OmniRetarget——可与场景交互的人形全身行走-操控系统:实现26年春晚宇树攀爬、跳跃、翻滚、蹬墙翻转及箱体搬运
本文提出OmniRetarget系统,用于解决人形机器人全身控制中的数据瓶颈问题。该系统通过交互网格建模技术,将人类示范动作重定向到机器人形态,同时保持与场景的关键交互关系。相比现有方法,OmniRetarget采用约束优化确保物理可行性,避免了运动伪影,并能自动生成多样化训练样本。实验表明,基于该系统数据训练的策略在多种交互任务中表现优异,且能实现零样本仿真到真实的迁移。该系统为人形机器人自然行
前言
25年2.16日,除夕之夜,看到春晚上宇树机器人的惊艳表现之后,我在朋友圈说道
- 24年,从大模型应用开发切入具身机器人
- 25年,技术上完成多轮突飞猛进
- 26年,不遗余力,继续全力做具身,用十年时间让所有机器人都有一个聪明的大脑
而宇树目前的运控这么牛,有一半源于各大科研机构、各个开发者,基于宇树本体做了太多工作,并开源,包括我司也在各种本体上做了各种开发/训练(当然,干活方面,26年智能机械臂、智能轮式人形,会大放异彩)
考虑到不少朋友对宇树春晚表现背后的技术感兴趣,故我准备解读几篇相关技术的paper
第一部分 OmniRetarget: Interaction-Preserving Data Generation for HumanoidWhole-Body Loco-Manipulation and Scene Interaction
1.1 引言与相关工作
1.1.1 引言
如原论文所说,为了让人形机器人能够执行复杂的全身场景与物体交互任务,人们长期以来一直受制于一个根本性的数据瓶颈
- 尽管深度强化学习(RL)在机器人控制方面已经取得了显著成功,但高效的探索对奖励工程极为敏感 [3]
在有人形机器人场景中,这一挑战被进一步放大:其高维动作空间和复杂动力学特性,使得从零开始学习自然且具有表现力的行为既困难又低效 - 为了解决这些挑战,模仿人类动作为学习全身控制提供了一种有力的替代方案,尤其适用于复杂场景交互
人类示范能够捕捉动态协调能力,例如在不平地形上行走的同时搬运物体,并已在动画领域得到有效应用 [4], [5], [6] - 然而,在机器人领域中出现了一个关键挑战:与虚拟角色不同,实体人形机器人只能近似人类形态,在形状、比例以及自由度等方面都存在显著差异
