【legged_gym学习】legged_robot.py部分解读五(课程学习与动态干预 Curriculum & Dynamic Interventions)
在上一篇文章中,我们打通了从神经网络到物理引擎的“任督二脉”,让机器人拥有了执行动作的能力。但训练一个复杂的强化学习策略往往面临一个巨大的悖论:如果环境太简单,机器人学不到真本事;如果环境太复杂,机器人由于初期总是失败,根本收集不到有效的正向奖励,最终什么也学不会。课程学习与域随机化(动态篇),就是一套为机器人量身定制的“打怪升级”系统。我们将深入探讨等核心函数,看看 AI 是如何一步一个脚印征服
前言
在上一篇文章中,我们打通了从神经网络到物理引擎的“任督二脉”,让机器人拥有了执行动作的能力。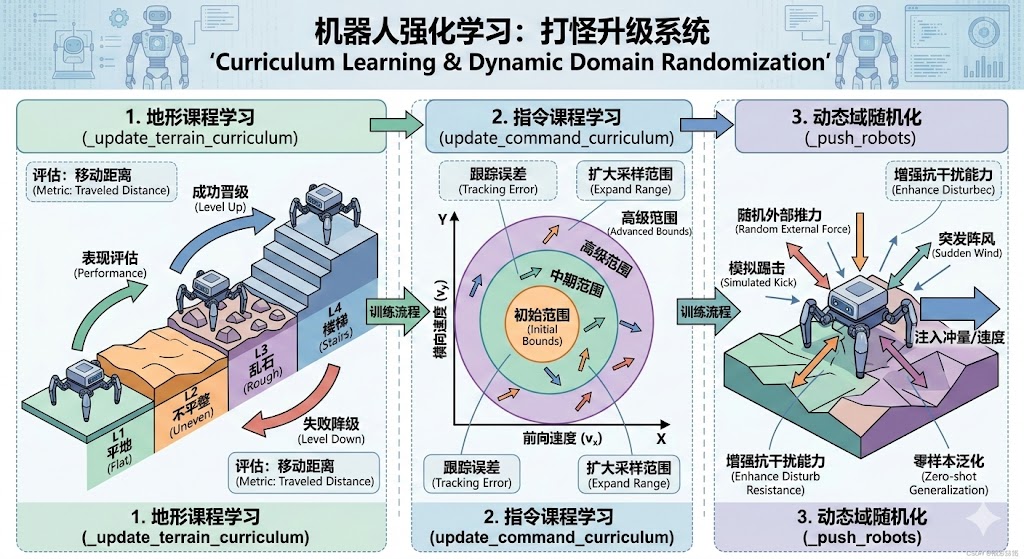
但训练一个复杂的强化学习策略往往面临一个巨大的悖论:如果环境太简单,机器人学不到真本事;如果环境太复杂,机器人由于初期总是失败,根本收集不到有效的正向奖励,最终什么也学不会。
今天,我们要解析的第四部分:课程学习与域随机化(动态篇),就是一套为机器人量身定制的“打怪升级”系统。我们将深入探讨 _update_terrain_curriculum、update_command_curriculum 等核心函数,看看 AI 是如何一步一个脚印征服复杂世界的。
1. 地形的“段位系统”:_update_terrain_curriculum(env_ids)
想象一下,你正在训练一台多足(例如六足)机器人。你希望它能爬楼梯、过乱石堆。直接把它扔进乱石堆,它只会疯狂摔倒。地形课程学习 (Terrain Curriculum) 的核心思想就是:根据机器人的当前能力,动态分配适合它的地形难度。
在 Isaac Gym 的地形生成中,地形通常被划分为一个矩阵(网格)。行代表地形类型(平地、斜坡、楼梯等),列代表难度级别(坡度大小、台阶高度等)。
核心升级/降级逻辑:
每次机器人触发 reset(比如摔倒或超时)时,环境会调用此函数评估它的表现:
-
评估指标: 通常计算机器人在当前回合(Episode)中沿着目标方向移动的距离。
-
晋级 (Level Up): 如果移动距离超过了设定的阈值(比如走完了当前地形长度的 80%),说明当前难度对它来说太简单了,将其环境配置中的
terrain_level加一,下一回合它将出生在更难的地形上。 -
降级 (Level Down): 如果机器人刚走两步就摔倒了(移动距离小于地形长度的 10%),说明当前难度超纲了,将其
terrain_level减一,退回上一关重新练习。
这种机制保证了机器人的训练始终处于其能力的“最近发展区”,极大地提升了训练效率和最终的收敛效果。
def _update_terrain_curriculum(self, env_ids):
""" Implements the game-inspired curriculum.
