RISE:基于组合世界模型的自改进机器人策略
26年2月来自港中文、Kinetix AI、港大、上海创新研究院、地平线机器人和清华的论文“RISE: Self-Improving Robot Policy with Compositional World Model”。尽管模型容量和数据采集能力持续扩展,视觉-语言-动作(VLA)模型在接触频繁且动态的操作任务中仍然脆弱,执行偏差可能累积导致失败。强化学习(RL)虽然提供了一条实现鲁棒性的原则
26年2月来自港中文、Kinetix AI、港大、上海创新研究院、地平线机器人和清华的论文“RISE: Self-Improving Robot Policy with Compositional World Model”。
尽管模型容量和数据采集能力持续扩展,视觉-语言-动作(VLA)模型在接触频繁且动态的操作任务中仍然脆弱,执行偏差可能累积导致失败。强化学习(RL)虽然提供了一条实现鲁棒性的原则性途径,但在物理世界中,基于策略的强化学习受到安全风险、硬件成本和环境重置的限制。为了弥合这一差距,本文提出RISE,一个基于想象的可扩展机器人强化学习框架。其核心是一个组合式世界模型,该模型(i)通过可控动力学模型预测多视角未来,以及(ii)使用进度价值模型评估想象的结果,从而为策略改进提供有用的信息优势。这种组合式设计允许根据最合适但又不同的架构和目标来定制状态和价值。这些组件集成到一个闭环自改进管道中,该管道持续生成想象的展开(rollout),估计优势,并在虚拟空间中更新策略,而无需昂贵的物理交互。在三个具有挑战性的现实世界任务中,RISE 比现有技术有显著的改进,动态砖块分拣的绝对性能提高 35% 以上,背包打包提高 45%,箱子封口提高 35%。
