【CVPR2026】医疗影像分割的新范式:从全量微调到 Token 级的“专家会诊”

在计算机视觉领域,Segment Anything Model (SAM) 的出现定义了通用分割的新高度。然而,医学影像的异质性——从 CT 的 Hounsfield 单位到 MRI 的多种加权序列,再到 X-ray 的投影重叠——使得直接迁移 SAM 面临巨大的域偏移挑战 。目前的学术界主流做法往往陷入了“数据竞赛”,通过构建数以千万计的医疗数据集进行全参数或解码器微调 。这种方式虽然提升了性能,却容易导致模型原始通用能力的丧失,且带来了高昂的计算成本与噪声干扰 。
近期由四川大学、新疆大学及阿里达摩院等机构联合发表于CVPR2026的论文提出了一种名为 SegMoTE 的创新框架 。该研究的核心逻辑在于:与其改变模型的“身体”(骨干网络),不如通过引入 Token 级别的混合专家(Mixture of Experts, MoE)机制,为模型装上一颗能够根据输入模态自动切换逻辑的“专家大脑” 。
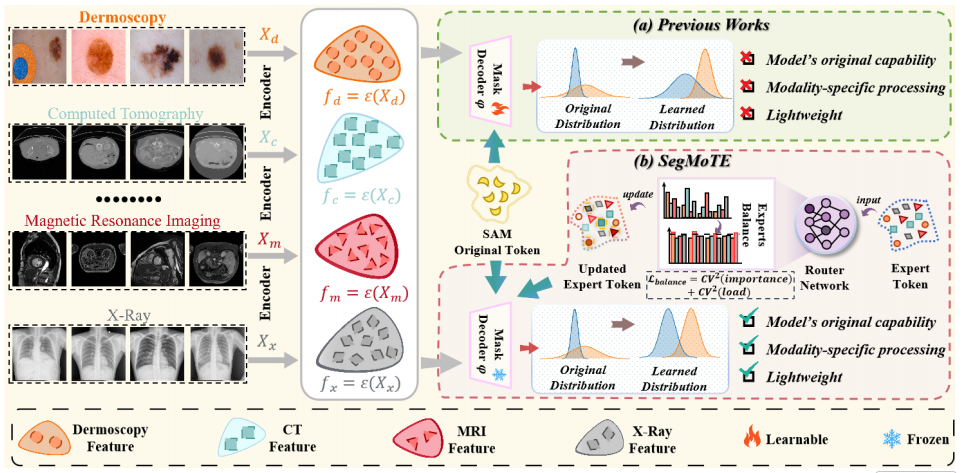
上图显示了SegMoTE与先前工作对比。 异构数据 XXX首先由编码器ϵ\epsilonϵ处理以提取特征表示fff。(a)先前方法通常对掩码解码器进行完整微调或参数高效微调,导致从预训练模型出现分布偏移。(b)SegMoTE引入了一种基于token级别的专家混合模型机制,在冻结掩码解码器的同时动态选择模态自适应的专家token。该过程由负载均衡损失LbalanceL_{balance}Lbalance指导,并使用变差平方系数(CV2CV^2CV2)进行约束。这种设计保留了SAM的原始能力,增强了模态特定的适应性,并保持了轻量级架构。
1.架构深探:Token 级混合专家的动态路由
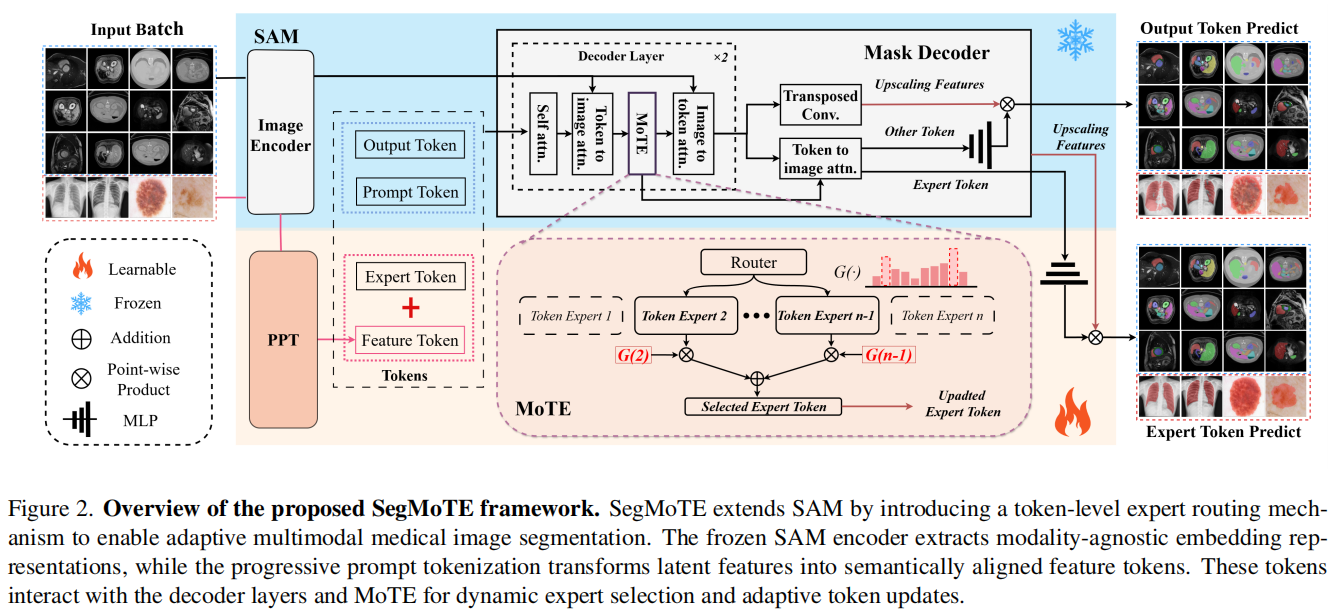
SegMoTE 的技术核心在于对 SAM 掩码解码器(Mask Decoder)的改造。研究者并没有采用传统的层级微调,而是引入了一组可学习的专家 Token(Expert Tokens) 。
1.1 多专家协同机制
系统预设了 NNN 个维度的专家 Token,这些 Token 与 SAM 原有的输出 Token 及提示 Token 共同进入解码器进行自注意力(Self-attention)与交叉注意力(Cross-attention)计算 。在 token-to-image 阶段,专家 Token 能够整合来自特定模态的视觉特征与提示信息的几何语义 。
