小白程序员必看:收藏这份强化学习大模型实战指南,轻松掌握RLHF与Agentic-RL!
智能体(Agent)通过与环境(Environment)的持续交互,通过 “试错” 学习最优行为策略,以最大化长期累积奖励(Reward),其流程图如下所示:图1. RL基本流程• 智能体(Agent) = 正在学习的 “机器人 / 模型”(比如自动驾驶汽车、大模型、工业机械臂);• 环境(Environment) = 智能体所处的场景(比如城市道路、对话场景、工厂生产线);• 状态(State)
本文从强化学习(RL)的基础知识出发,探讨了其如何驱动智能体在复杂环境中学习和决策,并将大模型的决策能力转化为现实生产力。文章涵盖了RL的核心概念、常用算法(如Q-learning、REINFORCE、PPO等),并对比了LLM-RL与Agentic-RL的差异。最后,介绍了热门的Agentic RL训练框架和业界优秀实践案例,旨在帮助读者全面了解RL在大模型中的应用,并提供了实用的学习资源和工具推荐。
一、RL基础知识
1、什么是RL
强化学习是机器学习的三大核心分支之一(另外两个是监督学习、无监督学习),核心逻辑是:智能体(Agent)通过与环境(Environment)的持续交互,通过 “试错” 学习最优行为策略,以最大化长期累积奖励(Reward),其流程图如下所示:
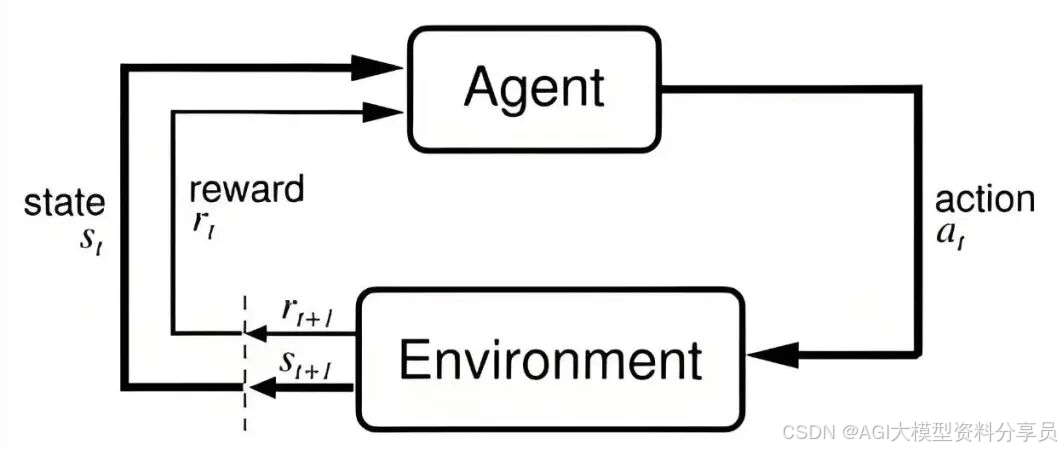
图1. RL基本流程
可以用一个通俗的类比理解:
- • 智能体(Agent) = 正在学习的 “机器人 / 模型”(比如自动驾驶汽车、大模型、工业机械臂);
- • 环境(Environment) = 智能体所处的场景(比如城市道路、对话场景、工厂生产线);
- • 状态(State)= 环境的实时情况(比如道路拥堵、用户的提问、机械臂的位置);
- • 动作(Action)= 智能体的决策(比如刹车、模型的回复、机械臂的抓取动作);
- • 奖励(Reward)= 环境对动作的反馈(比如安全通过路口得正奖励、用户满意回复得正奖励、抓取失败得负奖励);
- • 策略(Policy)= 智能体学到的 “决策规则”(比如 “看到红灯就刹车”“用户问事实就输出准确答案”)。
2、RL的核心特点(区别于其他机器学习)
- 无监督标注:不需要提前准备 “输入 - 输出” 的标注数据(比如监督学习需要的 “图片 - 标签”),数据通过智能体与环境的交互实时生成;
- 长期视角:不追求单次动作的 “即时奖励”,而是最大化 “长期累积奖励”(比如自动驾驶不会为了短期加速而忽视长期安全);
- 探索与利用(Exploration vs Exploitation):智能体需要在 “尝试新动作(探索未知策略)” 和 “使用已知有效动作(利用已有经验)” 之间平衡,避免陷入局部最优。
3、为什么需要RL
物理世界中,很多真实问题本质上就是「序列决策」,凡是符合以下几种情境的场景下,强化学习都天然适用:
- • 机器人控制:机械臂抓取、无人机飞行、自动驾驶。
- • 游戏 & 对弈:围棋、星际争霸、Dota2(AlphaGo、AlphaStar)。
- • 推荐与广告:不是只看「这一条推荐是否被点」,而是看 长期用户价值:留存、生命周期价值、多次交互。
- • 运筹 & 调度:仓储选址、路径规划、资源调度(多少机器处理多少任务)。
- • 对话系统 & Agent:一个 Agent 多轮对话、调用工具、写代码、检查结果,这些都是 「长链路、多步反馈」的过程。
这些场景共性就是:
当下的选择会影响「未来能走到的状态」,而我们关心的是整体长期收益,不是某一步的得失。 这类问题,用纯监督学习往往很难建一个特别合理的目标函数,RL 则是为这种情形量身定做的。
4、举例说明
下面使用一个悬崖漫步的例子说明一下强化学习。从4X12的网格左下角状态(Initial State)出发,目标是右下角的旗帜状态(Goal State)。
智能体(Agent)可以采取4种动作(Action):上、下、左、右,环境(Environment)中有一段是悬崖,智能体每走一步奖励(Reward)是-1,掉入悬崖是-100,掉入悬崖和到达终点都是终止态,会回到起点,而最终从起点到终点的最优路径就是策略(Policy)。
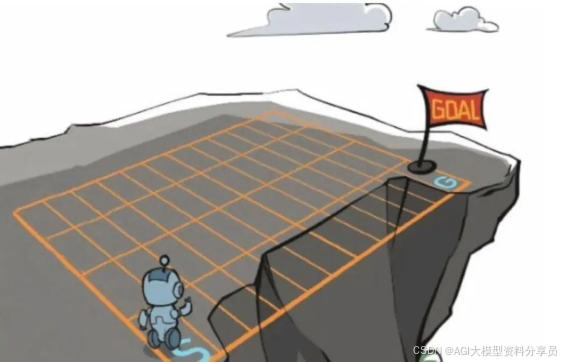
图2. RL示例
物理世界中,很多真实问题本质上就是「序列决策」,凡是符合以下几种情境的场景下,强化学习都天然适用:
除此之外,对大模型 / Agent 来说,RL更是「后训练」阶段的核心工具,其带来的好处包括:
- 能直接优化「任务成功率」而不是「和标注相似度」。
- 能允许模型在一些场景里探索新的策略,而不是拘泥于人类示范。
- 天然适合「Agent + 工具 + 环境」的一整套闭环。
综上,强化学习的核心价值在于它是解决 “决策型 AI 问题” 的唯一有效技术,并且能降低数据成本、适应动态环境。
二、RL核心理论
1、问题建模:马尔可夫决策过程(MDP)
强化学习到底在学习什么?要想回答这个问题,我们可以将其抽象成一个经典MDP(Markov Decision Process,马尔可夫决策过程),一个(折扣)马尔可夫决策过程通常写成一个5元组: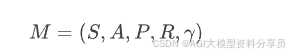
其核心要素如下:
- • 状态空间 𝑆 :当前环境的刻画,比如棋盘布局、机器人位置、当前对话历史等。
- • 动作空间 𝐴 :在这个状态下,智能体能做的选择:走一步、说一句话、推荐一个商品、买/卖/不动…
- • 转移概率 𝑃 :给定当前状态和动作,下一状态的分布,其体现了系统的物理/业务演化规律,通常对智能体是未知的,表达形式如下:
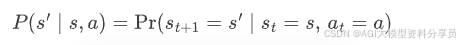
奖励函数 𝑅:环境给的一句「好/不好」的反馈,可以是立即的,也可以是很延迟的,常见写法如: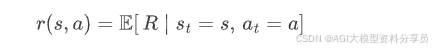
折扣因子 𝛾 ∈ ( 0 , 1 ) :用来定义「未来奖励」的重要程度,𝛾 越接近 1 越重视长期收益,𝛾 越小越「短视」,只在乎眼前利益。
给定一个 MDP,要解决的核心问题是:选什么动作? 选取什么动作执行往往由策略 Policy 𝜋(𝑎 ∣ 𝑠)决定,即给定状态下智能体选择动作的分布——这就是我们要学到的东西。
在策略 𝜋 下,一次从开始到结束的交互形成一条轨迹(trajectory):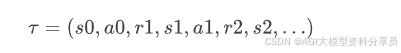
生成过程如下:
1.初始: 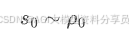
2.每一步:
-
• 策略选动作:
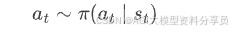
-
• 环境转移:
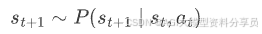
-
• 环境给奖励:
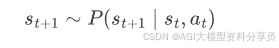
这条轨迹的概率: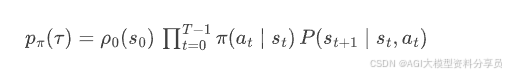
回报 Return 𝐺 定义为从当前时刻往后看的「总收益」,比如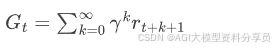
其最终目标是:找到一个策略 
,最大化「期望回报」
2、核心概念:值函数
为什么需要值函数?在前面的 MDP 里,我们的目标是最大化期望回报,但这个目标是「整条轨迹」级别的,不够“局部化”。为了能对“当前在某个状态/做某个动作”进行评估,我们引入值函数(value function):
值函数 = 在某个状态(或状态 + 动作)下,未来能拿到的“好处”的期望。
它把「整条未来」压缩成一个标量,方便比较、优化和做动态规划。
值函数有以下几种定义形式:
- • 状态价值函数:在状态 𝑠 上,如果之后一直按策略 𝜋 走下去,从现在开始往后能拿到的折扣总奖励的期望:
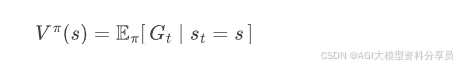
状态-动作价值函数: 在状态 𝑠 下先执行一次动作 𝑎 ,然后以后都按策略 𝜋 走下去,能拿到的折扣总奖励期望: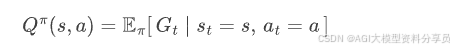
优势函数:在状态 𝑠 下,做动作 𝑎 比起「随便按策略 𝜋 正常走」到底好多少/差多少:
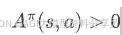
说明比平均水平好, 说明比平均水平差,优势函数出现在很多策略梯度算法(Actor-Critic, PPO, A2C)里,用来减少梯度估计的方差。
3、核心概念:Bellman期望方程
总体上,任何状态的回报都可以被拆解为两个部分:一是从当前状态到下一个状态的即时奖励;二是从下一个状态开始,按照特定策略行动,未来的折扣回报。值函数的关键性质是满足递归关系,而这种递归关系就是Bellman 期望方程(Bellman Expectation Equation)。
- • 对状态价值函数
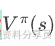
的Bellman方程
