langfuse https://langfuse.github.io/langfuse-helm# 安装Langfusehelm install langfuse langfuse/langfuse \ --namespace langfuse \ --create-namespace \ -f values.yaml
四、核心功能详解:从Trace到Evaluation
4.1 Trace追踪:看见每一次LLM调用
什么是Trace?
Trace是Langfuse的核心概念,它记录了从用户请求到最终响应的完整执行链路。
在传统监控体系下,我们往往只能看到应用层的日志;而在Langfuse的体系中,每一次LLM调用、检索、工具调用乃至最终响应,都会被完整追踪。
Trace的层级结构:
Trace (追踪)├── Span (跨度) - 表示一个操作单元│ ├── Generation (生成) - LLM调用│ ├── Event (事件) - 自定义事件│ └── Span (嵌套跨度)└── Score (评分) - 质量评估
4.2 实战:Python集成示例
安装SDK:
pip install langfuse
基础集成:
from langfuse import Langfusefrom langfuse.decorators import observe, langfuse_context# 初始化langfuse = Langfuse( public_key="pk-lf-xxxxxxxxxxxxx", secret_key="sk-lf-xxxxxxxxxxxxx", host="https://cloud.langfuse.com")# 方法1:使用装饰器(推荐)@observe()def chat_with_user(user_input: str) -> str: """智能对话函数""" # 添加自定义元数据 langfuse_context.update_current_trace( name="用户对话", user_id="user_123", session_id="session_456", metadata={ "environment": "production", "version": "1.0.0" } ) # 调用LLM response = call_llm(user_input) # 记录评分 langfuse.score( trace_id=langfuse_context.get_current_trace_id(), name="user-feedback", value=1.0, # 1.0表示好评,0.0表示差评 comment="用户明确满意" ) return response# 方法2:手动创建Tracedef manual_trace_example(): trace = langfuse.trace( name="customer-support-agent", user_id="user_789", metadata={"channel": "web"} ) # 创建Span span = trace.span( name="retrieve-knowledge", metadata={"database": "faq_db"} ) # RAG检索 context = retrieve_documents("如何退货") span.end(output=context) # LLM生成 generation = trace.generation( name="generate-response", model="gpt-4", prompt=build_prompt("如何退货", context), model_parameters={"temperature": 0.7} ) response = generate_response(prompt) generation.end(output=response) return response
4.3 LangChain集成(最常用)
from langfuse import Langfusefrom langfuse.langchain import CallbackHandlerfrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import ChatPromptTemplate# 创建Langfuse Callback Handlerlangfuse_handler = CallbackHandler( public_key="pk-lf-xxxxxxxxxxxxx", secret_key="sk-lf-xxxxxxxxxxxxx", host="https://cloud.langfuse.com")# 构建LangChain链prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个专业的客服助手,请用友好的语气回答问题"), ("human", "{input}")])model = ChatOpenAI(model="gpt-4", temperature=0.7)chain = prompt | model# 执行时传入callbackresponse = chain.invoke( {"input": "如何申请退款?"}, config={"callbacks": [langfuse_handler]})print(response.content)
效果:
执行后,你可以在Langfuse Dashboard中看到:
- • 完整的Prompt和Response
- • Token消耗统计
- • 响应时间
- • 模型参数
4.4 LlamaIndex集成
from langfuse import Langfusefrom langfuse.llama_index import LlamaIndexCallbackHandlerfrom llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader# 创建Handlerlangfuse_handler = LlamaIndexCallbackHandler( public_key="pk-lf-xxxxxxxxxxxxx", secret_key="sk-lf-xxxxxxxxxxxxx", host="https://cloud.langfuse.com")# 配置LlamaIndexSettings.callback_handlers = [langfuse_handler]# 构建RAG系统documents = SimpleDirectoryReader("./data").load_data()index = VectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine()# 查询response = query_engine.query("公司产品有哪些?")
4.5 Evaluation评估系统
为什么需要评估?
