VLAW:视觉-语言-行动策略和世界模式的迭代式协同-改进
26年2月来自斯坦福和清华的论文“VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model”。本文旨在通过迭代式在线交互来提升视觉-语言-动作(VLA)模型的性能和可靠性。由于在真实世界中收集策略部署数据成本高昂,研究能否利用学习型模拟器(具体而言,是一个基于动作条件的视频生成模型)来生成额外的部
26年2月来自斯坦福和清华的论文“VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model”。
本文旨在通过迭代式在线交互来提升视觉-语言-动作(VLA)模型的性能和可靠性。由于在真实世界中收集策略部署数据成本高昂,研究能否利用学习型模拟器(具体而言,是一个基于动作条件的视频生成模型)来生成额外的部署数据。然而,现有的世界模型缺乏策略改进所需的物理保真度:它们主要基于演示数据集进行训练,而这些数据集缺乏对多种物理交互(尤其是故障案例)的覆盖,并且难以精确建模接触丰富的物体操作中那些虽小但至关重要的物理细节。本文提出一种简单的迭代改进算法VLAW,该算法利用真实世界的部署数据来提升世界模型的保真度,进而生成补充合成数据,用于改进VLA模型。在真实机器人实验中,用这种方法来提高最先进的VLA模型在多个下游任务上的性能。与基础策略相比,实现39.2%的绝对成功率提升;与使用生成的合成展开集进行训练相比,成功率提升11.6%。
后训练视觉-语言-动作模型
视觉-语言-动作(VLA)模型在机器人操作任务中取得显著的成功(Intelligence et al., 2025b; Pertsch et al., 2025; Liu et al., 2025a; Cui et al., 2025; Hu et al., 2024; Guo et al., 2024; Zhang et al., 2026)。一种常见的方法是在大规模数据上训练VLA模型,然后在目标任务上进行监督式微调(Zhang et al., 2025a; Black et al., 2024; Zhang et al., 2025b)。