从定义出发: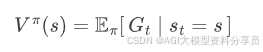
把 𝐺𝑡 拆开:
代入: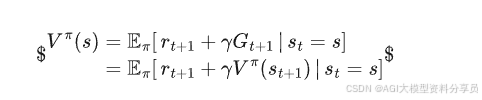
再展开条件期望(先对动作再对下一个状态求期望):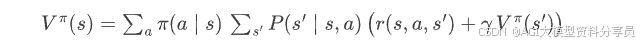
这就是 Bellman 期望方程 的离散形式。
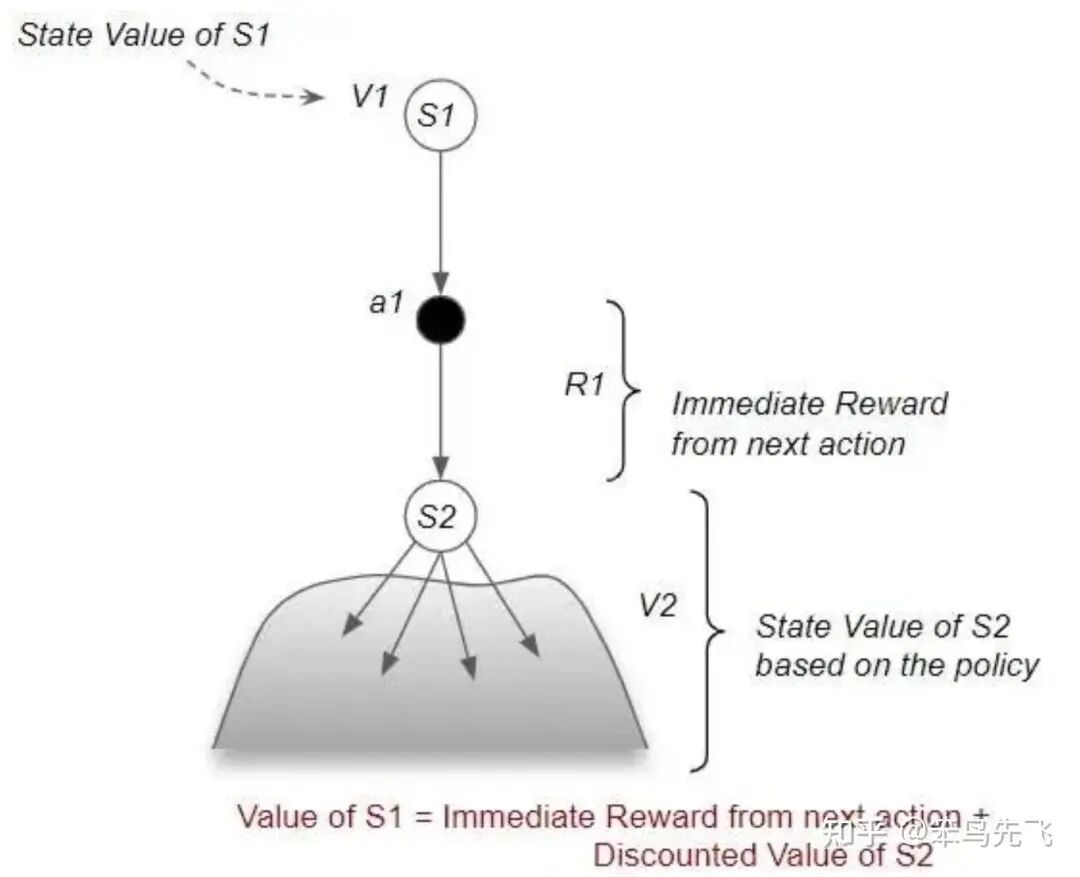
图3. 状态价值函数Bellman方程图例
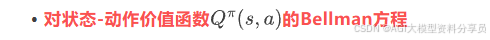
类似地,对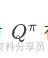
有: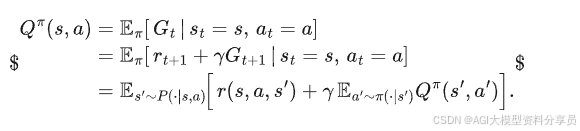
展开成求和形式: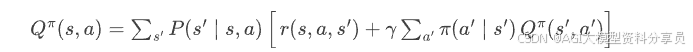
Bellman最优方程(Bellman Optimality Equation)
上面是「给定策略」时的值函数方程,如果我们关心的是最优策略 ,则对应有最优值函数: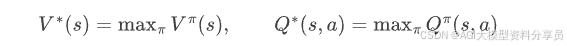
利用“最优策略在每一步都选那时最优动作”的直觉,可以写出Bellman最优方程。

这就是 Q-learning 之类方法的理论基础,即学到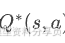
之后,就能通过「在每个状态选 Q 最大的动作」导出最优策略。
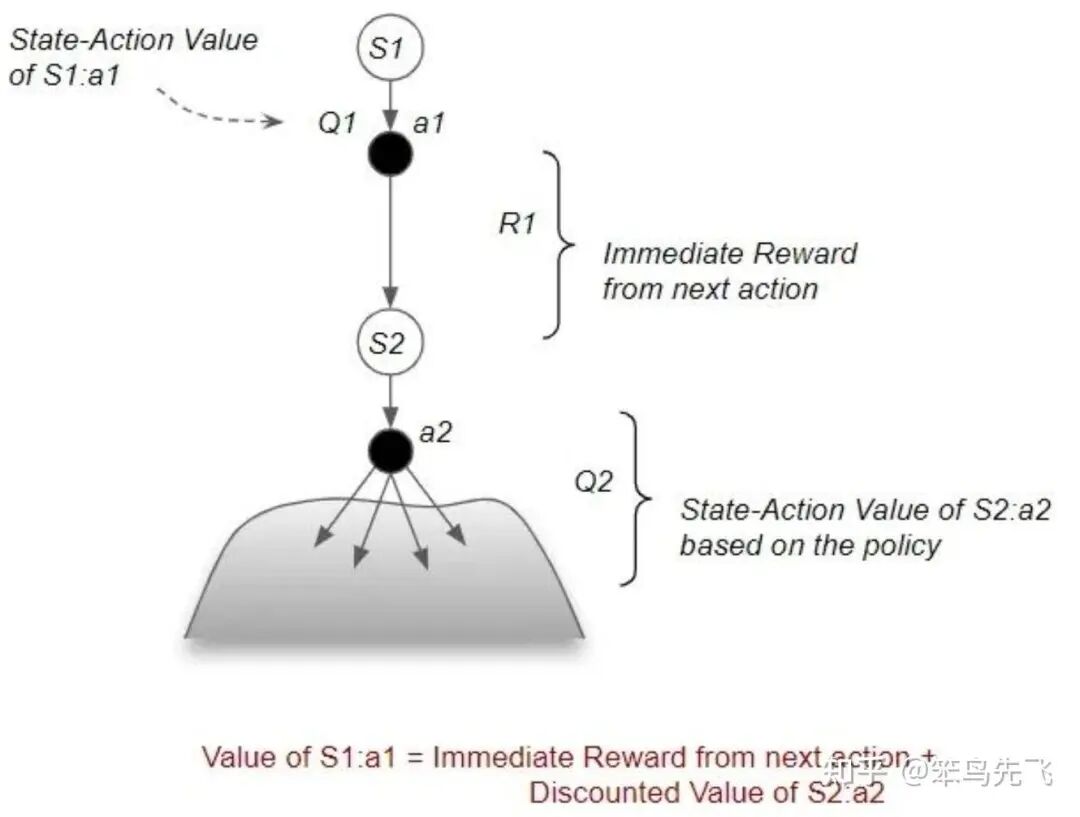
图4. 状态-动作价值Bellman方程图例
三、RL常用算法
1、常用算法分类
1.从优化目标来看,常用RL算法包括以下几个类别:
- • 基于价值函数的方法(Value-Based):基于价值函数的方法,就是先学会“每个状态/动作有多好”(价值),再用这个价值函数去导出策略,其典型做法为学一个 状态价值函数 𝑉(𝑠) 或 动作价值函数 𝑄(𝑠,𝑎) ,而在深度 RL 时代,一般都学 Q 函数(因为更容易直接导出策略),常用算法有Q-learning等。
- • 基于策略的方法(Policy-Based):直接学一个
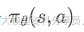
,把策略本身当成参数化模型,直接最大化期望回报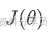
,常用算法有REINFORCE等。 - • 策略价值并行方法(Actor-Critic):同时学习策略(Actor)和价值函数(Critic),用价值函数做「baseline」减小方差,常用算法有PPO等。
2.从数据来源来看,常用RL算法可分为以下两个类别:
- • On-Policy:训练数据由需要训练的策略本身通过与环境的互动产生,用自己产生的数据来进行训练(可以理解为需要实时互动)。
- • Off-Policy:同训练数据预先收集好(人工或者其它策略产生),策略直接通过这些数据进行学习。。
2、典型算法详解
本章节聚焦了一些深度RL领域的常见算法并介绍其理论依据,公式推导和代码实现。
2.1 Q-learning
Q-learning 的核心目标就是:在不知道环境转移概率 𝑃(𝑠′∣𝑠,𝑎) 的情况下,直接通过与环境交互采样到的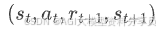
,用一种「自举(bootstrapping)」的方式逼近 
。
Q-learning 的基本思想如下:
我们无法直接算期望,于是用采样到的单步经验:
Q-learning 每步都在用「目标 = 立即奖励 + 折扣后的下一状态最大 Q」来更新当前 Q。
假设:
状态空间 𝑆 和动作空间 𝐴 都是离散且可枚举;
用一个二维表 Qs[1] 存储每个状态-动作对的 Q 值;
则 Q-learning 算法的伪代码如下:
输入:学习率 α ∈ (0,1],折扣因子 γ ∈ [0,1),
探索系数 ε(可随时间衰减),
状态空间 S,动作空间 A
初始化:对所有 s ∈ S, a ∈ A,令 Q(s, a) ← 任意值(例如 0)
for episode = 1, 2, ... do
从环境中初始化状态 s ← s_0
while s 不是终止状态 do
# 1. 使用 ε-greedy 策略选动作
以概率 ε:从 A 中随机选择动作 a
以概率 1 - ε:令
a ← argmax_{a'} Q(s, a')
