【世界模型】UrbanWorld: An Urban World Model for 3D City Generation
本文提出UrbanWorld,首个生成式城市世界模型,可自动创建高真实度、可交互的三维城市环境。通过渐进式扩散渲染和城市专用多模态大语言模型(Urban MLLM),UrbanWorld支持从开放地图数据或语义布局生成定制化城市环境。实验表明,该方法在五项视觉指标上达到最优真实度,并能有效支持智能体的感知与导航任务。该开源框架(https://github.com/Urban-World/Urba

标题:UrbanWorld:一种用于三维城市生成的城市世界模型
原文链接:https://arxiv.org/abs/2407.11965
源码链接:https://github.com/Urban-World/UrbanWorld
发表:预印本(ICLR-2025被拒)
https://openreview.net/forum?id=4W1wTg7q9o
摘要
城市作为人类生活的核心环境,包含建筑、道路、植被等多样的物理要素,且这些要素会与人类、车辆等动态实体持续交互。构建真实、可交互的三维城市环境,对于培育通用人工智能(AGI)系统、打造能在现实环境中像人类一样完成感知、决策与行动的人工智能体而言至关重要。然而,创建高保真的三维城市环境通常需要设计人员投入大量人工工作,涉及对复杂城市要素的精细化刻画与表达。因此,实现这一过程的自动化仍是一项长期存在的挑战。针对该问题,本文提出UrbanWorld——首个生成式城市世界模型,该模型能够在灵活的控制条件下,自动创建定制化、高真实度且可交互的三维城市世界。具体而言,本文设计了一种基于渐进式扩散的渲染方法,以生成带有高质量纹理的三维城市资产;同时,提出了一种专门的城市多模态大语言模型(Urban MLLM),该模型在真实的街景图文语料库上完成训练,可对生成过程进行监督与引导。UrbanWorld的生成流程包含四个关键阶段:基于开放街道地图(OSM)数据或含语义与高度图的城市布局,生成灵活的三维城市布局;借助Urban MLLM完成城市场景设计;通过渐进式三维扩散实现可调控的城市资产渲染;在多模态大语言模型的辅助下完成场景优化。本文基于五项视觉指标开展了全面的定量分析,结果表明UrbanWorld实现了当前最先进的生成真实度。此外,本文还通过文本和图像两种提示方式,展示了UrbanWorld可控生成能力的定性结果。最后,本文通过验证智能体在生成环境中的感知与导航能力,证实了这些环境的可交互特性。本文将UrbanWorld作为开源工具进行贡献,项目地址为:https://github.com/Urban-World/UrbanWorld。
1 引言
城市是最复杂的以人为中心的环境,其特征体现为复杂的空间结构、由建筑、基础设施和公共空间构成的异质组件,以及这些组件与人类活动之间的动态交互。构建高真实度的三维城市世界环境,是通用人工智能[1]、人工智能体[2]、具身人工智能[3]、城市仿真[4]和元宇宙[5]等多个领域开展广泛研究与实际应用的基础技术。传统上,构建这样的环境需要设计人员投入高昂的人工成本,完成精细化的资产建模、纹理映射和场景组合。随着生成式人工智能的发展,目前已出现一些基于体绘制[6,7]和扩散模型[8,9]的三维场景自动生成方法。这些方法革新了三维场景生成的范式,降低了人工设计的高成本。但通过这类方法构建的三维场景仅以视频格式呈现,无法提供具身交互式的环境。针对这一问题,一系列被称为世界模型的方法近期应运而生,这类方法最初聚焦于自动驾驶场景[10,11]。研究表明,这些模型具备理解场景动态性和预测未来状态的能力,提升了三维场景生成的交互性。然而,现有方法生成的城市环境与人类实际生活的真实城市世界之间仍存在巨大差距。综上,要实现真正的“城市世界模型”仍有很长的路要走,本文将城市世界模型定义为能够创建满足以下特征的城市环境的模型:(1)高真实度且可交互;(2)可定制且可调控;(3)能够支撑具身智能体的学习。表1从这些关键维度对现有的三维城市生成方法进行了全面综述,结果表明目前尚无任何一种方法能完全满足上述要求。
城市世界模型对于具身智能和通用人工智能的发展具有重要意义。首先,该模型有望弥合虚拟环境与现实世界之间的差距,使具身智能体能够在细节丰富、高度真实的城市环境中进行交互与学习。其次,通过构建合成的三维城市环境,研究人员能够完全掌控数据生成过程,获取所有生成参数,进而可在现实世界中不适合开展或需要多样环境支撑的任务上,对机器感知系统进行训练。最后,完善的城市世界模型能够模拟从繁华的城市中心到静谧的居民区等各类环境,同时还原建筑、道路、自然空间等物理基础设施的真实视觉外观。这对于避免模型过拟合、打造能在多样且动态的环境中具备高泛化能力的智能体而言至关重要。然而,目前尚无专门用于自动构建可交互三维城市环境的城市世界模型,这阻碍了人工智能通过复杂开放世界中的具身学习向通用智能发展。