这种具身差异意味着,仅仅对人类动作进行简单适配还不够;为了生成可用的参考,还必须将他们与场景的交互也适配到机器人特定的形态
为此,研究者主要采用了两种策略
- 第一种是遥操作[7], [8], [9],其中仅将人类操作员的动作进行重定向,用于在线控制机器人。这种方法利用人类操作员进行实时适应,从而绕过了对自动交互重定向的需求
然而,尽管具有在线反馈的优势,该方法仍然需要大量人工投入,难以在大规模数据生成场景中很好地扩展 - 第二种、也是更具可扩展性的策略是离线交互重定向,它以整体方式同时将人的运动及其与场景的交互适配到机器人特定的具身形态
————
然而,大多数现有的重定向方法 [10], [9], [11] 在这方面表现不足。它们主要依赖于无约束或仅带有轻微惩罚的优化过程,导致生成的动作不真实,出现诸如脚步打滑和物体相互穿透等伪影
更重要的是,这些方法在重定向建模中并未显式考虑交互保持(即保持空间关系和接触关系),而只是简单依赖关键点匹配
因此,得到的参考动作质量较低,进而增加了后续基于强化学习的策略训练 [12], [8],[13] 的难度
对此,来自的研究者提出了 OmniRetarget,这是一款开源的数据生成引擎,用于将人类示范转化为多样且高质量的运动学参考,以实现仿人机器人全身控制

- 通过利用交互网格(interaction mesh)[14] 建模机器人、物体与地形之间的空间与接触关系,OmniRetarget 保留关键交互并生成在运动学上可行的多种变体
————
现有方法需要为每一种变体分别采集示范数据——这不仅使数据采集成本高昂,也限制了覆盖范围——而 OmniRetarget 直接解决了这一瓶颈
受用于高接触操控任务的数据增强框架 [15] 的启发,OmniRetarget可以自动将单次示范扩展为大量训练样本,覆盖不同的物体构型、形状、机器人形体以及环境 - 且作者的流水线采用约束优化来确保物理可行性,包括避免碰撞、关节极限以及足部接触稳定性,同时将交互网格的形变最小化
