LangGraph 添加记忆:实现多轮对话的 AI 助手
## 前言
在开发 AI 聊天机器人时,一个常见的问题是:**如何让机器人记住之前的对话内容?**
想象一下,你告诉 AI "我叫张三",几秒钟后问 "我叫什么名字?",如果 AI 回答 "我不知道",那用户体验就太差了。这就是**记忆功能**的重要性。
本文将介绍如何在 LangGraph 中添加记忆功能,让你的 AI 助手能够记住多轮对话的上下文,实现真正的连续对话体验。
---
## 核心概念
### 1. Checkpointer(检查点)
Checkpointer 是 LangGraph 中实现状态持久化的核心机制。它负责:
- **保存状态**:在每个节点执行后自动保存当前状态
- **恢复状态**:根据配置加载之前保存的状态
- **管理会话**:通过 `thread_id` 区分不同的对话会话
### 2. Thread ID(会话 ID)
`thread_id` 是区分不同对话会话的标识符:
- 相同的 `thread_id` 共享同一份记忆
- 不同的 `thread_id` 之间记忆互不相通
- 可以实现多用户、多会话的场景
### 3. MemorySaver
`MemorySaver` 是 LangGraph 提供的一种内存检查点实现:
- 将状态保存在内存中(适合开发和测试)
- 生产环境可以使用 `SqliteSaver` 或 `PostgresSaver` 实现持久化存储
---
## 完整代码实现
```python
"""
LangGraph 教程 - 为聊天机器人添加记忆
本示例在基础聊天机器人的基础上,添加持久化检查点(checkpointer)实现多轮对话记忆。
通过 MemorySaver 和 thread_id,聊天机器人可以记住之前的交互上下文。
官方教程地址:https://langchain-ai.github.io/langgraph/tutorials/introduction/
"""
# 过滤警告信息
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore", category=UserWarning)
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import ToolMessage, AIMessage
from langchain_community.tools.tavily_search import TavilySearchResults
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.checkpoint.memory import MemorySaver
from dotenv import load_dotenv
import json
import os
# 加载环境变量
load_dotenv()
# 检查 Tavily API Key 是否设置
if not os.getenv("TAVILY_API_KEY"):
raise ValueError("TAVILY_API_KEY 未设置,请在 .env 文件中配置")
# ==================== 1. 定义状态 ====================
class State(TypedDict):
"""
定义图的状态结构。
messages: 消息列表,使用 add_messages reducer 函数
确保新消息追加到列表,而不是覆盖
"""
messages: Annotated[list, add_messages]
# ==================== 2. 创建图 ====================
def create_graph():
"""
创建并编译 StateGraph,添加 checkpointer 实现记忆功能。
Returns:
编译后的图对象
"""
# 创建图构建器
graph_builder = StateGraph(State)
# 初始化模型
llm = ChatOpenAI(
model="Qwen/Qwen3-Next-80B-A3B-Instruct",
openai_api_key=os.getenv("SILICONFLOW_API_KEY"),
openai_api_base="https://api.siliconflow.cn/v1",
temperature=0.7
)
# 创建 Tavily 搜索工具
tool = TavilySearchResults(max_results=2)
tools = [tool]
# 绑定工具到 LLM
llm_with_tools = llm.bind_tools(tools)
# 定义聊天机器人节点
def chatbot(state: State):
"""
聊天机器人节点。
Args:
state: 当前状态
Returns:
包含 LLM 响应的字典
"""
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 添加节点
graph_builder.add_node("chatbot", chatbot)
# 使用 LangGraph 预定义的 ToolNode(替代 BasicToolNode)
tool_node = ToolNode(tools=tools)
graph_builder.add_node("tools", tool_node)
# 添加边
graph_builder.add_edge(START, "chatbot")
# 添加条件边:从 chatbot 到 tools 或 END
# 使用 LangGraph 预定义的 tools_condition
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
# 添加边:从 tools 回到 chatbot(形成循环)
graph_builder.add_edge("tools", "chatbot")
# ==================== 关键:添加 MemorySaver 检查点 ====================
# 创建内存中的检查点(生产环境可使用 SqliteSaver 或 PostgresSaver)
memory = MemorySaver()
# 编译图时传入 checkpointer
return graph_builder.compile(checkpointer=memory)
# ==================== 3. 运行聊天机器人 ====================
def stream_graph_updates(graph, user_input: str, config: dict):
"""
流式处理图更新。
Args:
graph: 编译后的图对象
user_input: 用户输入的消息
config: 包含 thread_id 的配置字典
"""
# 注意:config 是第二个位置参数!
for event in graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config,
stream_mode="values"
):
if "messages" in event:
last_message = event["messages"][-1]
# 只打印 AI 消息(助手回复),不打印用户消息和工具消息
if isinstance(last_message, AIMessage) and last_message.content:
print("助手:", last_message.content)
def main():
"""主函数 - 运行交互式聊天机器人。"""
print("🤖 LangGraph 带记忆功能的聊天机器人已启动!")