除了监督式微调之外,利用在线部署数据改进VLA策略已成为一个很有前景的研究方向(Intelligence et al., 2025a; Guo et al., 2025b; Lu et al., 2025; Zang et al., 2025)。一些先前的研究采用基于策略的强化学习方法,例如PPO(Schulman et al., 2017)或GRPO(Shao et al., 2024),来改进VLA策略。
然而,标准的基于策略的强化学习通常需要大量的部署数据,因此主要在仿真环境中进行验证(Li et al., 2025b;a; Liu et al., 2025b)。此外,目前最先进的VLA模型通常使用流匹配目标进行训练,而流匹配目标无法提供明确的策略似然性,这使得传统的策略梯度方法难以应用。为了在真实世界环境中实现策略学习,π0∗.6(Intelligence 等人,2025a)采用一种离线或批量强化学习方法,并以优势条件监督学习为目标。
用于决策的世界模型
基于行动的世界模型能够根据当前的观察和行动预测未来的结果,也称为前向动态模型。许多研究利用此类模型进行基于模型的强化学习(Hafner et al., 2019; 2020; Hansen et al., 2022; Oh et al., 2015; Wu et al., 2024)和视觉规划(Finn & Levine, 2017; Ebert et al., 2018; Xie et al., 2019; Dasari et al., 2019; Yang et al., 2023)。其中DayDreamer(Wu et al., 2023)、SOLAR(Zhang et al., 2019)和World4rl(Jiang et al., 2025),也运行于真实世界的基于视觉模型强化学习环境中。然而,由于模型容量和数据规模的限制,这些早期方法通常学习的是特定任务的动态模型。随着视频扩散模型的最新进展(Ren et al., 2025; Ball et al., 2025; Mei et al., 2026),训练能够生成逼真未来视觉观测的多任务动作条件世界模型已成为可能(Chen et al., 2024; Gao et al., 2025; Zhu et al., 2024; 2025; Sharma et al., 2026)。尽管取得了这些进展,但准确地对复杂的物理动力学进行建模仍然是一个根本性的挑战,正如之前的世界模型文献中广泛观察的那样(Guo et al., 2025a),这可能是因为这些模型通常是在离线机器人数据集上训练的,而这些数据集通常主要由演示数据组成。
