RISE: 基于组合式世界模型的自改进机器人策略
价值模型由预训练的VLA策略参数化,这带来两个优势:首先,预训练策略已在广泛的机器人数据集上训练,具有以机器人为中心的理解。在虚拟仿真器中,智能体可以并行执行大规模交互,状态和奖励的更新都是可控且可访问的。基于想象的策略改进关键依赖于一个与奖励相关的信号,该信号需要在较长的时间范围内具有稠密性,并且对接触丰富的操作中的细微故障非常敏感。在训练过程中,策略以优势信号为条件,该优势信号由学习的价值模型
1. 研究背景与动机
视觉-语言-动作(VLA)模型在机器人领域取得了显著进展,通过在大规模数据上预训练获得了广泛的语义理解和指令跟随能力。然而,这些模型在接触频繁且动态的操作任务中仍然表现脆弱。当机器人执行过程中出现轻微偏差时,这些偏差会累积并最终导致任务失败。
这一现象源于模仿学习的固有局限性:一旦机器人偏离专家演示的轨迹,它就缺乏纠正错误的恢复技能,无法自主调整回正确路径。
强化学习提供了一条通过试错来提升鲁棒性的原则性路径。在虚拟仿真器中,智能体可以并行执行大规模交互,状态和奖励的更新都是可控且可访问的。然而,这种可控性和并行性在现实世界中并不成立。预计3月开源:Github
物理世界的强化学习面临三大核心挑战:
- 安全风险:机器人在探索过程中可能损坏硬件或环境
- 硬件成本:需要大量机器人并行运行以获得足够的数据
- 环境重置:每次试验后需要人工监控和重置,串行执行耗时且劳动密集
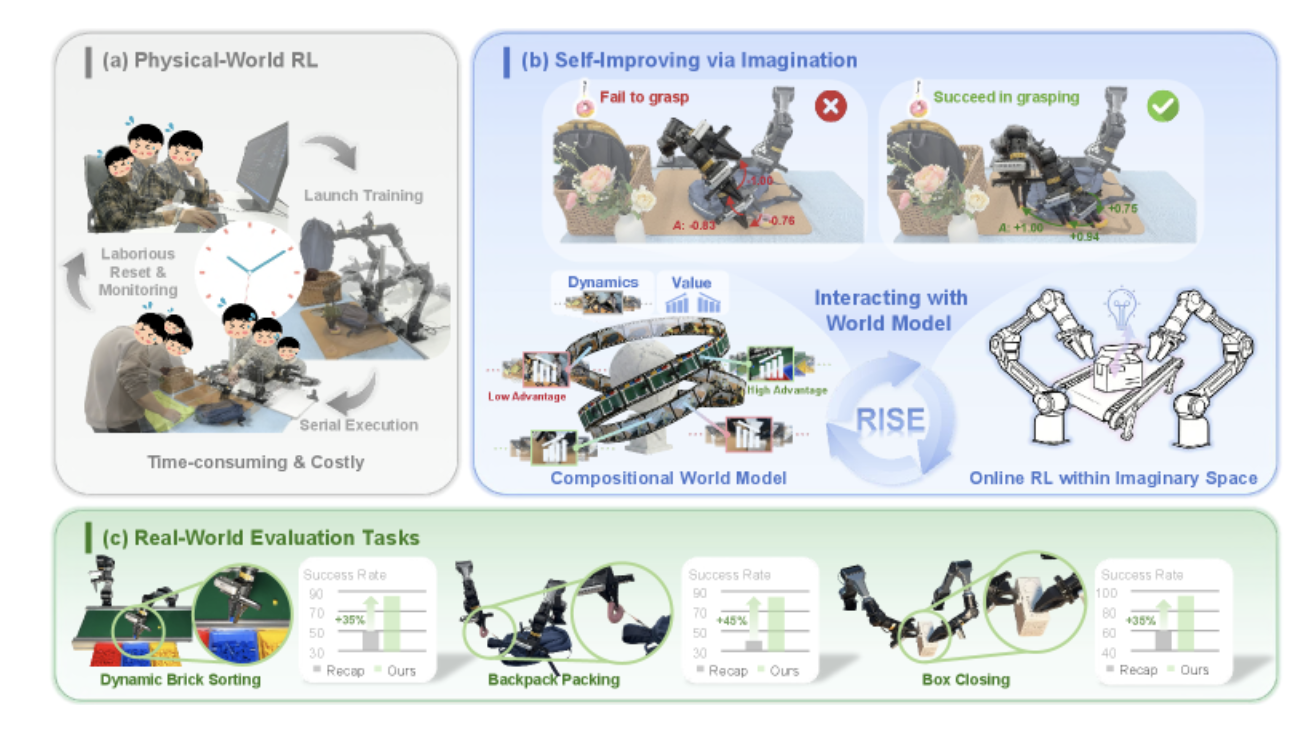
图1: 传统物理世界强化学习的瓶颈 vs RISE的解决方案
为了弥合仿真器与物理世界之间的差距,研究者们开发了世界模型。世界模型首先从被动经验中学习,然后模拟不同动作条件下的未来结果。然而,构建适用于现实世界机器人的世界模型面临两个根本性挑战。