在 SegMoTE 框架中,专家 Token 的协同并不是简单的并列,而是一个深度嵌入 SAM 掩码解码器(Mask Decoder)计算流的动态过程。其核心逻辑在于改变了 SAM 原有的“特征-Token”交互拓扑结构。
(1)专家 Token 的初始化与输入构造
SegMoTE 引入了一组维度为 N×256N \times 256N×256 的可学习专家 Token 。
序列拼接:这些专家 Token 不会替换原有的组件,而是与 SAM 原始的 4 个输出 Token(Output Tokens)以及由提示编码器生成的提示 Token(Prompt Tokens)在序列维度上进行拼接 。
多维度表征:NNN 的数量取决于任务复杂度或预设的模态覆盖范围(实验证明 N=4N=4N=4 通常足以覆盖主流医疗模态) 。
(2)解码器内的双向注意力交互
拼接后的 Token 序列进入掩码解码器的两层结构中,进行高频次的特征交换 :
同类自注意力(Self-attention):专家 Token 首先与其他所有 Token(包括原始输出 Token 和提示 Token)进行交互,从中学习提示信息的几何约束(如框的位置)和掩码的初步表示 。
Token-to-Image 交叉注意力:这是专家 Token 获取“模态感知”的关键步骤。专家 Token 作为 Query,去查询(Query)图像编码器提取的二维图像嵌入(Image Embeddings)。通过这一步,专家 Token 能够捕获到特定模态(如 CT 的高对比度边缘或 MRI 的组织纹理)的空间特征 。此时,每个专家 Token 都包含了一份结合了“图像特征 + 提示语义”的中间表示。
(3)动态路由与权重分配(MoTE 核心)
这是 SegMoTE 最具创新性的环节。在 Token 更新之前,系统必须决定哪一个专家更适合当前的图像 。
逻辑路由(Router):路由网络通过一个线性层 WgW_gWg 处理输入 Token,计算其对所有专家 E 的原始得分(Logits) 。
带噪声的 Top-2 选择:为了增强鲁棒性,系统在得分中注入高斯噪声,并选择得分最高的两个专家路径进行激活(Top-2) 。