VLAW
如图所示:VLA模型在现实世界中的部署耗时且难以扩展。在VLAW中,首先利用有限的现实世界在线部署来学习一个基于动作的世界模型,进而生成大规模的虚拟合成数据。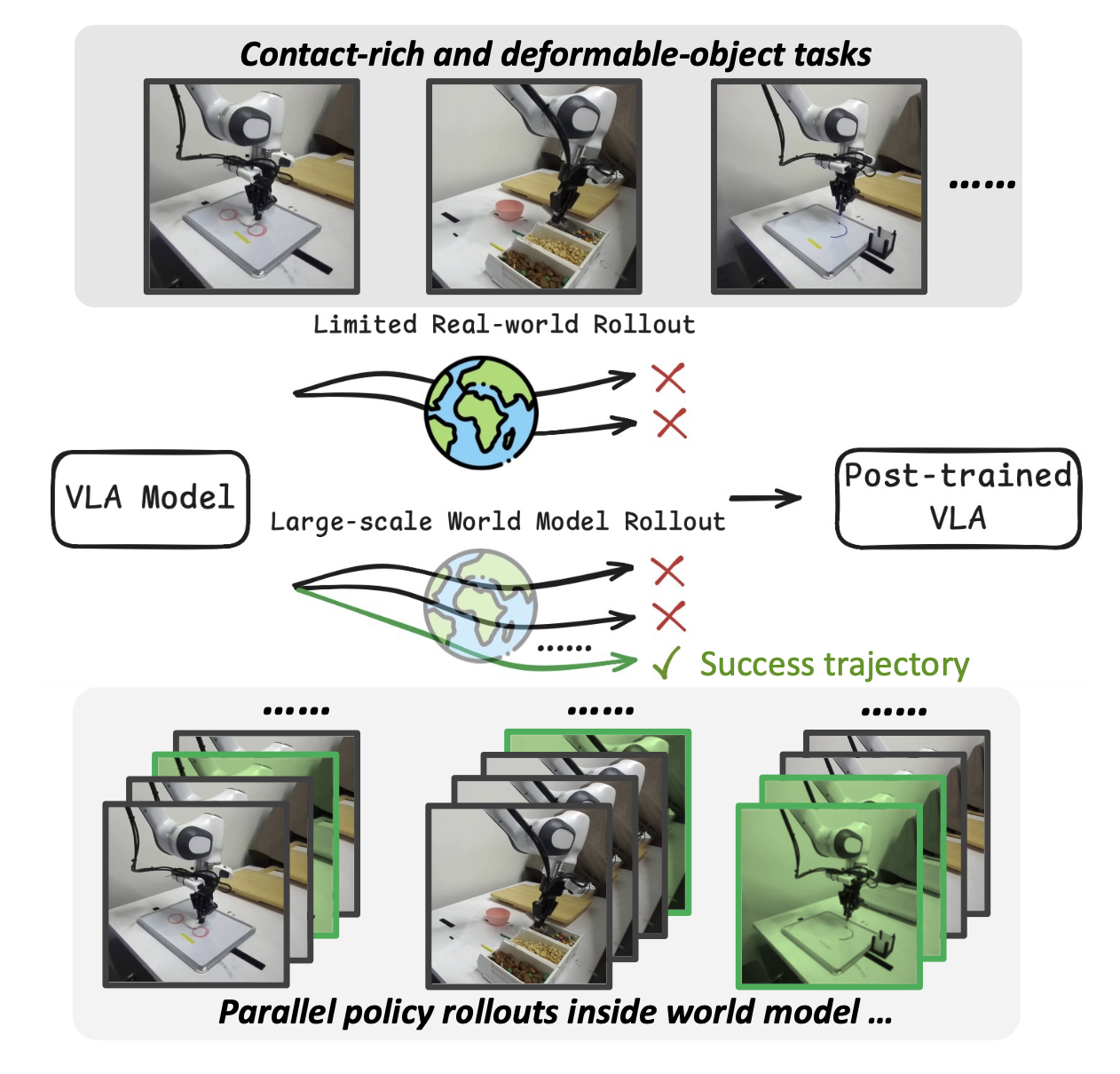
如图所示,VLAW通过世界模型演练迭代地改进VLA模型。首先利用包含大量失败案例的在线演练数据进行微调,学习一个基于物理实际的世界模型。经过在线演练数据训练后,世界模型能够捕捉策略执行过程中遇到的复杂动态,从而显著提升其对成功和失败案例的建模能力。随后,使用改进后的世界模型生成大规模、高保真度的合成轨迹,并使用视觉语言奖励模型(Lee,2026)对其进行自动标注。在策略优化过程中,仅使用能够轻松扩展到大型表达模型的稳定监督学习目标(例如,具有难处理动作概率的流匹配策略(Intelligence,2025b)),而不是动态规划/引导或策略梯度。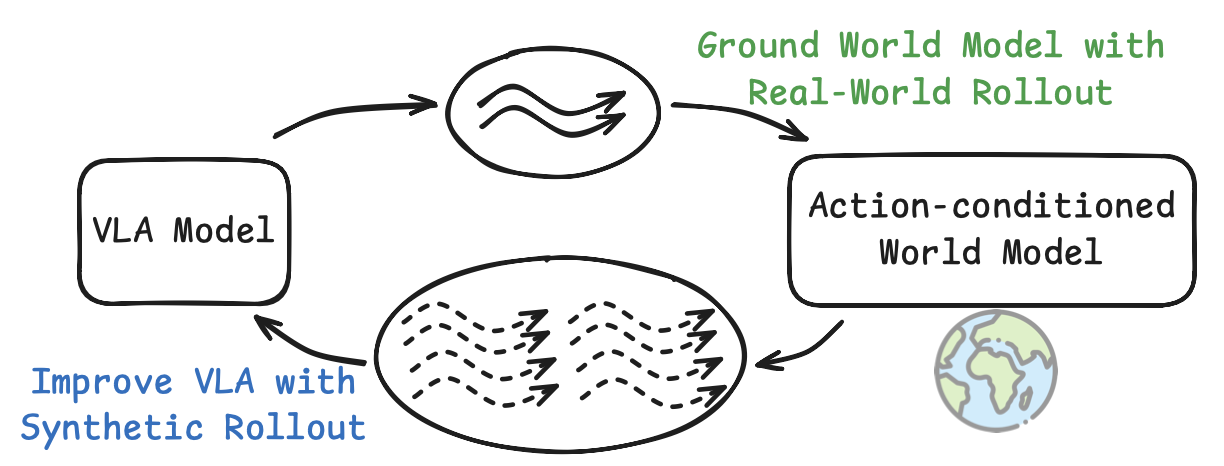
研究一个多任务机器人操作问题,其中每个任务都由一条语言指令 I 指定,并建模为一个马尔可夫决策过程 (MDP) M_I = (S, A, P, R_I, γ)。这里,S 表示状态空间,A 表示动作空间,P(s_t+1 | s_t, a_t) 表示状态转移动力学,R_I 表示与任务相关的奖励函数,γ 表示折扣因子。在训练开始时,给定一个预训练的视觉-语言-动作 (VLA) 策略 π_θ 和一个动作条件化的世界模型 M_φ。该策略将当前状态和指令映射到动作分布 a_t ∼ π_θ(· | s_t, I),而世界模型则根据当前状态和动作预测下一个状态 sˆ_t+1 ∼ M_φ(· | s_t, a_t),其中 sˆ_t+1 表示预测的下一个状态。
该策略允许在真实环境中收集在线部署结果,从而生成轨迹 τi_real = {s_0, a_0,…, a_T−1, s_T}。每条轨迹都带有任务级奖励 r_i,用于指示成功或失败。目标是利用在线交互迭代改进该策略,使其在所有任务中都能表现良好。