由此产生的运动能够保持交互特性,只呈现极少的运动学伪影,从而提供密集的学习信号,以极少的奖励设计就能加速强化学习(RL)
在包括抬箱、攀爬平台和坡面爬行等多种全身交互任务上,基于 OmniRetarget 数据集训练得到的策略在运动质量和鲁棒性上均优于以往的重定目标方法,并且能够在无需额外调参的零样本仿真到真实(sim-to-real)迁移设置下成功部署到实体的人形机器人上
1.1.2 相关工作
首先,对于动作重定向
- 在计算机图形学中,跨角色的动作迁移已经被广泛研究。研究者采用基于优化的方法,将人体动作重定向到虚拟化身上:通过保持关键点之间的距离和朝向 [16]、最小化形变能量 [14], [17],或者对动作进行缩放以满足硬约束 [18]
也有工作利用数据驱动的方法,将不同的骨骼映射到一个规范化表示 [19],利用神经网络求解逆运动学 [20],或者使用强化学习来保持交互图结构 [21] - 将动作重定向到人形机器人带来了超出角色动画范畴的额外挑战,尤其是必须满足物理约束。例如,PHC[10] 是一种在机器人领域中被采用的图形学方法[13], [8],其使用基于关键点匹配的无约束优化,往往会导致几何体穿透、脚滑,以及对物体或场景缺乏感知
类似地,GMR [9] 将关键点匹配扩展到了方向信息,但也存在相同的问题
VideoMimic [11] 通过引入软接触和碰撞惩罚项提高了真实感,但无法提供任何严格保证,并且需要精细的参数调整 - 与作者的方法最接近的是基于 Interaction Mesh 的运动自适应(Interaction Mesh based Motion Adaptation,IMMA)[22],它同样利用 interaction mesh [14] 来保持身体各部分之间的空间关系
然而,该方法并未开源,而且忽略了运动学极限以及与环境或被操控物体之间的交互。相比之下,OmniRetarget 统一了所有硬约束,包括脚部黏附(foot sticking)、非穿透(non-penetration)、以及关节和速度限制,同时还显式地保留与环境和物体的交互
其次,对于基于学习的人形机器人全身控制
- 最新的基于学习的全身控制方法已经使人形机器人能够穿越动态场景并操纵物体 [23], [24], [25], [26], [27],[28], [29], [30], [31]