针对上述问题,本文提出UrbanWorld——一种生成式城市世界模型,该模型能够根据用户指令和多种格式的城市布局数据(如开放街道地图(OSM)、含语义和深度图的布局[8,12]),自动创建高真实度、可调控且具身化的三维城市环境。具体而言,UrbanWorld的框架包含四个核心模块:首先,该模型利用上述输入数据自动生成无纹理的三维布局,并通过Blender软件完成精细化的资产处理;其次,采用经微调的城市专用多模态大语言模型(即Urban MLLM),根据用户指令高效规划和设计城市场景,生成城市要素的详细文本描述;再次,集成一个基于纹理扩散和优化的三维资产渲染器,该渲染器可通过文本和视觉条件实现灵活调控;最后,为进一步优化视觉外观,模型利用Urban MLLM对构建完成的三维城市环境进行检验,生成具体的优化建议并启动额外的一轮渲染过程。
本文提出的框架具备高度灵活性,可支持生成两种典型的三维城市环境:一方面,UrbanWorld能够以真实街景图像为生成条件,创建与真实城市环境高度贴合的复刻版本,这对于城市规划和地理信息系统相关研究具有重要价值;另一方面,该模型也能以文本描述为生成条件,创建完全定制化的城市环境,这一能力对于模拟和探索虚拟城市场景具有重要意义,在虚拟城市设计、游戏开发和应急响应规划等领域尤为适用。在实验部分,本文首先基于五项视觉指标开展全面的定量评估,验证了UrbanWorld生成环境的当前最优真实度;随后,展示了由多种文本和图像提示生成的多样化结果,凸显了UrbanWorld卓越的可调控性;最后,通过验证智能体在生成环境中的感知与导航能力,强调了所生成三维城市环境的可交互特性。本文将UrbanWorld作为开放平台进行贡献,以支持更先进的三维城市环境的创建与操作,为广大人工智能领域的发展提供助力。
本文的研究贡献可总结如下:
- 提出UrbanWorld,这是首个能够在灵活的控制条件下,自动创建高真实度、定制化且可交互的具身三维城市环境的城市世界模型;
- UrbanWorld展现出构建高保真三维城市环境的优异生成能力,大幅提升了环境中交互行为的真实性;
- 将UrbanWorld作为开源平台进行贡献,为三维城市环境的开发提供支撑,该平台可服务于具身智能、人工智能体等多领域研究,进一步为通用人工智能的发展奠定基础。
2 相关工作
2.1 三维城市场景生成
三维城市场景生成的目标是结合精细化的城市规划和视觉要素设计,创建高真实度的三维城市环境,这一过程通常需要投入大量人工工作,包括复杂的资产建模、纹理映射和场景组合。随着深度学习技术的发展,目前已出现三类实现该过程自动化的方法,分别为基于神经绘制的方法[6,7,13]、基于扩散的方法[8,18,19]和基于三维建模软件的方法[20,16,15],表1展示了各类方法的对比概述。
基于神经绘制的方法通过隐式方式表征城市场景,并对神经场进行体绘制。例如,CityDreamer[7]先将场景划分为建筑和背景两部分,再引入不同类型的神经场进行资产绘制。这类方法能生成视觉效果优异的画面,但可能损失几何保真度。基于扩散的方法利用扩散模型生成城市布局或城市场景,CityGen[8]提出了端到端的流程,结合稳定扩散模型创建多样化的三维城市布局。这类方法在生成场景图像或视频方面具有创新性,但难以构建具身化的三维环境,限制了实际应用场景。
近期出现了一些基于专业软件脚本的方法,这类方法尝试利用大语言模型构建自动化的智能体工作流,通过控制专业软件完成场景创建。CityCraft[17]利用大语言模型,基于现成的资产库设计和构建三维城市环境。这类方法虽具备一定有效性,但仅能利用现有三维模型创建城市环境,无法在需要时灵活生成新的资产。相比之下,本文提出的模型能够以高度可控的方式自主生成新的三维城市资产,支持构建多样化的城市环境。
2.2 三维世界模拟器
人工智能研究的一个长期目标,是开发能够像人类一样在三维空间中与各类环境进行交互的机器智能体。为实现这一目标,研究人员一直致力于构建以视频[21]或具身环境[22]为形式的各类交互式世界模拟器。现有世界仿真环境和平台大多面向室内场景[23,24,25,26],与之不同,三维世界(Threedworld)[27]聚焦于室外环境的创建,通过从现有资产库中检索并组合物体完成场景构建。
针对城市这一最重要的开放环境,现有研究大多聚焦于面向自动驾驶的生成式世界模型,这类模型能够学习场景动态性并理解物理世界的几何特征[10,11,28]。但此类模型仅能以视频形式生成新场景,难以提供可实际使用的具身化交互式城市环境。城市生成智能(UGI)[4]提出了城市世界仿真的相关构想,建议为智能体开发构建具身化的城市环境,但尚未完成实际落地。