置信度加权更新:系统利用 Softmax 计算出最优专家的可靠性指标 G(⋅)G(\cdot)G(⋅) 。通过公式 z~=G(⋅)⋅h(idx)\tilde{z} = G(\cdot) \cdot h^{(idx)}z~=G(⋅)⋅h(idx),高置信度的专家 Token 表征被放大,而低置信度的则被抑制 。这保证了最终参与掩码生成的 Token 是经过“路由筛选”后的最优解 。
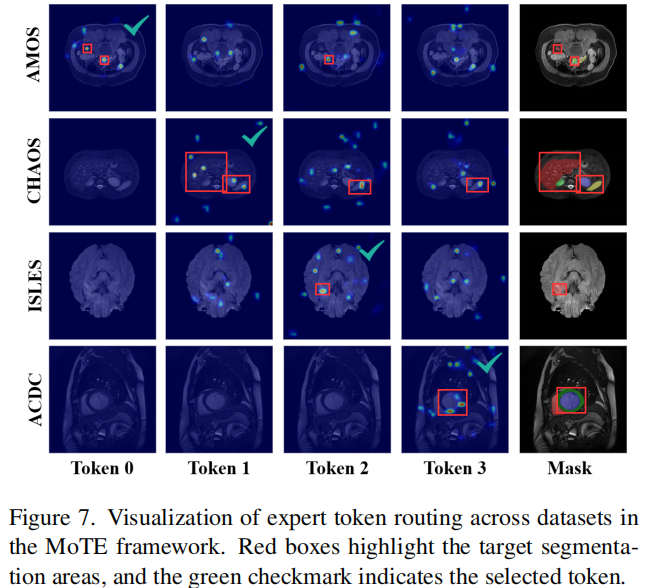
论文中的 Figure 7 旨在通过热力图(Heatmaps)形式,直观展示 MoTE(混合专家 Token)机制在面对不同医疗影像数据集时的路径选择逻辑与空间可解释性 。它不仅证明了模型能够“选对专家”,还揭示了这些专家 Token 实际上在关注图像中的哪些具体区域。
Token 0:在 AMOS (MRI) 任务中表现活跃,能够完整覆盖目标区域 。
Token 1:在 CHAOS (T2) 任务中展现出极高的定位精度,而此时 Token 0 则处于非激活状态 。
Token 2:专门负责 ISLES(缺血性卒中病灶)的识别,只有它能覆盖目标 。
Token 3:在 ACDC(心脏影像)中被激活,并成功定位目标 。
这表明不同的专家 Token 已经学习到了互补的、具有模态判别力的表征 。
(4)Image-to-Token 反馈与掩码生成
经过路由更新后的专家 Token 会再次参与 Image-to-Token 交叉注意力 计算,将更新后的模态特异性信息反馈给图像特征图 。最后,这些被激活且强化过的专家 Token 会通过一个小型的 MLP 转化为动态权重,与缩放后的图像特征进行逐元素相乘(Point-wise Product),从而生成最终的高精度分割掩码 。
1.2 负载均衡约束
在混合专家模型(MoE)的训练中,负载失衡是一个经典痛点:模型往往会产生“胜者通吃”效应,即路由网络倾向于反复调用少数几个表现较好的专家,而导致其余专家长期处于闲置状态(即训练不充分),这会严重削弱多模态适配的泛化能力 。为了解决这一问题,SegMoTE 引入了基于**变异系数(Coefficient of Variation, CV)**的辅助损失函数 Lbalance\mathcal{L}_{balance}Lbalance。其核心逻辑是通过数学手段约束专家库的“利用率”与“重要性”分布。
(1)核心指标:重要性与负载
在计算损失之前,系统定义了两个关键的统计维度:
专家重要性 (impeimp_eimpe):指在一个 Batch 中,所有 Token 分配给专家 eee 的路由权重的总和 。它反映了专家在特征贡献上的“分量”。
专家负载 (loadeload_eloade):指在一个 Batch 中,实际被路由分配到专家 eee 的 Token 数量 。它反映了专家在计算任务上的“忙碌程度”。
(2)变异系数(CV)的引入
变异系数定义为标准差与平均值的比值:
CV=std(Values)mean(Values)CV = \frac{std(Values)}{mean(Values)}CV=mean(Values)std(Values)
在 SegMoTE 中,研究者分别计算了重要性向量 {impe}\{imp_e\}{impe} 和负载向量 {loade}\{load_e\}{loade} 的 CV2CV^2CV2:
当 CVCVCV 趋近于 0 时:意味着各专家的重要性或负载几乎相等,分布处于极致的均衡状态 。
当 CVCVCV 较大时:意味着分布极度不均,某些专家过载,而某些专家被冷落。
(3)总平衡损失函数
最终的负载均衡损失 Lbalance\mathcal{L}_{balance}Lbalance 是这两者平方项的和:
Lbalance=CV2({impe}e=1E)+CV2({loade}e=1E)\mathcal{L}_{balance}=CV^{2}(\{imp_{e}\}_{e=1}^{E})+CV^{2}(\{load_{e}\}_{e=1}^{E})Lbalance=CV2({impe}e=1E)+CV2({loade}e=1E)
在整体训练的损失函数中,它通过一个超参数 λbalance\lambda_{balance}λbalance 进行调节:
Ltotal=Lseg+λbalance⋅Lbalance\mathcal{L}_{total}=\mathcal{L}_{seg}+\lambda_{balance}\cdot\mathcal{L}_{balance}Ltotal=Lseg+λbalance⋅Lbalance
(4)为什么要这样设计?