这些方法通常通过手工设计的奖励或任务接口进行训练(例如,速度跟踪、接触时序、末端执行器目标),但高度依赖繁琐的奖励工程,而且大多难以产生自然的、接近人类水平的运动 - 动作模仿提供了一种很有前景的替代方案
在计算机图形学中,DeepMimic [4] 展示了利用人类参考动作可以产生自然、类人化的行为,并具有敏捷、动态的运动表现
然而,将这种方法应用到人形机器人上仍然很困难,其原因在于缺乏可靠的、开源的运动学重定向流水线
在参考动作质量不佳的情况下,从业者不得不手动清洗数据[12],或者重新引入大量奖励工程工作,例如为接触、打滑和腾空时间设计临时性的正则项,以补偿这些伪影 [9],[13], [32] - 相比之下,仅具有最小的跟踪器比如像 BeyondMimic [33] 这样的奖励设计在具有高保真参考[34] 的硬件上取得了最先进的结果,但此类参考十分稀缺,而且只涉及机器人本体,不包含交互
- 而超越单角色运动,人–场景交互数据已被证明在角色动画中的地形穿越和行走操控(loco-manipulation)方面是有效的 [5], [6],然而要将其迁移到机器人领域仍然具有挑战
VideoMimic [11] 通过从视频中重建运动和地形,将这一思想应用于人–地形穿越,但会产生伪影且仅限于静态场景交互
————
为弥合这一差距,OmniRetarget 通过重定向获得的高质量参考,在无需手动后处理或奖励工程的前提下,实现了自然、敏捷的机器人–物体–场景交互
最后,对于面向类人行走-操作的数据生成
对全身交互数据的需求推动了大量以数据生成为目标的既有研究
- 一种途径是直接由人进行遥操作[35], [7], [8], [9], [36]。虽然这种方式可以提供在线反馈,但遥操作很难扩展:它劳动密集、易导致操作员疲劳,并且受到人体与机器人运动学之间具身差异的限制
缺乏丰富的触觉反馈以及难以稳定极端动作(例如深蹲)进一步限制了其适用性
为了解决这些扩展性方面的挑战,研究者开始探索自动化数据增强方法,特别是在机器人操作任务中。许多工作利用最先进的生成模型进行视觉 [37],[38], [39] 和语义 [40], [41], [42] 方面的增强; - 而另一些工作则依赖于在仿真中对基线轨迹进行简单的开环运动学重放 [43], [44], [45],或进行轨迹优化 [15]