在诸如 LIBERO [60] 之类的虚拟仿真器中,智体可以并行执行大规模交互,状态和奖励的更新都是可控且可访问的。这些精心设计仿真器的特性启发了近期基于VLA的强化学习 (RL) 成功应用 [63, 56, 61]。然而,这种可控性和并行性在现实世界中并不成立。如图 (a) 所示,由于需要手动监控和重置,机器人的执行是串行的、耗时的且劳动密集型的。这些物理挑战在很大程度上限制以往现实世界强化学习方法只能使用离线数据,并且当前策略的数据分布会发生显著偏移 [85, 64, 65, 80]。最终,如果没有足够的策略内数据流,策略改进可能会受到瓶颈限制 [52, 90, 72]。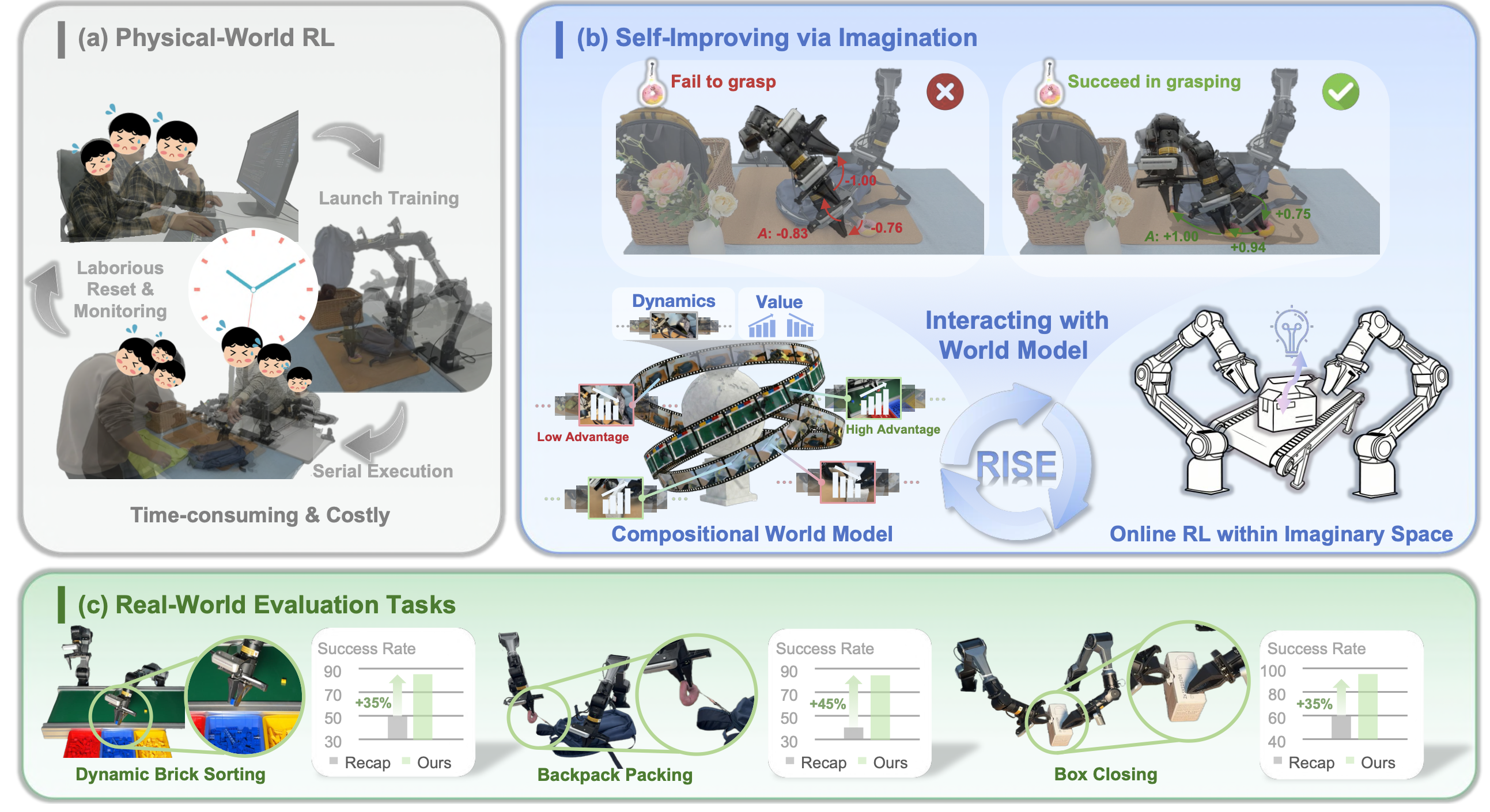
模拟器与物理世界之间的差距促使人们开发世界模型。世界模型首先从被动经验中学习,然后模拟不同动作条件下的未来结果[78, 27, 29, 30, 31, 50]。然而,构建适用于现实世界机器人的世界模型面临着根本性的挑战。为了实现控制,世界模型必须忠实地跟踪动作,以准确地表示其后果。尽管通过集成高容量生成模型可以提高视觉真实感[87, 26, 99],但如何提高对各种动作的可控性仍然是一个开放性问题[55]。此外,从想象中学习需要中间动作的信息性学习信号,而不是仅仅依赖于二元指标。否则,确定最终成功将需要世界模型模拟整个任务执行过程,这超出了大多数生成世界模型的可靠范围[55, 57]。