Args:
env_ids (List[int]): ids of environments being reset
"""
# Implement Terrain curriculum
if not self.init_done:# 如果初始化尚未完成,则不进行地形课程更新
# don't change on initial reset
return
distance = torch.norm(self.root_states[env_ids, :2] - self.env_origins[env_ids, :2], dim=1) # 计算机器人当前位置与环境原点之间的距离
# robots that walked far enough progress to harder terains
move_up = distance > self.terrain.env_length / 2# 如果机器人走过的距离超过环境长度的一半,则标记为需要提升地形难度
# robots that walked less than half of their required distance go to simpler terrains
move_down = (distance < torch.norm(self.commands[env_ids, :2], dim=1)*self.max_episode_length_s*0.5) * ~move_up# 如果机器人走过的距离少于其所需距离的一半,则标记为需要降低地形难度
self.terrain_levels[env_ids] += 1 * move_up - 1 * move_down# 根据需要提升或降低地形难度的标记,更新环境的地形难度等级(增加1或减少1)
# Robots that solve the last level are sent to a random one
self.terrain_levels[env_ids] = torch.where(self.terrain_levels[env_ids]>=self.max_terrain_level,# 如果地形难度等级超过最大值,则随机分配一个新的地形难度等级
torch.randint_like(self.terrain_levels[env_ids], self.max_terrain_level),# 随机生成一个新的地形难度等级
torch.clip(self.terrain_levels[env_ids], 0)) # (the minumum level is zero)
self.env_origins[env_ids] = self.terrain_origins[self.terrain_levels[env_ids], self.terrain_types[env_ids]]# 更新环境原点位置2. 指令的“渐进式施压”:update_command_curriculum(env_ids)
除了地形难度,机器人还需要学会听从人类的遥控指令。指令通常包含三个维度的目标速度:前向线速度 vx、横向线速度 vy 以及偏航角速度 ωz。
指令课程学习 (Command Curriculum) 的作用是:在机器人刚开始学走路时,只给它下达非常小、非常容易实现的速度指令;等它走稳了,再逐渐扩大指令的采样范围。
实现机制:
-
计算跟踪误差: 系统会持续监控机器人实际速度与指令速度的误差。
-
扩大舒适区: 如果机器人在一段时间内对当前指令范围的跟踪误差小于某个阈值(例如连续成功跟踪了目标速度),函数就会动态扩大指令的上下限配置(
command_bounds)。 -
重新采样
_resample_commands(env_ids): 当机器人重置或达到指令刷新时间点时,调用该函数,在当前阶段的指令范围(Bounds)内,使用均匀分布重新采样一组新的 (vx,vy,ωz) 作为下一步的追踪目标。
def update_command_curriculum(self, env_ids):
""" Implements a curriculum of increasing commands
Args:
env_ids (List[int]): ids of environments being reset
"""
# If the tracking reward is above 80% of the maximum, increase the range of commands
if torch.mean(self.episode_sums["tracking_lin_vel"][env_ids]) / self.max_episode_length > 0.8 * self.reward_scales["tracking_lin_vel"]:# 如果线速度跟踪奖励的平均值超过最大值的80%,则增加命令范围
self.command_ranges["lin_vel_x"][0] = np.clip(self.command_ranges["lin_vel_x"][0] - 0.5, -self.cfg.commands.max_curriculum, 0.) # 将线速度命令范围的下限减少0.5
self.command_ranges["lin_vel_x"][1] = np.clip(self.command_ranges["lin_vel_x"][1] + 0.5, 0., self.cfg.commands.max_curriculum) # 将线速度命令范围的上限增加0.53. 现实世界的“突发测验”:_push_robots()
我们在第三篇中提到了静态的域随机化(如改变摩擦力、质量)。而 _push_robots 则是动态域随机化的代表,它模拟的是现实世界中突如其来的外力干扰。
现实环境是不完美的。机器人可能会遇到一阵横风,或者被人不小心踢了一脚。如果仿真里没有经过这种训练,机器人一旦受到扰动就会立刻失去平衡。
底层逻辑:
-
触发频率: 这个函数通常在物理步进的回调中定期触发(例如每隔 10 到 15 秒)。
-
施加外力: 系统会为所有存活的机器人生成一个随机大小的 2D 速度向量 (Δvx,Δvy)。
-
状态注入: 直接修改 Isaac Gym 底层根节点状态张量(Root State Tensor)中的线速度部分。这相当于在物理引擎中瞬间给了机器人质心一个极大的冲量。
通过这种“随机推搡”,策略网络被迫学会在身体发生剧烈偏移时,迅速调整各个关节的力矩来恢复平衡,从而获得了极其强大的零样本(Zero-shot)抗干扰能力。
def _push_robots(self):
""" Random pushes the robots. Emulates an impulse by setting a randomized base velocity.
"""
max_vel = self.cfg.domain_rand.max_push_vel_xy #计算最大推力对应的速度值
self.root_states[:, 7:9] = torch_rand_float(-max_vel, max_vel, (self.num_envs, 2), device=self.device) # lin vel x/y
self.gym.set_actor_root_state_tensor(self.sim, gymtorch.unwrap_tensor(self.root_states))# 设置所有环境中机器人的根节点状态,应用随机推力总结
如果说物理控制是机器人的“肌肉”,那么课程学习与动态干预就是机器人的“教练”。
-
_update_terrain_curriculum和update_command_curriculum负责循序渐进地引导,防止机器人“摆烂”。 -
_resample_commands保证了指令的多样性。 -
_push_robots则是一位严厉的考官,随时进行抗击打测试。
在这些机制的协同作用下,机器人最终能够蜕变成一个既能飞檐走壁,又能抗风抗踢的“六边形战士”。
下一篇,我们将迎来整个框架中最核心、也是调参最让人头疼的部分:第五部分——奖励函数数组 (Reward Functions),也就是我们要如何手把手教 AI 区分“好”与“坏”。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)