近期,元城市(MetaUrban)[15]开发了面向城市环境中具身智能体的仿真平台,但其提供的环境风格固定,不具备可调控性。为解决上述问题,本文提出UrbanWorld,该模型有望助力构建视觉外观可调控、可精细化优化的多样化具身城市环境,为各类城市场景中的智能体开发和仿真提供支撑。
3 方法学
构建真正的“城市世界模型”需要解决三大核心挑战:高效的交互式环境构建、精细化的城市场景规划和高质量的纹理绘制。为实现上述目标,UrbanWorld采用了创新的“地图-设计-绘制-优化”生成流程,由专用的城市多模态大语言模型和城市资产绘制模块协同完成。具体而言,UrbanWorld包含四个关键阶段:(1)灵活的三维城市布局生成,基于开放街道地图(OSM)数据、含语义和高度图的城市布局等各类城市布局元数据,实现自动的2.5维到三维的映射,该阶段用于解决第一个核心挑战;(2)城市多模态大语言模型赋能的场景设计,利用经微调的城市多模态大语言模型对城市环境的卓越理解能力,模拟人类设计师完成高真实度城市场景的规划,该阶段用于解决第二个核心挑战;(3)基于扩散的可调控城市资产纹理绘制,通过支持文本和视觉双提示的三维扩散技术,实现灵活的城市资产绘制;(4)多模态大语言模型辅助的城市场景优化,利用城市多模态大语言模型对生成的城市环境进行检验和优化,模拟人类设计师标准化工作流程中的迭代修改过程。后两个模块共同实现了三维资产的高保真实纹理绘制,有效解决了第三个核心挑战。UrbanWorld的整体框架如图1所示。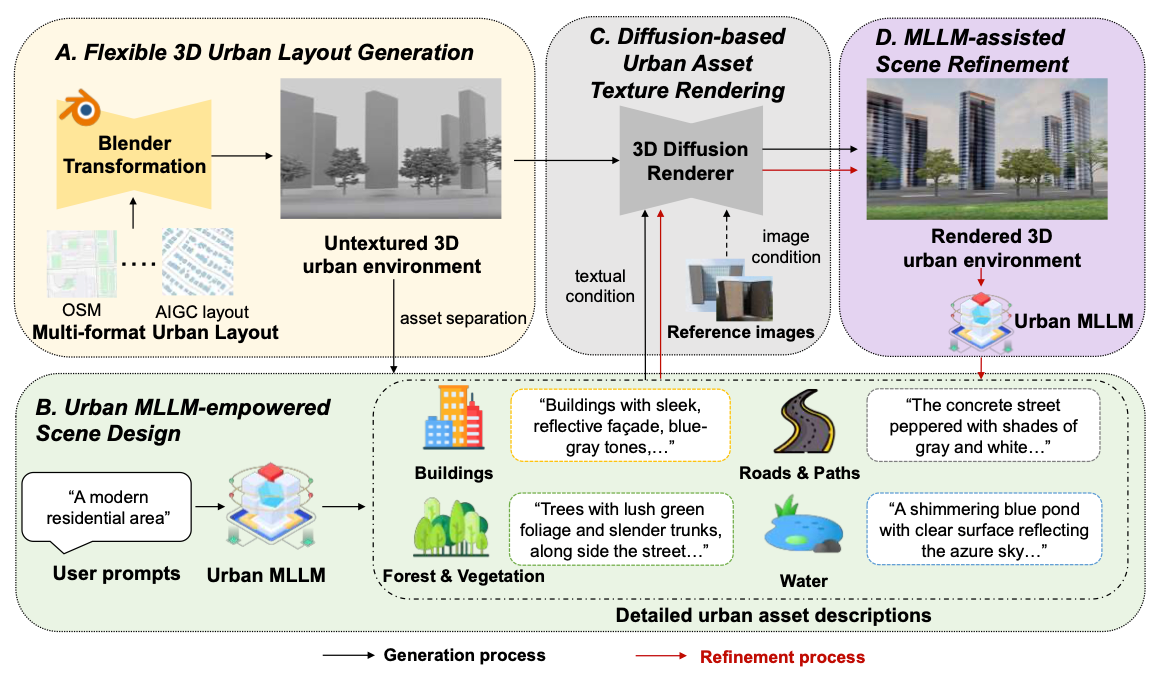
图 1:UrbanWorld 整体框架示意图,该框架包含四大核心模块:(A)灵活的三维城市布局生成;(B)城市多模态大语言模型赋能的城市场景设计;(C)基于扩散的城市资产纹理绘制;(D)多模态大语言模型辅助的城市场景优化。
3.1 灵活的三维城市布局生成
UrbanWorld支持以任意类型的2.5维布局数据为输入,高效构建无纹理的三维城市环境,如易获取的开放街道地图(OSM)数据、人工智能生成的城市布局数据等。这些2.5维布局数据记录了城市区域的元信息,包括道路、建筑、植被、森林、水域等各类城市要素的地理位置和属性特征。
所有城市资产会被自动拆分为独立的对象,用于后续的逐要素绘制。本步骤中,UrbanWorld还会记录每个对象的中心位置,以便后续对资产进行重组,使其与真实的城市布局相匹配。
3.2 城市多模态大语言模型赋能的场景设计
为高效构建定制化的城市环境,UrbanWorld集成了一款基于海量真实城市影像数据微调的先进多模态大语言模型,即城市多模态大语言模型(Urban MLLM)。具体而言,本文从谷歌地图中采集了约30万张城市街景图像,并利用GPT-4为其生成对应的文本描述;随后对这些描述进行人工审核,过滤掉低质量数据;最后,利用整理后的数据集对先进的开源多模态大语言模型VILA-1.5[29]进行微调,提升其对城市环境的理解能力。
在UrbanWorld的工作流程中,城市多模态大语言模型扮演着类人类设计师的角色,能够自动生成高质量、精细化的城市场景描述,确保构建的城市环境视觉上协调统一且符合用户指令要求。具体来说,模型将用户输入的简单文本指令(如“大学校园的教学区”)作为输入,通过精心设计的提示词调用城市多模态大语言模型,返回针对各资产视觉外观和材质的多样化详细描述,生成的资产描述将用于控制后续纹理绘制过程的条件。
3.3 基于扩散的可调控城市资产纹理绘制
由于城市场景包含复杂的要素和关联关系,大规模城市场景的绘制存在较大挑战,直接进行场景级绘制必然会出现纹理不匹配和分辨率偏低的问题。因此,本文采用逐要素绘制的策略,以保证绘制质量。同时,为提升绘制效率,本文对部分城市要素类型进行合并,最终定义了四大核心类别:建筑、道路与路径、森林与植被、水域。
简单来说,


本文采用基于扩散的可调控方法完成绘制,该方法包含UV纹理生成和纹理优化两个阶段,具体流程如图2所示。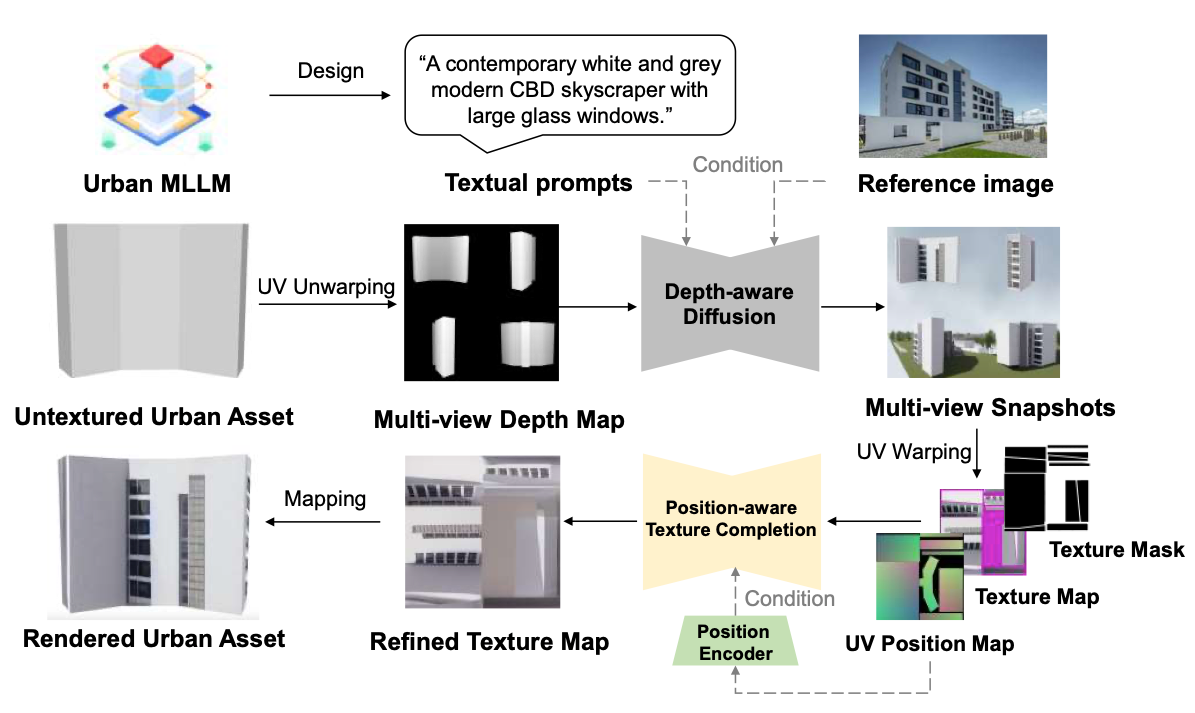
图 2:UrbanWorld 中城市资产纹理绘制方法的示意图,主要包含两个阶段:在文本与视觉提示下实现灵活控制的深度感知 UV 纹理生成,以及 UV 位置感知的纹理优化。
经过3.1节所述的三维环境生成步骤后,可得到城市区域 S S S的无纹理三维网格,以及其中包含的各类资产 { S 1 , S 2 , . . . , S i } \{S_1,S_2,...,S_i\} {S1,S2,...,Si}。对于每一类资产,UrbanWorld将城市多模态大语言模型生成的对应文本描述 t i t_i ti或参考图像 r i r_i ri作为提示词,对生成过程进行控制。
