浅谈具身世界动作模型 — Embodied World Action Model
本文探讨了具身智能领域世界模型与VLA(视觉-语言-动作)模型的发展现状与差异。25-26年,车企纷纷布局VLA和世界模型技术,如理想的DriveVLM、小鹏的XBrain等VLA应用,以及特斯拉、蔚来等企业的世界模型探索。文章分析了两者在数据来源、降维方式、建模路径上的本质区别:世界模型通过无监督学习预测环境变化,VLA则依赖语言抽象指导动作。当前世界模型正通过四条技术路线(MoT、外挂动作解码
https://zyxin.xyz/blog/2026-03/embodied-world-action-model/
25年到26年,在Robotics或者说具身智能领域,新的大模型如雨后春笋般冒了出来,不过大部分都是基于VLA或者世界模型的思路来的。
而在智驾领域,工业界对VLA和世界模型的布局更早了许多。在23年ChatGPT大爆发后,车企们争先恐后地将VLM给应用上车。其中最早的当属理想24年2月的DriveVLM,利用快慢系统打响了大模型上车的第一炮,随后有小鹏24年发布的XBrain,以及Waymo在24年下半年发布的EMMA。到了25年就更热闹了,首先是蔚来行业首个大规模推送的VLA模型,然后晚一点元戎发布VLA、Tesla在CVPR上提到使用语言增强FSD训练,再到最近小鹏发布VLA2.0,可以看出VLA这两年一直是智驾当红炸子鸡。
而在世界模型方面,车企们几乎是齐头并进地在探索。特斯拉早在2023 CVPR分享上即展示了General World Model的能力,是智驾行业商用世界模型的先驱,不过能看到当时图像重建质量有明显缺陷。而在国内,蔚来早在24年7月的NIO IN技术分享上就提出了NWM(NIO World Model),已经能看到图像重建质量已经超过一年前的特斯拉,NVM的发布也促使我写了上一篇行业博客。而后,智驾则进一步转向了世界模型与动作能力的结合:华为在25年4月发布的ADS 4.0采用了端云协同的WEWA架构(World Engine + World Action Model),而紧跟其后吉利在CES 2026上发布了WAM世界行为模型。学术界也有DreamZero等工作探索世界模型与动作的统一建模。
最近也有很多人问到这些概念的区别,我就来讲讲他们的来世今生,以及我认为我们需要追求的具身基础模型范式——具身Embodied世界World动作Action模型Model。
世界模型 & VLA
Disclaimer:这一节的VLA和世界模型仅指狭义的“世界模型”和“Vision-Language-Action”模型。他们并不是正交的两个概念,世界模型的定义更多的是从使用场景和训练监督范式出发,而VLA更多地是从数据模态出发进行的定义。近两年出了很多的将两者特点相互融合的文章,例如WorldVLA和DM0。这一节讨论二者的差异,就暂且把这一类融合的工作先排除在外。
定义
世界模型World Model——或者简称WM——这个概念最早可以追溯到基于模型的强化学习(Model-based RL)。在那个时代,世界模型指的是智能体在脑海中构建一个环境模型,能够预测“如果我采取某个动作,环境会变成什么样”。这个词真正被接受的广泛定义可能来自于Google Brain的《World Models》这篇论文。后来随着LeCun提出JEPA架构,以及视频生成领域的兴起,世界模型这个词也被广泛用于描述那些能够预测未来状态的生成模型。
In this context, I define world modeling as predicting the next plausible world state (or a longer duration of states) conditioned on an action.