为了解决这些问题,提出RISE,一个整体学习框架,它通过想象力强化机器人基础模型以实现自改进,如上图(b)所示。其核心是一个基于学习世界模型的在线学习环境。受先前将世界建模分解为易于处理的子问题以灵活利用异构架构和先验知识的工作[5, 20, 97, 86]的启发,构建一个组合式世界模型,该模型将仿真问题分解为两个目标:动力学预测和价值估计,并允许每个目标使用最适合其角色的架构和训练目标进行实例化。如上图(c)所示:大规模富有想象力展开的训练,有效地提升 RISE 在各种复杂、接触丰富任务中的表现,使其在性能上超越现有技术,取得显著的进步。
组合式世界模型
可扩展的强化学习需要精确的环境建模,以便将当前状态和策略动作映射到未来的动态和奖励。为此,引入一种组合式世界模型,将动态预测与价值估计解耦,从而实现每个组件的独立架构优化。从上下文观察出发,动态模型在候选动作块下模拟一个忠实的未来,该未来将由价值模型进行评估,以获得策略改进的优势。如图所示定性地展示了一些示例。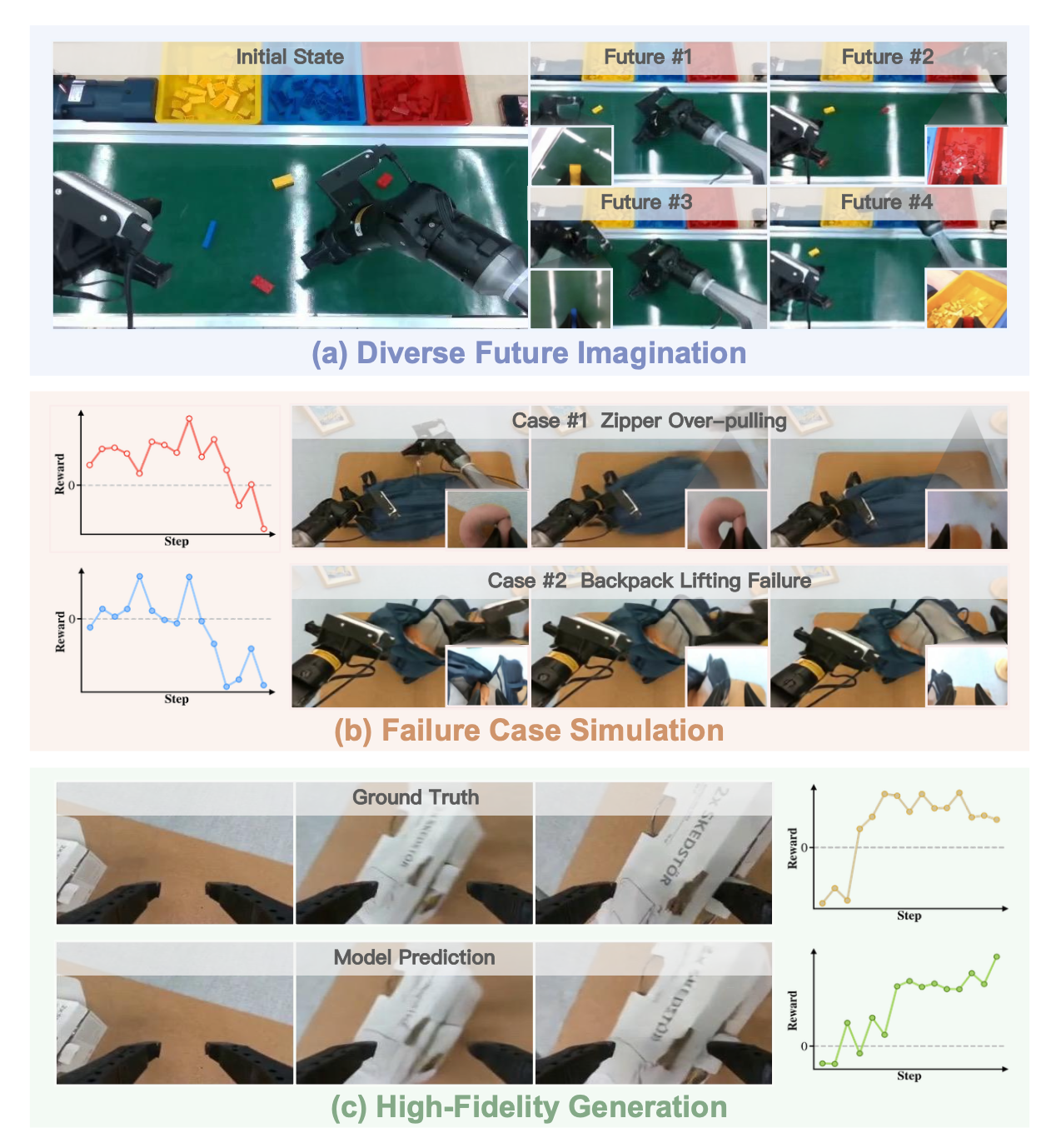
关键在于,该模型仅在训练期间使用,在推理阶段不会产生任何计算开销。如图所示展示世界模型的训练流程和推理流程。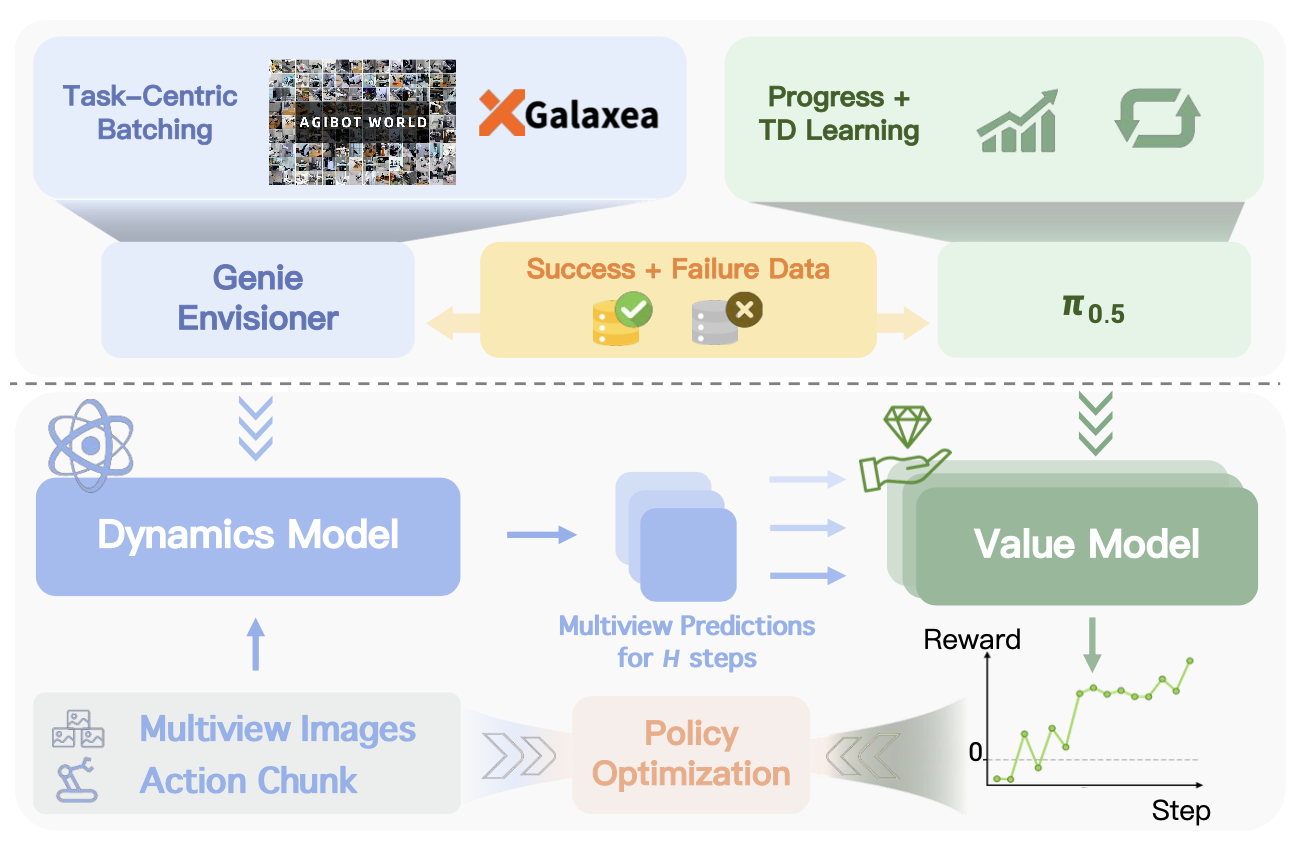
可控动态模型。可靠地模拟强化学习的未来状态有两个基本要求:(i)生成延迟不应过高,以免成为强化学习系统吞吐量的瓶颈。(ii)生成的状态不仅在视觉上合理,而且应与条件动作保持一致。因此,使用预训练的 Genie Envisioner [59](即 GE-base 变型)初始化动力学模型。该模型继承 LTX-Video [28] 的架构优势,并在生成质量和推理速度之间实现良好的平衡。相比之下,Cosmos [1] 等高级世界模型需要 10 分钟以上才能合成 25 个多视角观测数据,而 GE 仅需不到 2 秒即可达到相同的视野范围,速度提升 300 倍。这种高效的生成能力是应用强化学习训练的关键支柱。