首先,设置一系列相机视角 v i = { v i k } k = 1 N v_i=\{v_i^k\}_{k=1}^N vi={vik}k=1N,捕捉资产 S i S_i Si的多视角外观;随后,利用深度感知的控制网络(ControlNet)[30],控制二维扩散模型 F F F,在条件 c i ∈ { t i , r i , ( t i , r i ) } c_i \in \{t_i,r_i,(t_i,r_i)\} ci∈{ti,ri,(ti,ri)}的约束下,生成展示资产 S i S_i Si不同视角视觉外观的图像 I i I_i Ii,公式如下:
I i = F ( c i ; d i ; z ) I_i=F\left(c_i ; d_i ; z\right) Ii=F(ci;di;z)
其中, z z z为扩散过程的隐嵌入,不同视角的深度图 d i d_i di由绘制过程 d i = P ( S i , v i ) d_i=P(S_i, v_i) di=P(Si,vi)得到。
接着,将图像 I i I_i Ii裁剪为多个图像块,每个图像块对应绘制资产的一个独立视角 { I i k } k = 1 N \{I_i^k\}_{k=1}^N {Iik}k=1N;然后执行绘制的逆过程 P − 1 P^{-1} P−1,将图像 I i I_i Ii反投影至UV纹理空间,公式如下:
U i k = P − 1 ( v i k ; I i k ; S i ) U_i^k=P^{-1}\left(v_i^k ; I_i^k ; S_i\right) Uik=P−1(vik;Iik;Si)
随后,将不同视角的纹理图融合为单一纹理图 U i U_i Ui,公式如下:
U i = ∑ k = 1 n M i k ⊙ U i k U_i=\sum_{k=1}^n M_i^k \odot U_i^k Ui=k=1∑nMik⊙Uik
其中, M i k M_i^k Mik表示对应视角 v i v_i vi在UV空间中的掩码。
至此,可得到资产 S i S_i Si的初步纹理图,但实际应用中发现,由于相机视角的离散采样,物体表面仍会存在部分未绘制纹理的区域,对于多面资产而言该问题尤为突出。受扩散模型修复能力的启发,本文引入额外的UV纹理修复过程,以得到更完整、更自然的纹理效果。
但通用的基于扩散的修复方法无法直接实现该过程,因为该修复过程需要遵循UV纹理空间中的位置关系。因此,受通用三维物体修复过程[31]的启发,本文提出了一种由位置图引导的建筑UV纹理修复方法。
具体而言,添加UV位置图编码器 E V ( ⋅ ) E_V(\cdot) EV(⋅)对位置图 V i ∈ R H × W × 3 V_i \in \mathbb{R}^{H×W×3} Vi∈RH×W×3进行编码,该位置图标注了UV纹理片段的邻接关系,其中编码器 E V E_V EV的网络结构与扩散模型中的图像编码器保持一致。随后,为表面复杂的城市资产构建UV位置图与UV纹理图的配对数据集,并遵循控制网络(ControlNet)[30]的训练流程对位置编码器进行训练。在UV位置图的约束下,有望实现对UV纹理图的精准、自然修复。记 U i ∗ U_i^* Ui∗为修复后的UV纹理图,UV纹理修复过程的公式如下:
U i ∗ = F ( c i ; U i ; E V ( V i ) ) U_i^*=F\left(c_i ; U_i ; E_{V}\left(V_{i}\right) \right) Ui∗=F(ci;Ui;EV(Vi))
通过上述纹理生成和修复过程,UrbanWorld能够为各类城市要素生成协调统一、高保真的纹理。为提升绘制效果的视觉美感,本文进一步利用控制网络分块(ControlNet-tile)技术对图像进行超分处理,增强纹理图的结构锐度和真实度,使城市资产的外观更精细化、更贴近真实。
3.4 多模态大语言模型辅助的城市场景优化
完成城市资产绘制后,UrbanWorld会依据从城市布局元数据中提取的位置信息,自动对资产进行重组,精准还原原始的城市布局。受人类设计标准化工作流程的启发——设计师会对设计成果进行整体检视并开展迭代调整,UrbanWorld再次调用城市多模态大语言模型,对构建完成的三维城市环境进行全面检验,重点关注纹理细节。
具体而言,模型向城市多模态大语言模型输入提示词,使其识别生成结果与生成提示词之间的不一致性,最终由该模型给出精细化的优化建议,包括需要修改的要素和优化后的设计提示词。随后,3.3节所述的绘制模块将被激活,相关要素会在优化后的文本提示词约束下重新绘制,并更新至三维环境中。通过这一优化过程,UrbanWorld能够进一步让生成的城市环境贴合用户指令要求。本文在图3中展示了可视化案例,呈现了UrbanWorld运行过程中生成城市环境的演变过程,可见该模型通过迭代优化的方式构建高保真的城市环境,城市多模态大语言模型会自动识别低质量纹理并完成优化。