# 2. 与环境交互,获得下一步
执行动作 a,观察到即时奖励 r 和下一个状态 s'
# 3. 计算 TD 目标和更新 Q
令
y ← r + γ * max_{a'} Q(s', a') (若 s' 为终止状态,则 y ← r)
更新:
Q(s, a) ← Q(s, a) + α * (y - Q(s, a))
# 4. 状态前移
s ← s'
end while
end for
2.2 REINFORCE

该算法伪代码实现如下:
算法 REINFORCE(α, γ)
初始化策略参数 θ(例如随机)
loop: # 训练迭代
# 1. 采样一条完整的 episode
s ← env.reset()
记录列表: states = [], actions = [], rewards = []
while episode 未结束:
根据当前策略 π_θ(·|s) 采样动作 a
执行动作 a,获得 r, s'
将 s, a, r 追加到各自列表
s ← s'
# 2. 计算每个时间步 t 的折扣回报 G_t
G ← 0
returns = 空列表
对 rewards 从后往前遍历:
G ← r + γ * G
将 G 插入 returns 头部 # 得到 [G_0, G_1, ..., G_{T-1}]
# 3. 计算梯度并更新 θ
梯度估计 g ← 0
对每个时间步 t:
g ← g + G_t * ∇_θ log π_θ(a_t | s_t)
θ ← θ + α * g
2.3 PPO
近些年来非常流行对大语言模型做 “基于人类反馈” 的强化学习微调(RLHF),其核心流程是:先有一个预训练语言模型(或初步监督微调好的 SFT 模型),再结合人类偏好或自动奖励模型,对其进行策略优化,PPO就是该系列的主力算法。
PPO(Proximal Policy Optimization) 是 OpenAI 在 2017 年提出的一种策略优化(Actor-Critic)算法,专注于简化训练过程,克服传统策略梯度方法(如TRPO)的计算复杂性,同时保证训练效果。
- • 问题:在强化学习中,直接优化策略会导致不稳定的训练,模型可能因为过大的参数更新而崩溃。
- • 解决方案:PPO通过限制策略更新幅度,使得每一步训练都不会偏离当前策略太多,同时高效利用采样数据。
假设你是一个篮球教练,训练球员投篮:
- • 如果每次训练完全改变投篮动作,球员可能会表现失常(类似于策略更新过度)。
- • 如果每次训练动作变化太小,可能很难进步(类似于更新不足)。
- • PPO 的剪辑机制就像一个“适度改进”的规则,告诉球员在合理范围内调整投篮动作,同时评估每次投篮的表现是否优于平均水平。
PPO遵从On-Policy的策略,On-Policy的策略一般由四个关键组件组成训练的pipeline:
- • Actor: 产生动作的策略,最终需要学习得到的model。
- • Critic: 评估动作或状态的价值的网络,预测生成一个token后, 后续能带来的收益。
- • Reward Model:对状态转移给出即时的奖励的模型或者函数,输入query 和response,输出一个得分。
- • Reference Model: 参考模型,通常是sft 后的model,这是为了防止在训练过程中,策略网络在不断的更新后,相对于原始策略偏移地太远(避免它训歪了)。
PPO RLHF pipeline 可分为以下三步走:
实现时一般是最大化上述公式,或者最小化其负数。
损失函数可拆解为以下三项 Actor + Critic + Entropy:
-
- 策略损失(Actor)
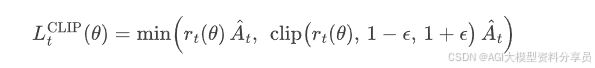
这是PPO 提出的核心目标函数 clipped surrogate objective,其目的在于用 clip 替代显式 KL 约束;
其中:
核心思想为在比率偏离旧策略太远时,进一步优化会被截断,损失不再鼓励大步更新。
- 价值函数损失(Critic)
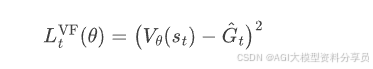
PPO 不是只优化策略,还会同时学习上述 value function;
- 熵奖励(Entropy Bonus):
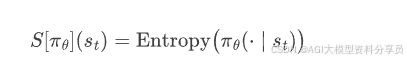
PPO 不是只优化策略,还会同时学习上述 value function;
实际代码里,一般写成最小化如下 loss: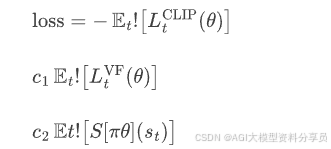
PPO 算法伪代码实现如下:
loop: # 每一轮迭代