尽管在操作任务上已有这些进展,面向全身行走-操作的数据增强仍然基本未被深入探索
与本研究最接近的前期工作 [46] 通过关键点插值来增强不同形状的物体,但同样无法处理多样的物体姿态。OmniRetarget 直接弥补了这一空白
1.2 保持交互的动作重定向
1.2.1 具有硬约束的交互网格
作者利用交互网格(interaction mesh)[14] 来保持身体各部位、物体与环境之间的空间关系
如下图所示
通过基于 interaction-mesh 的约束优化,将人类示范重定向到机器人。针对每一种空间和形状增强分别求解新的优化问题,从而生成多样化的轨迹,在仅需极少奖励设计并结合域随机化的条件下,作为强化学习训练的参考,使得策略能够零样本迁移到真实世界的人形机器人
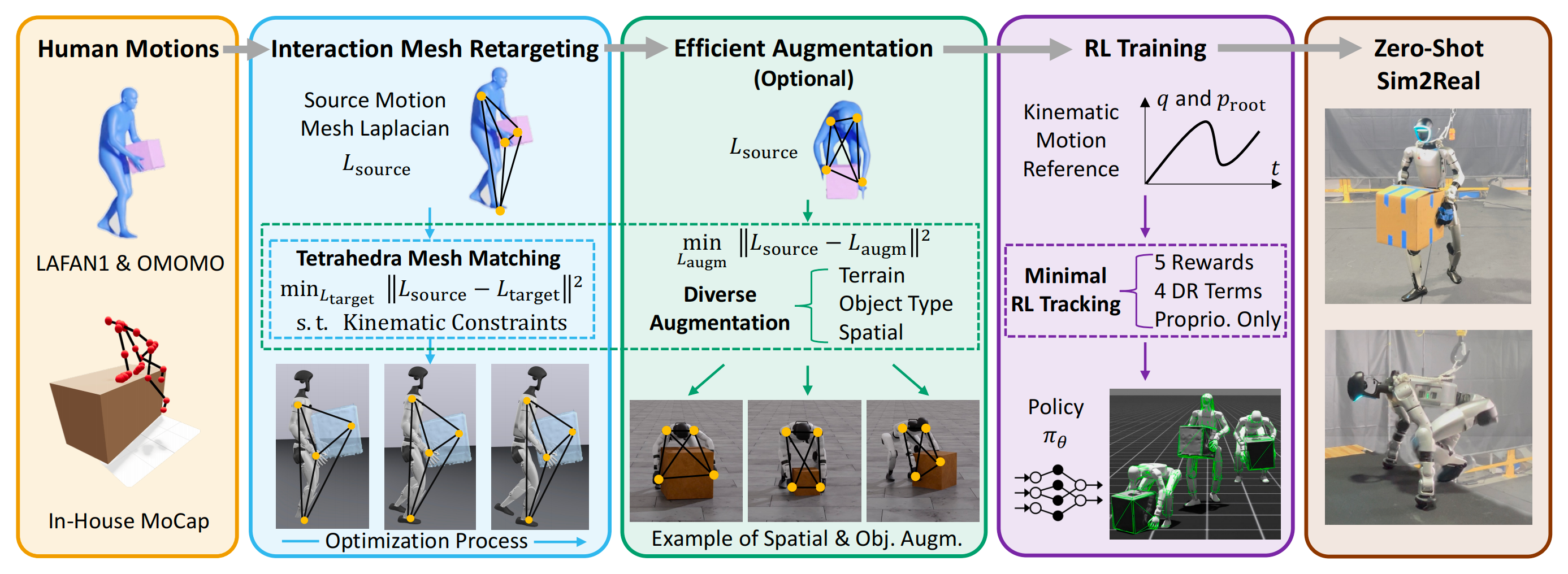
交互网格被定义为一种体积结构,其顶点由关键的机器人或人体关节,以及从物体和环境中采样得到的点构成。通过收缩或拉伸该网格,作者可以在保持相对空间构型和接触关系的前提下,将人体运动变形映射到机器人上
- 交互网格构建
作者通过对用户定义的关键关节位置以及从物体和环境中随机采样的点应用Delaunay 四面体化 [48] 来构建交互网格
为了更精确地保持接触关系,作者对物体和环境的表面进行比身体关节更高密度的采样 - 优化目标和约束
为保持身体部位、物体和地形之间的空间关系,作者的主要目标是最小化由两组对应关键点构造的交互网格[49],[50] 的拉普拉斯形变能量
————
在帧,
中的源集合由用户定义的人体解剖点,以及在被操控物体和环境上随机采样的点组成
用于重定向运动的目标集合由机器人上对应的解剖点,以及相同的被操控物体和环境点构成
作者的方法对这些关键点的精确放置相对鲁棒,仅要求在人与机器人之间具有语义一致的对应关系(例如,手对应手)
第
个关键点
的拉普拉斯坐标被定义为:该点与其邻居
的加权平均之间的差
- 其中
是归一化权重,并且为了简洁,在函数定义中作者省略了
对
的依赖