世界模型生成的轨迹。除了真实世界的交互之外,还可以在世界模型内部部署该策略。从真实轨迹中采样得到的初始状态 s_0 出发,策略模型和世界模型通过 a_t ∼ π_θ(· | sˆt, I) 和 sˆ_t+1 ∼ M_φ (· | sˆ_t , a_t ) 在闭环中相互作用。通过迭代此过程,自回归地生成完整的想象轨迹 τj_syn = {s_0, a_0, sˆ_1, a_1, …, a_T-1 ,sˆ_T-1}。
整个VLAW流程包含以下步骤:
- 世界模型后训练:用真实世界展开( Rollout)数据集 D_real 对世界模型 M 进行微调,并将其与原始 DROID 数据集 D_DROID 联合训练,以保持广泛的覆盖范围。此外,还在 D_real 上微调视觉语言奖励模型 R,以提高奖励准确率。
- VLA 策略后训练:使用更新后的世界模型,生成一个合成数据集 D_syn,并应用奖励模型 R 来识别成功的轨迹,从而得到一个经过过滤的数据集 D+_syn。然后,使用该数据集来微调 VLA 策略。
- 交替执行步骤 1 和 2,迭代地改进世界模型和策略。
整个流程总结在算法 1 和下图中。 该更新过程可以解释为在正则化强化学习框架下对策略优化的近似。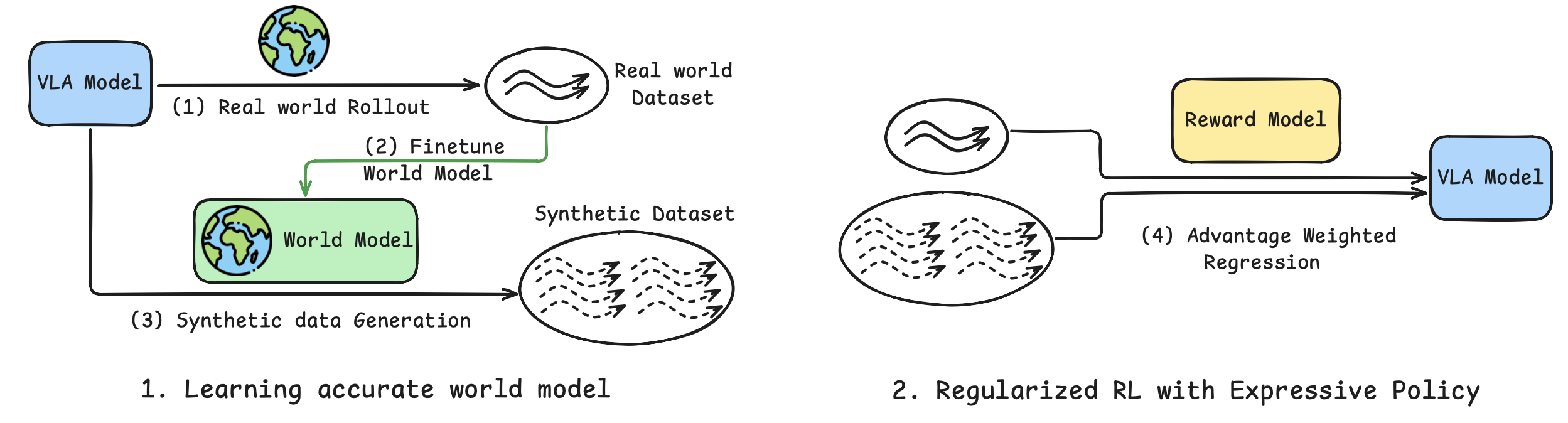
基于真实场景的世界模型学习
真实世界策略展开。以往的研究指出,学习有效的世界模型面临两大挑战:(1) 过度乐观,因为训练数据主要由成功的案例构成;(2) 物理保真度有限,尤其是在模拟涉及频繁接触或可变形体的复杂动态时。
为了解决这些问题,通过在现实世界中部署策略来获得 K 条轨迹,从而形成数据集 D_real = {τ1_real, …, τK_real }。此外,还为每条轨迹分配一个稀疏奖励 r_τ ∈{0,1},以指示每次重置机器人时是否成功。
训练目标。D_real 捕捉执行过程中遇到的各种物理交互,包括成功和失败的情况,并用于微调预训练的世界模型。具体来说,从预训练的 Ctrl-World 模型(Guo,2025a)进行初始化,这是一个在完整的 DROID 数据集 D_DROID 上训练的强大的基于扩散世界模型。在线部署数据集 D_real 上的微调,遵循原始的扩散目标函数(Blattmann,2023):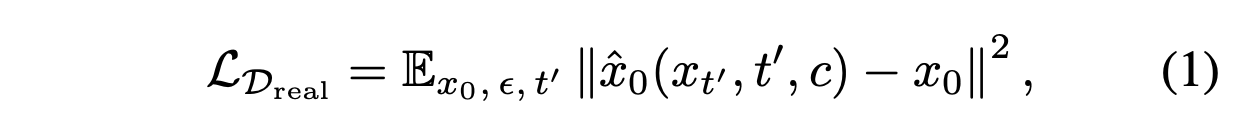