尽管 GE-Base 效率很高,但它最初是基于文本而非细粒度的机器人动作进行训练的。为了赋予模型精确的动作控制能力,使其能够进一步迁移到特定任务场景中,通过引入一个额外的轻量级动作编码器,在大规模动作标注数据集(包括 Agibot World [11] 和 Galaxea [43])上对模型进行进一步优化。此外,与原始基于GE的训练相比,其对上下文帧施加更强的噪声,以提高生成鲁棒性,应对记录数据和合成数据中可能出现的运动模糊和视觉伪影。然而,当每次优化迭代的同一批次中包含不同的任务和视觉域时,在异构动作数据上微调可控世界模型容易出现不稳定和收敛缓慢的问题。采用以任务为中心的批处理策略来缓解这个问题,该策略中每个批次仅从一小部分任务中采样,同时覆盖更多与不同动作相关的同一任务的样本。直观地说,这种批处理策略在批次优化中优先考虑同一场景下的动作多样性,而非场景多样性,从而有助于提高动作的可控性。实验结果表明,应用该策略可以提高特定任务的微调效率和策略改进效果。通过这些设计选择,动力学模型能够提供快速且准确的多视图状态预测,从而支持自改进循环。
进展价值模型。基于想象的策略改进关键依赖于一个与奖励相关的信号,该信号 (i) 在较长的时间范围内具有稠密性,并且 (ii) 对接触丰富的操作中的细微故障非常敏感。因此,学习一个价值估计器 V,它将感官观测映射到一个标量值,用于对想象的展开进行评分。V 由预训练的 VLA 策略 π0.5 [8] 参数化,这带来两个优势。首先,π0.5 已在广泛的机器人数据集上训练,因此具有以机器人为中心的理解,可以自然地迁移到价值估计中。其次,该策略骨干与多视图输入兼容,而通用的 VLM 大多是在单视图图像上开发的,没有这种适应性。