# ===== 1. Rollout 收集数据 =====
trajectories = []
for env_step in range(T): # 也可以多环境并行
s_t = 当前状态
a_t ~ π_θ(·|s_t)
执行 a_t 得到 (r_{t+1}, s_{t+1}, done)
记录 (s_t, a_t, r_{t+1}, done, log π_θ(a_t|s_t), V_φ(s_t))
if done: 重置环境
# ===== 2. 计算优势和回报 =====
用 GAE(γ, λ) 从后往前计算 A_t
用 G_t = A_t + V_φ(s_t) 作为回报目标
对 A_t 做归一化
# ===== 3. 多 epoch,小批次优化 =====
for k in range(K): # K 个 epoch
对 trajectories 打乱并按 batch_size 分组
for 一个 minibatch B:
从 B 中取出 s, a, A, G, logπ_old, V_old
# 重新算当前策略的 log prob
logπ_new = log π_θ(a | s)
r = exp(logπ_new - logπ_old)
L_clip = mean( min( r * A, clip(r, 1-ε, 1+ε) * A ) )
V_new = V_φ(s)
value_loss = mean( (V_new - G)^2 )
entropy = mean(策略熵)
loss = -L_clip + c1 * value_loss - c2 * entropy
对 (θ, φ) 进行一次梯度下降
2.4 DPO
鉴于经典 RLHF pipeline(以 PPO 为例),在 RL 优化策略的步骤同时要在线采样、计算 value function、advantage、clip…工程上比较重。
DPO(Direct Preference Optimization)算法提出其核心主张:KL 正则的 RLHF 目标,其实可以在闭式下解出「最优策略的形式」,然后直接用分类损失 / logistic loss去拟合这个最优策略,完全不用显式 reward model,也不用 RL 采样。
DPO 与 RLHF 算法对比如下:
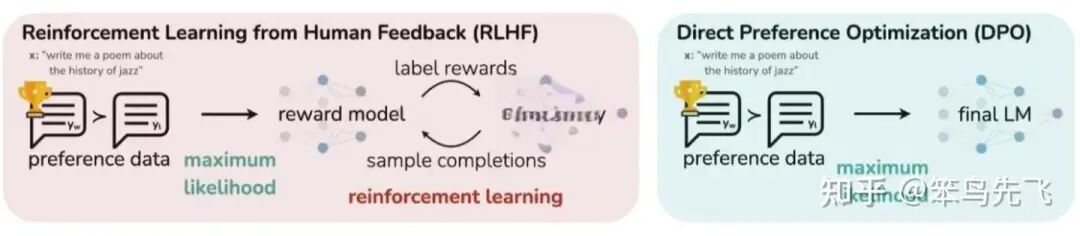
图5. DPO 与 RLHF 算法对比
DPO 的核心特点如下:

归根结底本质是一个 offline preference-based 分类微调。
DPO 算法核心公式推导如下:


DPO 算法伪代码实现如下:
输入:
- 参考模型 π_ref(冻结参数)
- 可训练模型 π_θ(初始参数 = π_ref)
- 偏好数据集 D = {(x, y_pos, y_neg)}
- 超参数:β, learning_rate, batch_size, num_epochs
for epoch in 1..num_epochs:
对 D 打乱并按 batch_size 划分
for (x_batch, y_pos_batch, y_neg_batch) in mini-batches:
# ----- 1. 计算 log prob -----
# 对正样本
logp_pos_theta = log π_θ(y_pos | x) # shape: [B]
logp_pos_ref = log π_ref(y_pos | x) # shape: [B]
# 对负样本
logp_neg_theta = log π_θ(y_neg | x) # shape: [B]
logp_neg_ref = log π_ref(y_neg | x) # shape: [B]
# ----- 2. 构造 Δ log prob -----
delta_theta = logp_pos_theta - logp_neg_theta # Δlogπ_θ
delta_ref = logp_pos_ref - logp_neg_ref # Δlogπ_ref
# ----- 3. DPO logistic loss -----
logits = β * (delta_theta - delta_ref) # shape: [B]
# 概率目标:P( y_pos 被选中 ) = σ(logits)
# 负对数似然:
dpo_loss = - mean( log σ(logits) )
# (有些实现会再加一个对称项 -log(1-σ(logits)),本质等价)
# ----- 4. 反向传播 & 更新 -----
loss = dpo_loss