逐步增长的数据集和协同训练。在连续迭代过程中,不断将新收集的真实世界轨迹添加到数据集中:D_real = D_real ∪ τi_real。为了防止模型过拟合有限的在线部署数据,还使用原始的 DROID 数据集 D_DROID 进行协同训练以进行正则化。最终的训练目标是: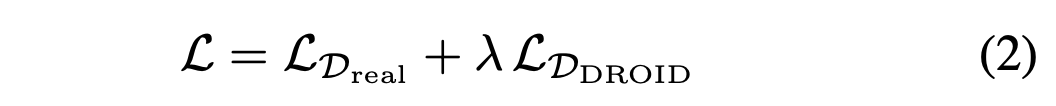
其中 λ 控制正则化的强度。
微调奖励模型。为了保持流程的简洁性和可扩展性,用通用视觉语言模型 Qwen3-VL-4B-Instruct(Team,2025a;Lee,2026)来评估轨迹是否成功。然而,零样本 VLM 的精度不够,因此在第一次迭代中,用 D_real 中的成功标签 r_τ 对 VLM 进行微调。
在实现过程中,奖励模型以轨迹视频 τi_real 和一个查询作为输入,该查询询问任务指令 Ii 是否成功完成。如果分配给“是”token的概率超过阈值 α,则将该轨迹分类为成功。通过调整 α,可以使奖励模型更加保守或更加宽松: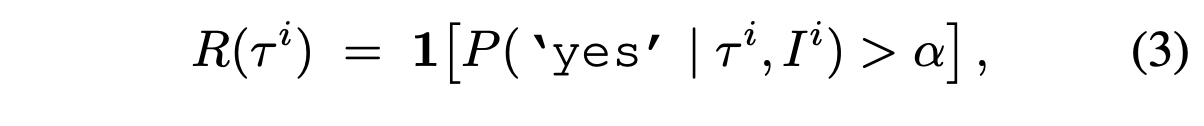
VLA策略的迭代改进
可扩展的训练流程。一旦拥有一个良好的学习世界模型和奖励模型,就可以利用它低成本地生成大量合成数据。原则上,许多不同的算法都可以用于利用这些数据,包括各种复杂的强化学习方法。由于希望能够轻松扩展到大规模基于流匹配的VLA策略,因此选择使用最简单的方法来整合这些合成数据。
具体来说,通过在想象中展开策略来生成N条轨迹:D_syn = {τ1_syn , …, τN_syn }。然后,应用微调后的奖励模型来识别成功的轨迹,并构建一个仅包含成功案例的过滤数据集:D+_syn = {τi_1_syn ,…,τi_n_syn },其中i_1,…,i_n是成功轨迹的索引。
策略学习目标。用基于真实世界部署数据和世界模型生成数据的加权流匹配目标来更新 π0.5 策略。在筛选出成功轨迹后,为来自成功轨迹的转换分配二元权重 w(o, a) = 1,为来自失败轨迹的转换分配二元权重 w(o, a) = 0: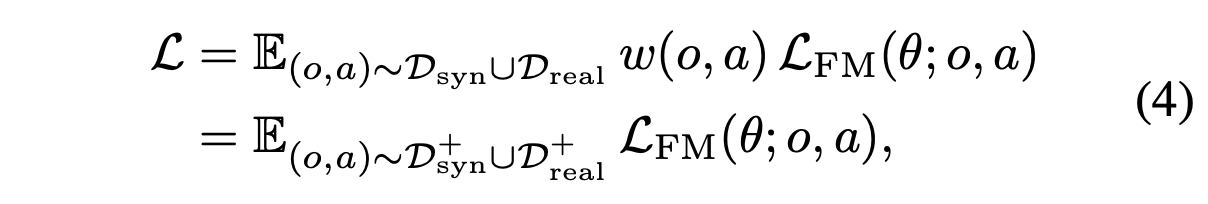
