实测:VLA用扩散模型比自回归快100倍!
扩展规模VLA模型在不同硬件平台上的推理性能对比。扩散与自回归VLA性能对比:在动作块大小(左图)和自由度(右图)增加时,经典自回归模型(蓝色)的延迟呈指数级增长,而基于扩散的模型(绿色/橙色)则保持近乎恒定的低延迟。基于VLA-Perf的分析模型,研究团队对π₀这一代表性的VLA模型在不同硬件上的性能进行了预测,并给出了一系列关于模型缩放、长下文推理等关键问题的洞见。将所有模型组件的延迟和数据在
你以为VLA在思考,其实它光是看清楚你在哪儿就已经“累够呛”……
——VLA的速度计算器
目录
今天这篇文章,我们将视线聚焦在VLA的推理速度上面,如何判断一个模型:它反应得够快吗?
在机器人需要与动态环境实时互动的场景下,比如抓住一个下落的物体或避开一个移动的障碍,毫秒级的延迟都可能导致任务失败。
业界普遍认为,10Hz(每秒10次决策)是可接受的实时门槛,而100Hz则是真正的高性能标准。
但是,VLA的推理性能一直是个“谜”。
模型大小、架构选择、硬件平台、网络条件……这些变量组合出了一个近乎无限的复杂空间。

我们如何知道一个800亿参数的VLA在WiFi 6网络下连接到云端GPU能跑多快?我们又该如何设计下一代模型和系统,以最低成本实现最高性能?
今天这篇来自NVIDIA团队的研究,提出了一个名为VLA-Perf的分析工具。
它就像一个VLA的“性能仪表盘”,通过一个对模型进行分析,精确预测出任意VLA在特定硬件和网络配置下的端到端推理速度。
01 如何将VLA性能“算”出来?
面对VLA推理这个由无数变量构成的“黑箱”,VLA-Perf 将整个端到端推理流程分解为一系列独立且可预测的基本组件。
一个典型的同步VLA推理过程包括:
机器人从摄像头捕捉图像,将图像数据传输给推理系统;
系统进行VLA模型的前向传播生成动作指令;
最后机器人执行动作。
这个过程必须在下一次相机捕捉到新画面之前完成,才能保证实时性。
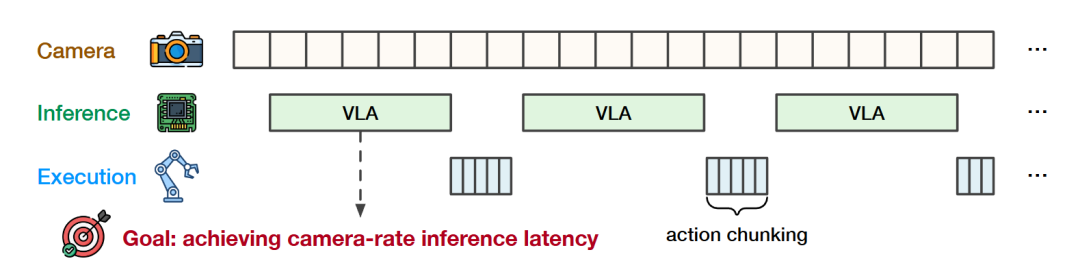
▲图1 | 同步VLA推理时间线:整个流程从相机捕捉图像开始,到机器人执行动作为止,其总延迟必须小于相机帧间隔,才能实现实时交互。
