Hello Data:具身智能,迎来数据驱动的新原点
摘要:人形机器人发展正经历从"算法驱动"到"数据驱动"的范式转变,高质量交互数据成为智能进化的关键。行业探索出四条技术路径:仿真合成数据、遥控操作、人类视频学习和无本体采集(如UMI技术),共同构建完整的数据供应链。诠视科技(Xvisio)的感知解决方案通过硬件预处理、多源融合、智能压缩等技术,为机器人训练提供高效精准的"数据流",解决从

如果说,在终端屏幕上打印出“Hello World”是一个程序员的成人礼,那么,为人形机器人注入第一组高质量、可泛化的交互数据,就是其具身智能的“启蒙时刻”。这个时刻,我们可以称之为——“Hello Data”。它标志着一个新时代的原点:智能的起点,从代码行移向了数据流。
人形机器人的开发,已历经从“传统编程”到“算法驱动”,并正迈向“数据驱动”的深刻转变。
早期基于规则的编程(范式1.0),在面对真实世界无限的复杂性与不确定性时,其代码复杂度和维护成本会急剧上升,难以赋予机器人真正的心智。这推动了以机器学习为核心的算法驱动(范式2.0)成为主流,人们期望算法能从数据中自动归纳出策略。然而,实践很快揭示了一个更根本的真理:任何先进算法的性能上限,几乎完全由其训练数据的质量与规模决定。缺乏高质量的交互数据,算法的潜力便无从释放。于是,行业的竞争焦点发生了决定性转移——从“设计更聪明的算法”,转向 “如何规模化地获取与精炼驱动智能的数据”。我们正式进入了数据驱动(范式3.0) 的新阶段。
为实现数据驱动的目标,行业主要探索出四条技术路径,它们各具优势,共同构成了从虚拟到真实、从低维到高维的完整数据光谱:
仿真合成数据
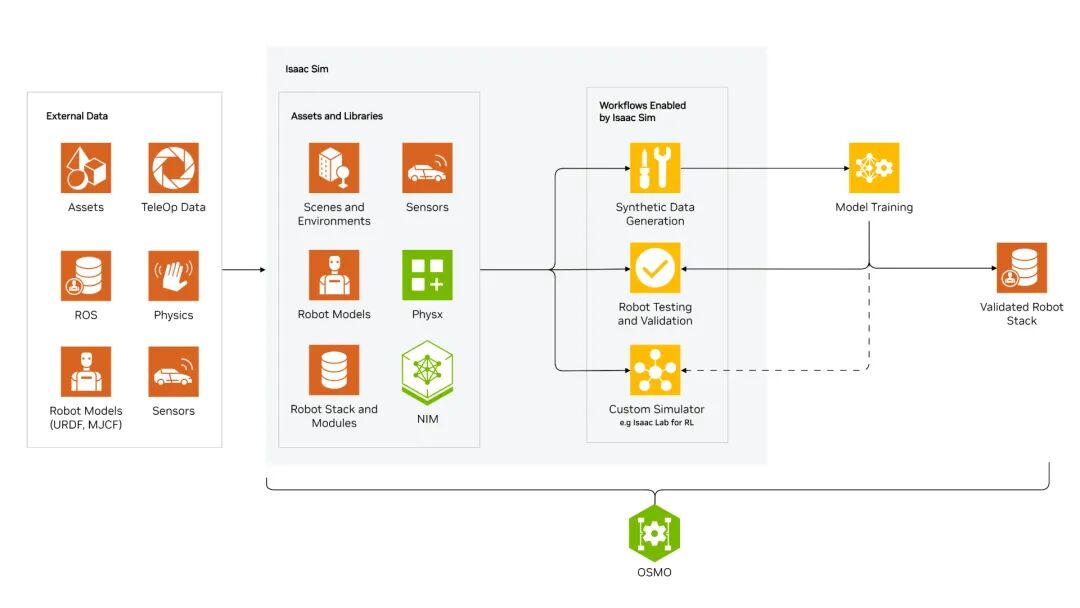
Isaac Sim 的工作原理,图片来源于NVDIA官方网站
在Isaac Sim、MuJoCo等虚拟环境中生成带完美标签的数据,成本极低且可无限生成,是算法前期验证与大规模预训练的基石。然而,其核心挑战在于难以弥合的 “仿真到现实差距” ,虚拟策略在真实世界往往表现不佳。
遥控操作真机

由人类专家通过手柄或VR设备直接操控真实机器人执行任务,例如Boston Dynamics展示的复杂动作编排。其产生的数据是保真度最高的“黄金标准”,但受限于极高的硬件成本、损耗风险与时间投入,难以复制规模化采集。
人类视频学习
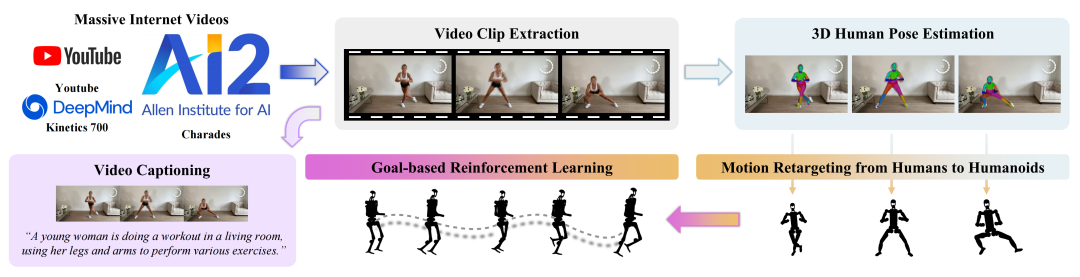
图片来源:Universal Humanoid Robot Pose Learning from Internet Human Videos
从Ego4D等互联网海量人类活动视频中学习视觉常识与技能经验。这类数据规模庞大,蕴含丰富的世界知识,但存在根本性缺失:视频中不包含精确的机器人力觉、本体感知与控制信号,难以直接转化为可执行的控制策略。
无本体采集
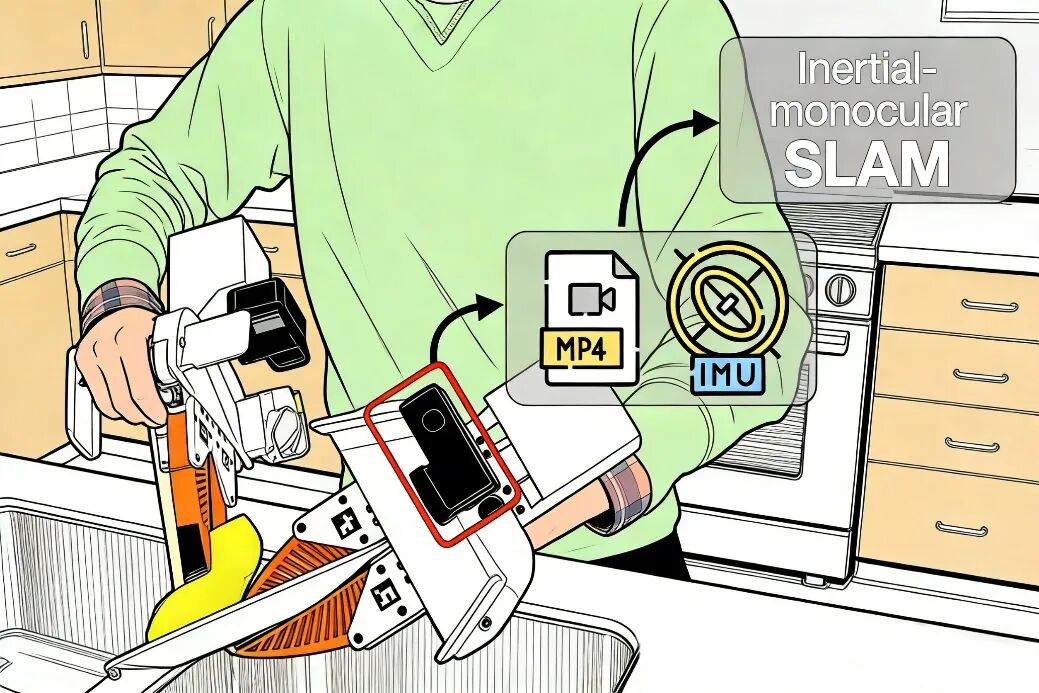
以 “UMI(通用操作接口)” 为代表的前沿范式,其核心突破在于 “解耦” :人类手持集成视觉与惯性传感器的轻便工具演示技能,系统同步记录运动轨迹与视觉场景,再将此数据映射至不同的机器人本体进行学习。这一范式由UC Berkeley等机构在2022年的《Universal Manipulation Interface》论文中明确提出,旨在以远低于遥操作的成本,规模化采集真实的物理交互数据,从而填补仿真预训练与真机微调之间的关键空白。