其中L_FM()表示观测-动作的流匹配损失。
实验设置
实验设置和任务。在 DROID 平台(Khazatsky,2024)上进行实验。在 DROID 设置中,Franka Panda 机械臂配备了 Robotiq 夹爪。
如图所示,用两台第三人称摄像头和一台腕戴式摄像头采集观测数据。在以下描述的五类需要大量接触的任务中评估方法:
• 堆叠:在每个回合开始时,四个彩色积木随机放置在桌面上。机器人接收指令:“将积木 A 堆叠在积木 B 上”,其中 A, B ∈ {红色, 绿色, 蓝色, 黄色}。
• 打开书籍:在每个回合开始时,一本书随机放置在桌面上。评估四本不同书籍的性能。机器人接收指令:“打开书的封面”。
• 擦除痕迹:在白板上随机绘制一到三个马克笔图案。机器人接收指令:“用纸巾擦除所有痕迹”。
• 舀取:机器人使用勺子将零食舀入碗中。勺子和碗均随机放置在工作空间内。指令为:“将一些 A 转移到碗中”,其中 A ∈ {花生, 糖果, 杏仁}。
• 绘图:机器人被指示使用记号笔在白板上画一个完整的圆。
基础模型和超参数。用 π0.5(Intelligence,2025b)作为基础视觉-语言-动作 (VLA) 模型,Ctrl-World(Guo,2025a)作为基础世界模型。对于每个任务类别,收集 25 个专家演示,并在此数据上微调 π0.5 以预热策略,该预热策略作为基础策略。奖励模型由 Qwen3-VL-4B-Instruct(Team,2025a)初始化。
在每次迭代中,在真实世界中为每个任务类别部署 50 条轨迹。用这些展开轨迹对世界模型进行 5 万次训练步的微调。然后,用更新后的世界模型为每个任务生成 500 条合成轨迹,从而构建合成数据集。此外,还使用第一次迭代的展开数据对奖励模型进行微调,以提高奖励的准确性。策略以 2000 步的迭代周期进行更新,批大小为 256。总共执行两次迭代。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 21
21 0
0- 0



 已为社区贡献198条内容
已为社区贡献198条内容

所有评论(0)