可观测性不仅要知道"发生了什么",还要知道"表现如何"。Langfuse提供了强大的评估功能。
评估类型:
- 人工标注(Human Annotation)
- 自动化评分(Automated Scoring)
- 基于LLM的评估(LLM-as-a-Judge)
实战示例:
# 1. 人工标注评分langfuse.score( trace_id=trace_id, name="human-feedback", value=1.0, # 1.0 = 好评, 0.0 = 差评 comment="回答准确且友好")# 2. 自动化评分 - 基于规则def calculate_relevance_score(prompt, response): """计算响应相关性""" # 这里可以是你的业务逻辑 if len(response) < 10: return 0.0 return 0.8langfuse.score( trace_id=trace_id, name="relevance-score", value=calculate_relevance_score(prompt, response))# 3. LLM-as-a-Judgefrom langchain.evaluation import load_evaluatorfrom langchain.chat_models import ChatOpenAIevaluator = load_evaluator( "labeled_score_string", criteria={ "helpfulness": "回答是否有帮助", "accuracy": "信息是否准确", "conciseness": "回答是否简洁" }, llm=ChatOpenAI(model="gpt-4"))eval_result = evaluator.evaluate_strings( prediction=response, input=prompt)langfuse.score( trace_id=trace_id, name="llm-judge-helpfulness", value=eval_result["score"] / 10.0 # 归一化到0-1)
4.6 Prompt管理与版本控制
问题场景:
你的团队有10个不同的Prompt版本,如何:
- • 追踪哪个版本效果最好?
- • 快速回滚到历史版本?
- • 团队协作修改Prompt?
Langfuse解决方案:
from langfuse import Langfuselangfuse = Langfuse()# 创建Promptlangfuse.create_prompt( name="customer-support-v1", prompt="""你是一个专业的客服助手。 请遵循以下原则:1. 语气友好专业2. 回答简洁明了3. 提供具体可执行的建议用户问题:{{question}}""", labels=["production"])# 使用Promptprompt = langfuse.get_prompt("customer-support-v1")formatted = prompt.compile(question="如何退货?")# 调用LLMresponse = call_llm(formatted)# A/B测试:创建新版本langfuse.create_prompt( name="customer-support-v2", prompt="""你是一个资深客服专家,拥有10年行业经验。你的特点是:- 耐心细致- 善于换位思考- 能提供超出预期的建议用户问题:{{question}}""", labels=["experiment"])
在Dashboard中对比版本效果:
Langfuse会自动统计不同版本的:
- • 平均评分
- • 用户满意度
- • Token消耗
- • 响应时间
4.7 Dataset数据集管理
用途:
- • 回归测试:确保新版本不会破坏现有功能
- • 基准测试:对比不同模型/参数配置
- • 持续改进:积累高质量测试用例
创建数据集:
from langfuse import Langfuselangfuse = Langfuse()# 创建数据集dataset = langfuse.create_dataset( name="customer-support-test-cases", description="客服系统标准测试集")# 添加测试用例test_cases = [ { "input": "如何申请退款?", "expected_output": "请在订单详情页点击'申请退款'按钮...", "metadata": {"category": "refund", "difficulty": "easy"} }, { "input": "产品保修期多久?", "expected_output": "我们的产品提供12个月质保...", "metadata": {"category": "warranty", "difficulty": "easy"} }]for case in test_cases: langfuse.create_dataset_item( dataset_name="customer-support-test-cases", input=case["input"], expected_output=case["expected_output"], metadata=case["metadata"] )
运行回归测试:
from langfuse import Langfuselangfuse = Langfuse()# 获取数据集dataset = langfuse.get_dataset("customer-support-test-cases")# 运行测试for item in dataset.items: # 执行你的应用 actual_output = my_agent.run(item.input) # 评估结果 score = evaluate_response(item.expected_output, actual_output) # 记录到Langfuse langfuse.score( trace_id=item.trace_id, name="regression-test", value=score )
五、实战演练:构建智能客服监控系统
5.1 场景描述
让我们通过一个完整的案例,展示Langfuse的强大功能。
需求:
- • 监控智能客服Agent的每一次对话