VLA-Perf将这个流程进一步拆解为视觉编码器、VLM主干网络和动作专家三个核心模型组件,以及它们之间的数据传输过程。
对于每一个模型组件的运算,VLA-Perf都采用了高性能计算领域经典的Roofline模型进行建模。
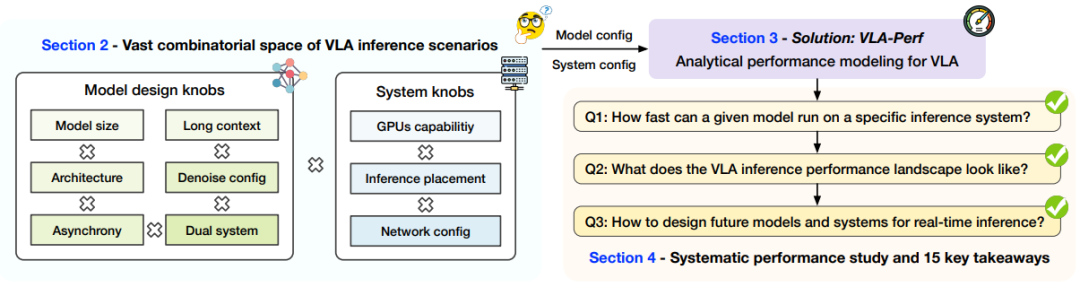
▲图2 | VLA-Perf框架概览:它将复杂的VLA推理场景分解为模型和系统两大类配置参数,并围绕“一个模型能跑多快?”“性能瓶颈在哪里?”以及“如何设计未来系统?”这三个核心问题展开系统性分析。
Roofline模型指出,任何计算任务的性能上限,要么受限于处理器的浮点运算能力(FLOP/s),要么受限于内存带宽(Memory Bandwidth)。
通过这个模型,VLA-Perf可以精确计算出每个算子(Operator)的延迟。
将所有模型组件的延迟和数据在不同硬件(如CPU、GPU)之间传输的延迟相加,就得到了整个VLA的端到端推理延迟预测。
这个看似简单的模型,却抓住了决定性能的关键,其预测结果与在真实硬件(如RTX 4090)上运行的延迟相比,保真度高达70-80%,展现了强大的预测能力。
02 研究亮点:一些发现
架构选择的惊人影响:扩散模型比自回归快100倍
在动作生成方面,VLA通常采用自回归(Autoregressive)或扩散(Diffusion)两种范式。
传统观念认为,自回归模型逐个token生成动作,虽然精确但速度很慢。VLA-Perf的分析首次定量揭示了其速度劣势有多么巨大。
研究显示,在生成中等长度的动作序列(chunk size=50)时——
基于扩散的VLA(如论文中使用的π₀模型)比经典的自回归VLA快超过100倍!
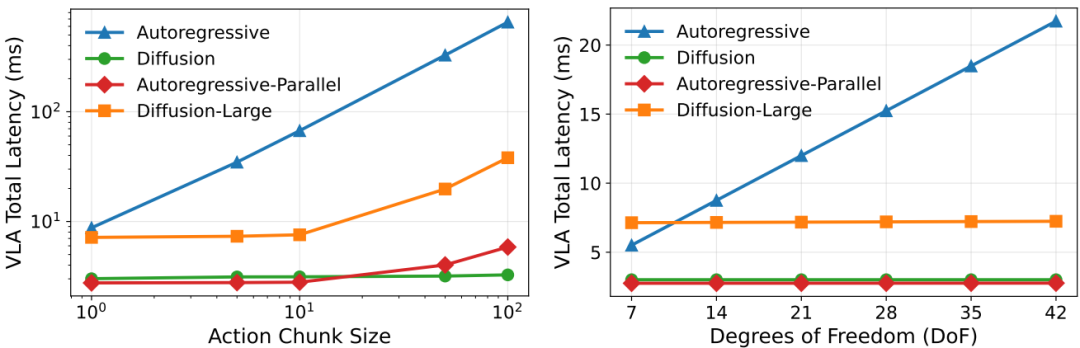
▲图3 | 扩散与自回归VLA性能对比:在动作块大小(左图)和自由度(右图)增加时,经典自回归模型(蓝色)的延迟呈指数级增长,而基于扩散的模型(绿色/橙色)则保持近乎恒定的低延迟。
这一“堪称惊人”的根源在于计算特性。
自回归模型每生成一个token都需要进行一次完整的VLM前向传播,使其成为计算密集型任务,延迟随动作序列长度线性增长。