在训练方面,首先使用简单的时间进度估计值 L_prog 对 V 进行热启动,该估计值作为目标函数,使价值模型能够粗略地理解单调时间结构。
虽然进度回归能够提供密集的信号,但它通常过于平滑,并且对失败不敏感,尤其是在交互频繁的场景中,执行错误在视觉上可能非常细微。为了克服这个问题,用时间差分 (TD) 学习 [77] 来增强进度损失,TD 学习同时利用成功的演示和失败的演示来建立一个价值函数 L_TD,从而区分成功和错误。
最终的价值学习目标函数 L_V = L_prog + L_TD 简单地结合这两个项,从而分别利用这两个项所提供的学习稳定性和错误敏感性。
基于真实世界经验的策略预热
在进行策略内改进之前,首先使用离线收集的数据对学习过程进行预热,将策略锚定到目标任务上物理上合理的行为分布,从而避免在后续阶段进行盲目探索。数据构成和训练目标主要遵循 RECAP [2]。对于每个任务,使用离线收集的数据(包括专家演示、策略成功和失败的部署以及人工干预的修正)对预训练策略(即 π0.5 [8])进行微调。在训练过程中,策略以优势信号为条件,该优势信号由学习的价值模型 V 标记,其中 oˆ_t+k 是离线录制视频中的后续帧。与 RECAP 中同时标记离线数据和策略部署的优势不同,同时标记这两个来源的优势比仅标记部署的优势效果更差。因此,在实验中,只有推广数据被赋予学习的优势,而专家数据和人工校正数据则直接与最优优势(记为1)配对。因此,这个预热阶段使策略能够吸收不同质量的动作数据,这对于下一个通过在线试错学习的自我改进阶段至关重要。