print("=" * 50)
print("提示:")
print(" - 输入 'quit'、'exit' 或 'q' 退出对话")
print(" - 输入 'new' 开始新会话(切换 thread_id)")
print(" - 聊天机器人可以记住之前的对话内容\n")
# 创建图
graph = create_graph()
# ==================== 关键:使用 thread_id 配置 ====================
# 默认会话 ID
current_thread_id = "1"
config = {"configurable": {"thread_id": current_thread_id}}
print(f"当前会话 ID: {current_thread_id}")
print("-" * 50)
while True:
try:
# 获取用户输入
user_input = input("用户: ")
# 检查退出命令
if user_input.lower() in ["quit", "exit", "q"]:
print("\n👋 再见!")
break
# 检查是否切换会话
if user_input.lower() == "new":
current_thread_id = str(int(current_thread_id) + 1)
config = {"configurable": {"thread_id": current_thread_id}}
print(f"\n📝 已切换到新会话,会话 ID: {current_thread_id}")
print("-" * 50)
continue
# 检查当前状态(可选,用于调试)
if user_input.lower() == "state":
snapshot = graph.get_state(config)
print(f"\n📊 当前会话状态 (thread_id={current_thread_id}):")
print(f" 消息数量: {len(snapshot.values.get('messages', []))}")
print(f" 下一步: {snapshot.next}")
print("-" * 50)
continue
# 处理用户输入并获取响应
# 传入 config 使图能够加载和保存状态
stream_graph_updates(graph, user_input, config)
print() # 空行分隔对话
except KeyboardInterrupt:
print("\n\n👋 再见!")
break
except Exception as e:
print(f"发生错误: {e}")
break
# ==================== 4. 演示记忆功能 ====================
def demo_memory():
"""
演示记忆功能的示例函数。
展示同一个 thread_id 能记住上下文,不同 thread_id 无法共享记忆。
"""
print("🧪 演示记忆功能")
print("=" * 50)
graph = create_graph()
# 会话 1:建立记忆
print("\n【会话 1 - thread_id='1'】")
config_1 = {"configurable": {"thread_id": "1"}}
user_input = "你好,我叫张三"
print(f"用户: {user_input}")
for event in graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config_1,
stream_mode="values"
):
if "messages" in event:
last_message = event["messages"][-1]
# 只打印 AI 消息(助手回复)
if isinstance(last_message, AIMessage) and last_message.content:
print(f"助手: {last_message.content}")
# 会话 1:测试记忆
user_input = "我叫什么名字?"
print(f"\n用户: {user_input}")
for event in graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config_1,
stream_mode="values"
):
if "messages" in event:
last_message = event["messages"][-1]
# 只打印 AI 消息(助手回复)
if isinstance(last_message, AIMessage) and last_message.content:
print(f"助手: {last_message.content}")
# 会话 2:没有记忆
print("\n【会话 2 - thread_id='2'】")
config_2 = {"configurable": {"thread_id": "2"}}
user_input = "我叫什么名字?"
print(f"用户: {user_input}")
for event in graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config_2,
stream_mode="values"
):
if "messages" in event:
last_message = event["messages"][-1]
# 只打印 AI 消息(助手回复)
if isinstance(last_message, AIMessage) and last_message.content:
print(f"助手: {last_message.content}")
# 检查状态
print("\n【检查状态】")
snapshot = graph.get_state(config_1)
print(f"会话 1 的消息数量: {len(snapshot.values.get('messages', []))}")
snapshot = graph.get_state(config_2)
print(f"会话 2 的消息数量: {len(snapshot.values.get('messages', []))}")
if __name__ == "__main__":
# 运行交互式聊天机器人
# main()
# 如需运行演示,取消下面这行的注释:
demo_memory()
```
---
## 关键代码解析
### 1. 添加 MemorySaver
```python
from langgraph.checkpoint.memory import MemorySaver
# 创建内存中的检查点
memory = MemorySaver()
# 编译图时传入 checkpointer
return graph_builder.compile(checkpointer=memory)
```
**要点**:
- `MemorySaver` 将状态保存在内存中,程序结束后数据会丢失
- 生产环境建议使用 `SqliteSaver` 或 `PostgresSaver` 进行持久化
### 2. 配置 thread_id
```python
# 创建配置字典,包含 thread_id
config = {"configurable": {"thread_id": current_thread_id}}
# 调用图时传入 config
for event in graph.stream(
{"messages": [{"role": "user", "content": user_input}]},
config, # 第二个参数是 config
stream_mode="values"
):