― Jim Fan, The Second Pre-training Paradigm
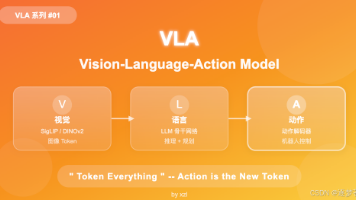
而VLA则简单直接得多——VLA = VLM + A,即在视觉Vision语言Langauge大模型Model的基础上,再接一个动作Action的编码和解码结构。
这里也引用一下WorldVLA文中被引用很多次的一张图:
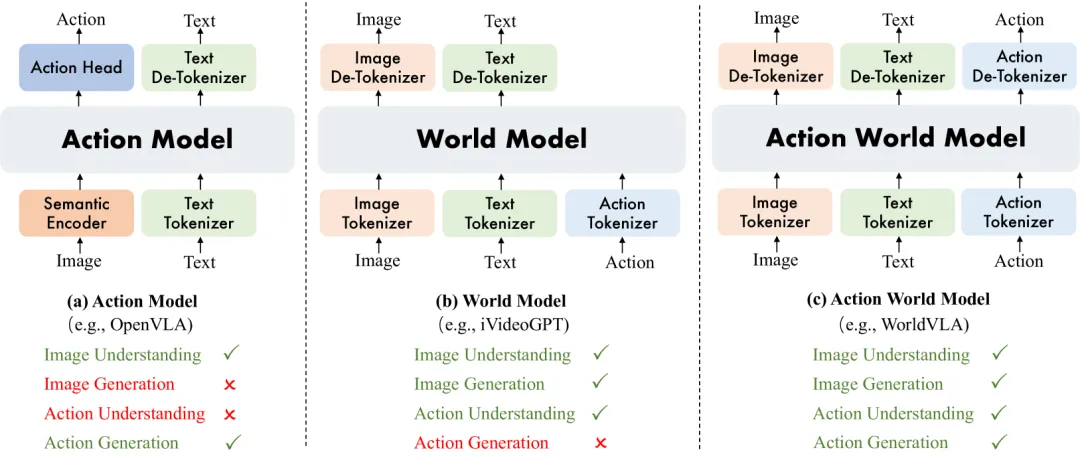
WorldVLA中对世界动作模型的解释
本质和区别
尽管两者常常被放在一起讨论,但它们的出发点其实很不一样:
- 数据来源与降维方式
世界模型的出发点是利用无标注数据学习世界的规律。它不需要人类告诉模型"这个动作是什么意思",只需要模型通过观察海量的视频数据,自己去发现"如果我把杯子推倒,里面的水会流出来"这样的因果规律。这是一种“自底向上”的学习方式。
而VLA的出发点是通过人类智慧的结晶——语言,来将世界降维。它利用了我们在VLM上已经积累的强大表征能力,通过语言这个高度抽象的符号系统来理解任务指令,然后再输出动作。这是一种"自顶向下"的传递方式。
- 理解 vs 生成
在大模型时代,世界模型一般都走的是生成模型路线——T2I(文生图)、T2V(文生视频)、TTS(文本转语音)。它们的本质是"我能创造一个我理解的世界"。
而VLA一般都走的是理解模型路线——I2T(图像转文本描述)、V2T(视频转文本描述)、ASR(语音转文本)。它们的本质是"我能用语言描述我看到的世界"。
最终我们需要的是理解、生成统一的模型。但这两条路线在现阶段还是有着明显的分界。
- 连续 vs 离散的世界认知
在具身领域,VLA有一个根本性的局限:世界本质上是连续的(请允许我用"连续"这个词,不要用普朗克常数来杠我)。很多物理状态及其变化都无法通过语言精确描述。
举个例子:当你拧螺丝的时候,你需要感知螺丝的阻力、判断拧紧的程度、调整手腕的角度以避开杯柄的阻挡——这些都是连续的、细微的物理量,语言很难精确描述。但世界模型可以通过视频预测直接学习这些物理规律。
Scaling的两条路径
除了上述的原理性差异,当前VLA和世界模型的发展在scaling策略上也呈现两条明显不同的路径:
从基座数据出发: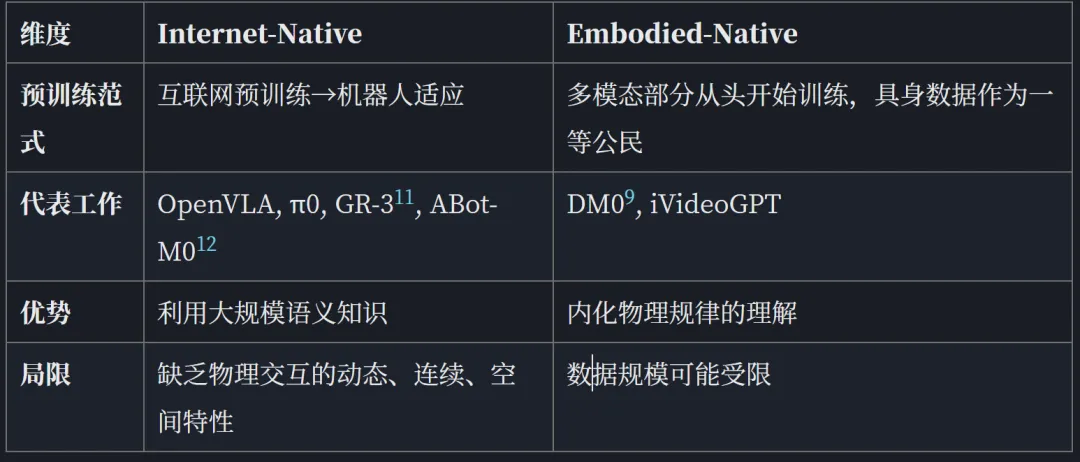
从核心建模的要素出发:
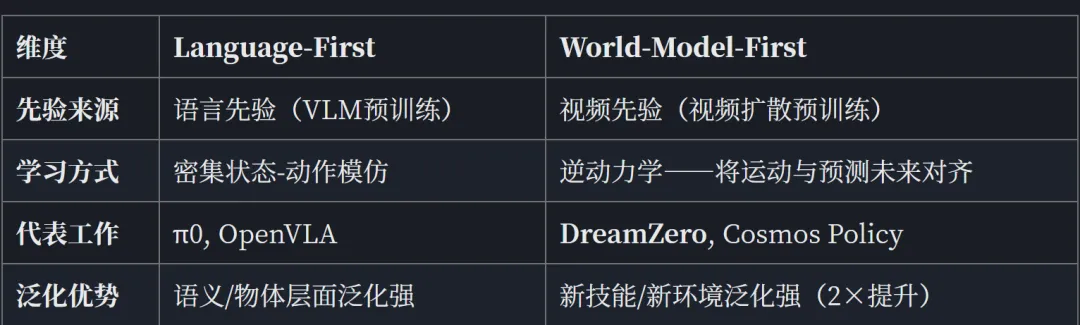
… Even on simple pick-and-place tasks (PnP Easy), VLAs occasionally reach toward the correct object but fail to interact accurately with unseen objects in novel environments. In contrast, DreamZero successfully learns from heterogeneous data, achieving 62.2% average task progress—over 2× higher than the best pretrained VLA baseline (27.4%), …
― DreamZero
WAM:赋予世界模型规划动作的能力
世界模型虽然能预测未来,但它本身并不输出动作(哪怕它可以根据动作输入去预测未来)。要让它能控制机器人,还需要一条从世界模型到策略Policy出action的通路。类比于VLA = VLM + A,这里WAM = WM + A。
目前业界实现WAM(通常会取名为XX-policy或者XX-VA)主要有四条路线:
一、VLM + Mixture of Transformers (MoT):这条路线需要修改backbone本身,原生支持多条transformer网络,可以看作是MoE(Mixture of Experts)的升级版。它将VLM Expert和Action Expert集成在同一个backbone中,两者有独立的FFN和Q/K/V/O投影矩阵,分别负责语义理解/规划和低层控制执行。这个路线的工作包括自变量WALL-OSS、小米Robotics-0、MoTVLA(统一快慢推理架构)等。其中代表工作Being-H0.5采用MoT+MoF架构,在UniHand-2.0数据集(3.5万+小时)上实现单一checkpoint在30种机器人具身的跨具身部署。
二、基础模型 + Action Expert:这条路线由Physical Intelligence公司的Pi0工作提出,核心思想是冻住backbone的结构,额外利用其隐特征(hidden features)去构建外部网络来输出动作。这种方式不需要修改backbone本身,而是在预训练模型的基础上"外挂"一个动作解码器,跟MoE其实没啥关系,但是不少地方也会把这个称为MoE。这一架构后来被多个后续工作采用。延续到代表工作之一DM0,其提出Embodied-Native范式,将具身数据视为与语言和视觉数据同等的first-class citizen。作为其一种变体,DriveLaW提出Chained架构,将视频生成器的latent features直接注入planner,从大规模视频生成学到的表示比传统BEV或VLM features具有更好的语义一致性。
三、视频生成模型 + Co-Diffusion:这条路线其实跟MoT路线很像,但是MoT起点一般是VLM,这条路则会基于视频Diffusion模型修改。其核心思想是:已有视频扩散模型能生成未来的视觉状态,然后通过增加一条动作的diffusion链路,并且跟视频diffusion进行同步去噪,学习如何让预测的未来与动作对齐。相关的工作包括NVIDIA的Cosmos Policy、DreamZero、以及最新的蚂蚁LingBot-VA等。其中DreamZero(14B参数)实现零样本泛化相比SOTA VLA提升2×以上;Cosmos Policy则是通过构造Latent Frame将动作编码直接注入视频扩散序列。
四、纯自回归Autoregressive:这条路线试图将世界模型和动作模型完全统一在一个自回归框架中。代表工作包括非具身领域的腾讯混元1.5,使用自回归diffusion架构;阿里巴巴的WorldVLA(统一世界模型和VLA的单一框架),它能够完全自回归地生成文本、图像和动作;清华和华为提出的iVideoGPT,使用纯自回归的方法同时增加了图像压缩模块,然后action和reward穿插在图像token中进行学习。此外还有OpenVLA-OFT,使用并行解码来提高效率[^openvla-oft];我个人可能更看好纯自回归路线,因为它的架构最简洁,并且更容易插入新的模态。但这条路线也面临着长序列建模中的误差累积问题,有待未来的探索。
相比于从语言预训练出发的VLA,我认为从世界模型出发的WAM是更适合具身行业的一条路线——说到底还是因为,具身行业采物理环境的数据容易,采语义标签丰富的数据难。不过,这里仍然需要说明的一点:WAM和VLA并不是对立的,WAM通常也会纳入语言这个模态,只是语言的比重不会那么高。
目前的WM/WAM还缺什么
尽管世界模型在2025年取得了巨大进展,但距离真正理解物理世界还有很长的路要走。
一、对力触觉的理解:目前绝大多数世界模型都是基于视觉的。但在机器人与物理世界的交互中,力觉和触觉是不可或缺的。当你拿起一个鸡蛋时,你需要感知它的重量、表面的光滑度、蛋壳的脆弱性——这些都无法仅从视觉中获得。
模态缺失:
我读过的数十篇篇近期世界模型和VLA论文中,鲜有工作真正融合了力觉或触觉传感器数据:DreamZero、Cosmos Policy、GR系列、DWM、ABot-M0、Being-H0/H0.5等所有工作主要或完全依赖视觉输入。
2025年,帕西尼感知科技发布了第三代多维触觉传感器,力感知精度达到0.01N。复旦大学研发的"电子皮肤"每平方厘米集成了4万个感知点,灵敏度是人类指尖的10倍。但这些传感器数据的建模和利用,还远未达到视觉的成熟度。

用手拧紧瓶盖,是一个典型的只有力触反馈做好之后才能搞定的任务
二、对声音信号的捕捉:人类社会的不少工具会被刻意设计成会产生指示音——微波炉热好食物的“叮”、电脑开机提示音的“滴”、扭矩扳手扭到位的“咔哒”等等。这些提示信号本质上是由声音/震动传导的指示信号,但目前的模型还很少利用这一模态。音频模态(Audio)作为捕捉震动的一种方式,除了接受这些信号之外还有更大的用处。例如,通过监听电机声音来判断负载情况,通过分析碰撞声音来判断物体材质,但这需要模型具备强大的多模态融合能力,并有充足的模态对齐数据供学习。
三、多视角统一理解:现有的世界模型大多缺乏显式的空间建模能力。当机器人从不同角度观察同一个物体时,模型很难将这些不同视角的信息统一起来形成一个一致的三维表征。这就是为什么我们经常看到视频生成模型在长视频中会出现"物体消失又出现"或"空间关系不一致"的问题。部分工作开始探索显式3D建模:DWM使用静态3D场景渲染作为输入以"确保空间一致性"24,ABot-M0通过Plug-and-Play 3D模块注入几何先验12。但真正的世界模型可能是需要具备显式的三维空间表征能力,空间不一致时当前基于视频生成模型的WM的主要短板之一。
EWAM:具身世界模型,到底怎么算具身
基于目前的不足,我认为未来的世界模型需要在以下几个方向取得突破:
一、对物理规律的理解:目前的泛化大多基于外表(appearance)。模型看到红色的杯子就知道应该拿红色杯子,但如果换成蓝色的杯子,或者换个角度、换个光照条件,模型可能就不认识了。我们需要的是基于物理规律的泛化。模型应该理解"杯子是易碎的"、“重力会让物体下落”、“摩擦力影响抓取力度"等物理规律,而不是仅仅记住特定物体的外观。这意味着模型需要在训练中接触到大量符合物理规律的数据,并且通过试错(Trial and Error)主动探索环境的边界,将这些经验抽象为物理规律与因果关系的知识图谱。
部分工作开始尝试从appearance-based转向physics-based:ABot-M0提出"动作流形假设”——有效机器人动作在受物理规律约束的低维平滑流形上,而非全维度空间。
二、跨本体同一建模:不同的机器人本体(机械臂、四足机器人、人形机器人)有不同的传感器配置和运动学结构。目前的大多模型都是针对特定本体训练的,难以跨本体迁移。未来的世界模型需要学习到"本体无关"的物理表征——无论你是用机械臂还是用灵巧手,“抓取"这个动作的物理本质是一样的。
近期相关的进展包括:Being-H0.5提出"人类数据作为物理交互的母语”,通过Unified Action Space单一checkpoint在5个机器人平台部署15;ABot-M0的UniACT数据集整合600万+轨迹、9,500+小时数据、20+种机器人具身12;DreamZero跨本体迁移仅需30分钟play data,相对提升42%7。
三、显式空间建模:为了实现空间一致性,世界模型需要显式地建模三维空间。这可以通过3D点云、神经辐射场(NeRF)、3D高斯溅射(3DGS)等技术实现。显式空间建模不仅能让模型理解"物体在不同视角下的一致性",还能让模型进行物理仿真——预测"如果我把这个物体推一下,它会怎么滚动、会和什么物体碰撞"。显示建模不意味着模型本身需要构建在某种3D表示上,而是模型在训练时需要充分监督其3D理解与生成能力,最近的LingBot-Depth就是这个方向很好的一篇工作