- • 追踪RAG检索过程
- • 评估回答质量
- • 识别问题对话并告警
- • 分析成本与性能
5.2 系统架构
用户请求 ↓API Gateway ↓智能客服Agent (LangChain + Langfuse) ├── RAG检索 (记录检索文档) ├── LLM生成 (记录Prompt/Response) ├── 工具调用 (记录调用参数) └── 质量评估 (自动评分) ↓Langfuse Dashboard (实时监控)
5.3 完整代码实现
import osfrom typing import List, Dictfrom langfuse import Langfusefrom langfuse.decorators import observe, langfuse_contextfrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import ChatPromptTemplatefrom langchain.retrievers import WikipediaRetrieverfrom pydantic import BaseModel# 初始化Langfuselangfuse = Langfuse( public_key=os.getenv("LANGFUSE_PUBLIC_KEY"), secret_key=os.getenv("LANGFUSE_SECRET_KEY"), host=os.getenv("LANGFUSE_HOST", "https://cloud.langfuse.com"))class CustomerSupportAgent: """智能客服Agent""" def __init__(self): self.llm = ChatOpenAI(model="gpt-4", temperature=0.7) self.retriever = WikipediaRetriever(top_k_results=3) @observe() async def handle_query( self, user_id: str, query: str, session_id: str = None ) -> Dict: """处理用户查询""" # 更新Trace元数据 langfuse_context.update_current_trace( name="customer-support-query", user_id=user_id, session_id=session_id, metadata={ "query_type": "general", "channel": "web", "priority": "normal" } ) # 步骤1:检索知识 context = await self._retrieve_knowledge(query) # 步骤2:生成回答 response = await self._generate_response(query, context) # 步骤3:质量评估 quality_score = await self._evaluate_quality(query, response) # 步骤4:记录评分 langfuse.score( trace_id=langfuse_context.get_current_trace_id(), name="quality-score", value=quality_score ) # 步骤5:问题检测与告警 if quality_score < 0.6: await self._trigger_alert(query, response, quality_score) return { "response": response, "quality_score": quality_score, "context_used": context } @observe(name="retrieve-knowledge") async def _retrieve_knowledge(self, query: str) -> str: """检索相关知识""" docs = self.retriever.get_relevant_documents(query) context = "\n\n".join([doc.page_content for doc in docs[:3]]) return context @observe(name="generate-response") async def _generate_response(self, query: str, context: str) -> str: """生成回答""" prompt = ChatPromptTemplate.from_messages([ ("system", """你是专业的客服助手。 基于以下背景信息回答问题:{context}如果背景信息不足以回答问题,请诚实告知用户。"""), ("human", "{query}") ]) chain = prompt | self.llm response = chain.invoke({ "context": context, "query": query }) return response.content @observe(name="evaluate-quality") async def _evaluate_quality(self, query: str, response: str) -> float: """评估回答质量""" # 这里可以使用LLM-as-a-judge或其他评估方法 # 简化示例:基于响应长度和相关性关键词 quality_indicators = [ len(response) > 50, any(word in response.lower() for word in ["请", "建议", "可以"]), not any(word in response.lower() for word in ["不知道", "无法回答"]) ] score = sum(quality_indicators) / len(quality_indicators) return score @observe(name="trigger-alert") async def _trigger_alert(self, query: str, response: str, score: float): """触发告警""" # 实际场景中可以发送邮件/Slack消息 print(f"⚠️ 低质量回答告警:") print(f"查询: {query}") print(f"响应: {response[:100]}...") print(f"评分: {score}")# 使用示例async def main(): agent = CustomerSupportAgent() result = await agent.handle_query( user_id="user_12345", query="如何重置密码?", session_id="session_abc" ) print(f"回答: {result['response']}") print(f"质量评分: {result['quality_score']}")# 运行import asyncioasyncio.run(main())