# 处理事件...
```
**要点**:
- `config` 是 `stream()` 方法的**第二个位置参数**,不是关键字参数
- 相同的 `thread_id` 会自动加载之前保存的状态
### 3. 检查当前状态
```python
# 获取指定 config 的状态快照
snapshot = graph.get_state(config)
# 查看消息数量
print(f"消息数量: {len(snapshot.values.get('messages', []))}")
# 查看下一步要执行的节点
print(f"下一步: {snapshot.next}")
```
---
## 运行效果
运行 `demo_memory()` 函数,你会看到以下输出:
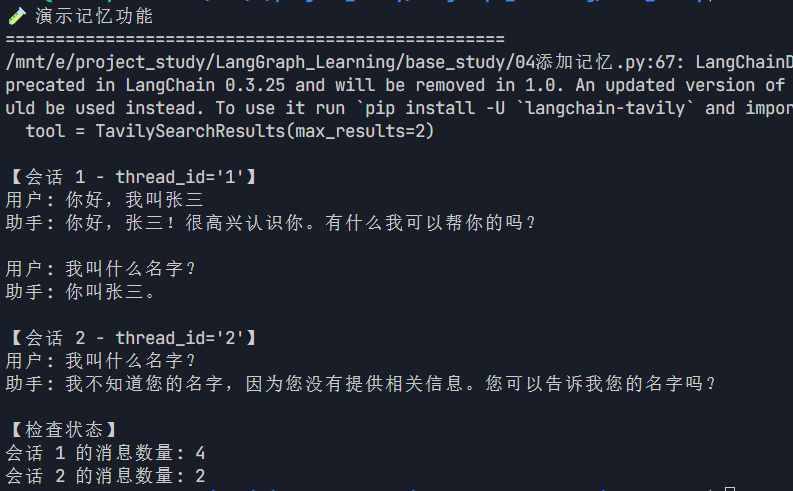
**结果分析**:
- 会话 1 中,AI 记住了用户叫"张三"
- 会话 2 中,AI 无法获取会话 1 的信息,因为 `thread_id` 不同
- 会话 1 有 4 条消息(2 轮对话,每轮包含用户和 AI 各一条)
- 会话 2 只有 2 条消息(1 轮对话)
---
## 踩坑记录
### stream_mode="values" 返回所有消息类型
在使用 `stream_mode="values"` 时,事件中的 `messages` 列表包含**所有类型的消息**:
- `HumanMessage`:用户输入
- `AIMessage`:AI 回复
- `ToolMessage`:工具执行结果
**问题**:直接打印 `last_message` 可能会输出工具消息的内容,这不是我们想要的效果。
**解决方案**:
```python
last_message = event["messages"][-1]
# 只打印 AI 消息(助手回复),不打印用户消息和工具消息
if isinstance(last_message, AIMessage) and last_message.content:
print("助手:", last_message.content)
```
通过 `isinstance(last_message, AIMessage)` 过滤,只显示 AI 的回复内容。
---
## 总结
本文介绍了如何在 LangGraph 中添加记忆功能:
| 要点 | 说明 |
|------|------|
| **Checkpointer** | 使用 `MemorySaver` 实现状态持久化 |
| **Thread ID** | 通过 `thread_id` 区分不同会话 |
| **Config 参数** | `stream()` 的第二个位置参数传入配置 |
| **状态检查** | 使用 `graph.get_state(config)` 查看当前状态 |
### 扩展建议
1. **持久化存储**:生产环境使用 `SqliteSaver` 或 `PostgresSaver` 替代 `MemorySaver`
2. **消息历史管理**:可以实现消息数量限制,防止上下文过长
3. **多用户支持**:将 `thread_id` 与用户 ID 关联,实现真正的多用户对话
---
**参考链接**:
- LangGraph 官方教程:https://langchain-ai.github.io/langgraph/tutorials/introduction/
- LangGraph 文档:https://langchain-ai.github.io/langgraph/
---
*本文作者:码上AI_123*
*转载请注明出处,谢谢!*

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)