四、强交互传感器融合:最后,也是我认为最重要的一点:未来的世界模型必须融合力觉、触觉等强交互传感器。只有当模型能够"感觉"到物理世界——感受到力的反馈、震动的传递、表面的纹理——它才能真正理解物理规律,才能在复杂环境中执行精细操作任务。这就是我所说的"具身"世界动作模型的核心内涵。
我把具有以上特点的世界动作模型,称之为具身Embodied世界World动作Action模型Model。因为它与现在常提到的世界模型,甚至世界动作模型有显著的差异,它才更像一个能在真实世界活动、工作、体验的人,它能感受到各类感官,对空间有充足的理解,并且知道如何利用物理规律改变一些事物。
让世界模型“具身”只是第一步,如何迈向真正全能的具身系统?
世界(动作)模型不是走向具身AGI的万金油,但它是让人工智能理解物理世界的重要手段。在此基础上,我们仍然需要长程的、verbal的、模态交织的长思考来满足复杂任务的拆解。
我判断会有另一套范式(可能从VLM延伸出去)来解决这个问题——让我们称之为Reasoning Model(推理模型,与世界模型相对)。这与大模型理解-生成的两条路线类似:
-
理解类模型更强调语言推理、长程任务拆解,在具身里更适合做任务编排大脑、奖励模型——适合作为Reasoning Model的架构
-
生成类模型更强调保真和多模态、以及条件生成等,模型推理时间可控——适合作为World (Action) Model的架构
而在我眼里,最终世界模型和推理模型会按照人类的快慢系统神经架构进行合作:
-
World Action Model构建本能快思考(System I):高频运行,密集地理解物理世界,直接输出反应式动作
-
Reasoning Model构建大脑慢思考(System II):以较低频率稀疏地理解物理世界,但密集地进行长程思考、任务拆解和反思监督
绝大部分时候都是本能系统(World Model)直接发挥作用——就像人类走路时不需要思考"先迈左脚还是右脚"。而大脑(Reasoning Model)则负责任务拆解、异常情况处理和动作监督反思——就像人类遇到复杂路况时会停下来思考该怎么走。虽然这已经很俗套了,但是仍然是在工程上看起来可行,且优雅的解。
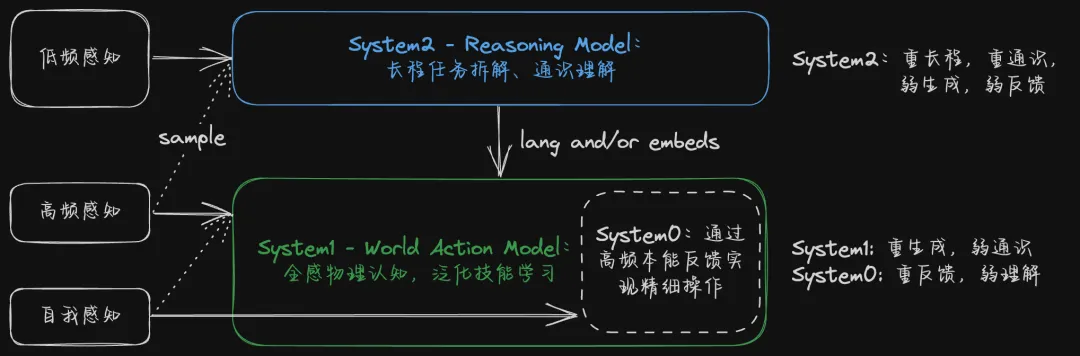
目前我认为最理想的具身模型架构
这里的架构跟之前智驾领域的双系统(例如陈龙博士在他的博客里提到的推理与决策架构)稍有不同,智驾通常提到的System I快思考,是由端到端网络所完成的,端到端驾驶网络通常不是通识模型,不怎么会用领域外的数据来训练。这个角色更像是我所设想的System 0,而上图的System I则是直接由WAM构成,它本身也应该是个Foundation Model,应该获得领域外数据的监督以获得很好的泛化性。因此,这个框架里实际上有两个Foundation Model,只是一个重长程任务拆解,一个重物理世界反馈。至于他们谁跑的快,谁跑的慢,这实际上只是个工程问题,跟模型尺寸有关。
双系统这个事又是个大课题了,目前我也只是有一些初步的想法,希望在未来有了更多的探索和经验后再来跟大家分享。
结语
回到标题,我认为现有的WAM架构探索尚属早期,我们还没有抓住“具身”的真正内涵。真正能在各种泛化场景任务下都能表现优秀的“具身”世界动作模型,核心在于三点:
-
强交互传感器建模:必须包含力觉、触觉等模态,这是模型真正能改变物理世界的窗口与扳手。
-
底层物理规律理解:基于物理规律实现泛化,而非基于外表Appearance。这意味着模型需要通过试错主动探索环境边界,将经验抽象为物理规律与因果关系25。
-
三位空间建模:以实现空间一致性和跨视角统一理解,这是当前视频生成模型的主要短板之一。