对 θ 做一次梯度下降更新
2.5 GRPO
GRPO(Group Relative Policy Optimization)是DeepSeek提出的强化学习算法,专为优化大语言模型(如DeepSeek-V3)设计。它通过组内相对奖励代替传统价值模型,降低训练成本,同时保持策略稳定性。
GRPO 与 PPO 算法的流程对比如下:
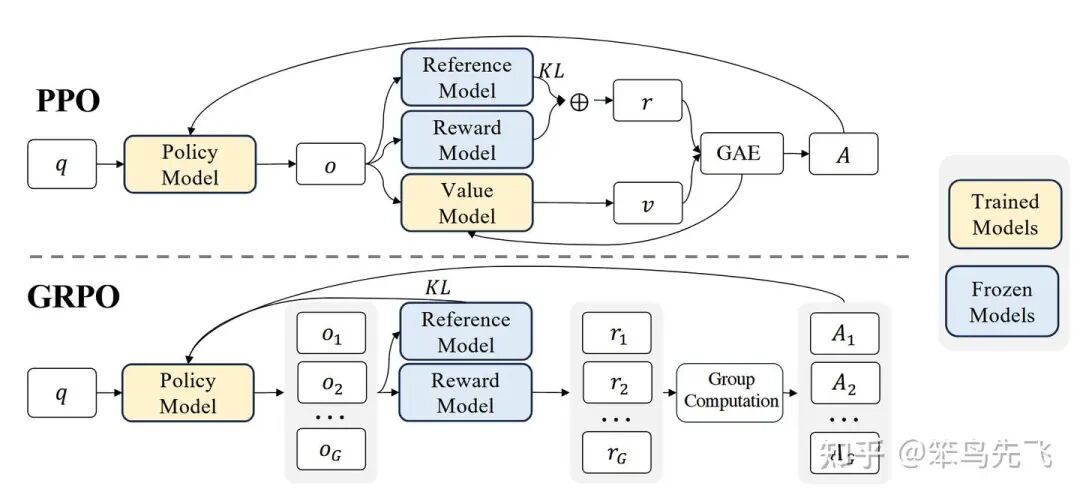
图6. GRPO VS PPO
相较于 PPO,GRPO 的核心 idea 如下:
- • 干掉 Critic,不再训练 value function;
- • 每个 prompt 一次采样一组输出(group),用组内的平均 reward 当 baseline;
- • 优势 𝐴 完全由「相对于组平均的 reward」来计算;
- • 仍然保留 PPO 的 clip 比例 和 KL 正则,更新稳定性不丢。
GRPO 的最终目标:group + 无 critic + KL 直接进 loss
相较于 PPO,GRPO 做了三件关键改动:


保证非负。

GRPO 的“精髓”就在 上:让 group 自己提供 baseline,代替 value function。
对每个问题 𝑞 ,有一组输出 Extra open brace or missing close brace ;
相对应地有 reward model 打分 Extra open brace or missing close brace ;
使用过程监督对这组 reward 做 group 标准化 (目的是为了对数学 / 推理任务进行精细的监督,每一步推理都给reward)

GRPO 算法伪代码实现如下
给定:
- 初始策略模型 π_θ_init (通常是 SFT checkpoint)
- 奖励模型 r_φ
- 参考模型 π_ref (初始 = π_θ_init)
- 任务 prompt 集合 D
- 超参数: ε (clip), β (KL), G (group size), μ (每批上内循环步数)
初始化 θ ← θ_init
for outer_iter = 1..I:
设置参考模型 π_ref ← π_θ # 冻结一份
for step = 1..M:
从 D 采一批 prompt:{q}
设 π_old ← π_θ # 用当前策略作 roll-out 策略
# ----- 1. 采样 group 输出 -----
对每个 q:
采样 G 个输出 {o_i} ~ π_old(· | q)
# ----- 2. 计算 group reward -----
用 r_φ 对所有 (q, o_i) 打分,得到 {r_i} 或 step-level reward
# ----- 3. 计算组相对优势 A_hat_{i,t} -----
- outcome RL: Â_{i,t} = (r_i - mean(r)) / std(r)
- process RL: 用所有 step reward 标准化后,令
Â_{i,t} = sum_{future steps} normalized_reward
# ----- 4. policy update: 多次 GRPO 内循环 -----
for k = 1..μ:
对这一批 (q, {o_i}) 计算:
- 比率 r_{i,t} = π_θ / π_old
- PPO-style clip surrogate using Â_{i,t}
- KL(π_θ || π_ref)
形成 J_GRPO(θ),对 -J_GRPO(θ) 做一次梯度下降
三、LLM-RL VS Agentic-RL
1、LLM-RL(目前主流的 RLHF / PPO 微调)
LLM-RL 典型形态如下:
- • 模型:一个大语言模型 ,输入 prompt,输出一整段回答;
- • 环境:几乎没有显式环境,更多是“离线日志 + 打分器(RM)”模式;
- • 奖励:人类偏好/排名(RM 输出的标量)或者简单功能性 reward(例如 code 能运行、数学题对不对);
- • 算法:PPO / DPO / RPO / GRPO 一类的「对整段回答的概率分布做调整」。
可以粗暴理解为:把 LM 当成一个大 policy,每次行动就是“生成一整个回答”,然后根据这次回答的评分,整体推一下参数。
基本特征如下:
- • 单轮或短上下文;
- • 没有显式状态转移(环境不会因为你这次回答改变「可观测状态」);
- • 没有真正意义上的探索策略,只是从现在的 LM 采样几条候选。