仿真、遥操作、视频学习与UMI这四条路径并非彼此替代,而是构成一个从‘低成本试错’到‘高保真精炼’的完整数据供应链。它清晰地表明:机器人性能的飞跃,高度依赖于高质量的训练数据与高效的学习框架。 而在整个流程的起点——数据采集环节,高精度、低延迟的感知技术扮演着无可替代的角色。
热潮背后的冷思考:
数据是燃料,感知是入口
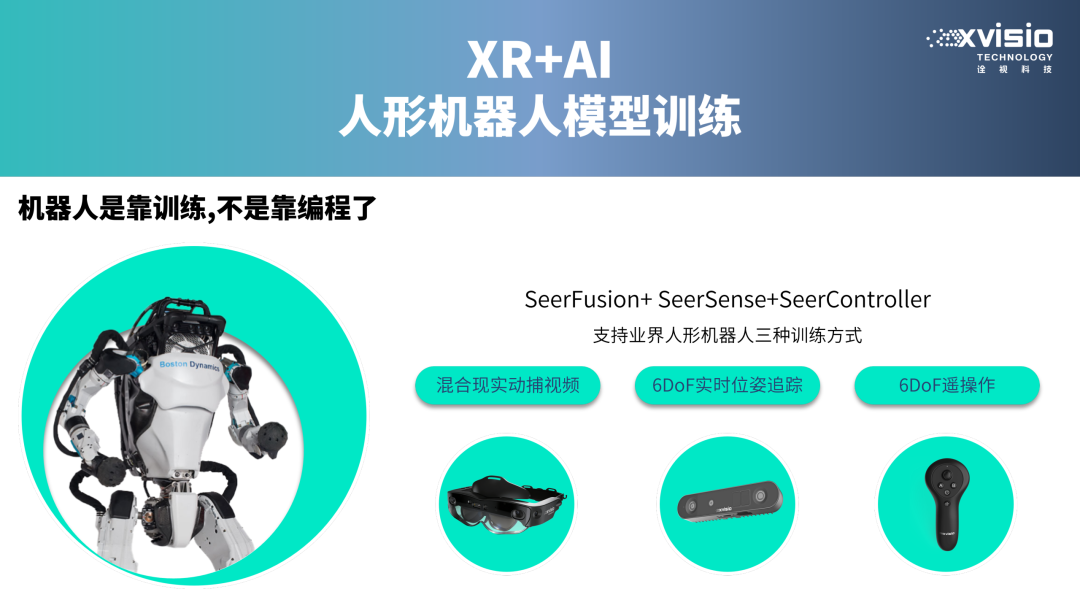
作为专注于空间计算与三维感知的解决方案提供商,诠视科技(Xvisio Technology)深知感知层在机器人进化中的关键意义。旗下SeerFusion,SeerSense,SeerController等多系列产品可以根据具身智能用户场景灵活组合,凭借高速三维重建、实时SLAM与物体识别能力,正可用于为机器人训练提供关键的“数据流”。
具体而言,我们的解决方案具备以下核心优势:
01
独立硬件预处理与云边端协同
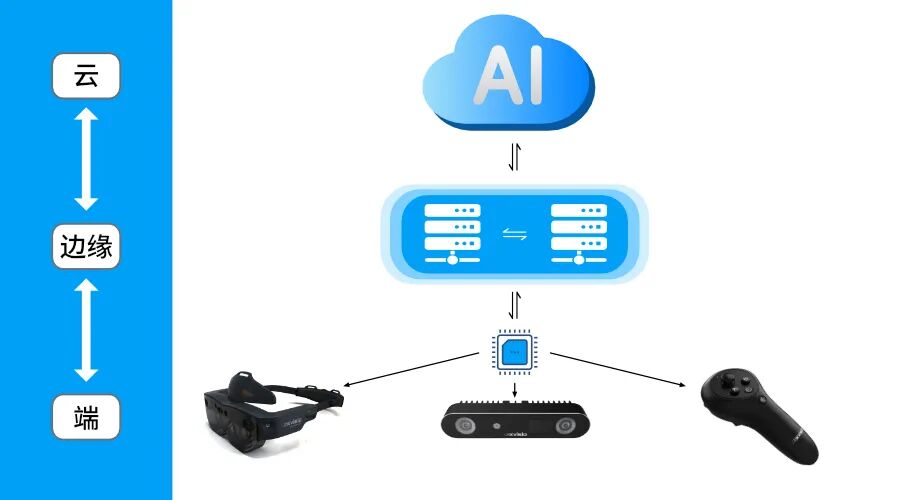
内嵌了一个高效的“智能感官小脑”。当它“看到”图像时,能在本地瞬间完成关键特征提取和初步运动计算,就像人的脊髓能先于大脑处理某些反射一样。这个设计,让系统的“大脑”(主控制器)不再需要事无巨细地处理海量原始像素,而是直接接收已经过提炼、结构化的感知结果。