强制均衡分配任务,确保每个专家 Token 都能在训练过程中接触到充足的样本,从而学习到稳健的模态特征 。如果不对负载进行约束,模型可能会用同一个专家去处理 CT 和 MRI,导致不同模态的表征逐渐同质化,丧失 SegMoTE 设计的初衷 。研究者将 λbalance\lambda_{balance}λbalance 设置为较小的数值(如 0.01),以确保平衡约束不会反客为主,干扰模型对分割任务(Dice Loss)的主目标优化 。通过这一约束,SegMoTE 在只有 4 个专家的情况下,实现了对 CT、MRI、X-ray 等多种异质影像的高效、平衡适配 。
2. 渐进式提示词 Token 化 (PPT):通往自动化分割之路
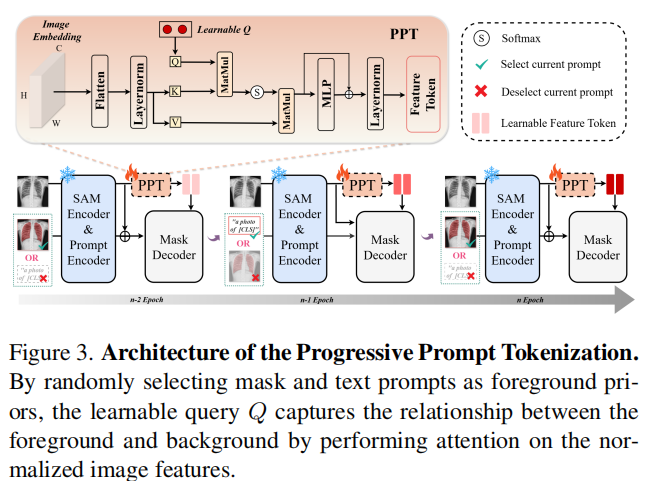
渐进式提示词 Token 化(Progressive Prompt Tokenization, PPT) 是 SegMoTE 实现从“交互式分割”向“自动化分割”跨越的关键技术 。其核心逻辑是利用图像自身的特征反馈,在训练过程中动态生成能够替代人工点击或方框的自适应提示 Token 。
(1)核心逻辑:从“外部干预”到“特征自引导”
传统的交互式分割模型(如原生 SAM)极度依赖用户提供的点(Points)或框(Boxes)来定位目标 。PPT 的设计初衷是让模型在推理阶段无需外界干预,通过图像编码器提取的潜在特征(Latent Features)自动感知前景(病灶/器官)与背景的分布差异,并将其转化为模型可理解的提示信号 。
(2)技术实现:三重演进过程
PPT 的运行流程分为先验注入、注意力对齐与残差精炼三个关键环节:
随机先验采样(Training Phase):在训练阶段,PPT 将掩码(Mask)和文本(Text)视为前景信息的具体表达 。系统通过随机采样这些提示来引导可学习的查询向量 QQQ(Learnable Queries) 。
多头注意力引导(MHA Guidance):QQQ 与经过归一化处理的图像特征执行多头注意力计算 。通过这种方式,QQQ 开始捕获图像中与前景语义一致的分布特征,逐渐学会在特征空间中区分目标区域与背景 。
**特征投影与残差融合:**交互后的表征通过 MLP 投影进行语义强化,并利用残差连接(Residual Fusion)保留原始特征的细节 。最终输出“特征条件提示 Token”(Feature-conditioned Prompt Tokens),这些 Token 已经包含了目标的几何与类别分布信息 。
(3)渐进式学习的成效+