如下图所示,LLM-RL 的架构更像是一个被严密监控的“内部自我博弈”系统。它的核心不在于使用工具的能力,而在于在“奖励模型”和“参考模型”的双重约束下,提升文本输出Token的结果。环境其实就是 Reward Model + Reference Model,这是一个虚拟的、静态的数学环境,优化的是文本的概率分布。
简单举个例子,LLM-RL 架构就是一个“带私教的模拟考试”系统:
-
- 学生 (Actor): 也就是我们要训练的 LLM,负责答题。
-
- 考官 (Reward Model): 代表人类喜好,只在最后打一个总分(比如:这篇 80 分)。
-
- 紧箍咒 (Ref Model): 防止学生为了刷分而走火入魔(乱凑字数),强迫它保持正常说话的习惯。
-
- 私教 (Critic): 因为考官只给总分,私教负责实时预测分数,一步步告诉学生:“刚才那句写得好,继续保持;这句写得烂,下次改掉”。
**一句话总结:**学生 (Actor) 在 私教 (Critic) 的指点下,努力讨好 考官 (Reward) 拿高分,同时还得戴着 紧箍咒 (Ref) 别乱写。
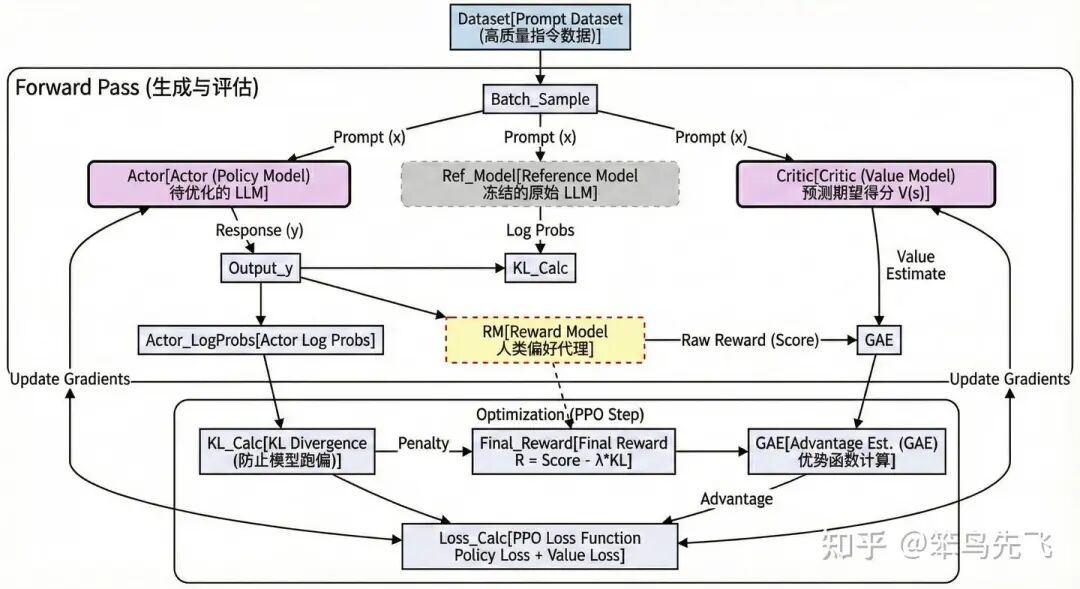
图7. LLM-RL流程图
2、Agentic-RL(基于智能体的强化学习)
这里的「Agent」指的是:
- • 状st态 :包含环境信息 + Agent 内部记忆(history、工具输出、数据库状态…);
- • 动作at :不再只是“下一个 token”,而是:选择工具、构造 SQL / API 调用、规划子任务、决定是否继续对话、是否写入知识库等等;
- • 环境 𝐸 :真实的数据库、Web API、用户、任务队列、文件系统……会随着动作变化;
- • 回报 rt:和任务成功率、延迟、成本、用户满意度、安全约束相关;
- • 策略:可以由 LLM+工具组成,但 RL 优化的是「整个决策流程」。
一句话总结,Agentic RL = 在“状态–动作–环境反馈”这个闭环上做 RL,LLM 只是这个闭环里实现策略的一部分。
这时候LLM 不再仅仅是“嘴巴”(生成文本),而是成了“大脑”(决策中心),它通过操纵“四肢”(工具/API)与“世界”(环境)交互,并根据“绩效指标”(Reward)来优化自身的决策逻辑,如下图所示。
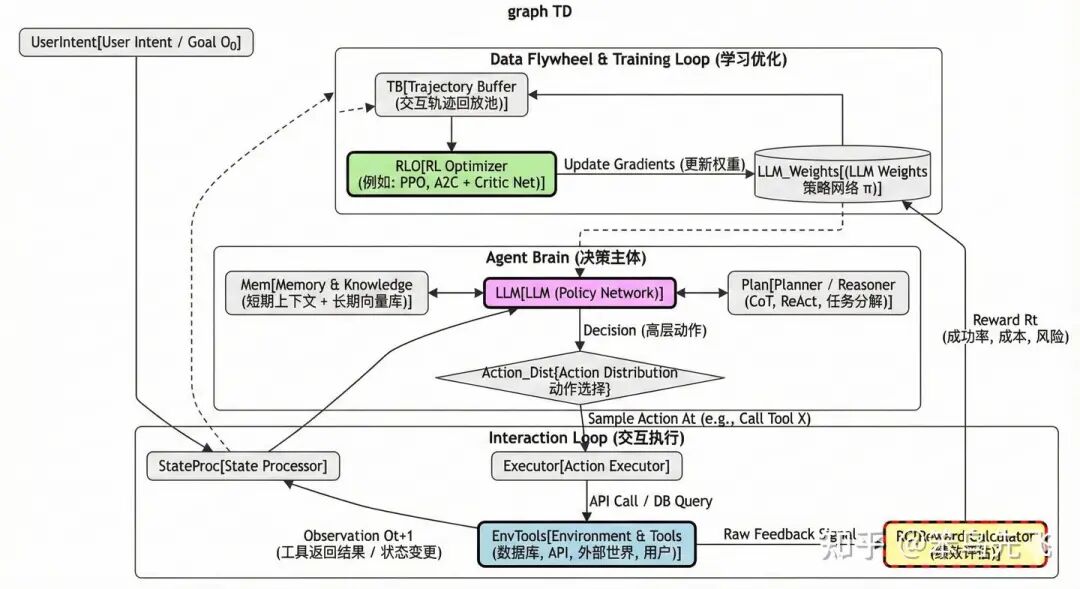
图8. Agentic-RL流程图
3、LLM-RL vs Agentic-RL 关键差异
3.1 环境 & 交互形式
LLM-RL:
- • 环境基本是静止的:给你一个 prompt,你吐一个回答,结束;
- • reward 在“episode 终点”给(整条回答一个分);
- • 不存在“对同一个任务多轮试错”这个概念。
Agentic-RL:
- • 环境是动态的:查询数据库会改变上下文;调用 API 可能改变外部世界;用户下一句话取决于你刚刚的回答;
- • 回合可以很长,多步骤、多工具、多轮对话;
- • 需要通过多轮 trial-and-error 去发现更好的策略;
换句更尖锐的话:LLM RL 优化的是「一次性吐答案」的质量;而Agentic RL 优化的是「多步交互过程」本身。
3.2 行动粒度 & 信用分配(credit assignment)
LLM-RL:
- • 行动粒度 = token 或整段回答;
- • reward 通常只在「最后」给一次(正确/错误、人类偏好分);
- • 信用分配基本是「把奖励摊到所有 token 上」,最多用 GAE 平滑一下;
Agentic-RL:
- • 行动是高层决策:调用哪个 tool、读哪张表、如何规划子问题、是否结束任务;
- • reward 可以在流程中的多个关键节点给(找到正确子问题、选中对的表 / API、成功更新知识库等等);
- • 信用分配可以精准到「哪一步决策让任务走向成功/失败」;
对「数据 Agent / 工具 Agent」来说:真正重要的是“每一步选的工具和操作是否对任务有贡献”,这个粒度上,单纯对最终回答打个分再 PPO 一下,是很难学到东西的。
3.3 优化目标:输出分布 vs 任务绩效
LLM-RL:
- • 目标多是「对齐」,而且在 给定 prompt、一次回答 这个框架里;
- • reward 模型学的是「用户更喜欢哪种回答」;
Agentic-RL:
- • 目标更接近「系统级 KPI」,包括成功率(任务完成 / 召回率 / 正确率)、成本(调用工具次数、API 费用、延迟)、稳定性 & 安全性(不会乱改数据、不会泄露隐私);