而扩散模型可以一次性并行生成整个动作序列,其计算主要集中在内存密集型的去噪网络上,对序列长度变化不敏感。
这一发现为未来VLA架构设计提供了明确指导:
在需要快速连续动作的场景,扩散模型是毫无疑问的最优选择。
部署策略的权衡:云端推理并非总是最优解
“将计算卸载到云端”似乎是解决端侧算力不足的万能钥匙。但对于延迟敏感的机器人任务,网络延迟可能成为新的瓶颈。
VLA-Perf 对设备端(On-device)、边缘服务器(Edge-server)和云端(Cloud)三种部署策略进行了系统性对比。
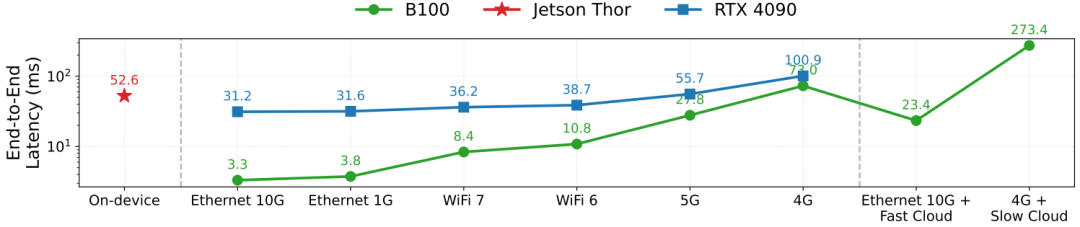
▲图4 | 不同部署方式下的端到端延迟对比:在各种网络条件下,边缘服务器(蓝色/绿色线)通常优于纯设备端推理(红色星形),但网络质量是决定性因素。
分析得出了一个“反直觉”的结论:在大多数情况下,使用本地网络连接的边缘服务器(即使只配备消费级GPU如RTX 4090)是最佳选择。
它不仅远快于纯设备端推理(在Jetson Thor上为52.6ms),而且在良好网络(如10G以太网或WiFi 7)下,其延迟(3-8ms)甚至低于连接到云端顶级B100 GPU的延迟(23.4ms)。
只有在网络条件极差(如4G网络+慢速云连接)时,云端推理的延迟才会飙升至无法接受的273.4ms。
异步推理的魔力:让吞吐量提升13倍
除了优化模型和硬件,VLA-Perf还探索了计算流程本身的优化空间,其中最亮眼的就是异步推理(Asynchronous Inference)。
在传统的同步模式下,机器人必须“等待”VLA完成思考才能行动。
而在异步模式下,VLA可以基于前一时刻的观测进行“预判”,并将推理计算与机器人的物理动作执行并行起来。
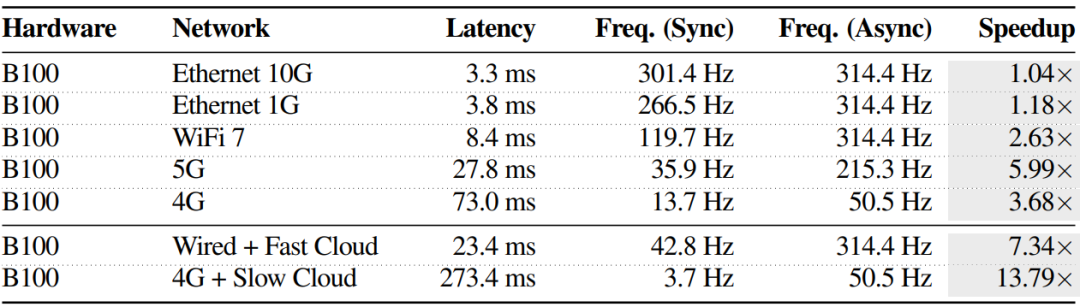
▲图5|采用双系统(异步)推理机制带来的性能提升。该表对比展示了引入双系统推理架构前后的性能变化情况,量化分析其在推理效率、响应速度或整体系统表现方面的提升效果。
这种并行带来了巨大的性能提升,尤其是在有显著网络延迟的服务器端推理场景中。
VLA-Perf 的分析显示,在云端推理场景下,采用异步可以将系统吞吐量从同步模式下的3.7Hz提升到50.5Hz,增幅高达13.79倍!