5.4 监控Dashboard
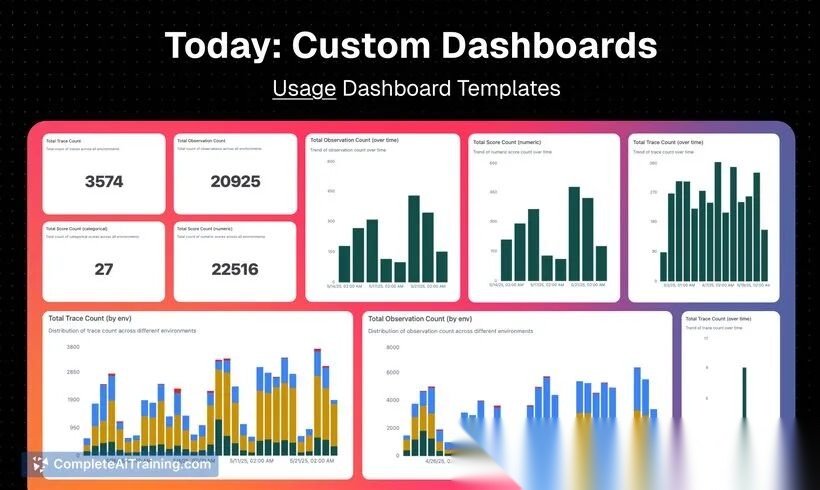
Langfuse自定义Dashboard
在Langfuse Dashboard中,你可以看到:
1. 总览指标
- • 总Trace数:3574
- • 总Token消耗:20925
- • 平均响应时间:2.3s
- • 平均质量评分:0.85
2. 趋势分析
- • 每日请求量趋势
- • 成本变化趋势
- • 质量评分趋势
3. 问题识别
- • 低评分对话列表
- • 高成本对话
- • 超时对话
4. 详细Trace
点击任意Trace,可以看到:
- • 完整的执行链路
- • 每个步骤的耗时
- • Token消耗明细
- • 输入输出内容
六、高级应用:自定义Dashboard与性能优化
6.1 构建自定义监控指标
Langfuse提供强大的API,你可以构建自定义的监控面板。
示例:成本分析Dashboard
from langfuse import Langfuseimport pandas as pdimport matplotlib.pyplot as pltlangfuse = Langfuse()# 获取所有Tracestraces = langfuse.fetch_traces(limit=1000)# 分析成本cost_data = []for trace in traces: cost_data.append({ "date": trace.timestamp.date(), "total_cost": trace.usage.total_cost, "model": trace.metadata.get("model", "unknown"), "user_id": trace.user_id })df = pd.DataFrame(cost_data)# 按日期聚合daily_cost = df.groupby("date")["total_cost"].sum()# 可视化plt.figure(figsize=(12, 6))plt.plot(daily_cost.index, daily_cost.values)plt.title("每日LLM API成本")plt.xlabel("日期")plt.ylabel("成本 ($)")plt.xticks(rotation=45)plt.tight_layout()plt.savefig("daily_cost.png")
6.2 性能优化技巧
1. 异步批量上传
from langfuse import Langfuselangfuse = Langfuse( # 批量上传配置 flush_at=10, # 每10条记录上传一次 flush_interval=1 # 或每1秒上传一次)
2. 采样策略
对于高流量应用,可以采样记录:
import randomdef should_sample(sample_rate: float = 0.1) -> bool: """10%采样率""" return random.random() < sample_rateif should_sample(): # 记录到Langfuse trace = langfuse.trace(...)
3. 敏感信息过滤
from langfuse.decorators import langfuse_contextdef sanitize_input(text: str) -> str: """过滤敏感信息""" # 实现你的过滤逻辑 return text.replace("password", "***")@observe()def process_query(query: str): # 过滤后再记录 safe_query = sanitize_input(query) langfuse_context.update_current_trace( input=safe_query )
6.3 告警系统集成
集成PagerDuty/Slack:
import requestsclass AlertManager: def __init__(self, langfuse: Langfuse, slack_webhook: str): self.langfuse = langfuse self.slack_webhook = slack_webhook def check_and_alert(self): """检查指标并触发告警""" # 获取最近1小时的Traces traces = self.langfuse.fetch_traces( from_timestamp=datetime.now() - timedelta(hours=1) ) # 计算平均质量评分 scores = [t.scores for t in traces if t.scores] avg_score = sum(scores) / len(scores) if scores else 1.0 # 触发告警 if avg_score < 0.7: self.send_slack_alert(f"⚠️ 质量评分过低: {avg_score:.2f}") # 检查成本 total_cost = sum(t.usage.total_cost for t in traces) if total_cost > 100: # 1小时成本超过100美元 self.send_slack_alert(f"💰 成本异常: ${total_cost:.2f}") def send_slack_alert(self, message: str): """发送Slack通知""" requests.post( self.slack_webhook, json={"text": message} )# 定时任务from apscheduler.schedulers.background import BackgroundSchedulerscheduler = BackgroundScheduler()alert_manager = AlertManager(langfuse, "https://hooks.slack.com/...")scheduler.add_job( alert_manager.check_and_alert, 'interval', minutes=15)scheduler.start()