- • 甚至是多目标加权:𝑅=𝛼⋅成功率−𝛽⋅成本−𝛾⋅风险
也就是说,LLM-RL 优化的是「回答好不好」;而 Agentic RL 优化的是「整个系统做事情做得好不好」。
3.4 数据来源 & 学习范式
LLM-RL:
- • 典型 RLHF 是「离线数据 + 少量在线采样」;
- • 主数据是标注好的对话 / 偏好对,环境不会变;
- • 很多时候更像「加了 KL 正则的监督学习」→ DPO、IPO 等。
Agentic RL:
- • 必须和环境「长期在线交互」才能形成 data flywheel,包括收集成功/失败信号、用户显式/隐式反馈,以及on-policy 或 off-policy 地持续更新策略;
- • 会涉及:探索、分布偏移、off-policy 修正等更“正统”的 RL 问题。
四、为什么Agentic RL 是“必要的”
1、真实业务任务大多是“长过程 + 多工具”的
目前广泛关注的数据 Agent,本质就是:给模型一个复杂任务(报表、诊断、数据质检…),它需要自己规划步骤、查表、连接 DB、抽取字段、写回结果,有时还要问人、有时要回滚操作。
而这些任务的成功与否:
- • 完全取决于一连串决策的组合(选对/错工具、读对/错表、update 对/错字段……);
- • 单次自然语言回答的 reward,只能部分反映这些决策好坏。
如果只在“最后一句回复”上做 PPO/RLHF:
- • 模型学会的是「如何描述自己正在做什么」,
- • 不一定学会「真正正确地做什么」。
这也就是为什么在 agent 场景里容易出现:嘴上说得天花乱坠,实际上工具调用乱来。
2、靠静态偏好数据,无法逼出“结构化策略”
很多 Agent 能力是「结构」而不是「风格」:
- • 如何把一个复杂 query 分解成子任务;
- • 如何根据 schema 选择合适的表;
- • 如何在工具失败时重试 / fallback;
- • 如何在 budget 约束下做最优查询计划。
这些东西:
- • 一方面很难事先写成「成对偏好数据」;
- • 另一方面更难靠标注几条“正确轨迹示例”去做 SFT 就学会泛化;
Agentic-RL 的必要点在于:
-
- 你必须让 Agent 在环境里大量试错;
-
- 让 reward 针对「任务结构」给反馈;
-
- 这样策略才会自动发现「哪些规划/工具使用模式更成功」;
3、数据飞轮 & 在线学习:只有 Agentic-RL 能真正闭环
想象你有大量真实用户在用你的数据 Agent :
- • 每天海量的对话 + 工具调用日志;
- • 每条任务最终要么成功要么失败,并带有一些可观测 signal(用户是否继续追问、是否导出报表、是否投诉…);
如果只做 LLM RL:
- • 这些 log 大多被当成“提示工程素材”或者“再标注一点偏好对”;
- • 更新节奏很慢,反馈利用率极低;
如果做 Agentic RL:
- • 可以把这些日志直接变成 RL episode:其中 为prompt + 历史交互 + 工具结果,为当前工具/操作/回复;为即时/终局任务得分;
- • 用 off-policy AC / Q-learning / policy gradient 等方法持续更新;
- • 形成真正的「Online Learning / 数据飞轮」;
在竞争场景下,这个“自动变聪明”的闭环是决定性差异,单纯 LLM-RL 做不到。
总结一下,传统的 LLM RL(例如 PPO-based RLHF)本质上仍然是一种“分布对齐”技术:它在离线偏好数据和静态 prompt 环境中,调整语言模型的输出概率分布,使单轮回答更符合人类偏好。
然而,在现实应用中,真正具有商业价值的智能系统往往是 Agent 化的:它们需要在一个动态环境中进行多步决策、调用多种工具、维护长期记忆,并对任务成功率、成本、安全约束等系统级指标负责。
这种情况下,仅仅针对单轮输出做 LLM RL 已经不够,我们需要将 RL 扩展到整个 “状态–动作–环境反馈” 的闭环上,用 Agentic RL 直接优化智能体的行为策略。
换言之,LLM RL 让模型“说得更好”,而 Agentic RL 让系统“做得更好”;只有两者结合,才能支撑未来复杂的数据智能体和企业级 Agent 应用。
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。

👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 33
33 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)