即使在网络条件较好的WiFi 7环境下,异步也能带来2.63倍的吞吐量提升。
这一发现揭示了通过软件和系统层面的优化,可以在不改变模型或硬件的情况下,极大压榨VLA系统的性能潜力。
03 更多结论
基于VLA-Perf的分析模型,研究团队对π₀这一代表性的VLA模型在不同硬件上的性能进行了预测,并给出了一系列关于模型缩放、长下文推理等关键问题的洞见。

▲图6|扩展规模VLA模型在不同硬件平台上的推理性能对比。该表比较了规模增大的视觉-语言-动作(VLA)模型在多种硬件平台上的推理表现,分析模型参数规模与算力平台差异对计算效率和系统性能的影响。
-
模型缩放:VLA的推理延迟与模型参数量大小近似线性相关。
一个标准的2.7B π₀模型在边缘设备Jetson Thor上可以跑到19Hz,但在数据中心级的B100上可以跑到惊人的314.4Hz。
而当模型扩展到81B时,只有B100还能勉强维持接近10Hz的实时推理能力。
-
长下文推理:随着机器人与环境交互时间的增长,VLA需要处理的上下文信息(过去的视觉帧)也越来越长。
分析表明,B100可以支持长达1000个时间步(约100秒)的实时历史回溯,而消费级的RTX 4090和边缘设备Jetson Thor则在超过100个时间步后性能便会急剧下降到10Hz以下。

▲图7|长上下文VLA模型的推理性能与显存占用对比。该表统计并比较了不同长上下文视觉-语言-动作(VLA)模型在推理阶段的性能表现及其内存消耗情况,用于分析上下文长度扩展对计算效率与资源需求的影响。
-
设备-服务器协同推理:一个看似合理的想法是将计算量大的VLM主干放在服务器上,将轻量的动作专家放在设备端。
然而,VLA-Perf 的分析否定了这种方案。因为VLM的KV Cache需要在服务器和设备间传输,其带来的网络开销使得这种协同方案的性能甚至不如纯设备端推理。
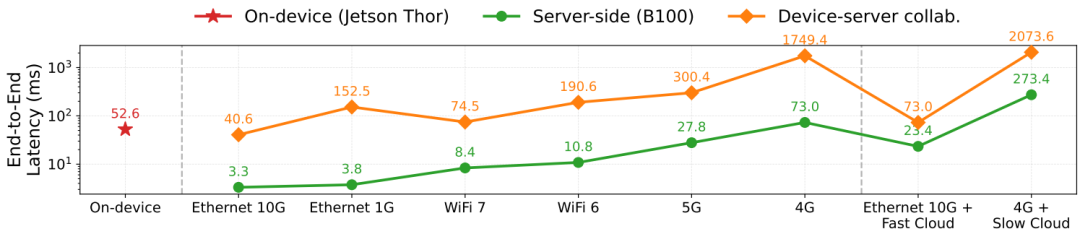
▲图8|端侧—服务器协同推理与纯服务器、纯端侧方案对比示意图。该图比较了设备—服务器协同推理架构与仅服务器部署、仅端侧部署三种方案的差异,展示不同计算分配方式在推理效率、延迟控制与资源利用方面的权衡关系。
04 总结与延伸
NVIDIA的VLA-Perf工作,首次为我们提供了一张清晰、量化的VLA推理性能地图——
将模型设计、硬件能力和系统部署这三个维度统一起来,并提炼出15条极具实践价值的“规则”。
当大模型的能力边界不断被拓宽时,如何让这些强大的“大脑”在物理世界中高效、敏捷地运行,将成为决定其能否真正落地的核心。
大家认为在机器人领域,是追求更强的模型能力更重要,还是追求更快的响应速度更关键呢?欢迎在评论区留言。
Ref
论文标题:How Fast Can I Run My VLA? Demystifying VLA Inference Performance with VLA-Perf
论文链接:https://arxiv.org/abs/2602.18397

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)