七、生产环境最佳实践
7.1 部署架构建议
开发环境:
- • Docker Compose单机部署
- • 本地数据库
- • 关闭Telemetry
测试环境:
- • 独立的Langfuse实例
- • 完整的测试数据集
- • 启用所有评估功能
生产环境:
- • Kubernetes集群部署
- • 高可用PostgreSQL
- • Redis缓存
- • 负载均衡
- • 定期备份
7.2 数据安全与合规
1. 数据加密
# docker-compose.ymlenvironment: - ENCRYPTION_KEY=your-32-character-secret-key-here - NEXTAUTH_SECRET=another-secret-key
2. 访问控制
- • 使用SSO集成(OAuth/SAML)
- • 基于角色的权限管理
- • API密钥轮换策略
3. 数据保留策略
-- 设置数据保留90天DELETE FROM traces WHERE timestamp < NOW() - INTERVAL '90 days';
7.3 性能调优
数据库优化:
-- 创建索引CREATE INDEX idx_trace_timestamp ON traces(timestamp);CREATE INDEX idx_trace_user_id ON traces(user_id);CREATE INDEX idx_trace_session_id ON traces(session_id);-- 分区表(大规模场景)CREATE TABLE traces_2024_q1 PARTITION OF traces FOR VALUES FROM ('2024-01-01') TO ('2024-04-01');
应用层优化:
# 连接池配置langfuse = Langfuse( request_timeout=30, # 超时时间 max_retries=3, # 重试次数 debug=False # 生产环境关闭debug)
7.4 监控Langfuse自身
健康检查:
import requestsdef check_langfuse_health(): response = requests.get("http://localhost:3000/api/health") if response.status_code != 200: send_alert("Langfuse服务异常")
关键指标:
- • API响应时间 < 200ms
- • 数据摄入延迟 < 5s
- • 数据库连接数 < 80%
- • 磁盘使用率 < 70%
八、成本分析与ROI计算
8.1 Langfuse部署成本
自托管方案(月):
| 资源 | 规格 | 成本 |
|---|---|---|
| 应用服务器 | 4核8G | $50 |
| PostgreSQL | 8核16G | $100 |
| 存储 | 100GB SSD | $20 |
| 合计 | $170/月 |
云服务方案:
- • Free Tier:免费,最多1000 traces/月
- • Pro:$29/月,最多10,000 traces
- • Enterprise:定制,无限traces
8.2 ROI计算
案例:某SaaS公司(月活10万用户)
实施前:
- • 月LLM成本:$10,000
- • 问题排查时间:10小时/次 × 5次/月 = 50小时
- • 工程师成本:小时5,000
- • 总成本:$15,000/月
实施Langfuse后:
- • 月LLM成本:$7,000(优化30%)
- • 问题排查时间:1小时/次 × 5次/月 = 5小时
- • 工程师成本:小时500
- • Langfuse成本:$200/月
- • 总成本:$7,700/月
月度节省:7,700 = $7,300
年度ROI:(2,400) / $2,400 = 3550%
8.3 隐性收益
除了直接成本节省,还有:
- • ✅ 用户满意度提升
- • ✅ 产品迭代速度加快
- • ✅ 团队效率提升
- • ✅ 风险降低(避免成本失控)
九、常见问题FAQ
Q1: Langfuse会影响应用性能吗?
A: 影响极小。Langfuse采用异步批量上传,对主流程的影响通常 < 10ms。建议使用异步SDK和合理的批量配置。
Q2: 数据隐私如何保障?
A:
- • 自托管:数据完全在你的基础设施
- • 云服务:支持数据加密和GDPR合规
- • 可以过滤敏感字段后再上传
Q3: 支持哪些LLM模型?
A: 支持所有主流模型:
- • OpenAI (GPT-3.5/4/4o)
- • Anthropic (Claude)
- • Google (Gemini)
- • 开源模型(通过自定义集成)
Q4: 如何处理高并发场景?
A:
- • 使用消息队列缓冲(Kafka/RabbitMQ)
- • 水平扩展Langfuse实例
- • 启用数据采样
- • 优化数据库索引
Q5: 能否与现有监控系统集成?
A: 可以。Langfuse提供:
- • REST API
- • Webhook
- • 数据导出功能
- • 支持Grafana等可视化工具
十、总结与展望
10.1 核心要点回顾
通过本文,你已经学习了:
✅ 为什么需要可观测性:AI Agent的不确定性要求完整的监控体系
✅ Langfuse的核心功能:Trace追踪、Prompt管理、评估系统、数据集管理
✅ 快速部署:5分钟搭建开发环境,云服务即开即用
✅ 实战集成:LangChain、LlamaIndex等主流框架
✅ 生产实践:性能优化、安全合规、成本控制
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 10
10 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)