只有做到这三点,我认为我们才真正拥有了“具身”的世界动作模型——一个不仅能够“看见”世界,更能够“感觉”世界、“理解”世界,并在物理世界中灵活行动的AI系统。
这条路还很长,但2025-2026年的技术演进让我相信,大模型能真正理解与改变物理世界,像人一样通过在物理环境里摸爬滚打成长的时代,正在到来。
参考资料
-
(arXiv) EMMA: End-to-End Multimodal Model for Autonomous Driving
-
一辆车,如何在停车场自主寻路?
-
[CVPR’23 WAD] Keynote - Ashok Elluswamy, Tesla
-
「预知」未来,找到「最优解」,这就是蔚来的「魔法」
-
华为乾崑ADS 4深度技术解析
-
吉利汽车集团发布WAM世界行为模型 AI技术体系进化到2.0时代
-
(arXiv) World Action Models are Zero-shot Policies
-
(arXiv) WorldVLA: Towards Autoregressive Action World Model
-
(arXiv) DM0: An Embodied-Native VLA towards Physical AI
-
(arXiv) World Models
-
Seed GR3 - 一个可泛化、支持长序列复杂操作任务的机器人操作大模型
-
(arXiv) ABot-M0: VLA Foundation Model with Action Manifold Learning
-
(arXiv) Xiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution
-
(arXiv) MoTVLA: Mixture-of-Transformers based Vision-Language-Action Model
-
Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
-
(arXiv) π0: A Vision-Language-Action Flow Model for General Robot Control
-
(arXiv) DriveLaW: Unifying Planning and Video Generation in a Latent Driving World
-
(arXiv) Causal World Modeling for Robot Control
-
(arXiv) Cosmos Policy: Fine-tuning Video Models for Visuomotor Control and Planning
-
HY-World 1.5: A Systematic Framework for Interactive World Modeling with Real-Time Latency and Geometric Consistency
-
(arXiv) iVideoGPT: Interactive VideoGPTs are Scalable World Models
-
帕西尼发布第三代多维触觉传感器GEN3:以顶级触觉,重塑具身感知未来
-
机器人也能有触觉!复旦AI“电子皮肤”WAIC首秀
-
(arXiv) Dexterous World Models: Egocentric Simulation from Dexterous World Models
-
具身智能如何进化?关键在于如何“试错”
-
(arXiv) Masked Depth Modeling for Spatial Perception
-
具身智能漫长的进化史、下一个Scaling与硝烟

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)