随着训练轮数(Epochs)的增加,PPT 生成的 Token 会经历从“模糊分布”到“精确语义对齐”的转变:在推理阶段,PPT 能够直接从图像特征中生成自适应提示,实现全自动分割 。该机制在目标明确、前景背景对比清晰的任务(如 ISIC 黑色素瘤分割、SZ-CXR 胸部 X 光)中表现尤为出色,能够显著降低临床部署时的交互负担 。
实验数据表明,在域外(OOD)测试中,PPT 辅助下的模型性能比传统点选提示方法提升了约 1% 至 6% 。
(4)局限性说明
由于多器官分割(Multi-class)任务涉及多个类别的语义重叠与干扰,目前 PPT 方案主要聚焦于二分类任务(Binary Classification),以确保在临床应用中的简洁性与推理效率 。
3.数据哲学的转变:MedSeg-HQ 的高质量启示
在构建 MedSeg-HQ 数据集的过程中,研究团队并没有采取传统医疗影像研究中“数据量即正义”的逻辑,而是建立了一套严苛的五维度专家评估系统,从 12 个原始公开数据集中精选出约 15 万个高质量标注样本 。这一系统由 5 名医学影像专家组成,针对每一张影像及其对应的掩码(Mask)进行多准则评分,确保了数据在训练过程中的“高信息增益” 。通过这套系统筛选出的 MedSeg-HQ 数据集,在 t-SNE 特征降维可视化中表现出了卓越的一致性:
特征流形平滑:相比于 COSMOS 或 IMed-361M 等数据集,MedSeg-HQ 的特征分布呈现出更加平滑且连续的转换过程 。
消除分布突变:五维度筛选有效地剔除了那些分布极其离散、带有严重噪声的冗余数据(即图中红色方框标注出的异常区域),显著提升了模型在跨模态任务下的泛化上限 。
这套系统的成功证明了在医疗 AI 领域,1% 的高质量“珍珠”数据,其价值远胜于 99% 的平庸“沙砾”数据 。

实验结果
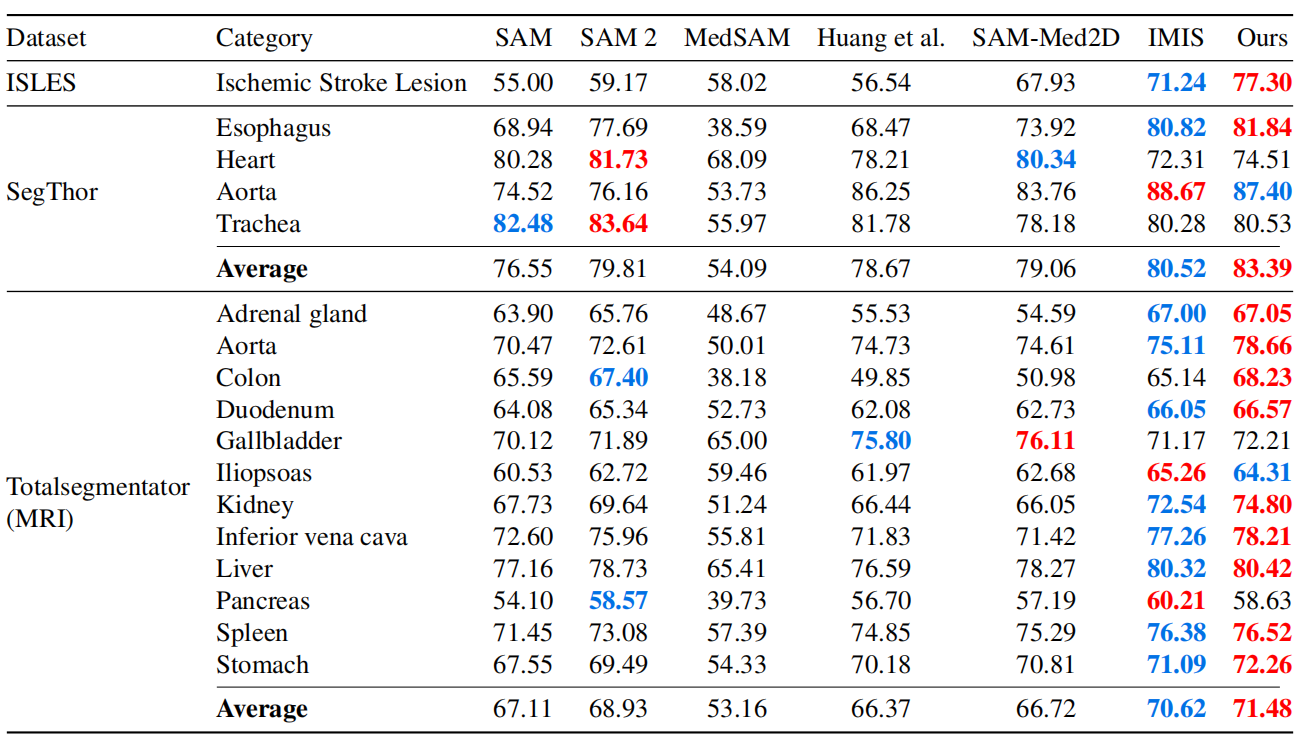
批判性分析
正如作者所述,PPT 面对多类别时的“类干扰”如何解决?是否需要多层查询机制? :实验显示 4 个专家足以覆盖现有模态,但如果扩展到上百种细分临床场景,4 个专家是否会出现表示容量饱和?
未来是否可以开发“即插即用”的专家 Token 库,让医生根据当前影像类型实时挂载对应的专家模块?如何将这种 Token-level MoE 扩展到 3D 医疗视频或多时相数据(如增强 CT 序列)中 。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)