基于世界模型的自改进
利用从离线数据预热阶段获得的优势条件化能力,将组合世界模型作为交互式模拟器来改进策略。如图所示,自改进循环迭代地执行部署阶段和训练阶段。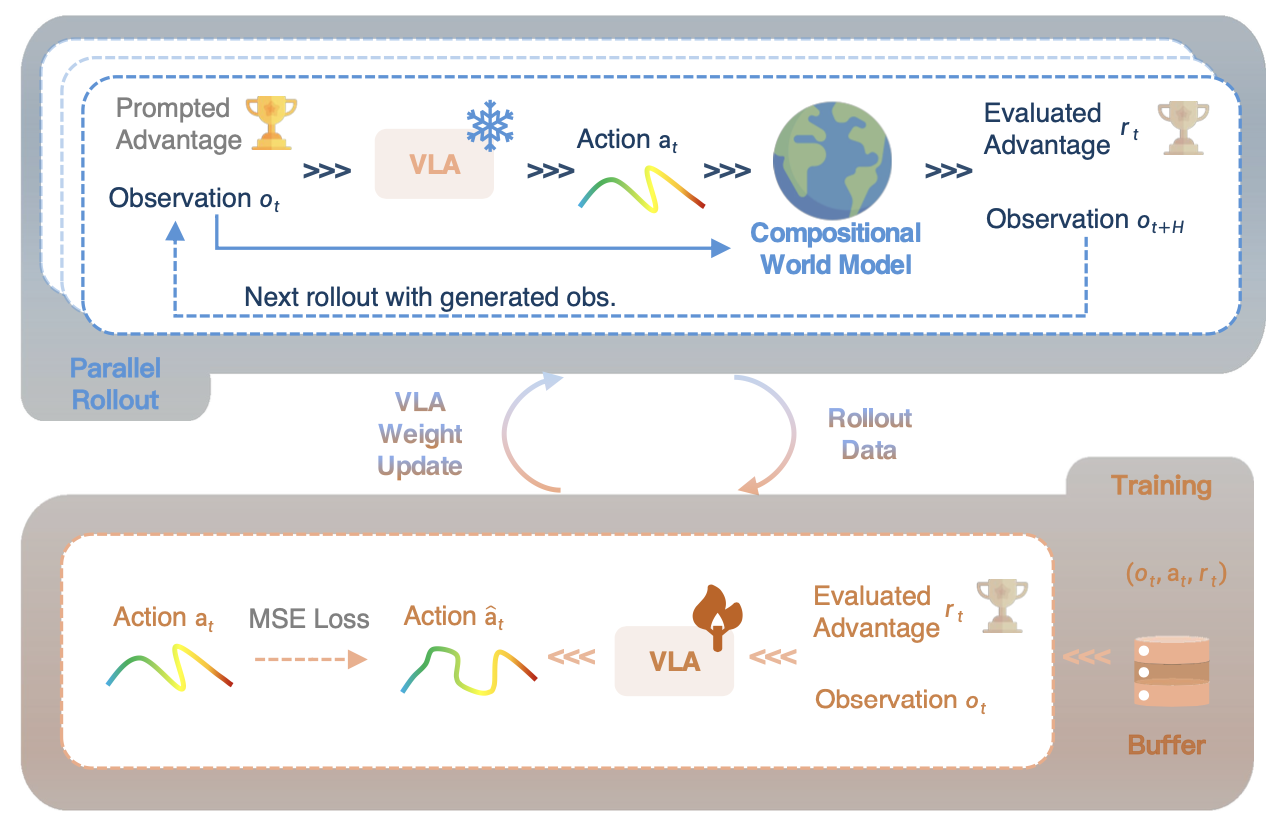
展开阶段。首先,从预热离线数据集中采样一个初始状态。同时,向展开策略 π_rollout 提供最优优势 1,以推断具有积极意图的动作:aˆ_t =π_rollout(1, o_t, l)。
视觉历史和动作提议被输入到动态模型中,以合成接下来的H个视觉状态。这些想象的状态随后由价值模型进行评估,以计算所提议动作的实际优势,记为Aπ_rollout(o_t, a_t, l)。将1定义为用于推断最优动作的提示优势,而Aπ_rollout(o_t, aˆ_t, l) 表示评估优势,反映生成动作的真实效用。该优势被离散化为N个均匀区间之一,代表动作在当前状态下的实际优势。为了在在线训练过程中扩大状态覆盖范围,想象的状态也将作为后续展开的输入。考虑到生成式视频模型已知的误差累积问题[38],对于每个离线状态,这种连续交互最多进行两次。展开策略参数通过指数移动平均(EMA)[40]进行更新,该EMA由行为策略权重混合而成。
RISE 与之前同样利用世界模型作为学习环境的方法 [44, 93, 13] 的一个主要区别在于,RISE 避免显式地模拟终止状态来获取奖励,而是直接为所提出的动作生成分块优势。训练阶段。策略内展开数据 ⟨o, aˆ, A⟩ 构成批次样本,用于优化策略。