4 实验
本节首先介绍实验设置与实现细节(见4.1节),随后通过对生成城市环境的定量评估验证UrbanWorld的优越性(见4.2节),最后展示UrbanWorld的生成结果并完成定性分析(见4.3节)。
4.1 实现细节
UrbanWorld融合了三项核心技术:专业三维建模软件Blender、基于扩散的绘制技术,以及城市多模态大语言模型赋能的场景设计与优化技术。具体而言,本文采用Linux系统下的Blender-3.2.2版本,并搭配兼容的Blosm插件处理开放街道地图(OSM)数据的转换。在基于扩散的绘制方面,以稳定扩散模型1.5版本[32]为基础扩散骨干网络,生成三维资产多视角图像时结合深度感知的控制网络(ControlNet-Depth)[30],同时引入图像提示适配器(IP-Adapter)[33],支持将参考图像作为额外的生成条件。
紫外线(UV)纹理优化阶段采用修复型控制网络(ControlNet-inpainting)[30]作为扩散控制器,真实度增强阶段则使用分块型控制网络(ContrlNet-tile)[30]。绘制部分的超参数设置为:相机视角数量 N = 4 N=4 N=4,该数量基本能满足大多数城市资产的绘制需求;所有扩散过程的推理步数默认设为30;三维资产的紫外线(UV)图在Blender中以“智能投影”模式展开。所有实验均在单块英伟达特斯拉A100图形处理器(GPU)上完成。
4.2 定量评估
为充分验证UrbanWorld的优异生成性能,本节基于五项指标开展定量分析:弗雷歇初始距离(FID)、核初始距离(KID)、深度误差(DE)、同质性指数(HI)和偏好得分(PS)(详细定义见附录A.1)。
本文测试了UrbanWorld的两个版本:以文本提示词为生成条件的UrbanWorld(文本版),以及以参考图像为生成条件的UrbanWorld(图像版)。对比方法选取了城市场景生成领域的代表性模型,包括SGAM[22]、PersistentNature[14]、SceneDreamer[8]和Citydreamer[7],这些模型代表了三维城市环境自动生成的当前最优性能。未纳入CityGen[8]、CityCraft[17]和SceneCraft[16]等方法的实验结果,原因是其源代码尚未开源。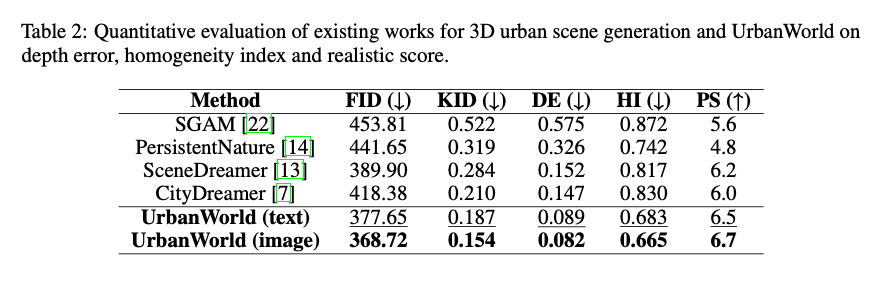
表2的实验结果表明,与基线模型相比,UrbanWorld在所有定量指标上均表现更优;以真实街景图像为生成条件的UrbanWorld,性能优于仅以文本为生成条件的版本。具体而言,与性能最接近的基线模型相比,UrbanWorld的弗雷歇初始距离(FID)和核初始距离(KID)分别提升5.4%和26.7%,说明其生成结果的真实度更高;深度误差(DE)指标提升44.2%,体现了UrbanWorld优异的几何特征保真性——而SceneDreamer、CityDreamer等绘制类方法虽能生成视觉效果良好的城市场景,却普遍存在几何特征不一致的问题。
在同质性指数(HI)方面,UrbanWorld相较基线模型提升10.4%。这与4.3节的定性结果观察一致:现有方法生成的场景同质性较高,风格受限于训练数据;而UrbanWorld能够根据用户指令生成多样化的城市环境,实现了定制化创建,可构建满足不同场景需求的各类三维城市环境。最后,GPT-4对UrbanWorld生成的城市环境给出了更高的偏好得分,其评分优于所有对比模型。
三项核心设计的有效性验证
为进一步验证UrbanWorld中三项核心设计的有效性,本文开展了消融实验,表3和表4分别展示了文本版和图像版UrbanWorld的消融实验结果。实验探究了三项设计对模型性能的影响:城市多模态大语言模型赋能的城市场景设计、纹理增强、多模态大语言模型辅助的场景优化。结果表明,这三项技术均对最终的生成性能有正向贡献。
具体而言,依托城市多模态大语言模型的丰富城市环境知识,其赋能的场景设计对生成城市环境的质量提升贡献最大;纹理修复与增强操作对深度误差(DE)指标的改善效果最为显著,原因是更高的纹理保真性有助于提升几何特征的感知精度;而最后的场景优化过程则使所有评估指标均得到提升,进一步优化了生成质量。
4.3 定性结果

本文在图4中展示了UrbanWorld以文本提示词为生成条件的生成结果,涵盖居民区、商业街区、公园三类典型的城市功能空间。为便于直观对比,同时展示了Infinicity[6]、CityGen[8]和CityDreamer[7]的生成样本(Infinicity和CityGen的结果取自其原论文,因二者源代码未开源)。