基于此,整个数据系统的分工变得前所未有的清晰:“端”(我们的产品端)负责实时感知与预处理,“边”(边缘服务器)负责多模态融合与复杂策略,“云”(云端平台)负责模型的长期训练与迭代。这种高效的协同,最终在系统层面带来了可感知的三大增益:主控“大脑”的算力得以解放,可以运行更复杂的智能模型;从感知到决策的“神经反射”路径极短,响应速度大幅提升;整体系统的“新陈代谢”效率更高,能耗显著降低。
02
多源输入与多引擎融合
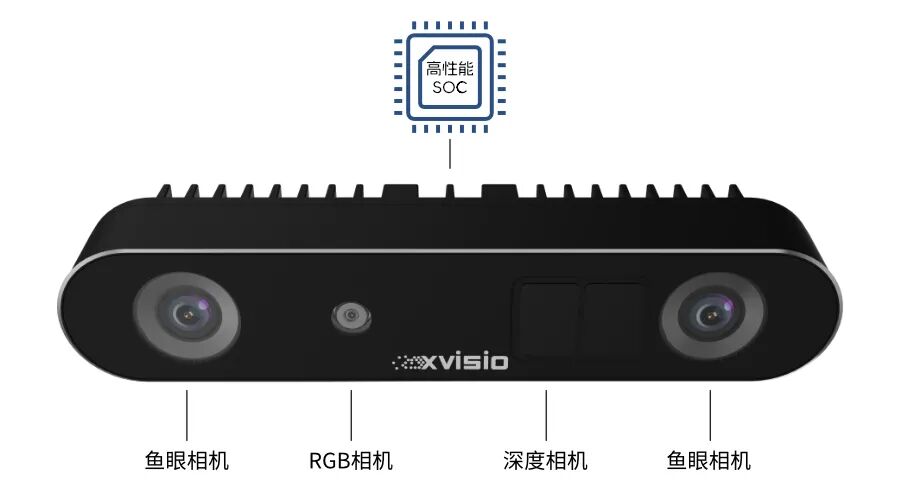
为机器人构建了一套 “全向智能感官系统” 。它可以同时接入广角鱼眼镜头(看清四周环境)、TOF深度相机(精确测距)和高清RGB镜头(识别颜色与纹理)等多路眼睛,从不同维度“观察”世界。
关键在于,这些不同“眼睛”看到的信息,并非孤立地传递。模组内置的 SLAM(定位建图)、深度计算等多重智能引擎,会在端侧进行实时交汇与融合。这就像一个精密的感官中枢,将“看到了什么”、“距离多远”、“是什么颜色”的信息瞬间对齐、叠加,生成立体、精确且时空统一的场景理解。
这一过程直接带来了两大优势:第一,它从数据源头解决了多传感器“各看各的”导致的同步难题,确保感知结果内禀一致;第二,它让机器人能同时处理“我在哪”、“周围有什么”、“如何交互”等多个任务,从容应对动态、遮挡、光照多变等复杂真实场景。
03
高级智能感知功能

结合VSLAM与深度信息,实现三维手势识别与追踪、体感识别、三维人脸防伪识别、物体识别与空间语义分割、场景理解等高级智能功能,为机器人大模型训练提供更丰富的环境理解与交互能力。
04
开放兼容与快速部署