VLA 的训练目标是在给定评估优势 A 的条件下,最小化其输出与所提出动作 aˆ 之间的距离。这使得策略能够从想象中发现的高优势成功和低优势失败中学习。为了防止探索过程中出现灾难性遗忘,还将离线标注数据混合到批次数据中。离线和在线经验均在统一的学习目标下得到利用。
实现细节
世界模型训练。动力学模型分为两个阶段。预训练阶段在 Galaxea [43] 和 Agibot World [11] 数据集上进行,使用 16 个 NVIDIA H100 GPU,全局批大小为 512,耗时约 7 天。随后,针对特定任务进行微调,用 8 个 NVIDIA H100 GPU,全局批大小为 64,耗时约 3 天。该值模型基于预训练的 VLA [8] 进行参数化,并利用从策略骨干继承的以机器人为中心知识,直接在特定任务数据上进行微调。仅在前 1 万个训练步骤中使用进度估计损失,并在剩余的 4 万个步骤中额外添加 TD 学习损失。在 8 个 GPU 上,总批大小为 64,模型大约一天即可收敛。重要的是,世界模型的两个模块仅在策略学习阶段应用,因此在实际策略执行过程中不会产生任何推理开销。
策略训练。策略预热阶段基本遵循 RECAP [2] 在离线收集数据集上的训练流程,其中策略以学习的价值模型所标记的优势为条件。接下来的自改进阶段大约需要 1 万步。两个阶段的全局批大小均为 64,使用 8 个 GPU。
任务特定数据。世界模型和策略共享同一组离线数据集,包括专家演示和策略成功与失败的部署,但策略学习还会使用一部分 DAgger 数据来丰富恢复模式,类似于 RECAP [2]。
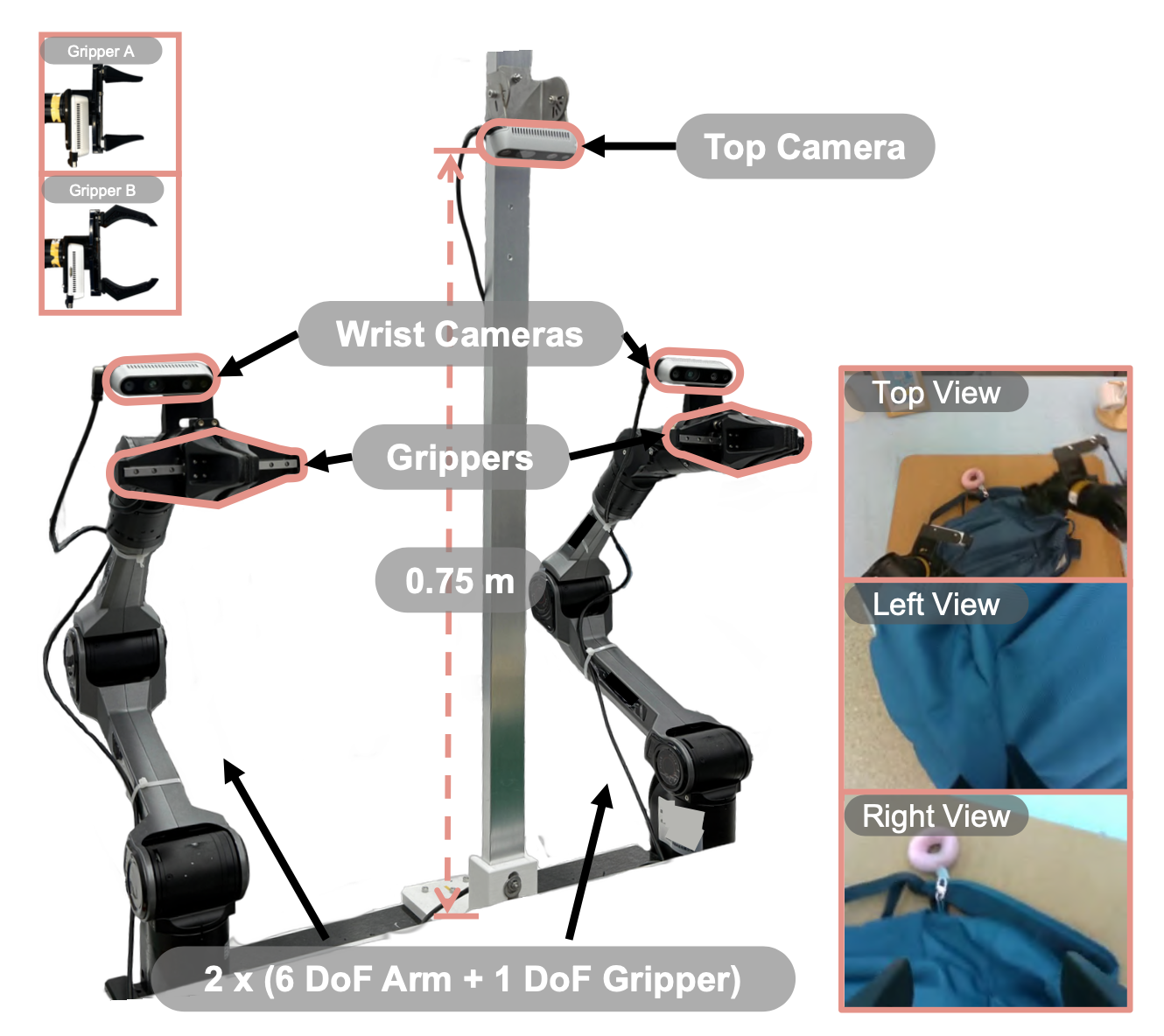
真实世界实验设置