结果可见:Infinicity生成的场景纹理模糊,建筑结构细节缺失;CityGen生成的场景风格同质化严重,无明显的城市功能特征;CityDreamer生成环境中的城市要素(尤其是建筑)视觉外观缺乏多样性,难以区分,且建筑边界存在明显的几何畸变。这些问题会为主体与城市环境的实际交互带来极大阻碍,例如具身智能体因周边要素高度相似而难以完成城市导航训练。
相比之下,UrbanWorld生成的城市要素视觉多样性高,且可通过用户指令灵活调控。此外,本文还探索了以真实图像为提示词,利用UrbanWorld生成高真实度城市资产的效果,图5展示了以真实图像为引导生成的不同风格城市建筑,可见生成资产与真实资产高度贴合,这是现有方法难以实现的。
本文进一步拓展了模型的大规模城市环境生成能力,图6展示了四类典型的城市功能空间生成结果,每类空间均具备视觉协调统一、与场景语境高度适配的外观特征。这些结果充分体现了UrbanWorld的优异可调控性,该模型支持以多样化的提示词作为生成条件。
4.4 交互性验证
为验证UrbanWorld生成的三维城市环境的交互特性,本文开展案例研究,分析该模型如何为智能体提供信息反馈和具身活动空间。参考现有城市智能体相关研究[15,2],本文聚焦于智能体与城市环境的两种典型交互模式:感知与导航。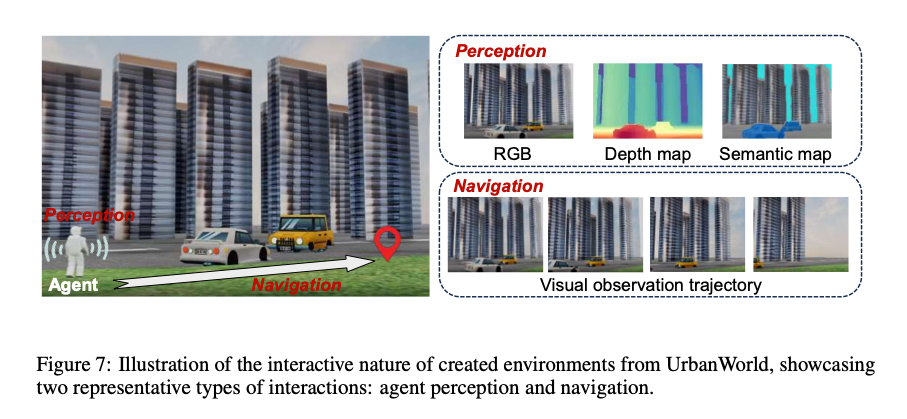
如图7所示,生成的城市环境能够为智能体提供多模态观测信息,包括红绿色蓝(RGB)图像、深度图和语义图,这类信息可增强智能体在各类复杂城市环境中的感知能力,助力其完成导航、物体操作等各类具身任务。本文还评估了智能体在生成城市环境中的导航能力,任务设定为:在三维环境中导航至指定的目标坐标。实验采用快速探索随机树(RRT)算法,结合智能体起始坐标、目标坐标和三维空间中的障碍物坐标完成路径规划,并记录了智能体导航过程中的视觉观测轨迹(见图7),验证了智能体与生成环境之间的有效交互。
5 结论
本文提出UrbanWorld,这是首个能够在灵活的控制条件下,以全自动方式创建高真实度、定制化且可交互的三维城市环境的生成式城市世界模型。该模型融合了城市多模态大语言模型对城市环境的卓越理解能力,以及扩散模型的可调控生成能力,能够高效构建高保真、定制化的城市环境,性能优于现有的三维城市生成方法。
在实际应用中,生成的城市环境可为具身智能和人工智能体的研发,提供高保真实数据和交互式环境。本文将UrbanWorld作为开源工具进行贡献,以期惠及广大研究领域,相信该模型将为高效构建三维城市世界开辟新途径,推动通用人工智能的发展。
附录
A.1 定量评估指标的详细说明
弗雷歇初始距离(FID)与核初始距离(KID):两项指标均用于量化生成图像与真实图像的分布相似度,数值越低表示生成结果的图像质量越好。本文计算了从生成场景中采样的帧,与从谷歌地图随机采样的1000张真实街景图像构成的评估集之间的FID和KID,这两项指标能有效衡量生成结果的真实度。
深度误差(DE):用于评估三维几何特征的精度,实现方式参考EG3D[34]和CityDreamer[7]。具体而言,采用预训练的深度估计模型[35],通过密度累积得到深度图的“真实值”;深度误差为归一化后的预测深度图与该“真实值”之间的L2距离,最终结果为生成城市场景的100帧采样结果的平均值。
同质性指数(HI):真实城市的特征是包含视觉外观多样化的复杂要素,这体现了不同城市区域的功能差异。为捕捉这一核心特征,本文提出对生成场景的同质性进行评估,主要衡量不同城市场景之间的方差。具体步骤为:首先利用残差网络(ResNet)[36]提取每张生成场景图像的视觉特征;再计算特征空间中任意两场景间的余弦相似度平均值,作为同质性指数。同质性指数数值越小,表明生成的城市环境多样性越高。
偏好得分(PS):利用性能优异的大语言模型作为评估器,是生成结果评估的常用方法[37,38]。本文向GPT-4输入提示词,使其对生成三维环境的采样快照进行评分,评分维度主要包括纹理精细度和几何完整性,分值范围为1-10分,得分越高表示生成结果的偏好度越高。
A.2 城市多模态大语言模型用于城市场景设计的定制提示词
城市场景生成提示词模板(图8)
cat_name = ['building ','path_roads ','forest ','vegetation ','water ','ground ']
user_prompts = "A modern residential area"
instruct_prompts = '''
You are an expert of urban scene design , now I want to generate a 3D urban scene of {}, composed of following kinds of assets (building ,
forest , vegetation , water , path_road , ground).