第一个是可控性挑战:世界模型必须忠实地跟踪动作,以准确表示其后果。尽管通过集成高容量生成模型可以提高视觉真实感,但如何提高对各种动作的可控性仍然是一个开放性问题。
第二个是学习信号挑战:从想象中学习需要中间动作的信息性学习信号,而不是仅仅依赖于二元指标。否则,确定最终成功将需要世界模型模拟整个任务执行过程,这超出了大多数生成世界模型的可靠范围。
2. RISE核心创新:组合式世界模型
RISE提出了一个整体学习框架,通过想象力强化机器人基础模型以实现自改进。其核心创新在于将世界建模问题分解为两个独立但协同的目标:动力学预测和价值估计。
这种组合式设计允许每个组件使用最适合其角色的架构和训练目标,从而实现更高效的学习。动力学模型专注于预测未来的多视角观测,而价值模型则负责评估想象状态的质量。
2.1 动力学预测模型
动力学模型负责预测未来的多视角观测。RISE基于预训练的Genie Envisioner初始化动力学模型,该模型继承了LTX-Video的架构优势,在生成质量和推理速度之间实现了良好的平衡。
相比Cosmos等高级世界模型需要10分钟以上才能合成25个多视角观测,Genie Envisioner仅需不到2秒即可达到相同的视野范围,速度提升300倍。这种高效的生成能力是应用强化学习训练的关键支柱。
然而,GE-Base最初是基于文本而非细粒度的机器人动作进行训练的。为了赋予模型精确的动作控制能力,RISE通过引入轻量级动作编码器,在大规模动作标注数据集上对模型进行优化。
RISE采用任务中心批处理策略来提高动作可控性:每个批次仅从一小部分任务中采样,同时覆盖更多与不同动作相关的同一任务的样本。这种批处理策略在批次优化中优先考虑同一场景下的动作多样性,而非场景多样性。