真实世界实验采用一台配备绝对关节控制的双7自由度AgileX机器人。测试三项灵巧性强、持续时间长的长任务,包括:动态砖块分拣:机器人需要在运行的传送带上动态分拣各种砖块,如图(a)所示;背包打包:这项任务涉及柔性可变形物体的操作,如图(b)所示;纸箱封箱:这项任务需要精确的双手协调来包装杯子,如图©所示。值得注意的是,消融实验是在实践中最具挑战性的任务——动态砖块分拣上进行的。所有实验的超参数均保持不变。
实际部署
为了弥合 VLA 模型离散、低频推理与实际机器人控制连续、高频需求之间的差距,实现一个直接在关节空间运行的异步控制框架。具体来说,VLA 策略以相对较低的推理频率预测时域为 H = 50 步的动作块,而机器人控制器则以 30 Hz 的频率执行关节指令。为了避免推理过程中出现运动冻结,没有按顺序执行这些动作块,而是采用了一种时间集成策略,将新预测的动作块持续集成到正在运行的执行规划中。
这种集成由一个线性加权方案控制,该方案旨在平滑过渡并抑制高频抖动。当从推理线程接收到新的动作块 a_new 时,它会与缓冲区中现有动作序列 a_old 的未执行部分重叠。对于重叠窗口内的任意时间步 t 处(对应于下图中的双手动设置)最终执行的动作指令是通过在先前的规划 a_old 和新的预测 a_new 之间进行时变线性插值得到的。这确保了在更新开始时,机器人的轨迹主要由已建立的规划所引导保持连续性,同时逐渐将优先级转移到最新的传感器观测结果上。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 9
9 0
0- 0



 已为社区贡献211条内容
已为社区贡献211条内容

所有评论(0)