Can you design and generate a caption for each asset (give five types of
captions for the building) (each caption within 50 tokens), making the scene visually look harmonious and realistic. Only describe the appearance features (must including ‘color ‘, ‘material ‘ (such as patterns , roughness , metalness), functional use and ‘elements ‘ (must include detailed descriptions (color , position) of the windows , doors for buildings), and don’t give too much other
Please use a dictionary to represent the output result {} without number. ''' information. Ensure the texts capable to control text -to -image diffusion models like stable -diffusion v1.5.
des = ""
for i in range(len(cat_name)): des += f"{cat_name[i]}: [Description of {cat_name[i]}]" if i < len(cat_name) -1:
des += ", " des = "{" + des + "}"
new_prompts = instruct_prompts .format(user_prompts , des)
参考文献
[1] 张伟嘉、韩 Jindong、徐昭、倪航、刘浩、熊辉. 迈向城市通用智能:城市基础模型的综述与展望[J]. arXiv预印本, arXiv:2402.01749, 2024.
[2] 杨济菡、丁润宇、埃利斯·布朗、戚小娟、谢赛宁. 虚拟智能体的现实落地:V-IRL框架[J]. arXiv预印本, arXiv:2402.03310, 2024.
[3] 王汉清、陈家和、黄温思、贲庆伟、王泰、米博宇、黄涛、赵思衡、陈怡伦、杨 Sizhe 等. 通用机器人的规模化城市落地:Grutopia框架[J]. arXiv预印本, arXiv:2407.10943, 2024.
[4] 徐凤丽、张军、高晨、冯洁、李永. 城市生成智能(UGI):具身城市环境中智能体的基础平台[J]. arXiv预印本, arXiv:2312.11813, 2023.
[5] 扎希尔·阿拉姆、阿尤布·沙里菲、西蒙·埃利亚斯·比布里、戴维·西德尼·琼斯、约翰·克罗格斯特. 元宇宙:智慧城市的虚拟形态——城市未来在环境、经济和社会可持续发展中的机遇与挑战[J]. 智慧城市, 2022,5(3):771-801.
[6] 林洁 Hubert、李欣颖、威利·梅纳佩斯、柴梦蕾、亚历山大·西亚罗欣、杨明轩、谢尔盖·图利亚科夫. 无限尺度城市合成:Infinicity模型[C]. 《IEEE/CVF国际计算机视觉大会论文集》, 2023:22808-22818.
[7] 谢浩哲、陈昭熹、洪方舟、刘子微. 组合式无界三维城市生成模型:Citydreamer[C]. 《IEEE/CVF计算机视觉与模式识别大会论文集》, 2024:9666-9675.
[8] 邓杰、柴文浩、郭建树、黄启轩、胡文浩、黄建能、王高安. 无限且可调控的三维城市布局生成:CityGen模型[J]. arXiv预印本, arXiv:2312.01508, 2023.
[9] 卢帆、林君毅、徐彦、李洪升、陈光、蒋昌俊. 可调控的三维城市场景生成:基于布局先验的城市建筑师模型[J]. arXiv预印本, arXiv:2404.06780, 2024.
[10] 安东尼·胡、劳埃德·拉塞尔、哈德森·杨、扎克·穆雷兹、乔治·费多塞夫、亚历克斯·肯德尔、杰米·肖顿、詹卢卡·科拉多. 自动驾驶生成式世界模型:Gaia-1[J]. arXiv预印本, arXiv:2309.17080, 2023.
[11] 王孝锋、朱正、黄冠、陈新泽、陆继文. 面向现实驱动的自动驾驶世界模型:DriveDreamer[J]. arXiv预印本, arXiv:2309.09777, 2023.
[12] 何柳、丹尼尔·阿利亚加. 上下文敏感的城市级分层城市布局生成:Coho模型[J]. arXiv预印本, arXiv:2407.11294, 2024.
[13] 陈昭熹、王光聪、刘子微. 基于二维图像集的无界三维场景生成:SceneDreamer模型[J]. IEEE模式分析与机器智能汇刊, 2023.
[14] 露西·柴、理查德·塔克、李正祺、菲利普·伊索拉、诺亚·斯内夫利. 无界三维世界生成模型:PersistentNature[C]. 《IEEE/CVF计算机视觉与模式识别大会论文集》, 2023:20863-20874.
[15] 吴 Wayne、何红林、王怡然、段晨达、杰克·何、刘志正、李全一、周博磊. 城市空间具身人工智能仿真平台:MetaUrban[J]. arXiv预印本, arXiv:2407.08725, 2024.
[16] 胡子牛、艾哈迈德·伊斯琴、阿希·贾因、托马斯·基普夫、易松·岳、戴维·A·罗斯、科德利娅·施密德、阿里雷扎·法提. 基于Blender代码的三维场景合成:大语言模型智能体SceneCraft[C]. 《第四十一届国际机器学习大会论文集》, 2024.
[17] 邓杰、柴文浩、黄俊升、赵中涵、黄启轩、高明艳、郭建树、郝胜宇、胡文浩、黄建能等. 三维城市生成的实际构建工具:CityCraft[J]. arXiv预印本, arXiv:2406.04983, 2024.
[18] 井上直人、菊地耕太郎、埃德加·西莫-塞拉、大谷麻友、山口航太. 可调控布局生成的离散扩散模型:LayoutDM[C]. 《IEEE/CVF计算机视觉与模式识别大会论文集》, 2023:10167-10176.
[19] 吴振楠、李阳、闫涵、尚泰章、孙伟轩、王森博、崔瑞凯、刘伟哲、佐藤博之、李红东等. 基于隐式三平面外推的可扩展三维场景生成:Blockfusion模型[J]. arXiv预印本, arXiv:2401.17053, 2024.