- 对于作者所有的实验,作者使用均匀权重,设置
形变能量度量源示例网格 与重定向后网格
之间这些拉普拉斯坐标的变化:
作者寻求机器人构型 ,由浮动基座位姿(四元数和平移)以及所有关节角组成,在满足一组严格运动学约束的前提下,使该形变能量最小化
机器人的关键点由其构型 通过正向运动学
确定,即
在每一个时间步,作者求解以下受约束的非凸规划问题
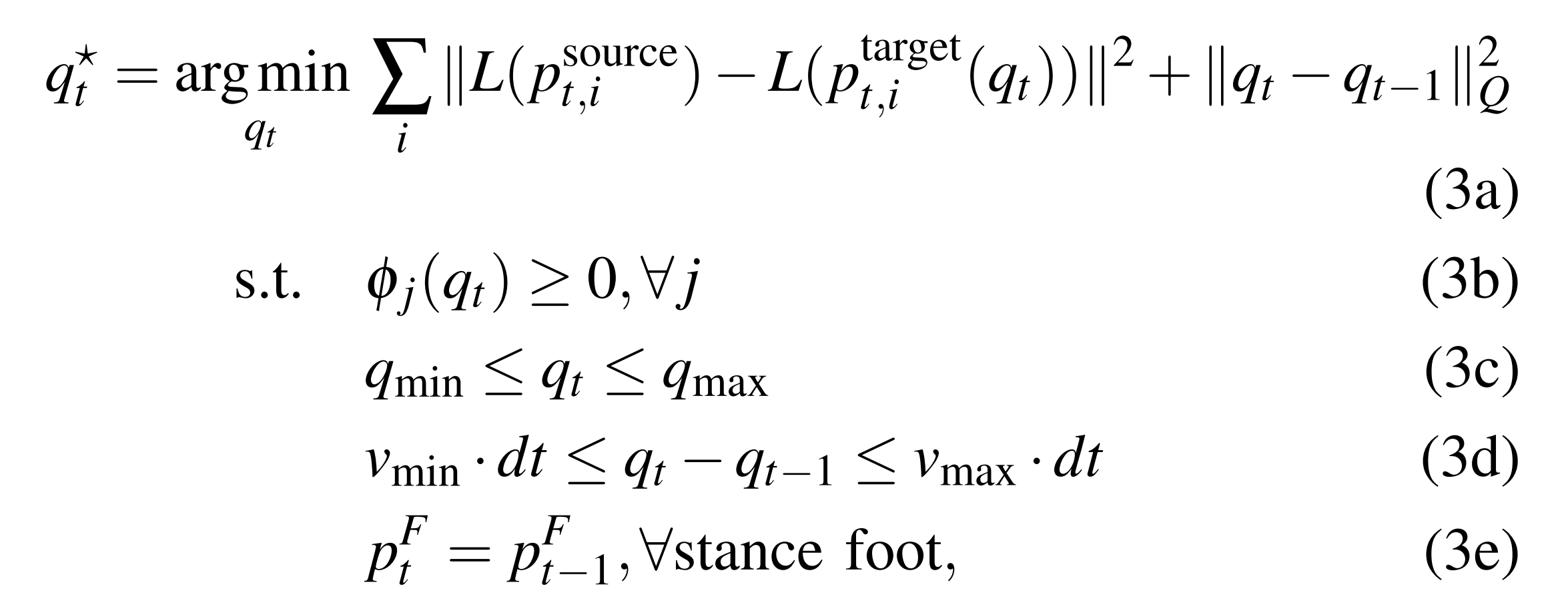
- 其中
是鼓励时间平滑性的代价矩阵,
表示第
个碰撞对的符号距离函数,
和
是构型和速度的边界,
表示足部位置
- 如果足部在源运动中的水平速度(在xy 平面)低于1 cm/s 的阈值,则认为该足处于支撑相。该优化程序求解一个在时间上一致的机器人轨迹,在满足
碰撞规避约束(3b)
关节和速度限制(3c)-(3d)
以及防止足部滑移(3e)
等硬约束的前提下,使交互网格形变最小 - 作者使用定制的顺序二次规划(Sequential QuadraticProgramming, SQP)风格的求解器,对每个时间步依次求解(3)
在每次迭代中,目标函数(3a) 被二次近似,而硬约束(3b)-(3e) 则在线性化到前一迭代的解附近
为确保时间一致性并加速收敛,第作为热启动
作者的实现利用了 Drake 中的自动微分框架 [51],该框架能够正确处理 S3 流形上旋转的微分几何 [52]
且基于交互网格的运动学管线具有很强的通用性。它可以通过仅修改交互网格中的关键点对应关系以及机器人的碰撞模型,自适应到不同的机器人形态,包括 Unitree G1、H1 和 Booster T1
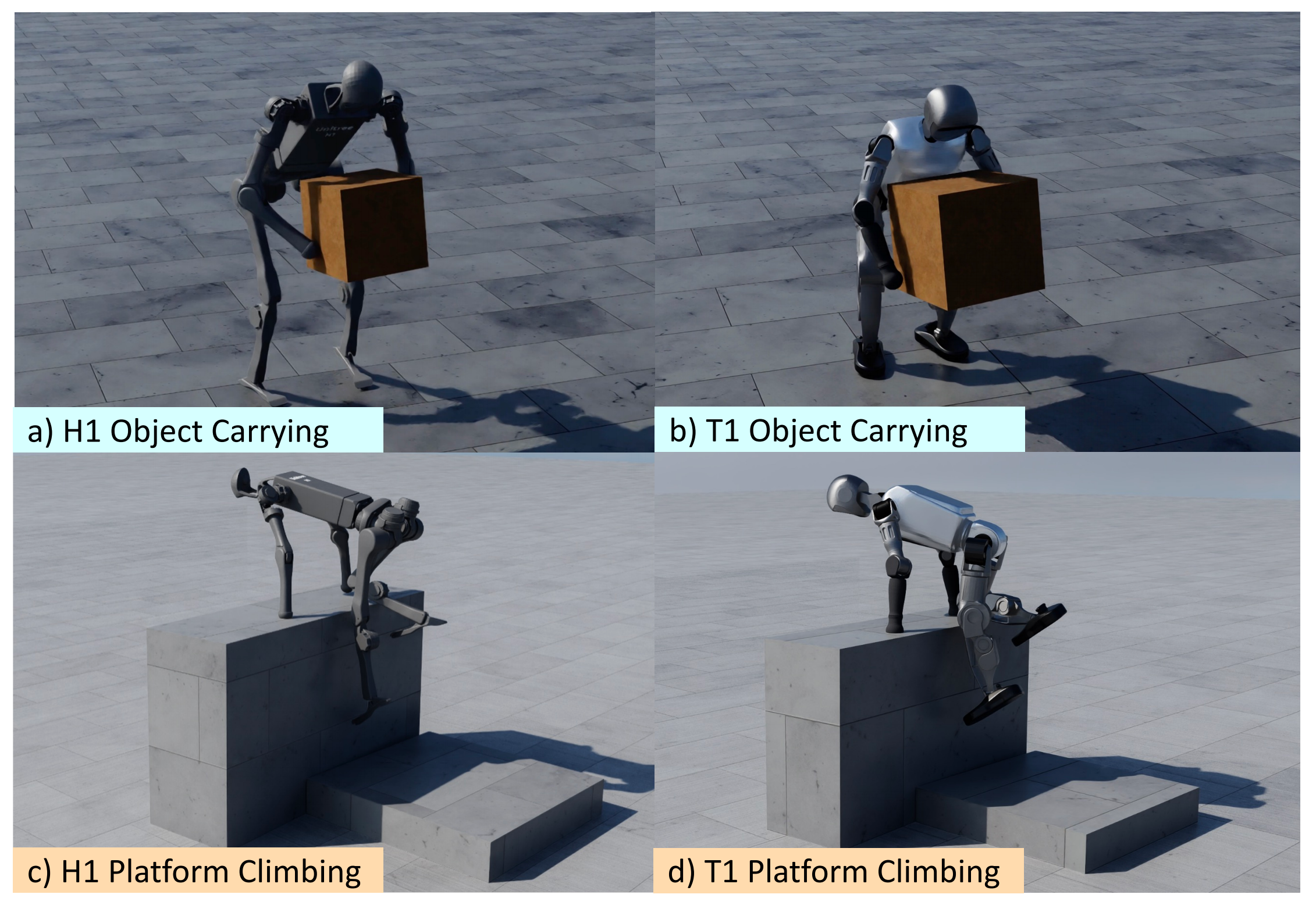
此外,它还支持多种交互类型:来自 OMOMO [1] 的机器人-物体交互、基于内部 MoCap 数据的机器人-地形交互,以及来自 LAFAN1 [2] 的平地机器人单体运动
1.2.2 地形、物体形状与空间增强
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 11
11 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)