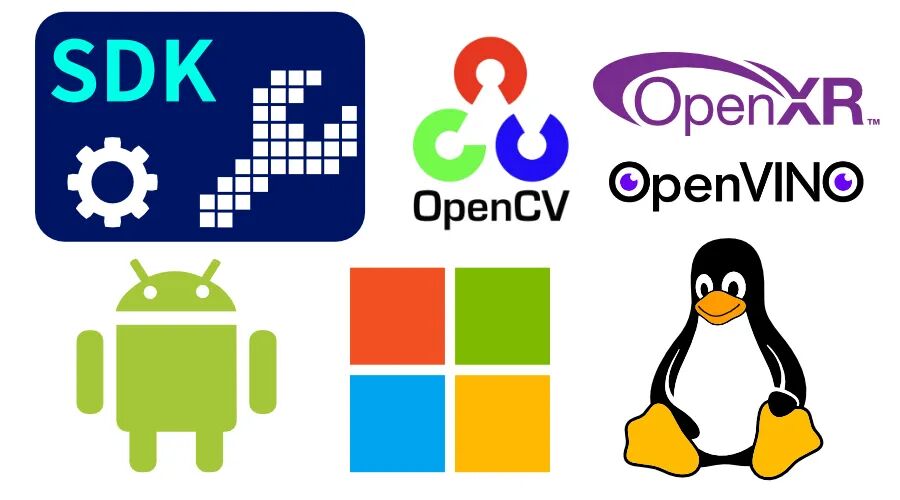
建设开发性的开发和应用生态环境,拥有丰富的SDK,兼容windows\Linux\android系统,完美适配OpenCV\OpenVINO\OpenXR等主流框架,支持用户便捷部署自训练模型,实现即插即用,大幅缩短研发周期。
05
智能视频压缩与带宽优化

基于硬件的H.265视频压缩技术,如同在数据源头装上了“高效过滤器”。它能将高分辨率、多路视频流在发送前大幅“瘦身”,从而显著节约传输带宽,缓解网络拥堵。这一关键优化,使得后端系统无需为处理海量原始数据而耗尽算力,整体负载与延迟得以降低,特别为需要持续稳定运行的多目高清实时系统扫清了障碍。
06
易集成

完善的功能以及灵活的组合,大幅降低了开发和集成门槛,让开发者能更专注于数据采集与训练系统的应用开发与创新。
我们向用户呈现的并非孤立的产品,而是一套系统化的工程答案。它确保在数据驱动的最源头,视觉感知能如稳定的灯塔,照亮机器人认知物理世界的初始一瞬。我们交付的,是数据炼油厂中,那个至关重要的“感知质量阀门”。
在具身智能的“Hello Data”时代,智能的涌现将不只在算法的巧思中,更在高质量数据持续汇集的河流里。谁能为这条河流保障纯净、充沛的源头活水,谁就握有了赋能整个生态的基石。我们深信,可靠的感知,正是这活水的第一道泉眼。
创新机器感知能力,赋能具身智能进化。
这是我们的“Hello Data”。
也期待,成为你智能征程的起点。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)