[20] 周梦琦、侯俊、罗传琛、王玉溪、张兆祥、彭俊然. 基于大语言模型的过程化可调控大规模场景生成:SceneX[J]. arXiv预印本, arXiv:2403.15698, 2024.
[21] 杰克·布鲁斯、迈克尔·D·丹尼斯、阿什利·爱德华兹、杰克·帕克-霍尔德、石玉格、爱德华·休斯、马修·莱、阿迪蒂·马瓦兰卡尔、里奇·斯泰格沃尔德、克里斯·阿普斯等. 生成式交互式环境:Genie[C]. 《第四十一届国际机器学习大会论文集》, 2024.
[22] 沈元、马伟秋、沈龙. 同步生成与建图的三维虚拟世界构建:SGAM模型[J]. 神经信息处理系统进展, 2022,35:22090-22102.
[23] 泽维尔·普伊格、凯文·拉、马尔科·博本、李佳满、王廷武、桑娅·菲德勒、安东尼奥·托拉尔巴. 基于程序的家庭活动仿真:Virtualhome平台[C]. 《IEEE计算机视觉与模式识别大会论文集》, 2018:8494-8502.
[24] 夏飞、阿米尔·R·扎米尔、何志洋、亚历山大·萨克斯、吉滕德拉·马利克、西尔维奥·萨瓦雷塞. 面向具身智能体的现实世界感知:Gibson环境[C]. 《IEEE计算机视觉与模式识别大会论文集》, 2018:9068-9079.
[25] 埃里克·科尔夫、鲁兹贝·莫塔吉、温森·韩、伊莱·范德比尔特、卢卡·魏斯、阿尔瓦罗·埃拉斯蒂、马特·戴特克、基亚娜·埃赫萨尼、丹尼尔·戈登、朱玉科等. 面向视觉人工智能的交互式三维环境:AI2-THOR[J]. arXiv预印本, arXiv:1712.05474, 2017.
[26] 夏飞、威廉·B·沈、李成书、普里娅·卡西姆贝格、米卡埃尔·埃德蒙·查普米、亚历山大·托舍夫、罗伯托·马丁-马丁、西尔维奥·萨瓦雷塞. 杂乱环境中的交互式导航基准:交互式Gibson基准[J]. IEEE机器人与自动化快报, 2020,5(2):713-720.
[27] 甘创、杰里米·施瓦茨、塞思·奥尔特、达米安·姆罗卡、马丁·施林普夫、詹姆斯·特雷尔、朱利安·德·弗雷塔斯、乔纳斯·库比柳斯、阿布舍克·班德瓦达尔、尼克·哈伯等. 交互式多模态物理仿真平台:三维世界(Threedworld)[J]. arXiv预印本, arXiv:2007.04954, 2020.
[28] 王宇琦、何佳伟、范略、李红欣、陈运涛、张兆祥. 面向自动驾驶的多视角视觉预测与规划:基于世界模型的未来驾驶[C]. 《IEEE/CVF计算机视觉与模式识别大会论文集》, 2024:14749-14759.
[29] 林季、殷宏旭、平伟、帕夫洛·莫尔恰诺夫、穆罕默德·肖伊比、韩松. 视觉语言模型的预训练:VILA模型[C]. 《IEEE/CVF计算机视觉与模式识别大会论文集》, 2024:26689-26699.
[30] 张吕敏、饶安怡、马尼什·阿格拉瓦拉. 为文本到图像扩散模型添加条件控制:ControlNet[C]. 《IEEE/CVF国际计算机视觉大会论文集》, 2023:3836-3847.
[31] 曾宪芳、陈欣、戚中奇、刘文、赵淄博、王治斌、付彬、刘永、余刚. 无光照纹理扩散的三维任意物体绘制:Paint3D模型[C]. 《IEEE/CVF计算机视觉与模式识别大会论文集》, 2024:4252-4262.
[32] 罗宾·龙巴赫、安德烈亚斯·布拉特曼、多米尼克·洛伦茨、帕特里克·埃塞尔、比约恩·奥默. 基于隐式扩散模型的高分辨率图像合成[C]. 《IEEE/CVF计算机视觉与模式识别大会论文集》, 2022:10684-10695.
[33] 叶虎、张俊、刘思博、韩笑、杨威. 文本兼容的图像提示适配器:IP-Adapter[J]. arXiv预印本, arXiv:2308.06721, 2023.
[34] 埃里克·R·陈、康纳·Z·林、马修·A·陈、永野康纪、潘博晓、沙里尼·德·梅洛、奥拉齐奥·加洛、莱昂尼达斯·J·吉巴斯、乔纳森·特朗布莱、萨梅赫·哈米斯等. 高效的几何感知三维生成对抗网络[C]. 《IEEE/CVF计算机视觉与模式识别大会论文集》, 2022:16123-16133.
[35] 勒内·兰夫特、卡特琳·拉辛格、戴维·哈夫纳、康拉德·申德勒、弗拉季伦·科尔图恩. 迈向鲁棒的单目深度估计:跨数据集零样本迁移的混合数据集方法[J]. IEEE模式分析与机器智能汇刊, 2022,44(3):1623-1637.
[36] 何恺明、张祥雨、任少卿、孙剑. 用于图像识别的深度残差学习[C]. 《IEEE计算机视觉与模式识别大会论文集》, 2016:770-778.
[37] 王培毅、李蕾、陈亮、蔡泽帆、朱大伟、林炳怀、曹云波、刘淇、刘天宇、隋志芳. 大语言模型并非公平的评估器[J]. arXiv预印本, arXiv:2305.17926, 2023.
[38] 彭元、崔雨欣、唐浩淼、齐泽坤、董润培、白静、韩春瑞、葛铮、张祥雨、夏树涛. 面向个性化图像生成的人类对齐基准:Dreambench++[J]. arXiv预印本, arXiv:2406.16855, 2024.

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)