借助 TensorFlow 实现基于视频数据的深度学习
本文介绍了使用TensorFlow高效处理视频数据的方法。重点讲解了FrameGenerator生成器类,它通过from_generator()接口实现内存高效的数据加载,适用于视频分类任务。同时介绍了einops库在视频下采样中的应用,通过ResizeVideo层实现张量尺寸调整,提升处理效率。这些技术不仅适用于视频数据,也可用于医疗影像等三维数据,在资源有限场景下尤其实用。文中提供了相关教程链
摘要:本文介绍了使用TensorFlow高效处理视频数据的方法。重点讲解了FrameGenerator生成器类,它通过from_generator()接口实现内存高效的数据加载,适用于视频分类任务。同时介绍了einops库在视频下采样中的应用,通过ResizeVideo层实现张量尺寸调整,提升处理效率。这些技术不仅适用于视频数据,也可用于医疗影像等三维数据,在资源有限场景下尤其实用。文中提供了相关教程链接,帮助开发者构建高效视频处理模型。
目录
借助 TensorFlow 实现基于视频数据的深度学习
视频数据包含丰富的信息,其结构相比图像数据更为复杂、数据量也更大。通过深度学习以内存高效的方式对视频进行分类,能帮助我们更好地理解数据中的内容。我们已在 TensorFlow 官方网站发布了一系列关于视频数据加载、预处理和分类的教程,以下是各教程的快速链接:
- 加载视频数据
- 基于 3D 卷积神经网络的视频分类
- 用于流式动作识别的 MoViNet 模型
- 结合 MoViNet 的视频分类迁移学习
在本篇博文中,我们将深入解析部分教程的特定内容,同时介绍如何整合这些内容,基于 TensorFlow 构建可高效处理视频或三维数据(如核磁共振扫描图像)的模型,实现内存高效利用,比如借助 Python 生成器、对数据进行缩放或下采样等方法。
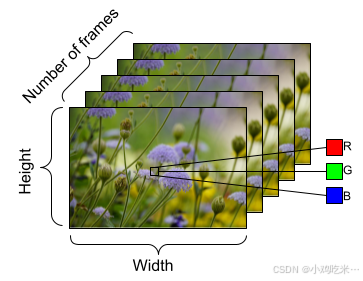
(附:视频数据三维结构示意图,展示高度、宽度和帧数(时间维度))视频数据的形状示例,维度构成如下:帧数(时间)× 高度 × 宽度 × 通道数
用于加载视频数据的 FrameGenerator 生成器
从《加载视频数据》教程出发,我们来介绍多数教程中的核心工具 ——FrameGenerator 类。通过该类,我们可以生成视频的张量表示形式,以及对应的视频标签或类别。
class FrameGenerator:
def __init__(self, path, n_frames, training = False):
"""
返回一组帧及其对应的标签
参数:
path:视频文件路径
n_frames:提取的帧数
training:布尔值,标记是否为训练数据集创建生成器
"""
self.path = path
self.n_frames = n_frames
self.training = training
self.class_names = sorted(set(p.name for p in self.path.iterdir() if p.is_dir()))
self.class_ids_for_name = dict((name, idx) for idx, name in enumerate(self.class_names))
def get_files_and_class_names(self):
video_paths = list(self.path.glob('*/*.avi'))
classes = [p.parent.name for p in video_paths]
return video_paths, classes
def __call__(self):
video_paths, classes = self.get_files_and_class_names()
pairs = list(zip(video_paths, classes))
if self.training:
random.shuffle(pairs)
for path, name in pairs:
video_frames = frames_from_video_file(path, self.n_frames)
label = self.class_ids_for_name[name] # 对标签进行编码
yield video_frames, label
创建该生成器类后,我们可调用 from_generator () 函数将数据输入深度学习模型。具体而言,from_generator () 编程接口会创建一个由生成器生成数据内容的数据集。与将整组数据序列存储在内存中相比,使用 Python 生成器的内存利用效率更高。建议你创建类似 FrameGenerator 的生成器类,并通过 from_generator () 接口将数据加载至 TensorFlow 和 Keras 模型中。
output_signature = (tf.TensorSpec(shape = (None, None, None, 3),
dtype = tf.float32),
tf.TensorSpec(shape = (),
dtype = tf.int16))
train_ds = tf.data.Dataset.from_generator(FrameGenerator(subset_paths['train'],
10,
training=True),
output_signature = output_signature)
用于调整视频数据尺寸的 einops 库
在《基于 3D 卷积神经网络的视频分类》第二篇教程中,我们将介绍 einops 库的使用方法,以及如何将其整合到由 TensorFlow 支持的 Keras 模型中。该库可灵活执行张量运算,不仅适用于 TensorFlow,也可与 JAX 框架配合使用。在本教程中,我们主要利用它在搭建的(2+1)D 卷积神经网络处理数据的过程中完成数据尺寸调整。
本教程中我们需要对视频数据进行下采样,这一操作尤为实用:它能让模型聚焦于帧的特定区域,识别可能与视频中某一特征相关的模式,同时舍弃非关键信息,实现维度约简,进而提升数据处理速度。
我们使用了 einops 库中的 parse_shape () 和 rearrange () 函数。其中 parse_shape () 函数会将张量各轴的名称映射至对应的长度,返回包含该映射信息的字典(记为 old_shape);rearrange () 函数则可对多维张量的轴进行重新排序,使用时只需传入张量及待重排的轴名称即可。
表达式b t h w c -> (b t) h w c表示将批次大小(记为 b)和时间维度(记为 t)进行合并,以便将数据输入 Keras 的 Resizing 层。实例化 ResizeVideo 类时,需传入帧目标缩放后的高度和宽度值;完成缩放后,再次调用 rearrange () 函数,通过表达式(b t) h w c -> b t h w c将合并的批次大小和时间维度还原。
class ResizeVideo(keras.layers.Layer):
def __init__(self, height, width):
super().__init__()
self.height = height
self.width = width
self.resizing_layer = layers.Resizing(self.height, self.width)
def call(self, video):
"""
利用einops库调整张量尺寸
参数:
video:视频的张量表示形式,由多帧图像构成
返回:
按目标高宽完成下采样后的视频张量
"""
# b=批次大小,t=时间维度,h=高度,w=宽度,c=通道数
old_shape = einops.parse_shape(video, 'b t h w c')
images = einops.rearrange(video, 'b t h w c -> (b t) h w c')
images = self.resizing_layer(images)
videos = einops.rearrange(images, '(b t) h w c -> b t h w c', t = old_shape['t'])
return videos
后续拓展
以上只是借助 TensorFlow 实现视频数据内存高效处理的几种方法,这些技术并非仅适用于视频数据。核磁共振扫描等医疗数据或三维图像数据,同样需要高效的数据加载方式,且可能需要调整数据形状。在计算资源有限的场景下,这些技术能发挥重要作用。希望这些教程能为你提供帮助,感谢阅读!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)