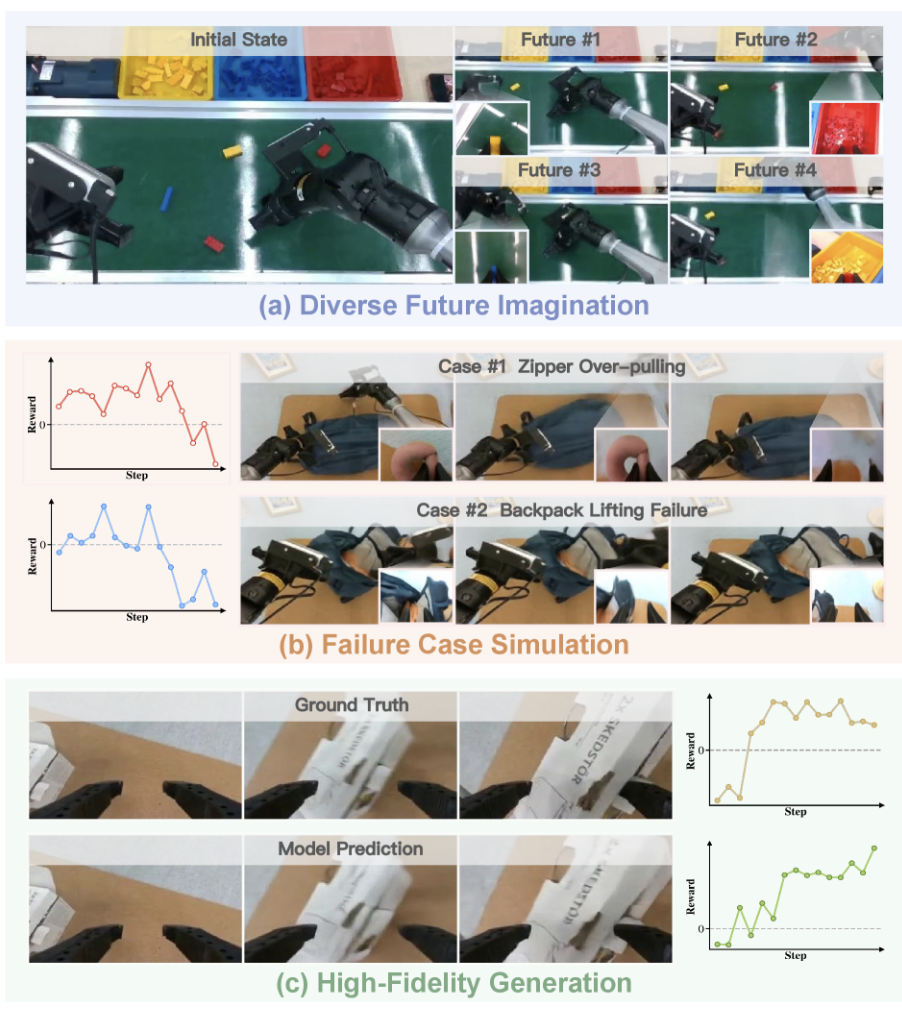
图2: 组合式世界模型的定性展示
2.2 价值估计模型
基于想象的策略改进关键依赖于一个与奖励相关的信号,该信号需要在较长的时间范围内具有稠密性,并且对接触丰富的操作中的细微故障非常敏感。
RISE学习一个价值估计器,将感官观测映射到标量值,用于对想象的展开进行评分。价值模型由预训练的VLA策略参数化,这带来两个优势:首先,预训练策略已在广泛的机器人数据集上训练,具有以机器人为中心的理解。
其次,该策略骨干与多视图输入兼容,而通用VLM大多只支持单视图。价值模型的训练采用双重目标函数:结合进度估计和时间差分学习。
进度回归能够提供密集的信号,但通常过于平滑且对失败不敏感。时间差分学习同时利用成功和失败的演示来建立价值函数,从而区分成功和错误。最终的价值学习目标函数简单地结合这两个项,分别利用学习稳定性和错误敏感性。
3. 闭环自改进管道
RISE的核心优势在于其闭环自改进管道,该管道持续生成想象的展开,估计优势,并在虚拟空间中更新策略,而无需昂贵的物理交互。整个流程分为三个阶段:策略预热、展开阶段和训练阶段。
3.1 策略预热阶段
在进行策略内改进之前,首先使用离线收集的数据对学习过程进行预热。这一阶段将策略锚定到目标任务上物理上合理的行为分布,从而避免在后续阶段进行盲目探索。
数据构成包括专家演示、策略成功和失败的部署以及人工干预的修正。在训练过程中,策略以优势信号为条件,该优势信号由学习的价值模型标记。
…详情请参照古月居

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)